监督学习(Supervised Learning)
- [监督学习(Supervised Learning)](#监督学习(Supervised Learning))
-
- [1. 假设空间与模型](#1. 假设空间与模型)
-
- [1.1 模型的两种形式](#1.1 模型的两种形式)
- [2. 策略:损失函数与风险最小化](#2. 策略:损失函数与风险最小化)
-
- [2.1 损失函数(Loss Function)](#2.1 损失函数(Loss Function))
- [2.2 风险函数(Risk Function)](#2.2 风险函数(Risk Function))
- [2.3 风险最小化准则](#2.3 风险最小化准则)
-
- [(1)经验风险最小化(Empirical Risk Minimization, ERM)](#(1)经验风险最小化(Empirical Risk Minimization, ERM))
- [(2)结构风险最小化(Structural Risk Minimization, SRM)](#(2)结构风险最小化(Structural Risk Minimization, SRM))
- [2.4 训练误差与测试误差](#2.4 训练误差与测试误差)
-
- [(1)训练误差(Training Error)](#(1)训练误差(Training Error))
- [(2)测试误差(Test Error)](#(2)测试误差(Test Error))
- [2.5 过拟合与正则化实例(多项式回归)](#2.5 过拟合与正则化实例(多项式回归))
-
- [(1)M 次多项式模型(M-th Order Polynomial Model)](#(1)M 次多项式模型(M-th Order Polynomial Model))
- (2)经验风险最小化(无正则化):过拟合的根源
- (3)正则化:给过拟合「踩刹车」
-
- [① L2 正则化(岭回归)](#① L2 正则化(岭回归))
- [② L1 正则化(Lasso 回归)](#② L1 正则化(Lasso 回归))
- [③ 正则化核心对比](#③ 正则化核心对比)
- [2.6 过拟合(Over-Fitting)通俗定义](#2.6 过拟合(Over-Fitting)通俗定义)
- [3. 泛化误差与泛化误差上界](#3. 泛化误差与泛化误差上界)
-
- [3.1 泛化误差(Generalization Error)](#3.1 泛化误差(Generalization Error))
- [3.2 泛化误差上界(Generalization Error Bound)](#3.2 泛化误差上界(Generalization Error Bound))
-
- 二分类问题的泛化误差上界
- [证明基础:Hoeffding 不等式(原式完整保留)](#证明基础:Hoeffding 不等式(原式完整保留))
- [4. 总结](#4. 总结)
监督学习(Supervised Learning)
监督学习其实很简单,核心就是用"带答案的数据"学规律,最终找到能精准预测新数据的模型。
它的核心方法可以总结为一个公式: 方法 = 模型 + 策略 + 算法 \boldsymbol{方法 = 模型 + 策略 + 算法} 方法=模型+策略+算法。
核心目标:找泛化能力最好的模型(简单说就是,不仅能做好"旧题",更能精准做"新题")
定模型:选一种"工具",要么是直接输出答案的决策函数(Y=f_θ(x)),要么是输出概率的概率模型(P_θ(Y|x))。
定损失:判断模型"答得对不对"的标准------分类题(比如判断猫/狗)用0-1损失(错1对0),回归题(比如预测房价)用平方损失(看预测值和真实值差多少),概率题用对数损失。
选策略:
- 样本多("练习题"够多):用经验风险最小化(ERM),直白说就是尽量让模型把现有练习题都做对。
- 样本少("练习题"不够):加正则化,用结构风险最小化(SRM),避免模型死记硬背"旧题",保证能应对"新题"。
评性能:看两个指标------训练误差(模型对"旧题"的拟合度)和测试误差(模型对"新题"的泛化能力),重点防止"过拟合"(只会背题,不会解题)。
保泛化:记住一个小技巧:样本越多、模型越简单,预测新数据的误差就越小。
最终:选结构风险最小的模型(既会做旧题,又能精准做新题)
1. 假设空间与模型
结合前文我们知道,监督学习的核心是找到合适的模型(三要素之一),而模型的选择,首先要明确「所有可能的模型范围」------这就是假设空间(hypothesis space):简单说,它包含了我们能想到的、所有可能用来拟合数据、预测答案的条件概率分布或决策函数。
1.1 模型的两种形式
我们常见的模型,主要分为以下两种(对应假设空间里的两类核心形式),具体区别和形式如下表所示:
| 模型类型 | 基本形式 | 参数化形式 |
|---|---|---|
| 决策函数模型 | F = { f ∣ Y = f ( x ) } \mathcal{F} = \{f \mid Y=f(x)\} F={f∣Y=f(x)} | F = { f ∣ Y = f θ ( x ) , θ ∈ R n } \mathcal{F} = \{f \mid Y=f_\theta(x), \theta \in \mathbb{R}^n\} F={f∣Y=fθ(x),θ∈Rn} |
| 条件概率模型 | F = { P ∣ P ( Y ∣ x ) } \mathcal{F} = \{P \mid P(Y \mid x)\} F={P∣P(Y∣x)} | F = { P ∣ P θ ( Y ∣ x ) , θ ∈ R n } \mathcal{F} = \{P \mid P_\theta(Y \mid x), \theta \in \mathbb{R}^n\} F={P∣Pθ(Y∣x),θ∈Rn} |
补充2个新手必懂的小解释:
- θ \theta θ:模型参数,就是我们训练模型时,需要不断调整的"关键参数"(比如前文说的"让模型变准的步骤",本质就是调整这个参数);
- R n \mathbb{R}^n Rn: n n n 维参数空间,简单理解为"所有可能的参数取值范围",我们的目标就是从这个范围里,找到最适合的参数 θ \theta θ。
2. 策略:损失函数与风险最小化
结合前文,我们确定了假设空间(所有可能的模型),接下来就要明确「怎么判断哪个模型最好」------这就是监督学习的策略。策略的核心很简单:先定义一个"评判标准"(损失函数),再基于这个标准衡量模型的整体表现(风险函数),最终选出"得分最高"(风险最小)的最优模型。
2.1 损失函数(Loss Function)
损失函数就是我们的「单次评判标准」,专门衡量模型一次预测的好坏 ,记为 L ( Y , f ( x ) ) L(Y, f(x)) L(Y,f(x))(决策函数模型)或 L ( Y , P ( Y ∣ x ) ) L(Y, P(Y \mid x)) L(Y,P(Y∣x))(概率模型)。
简单说:你让模型预测一次,把预测结果和真实答案对比,用损失函数算一个"误差值",值越小,说明这一次预测越准。常见的4种损失函数,对应不同任务,新手重点记"适用场景"即可:
- 0-1 损失函数 (0-1 Loss Function)------ 适用于分类任务(比如判断猫/狗、垃圾类别)
L ( Y , f ( x ) ) = { 1 , Y ≠ f ( x ) 0 , Y = f ( x ) L(Y,f(x))=\begin{cases} 1, & Y \neq f(x) \\ 0, & Y = f(x) \end{cases} L(Y,f(x))={1,0,Y=f(x)Y=f(x)
通俗解释:预测错了(Y≠f(x)),得1分(误差大);预测对了(Y=f(x)),得0分(误差小),简单直接。
- 平方损失函数 (Quadratic Loss Function)------ 适用于回归任务(比如预测房价、温度)
L ( Y , f ( x ) ) = ( Y − f ( x ) ) 2 L(Y,f(x))=(Y-f(x))^2 L(Y,f(x))=(Y−f(x))2
通俗解释:用"预测值和真实值的差的平方"来算误差,差值越大,误差值越大(比如预测房价差10万,误差就是100,惩罚更明显)。
- 绝对损失函数 (Absolute Loss Function)------ 适用于回归任务(对极端值更宽容)
L ( Y , f ( x ) ) = ∣ Y − f ( x ) ∣ L(Y,f(x))=|Y-f(x)| L(Y,f(x))=∣Y−f(x)∣
通俗解释:直接用"预测值和真实值的绝对值差"算误差,和平方损失比,极端值(比如预测错很多)带来的误差不会被放大。
- 对数损失函数 (Logarithmic Loss Function)------ 适用于概率模型(比如预测某件事发生的概率)
L ( Y , P ( Y ∣ x ) ) = − log P ( Y ∣ x ) L(Y,P(Y \mid x))=-\log P(Y \mid x) L(Y,P(Y∣x))=−logP(Y∣x)
通俗解释:预测的概率越接近真实结果(比如实际会发生,预测概率0.9),误差越小;越接近相反结果(比如实际会发生,预测概率0.1),误差越大。
核心结论:损失函数值越小,模型单次预测效果越好。
2.2 风险函数(Risk Function)
损失函数只能评判"单次预测",而我们需要的是「能稳定预测所有数据」的模型------这就需要风险函数,它衡量模型在所有数据(整体)上的平均预测好坏,是对模型整体表现的"综合打分"。
主要分为两种,新手重点理解"区别和用途",公式不用死记:
-
期望风险(Expected Risk)
模型关于所有数据(联合分布 P ( x , y ) P(x,y) P(x,y)) 的平均损失,是理论上的"最优打分"------相当于让模型做完所有可能的题目,算出的平均误差。
R e x p ( f ) = E P L ( Y , f ( x ) ) = ∫ X × Y L ( Y , f ( x ) ) P ( x , y ) d x d y \mathcal{R}_{exp}(f) = \mathbb{E}PL(Y,f(x)) = \int{X \times Y} L(Y,f(x)) P(x,y)dxdy Rexp(f)=EPL(Y,f(x))=∫X×YL(Y,f(x))P(x,y)dxdy
核心目标:我们最终想找的,就是期望风险最小的模型(理论上最完美的模型)。 -
经验风险(Empirical Risk)
现实中,我们不可能拿到"所有数据",只能用手头的训练数据(练习题)来近似计算期望风险------这就是经验风险,它是模型关于训练数据集 的平均损失。
R e m p ( f ) = 1 N ∑ i = 1 N L ( y i , f ( x i ) ) \mathcal{R}{emp}(f) = \frac{1}{N} \sum{i=1}^N L(y_i,f(x_i)) Remp(f)=N1i=1∑NL(yi,f(xi))
补充2个新手易懂的点:
- 当训练样本量 N N N 足够大(练习题足够多)时,经验风险会无限接近期望风险(相当于做的练习题越多,越能反映真实水平);
- 现实中样本量往往有限,要是直接用经验风险代替期望风险,模型容易"死记硬背练习题"(过拟合),遇到新题就不会做,所以需要矫正。
2.3 风险最小化准则
明确了损失函数和风险函数,接下来就是"怎么选最优模型"------核心是"最小化风险",主要有两种准则,对应不同样本量场景,衔接前文引言,新手容易理解:
(1)经验风险最小化(Empirical Risk Minimization, ERM)
核心逻辑:认为"在训练数据上表现最好(经验风险最小)的模型,就是最优模型" ,优化目标(不用死记,理解逻辑即可):
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( x i ) ) \min_{f \in \mathcal{F}} \frac{1}{N} \sum_{i=1}^N L(y_i,f(x_i)) f∈FminN1i=1∑NL(yi,f(xi))
- 适用场景:训练样本量 N N N 足够大时(比如有几万、几十万条数据),此时经验风险能很好地近似期望风险;
- 存在问题:当样本量 N N N 较小时(比如只有几十条数据),容易产生过拟合(模型死记硬背训练数据,不会应对新数据)。
(2)结构风险最小化(Structural Risk Minimization, SRM)
为了解决"过拟合"问题而提出,本质就是给模型"加约束"(正则化),不让它"死记硬背",在保证训练效果(经验风险小)的同时,让模型更简单,从而能应对新数据。
结构风险公式 (重点理解新增项的含义):
R s r m ( f ) = 1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f ) \mathcal{R}{srm}(f) = \frac{1}{N} \sum{i=1}^N L(y_i,f(x_i)) + \lambda J(f) Rsrm(f)=N1i=1∑NL(yi,f(xi))+λJ(f)
- J ( f ) J(f) J(f):正则化项,简单说就是"模型复杂度的惩罚分"------模型越复杂(比如死记硬背所有训练数据),这个惩罚分越高;
- λ ≥ 0 \lambda \geq 0 λ≥0:权衡系数,用来平衡"训练效果"和"模型复杂度"( λ \lambda λ 越大,越看重模型简单,越能防止过拟合);
- 核心逻辑 :SRM 认为,"经验风险小 + 模型简单"(结构风险最小)的模型,才是最优模型,优化目标:
min f ∈ F 1 N ∑ i = 1 N L ( y i , f ( x i ) ) + λ J ( f ) \min_{f \in \mathcal{F}} \frac{1}{N} \sum_{i=1}^N L(y_i,f(x_i)) + \lambda J(f) f∈FminN1i=1∑NL(yi,f(xi))+λJ(f)
2.4 训练误差与测试误差
我们平时判断模型好坏,常用的两个"直观指标",其实就是经验风险的具体应用,对应"做旧题"和"做新题"的能力,衔接前文核心目标(泛化能力):
(1)训练误差(Training Error)
就是模型关于训练数据集(旧题) 的平均损失,和经验风险本质一样,反映模型"记牢旧题"的能力:
R e m p ( f ^ ) = 1 N ∑ i = 1 N L ( y i , f ^ ( x i ) ) \mathcal{R}{emp}(\hat{f}) = \frac{1}{N} \sum{i=1}^N L(y_i,\hat{f}(x_i)) Remp(f^)=N1i=1∑NL(yi,f^(xi))
通俗说:训练误差越小,说明模型把"练习题"做得越好,但不代表能做好"新题"(可能是死记硬背)。
(2)测试误差(Test Error)
模型关于测试数据集(新题) 的平均损失,反映模型的"泛化能力"(做新题的能力),是我们判断模型实用价值的关键:
E t e s t = 1 N ′ ∑ i = 1 N ′ L ( y i , f ^ ( x i ) ) E_{test} = \frac{1}{N'} \sum_{i=1}^{N'} L(y_i,\hat{f}(x_i)) Etest=N′1i=1∑N′L(yi,f^(xi))
补充2个分类任务常用的衍生指标(0-1损失下,新手易理解):
- 测试误差(分类场景):就是模型预测错误的比例:
E t e s t = 1 N ′ ∑ i = 1 N ′ I ( y i ≠ f ^ ( x i ) ) E_{test} = \frac{1}{N'} \sum_{i=1}^{N'} I(y_i \neq \hat{f}(x_i)) Etest=N′1i=1∑N′I(yi=f^(xi)) - 测试准确率(分类场景):就是模型预测正确的比例,和测试误差互补(准确率越高,测试误差越小):
r t e s t = 1 N ′ ∑ i = 1 N ′ I ( y i = f ^ ( x i ) ) r_{test} = \frac{1}{N'} \sum_{i=1}^{N'} I(y_i = \hat{f}(x_i)) rtest=N′1i=1∑N′I(yi=f^(xi))
2.5 过拟合与正则化实例(多项式回归)
(1)M 次多项式模型(M-th Order Polynomial Model)
f M ( x , w ) = w 0 + w 1 x + w 2 x 2 + ⋯ + w M x M = ∑ i = 0 M w i x i f_M(x,w) = w_0 + w_1x + w_2x^2 + \dots + w_Mx^M = \sum_{i=0}^M w_i x^i fM(x,w)=w0+w1x+w2x2+⋯+wMxM=i=0∑Mwixi
| 符号 | 含义 | 新手通俗解释 |
|---|---|---|
| M M M | 多项式阶数(模型复杂度) | M M M 越大,模型越复杂、曲线越曲折; M = 0 M=0 M=0是水平线, M = 1 M=1 M=1是直线, M = 9 M=9 M=9是复杂高次曲线 |
| w i w_i wi | 多项式系数(模型参数) | 模型可调的"参数旋钮",通过训练数据学习得到,决定曲线形状 |
| f M ( x , w ) f_M(x,w) fM(x,w) | 模型预测值 | 输入 x x x,输出拟合结果,目标是贴近真实数据 y y y |
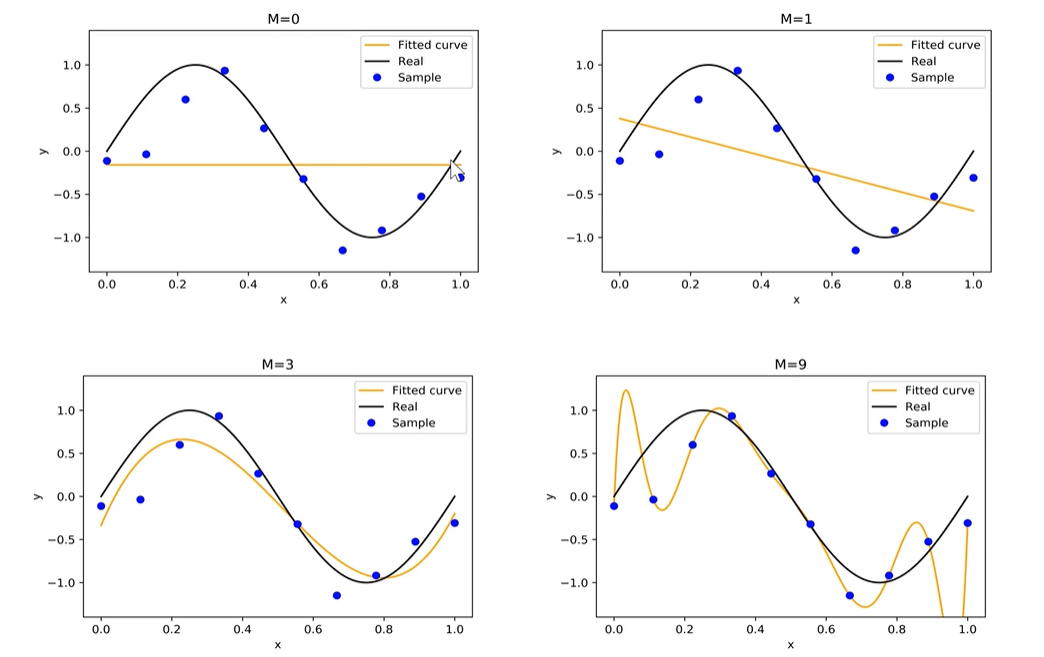
图表核心规律:
- M=0(常数):水平直线,抓不住数据趋势 → 欠拟合(模型太简单)
- M=1(一次直线):只能看大致趋势,拟合不了曲线变化 → 仍欠拟合
- M=3(三次多项式):贴合真实规律,不瞎波动 → 拟合最优、泛化能力强
- M=9(高次多项式):硬怼所有样本点、曲线乱晃 → 过拟合(死记数据、不学规律)
- M M M越小 → 模型越简单 → 容易欠拟合
- M M M越大 → 模型越复杂 → 容易过拟合
- 最优思路:选适中阶数,或用正则化限制模型乱复杂
(2)经验风险最小化(无正则化):过拟合的根源
平方损失下无正则化的经验风险:
L ( w ) = 1 2 ∑ i = 0 N ( ∑ j = 0 M w j x i j − y i ) 2 L(w) = \frac{1}{2} \sum_{i=0}^N \left( \sum_{j=0}^M w_j x_i^j - y_i \right)^2 L(w)=21i=0∑N(j=0∑Mwjxij−yi)2
通俗理解:
- 1 2 \frac12 21:纯数学化简用,不影响最终最优结果;
- 内层求和是模型预测值,减真实值再平方,统计整份训练数据的总误差;
- 模型为了把训练误差压到最低,阶数 M M M很高时会疯狂调大参数,把数据里的噪声、杂波也当成规律记住,最终造成严重过拟合。
--
(3)正则化:给过拟合「踩刹车」
正则化 = 在原有误差基础上,加一项模型复杂度惩罚,让模型:既要贴合数据,又不能太复杂。
① L2 正则化(岭回归)
L ( w ) = 1 N ∑ i = 1 N ( f ( x i ; w ) − y i ) 2 + λ 2 ∥ w ∥ 2 2 L(w) = \frac{1}{N} \sum_{i=1}^N (f(x_i;w)-y_i)^2 + \frac{\lambda}{2} \|w\|_2^2 L(w)=N1i=1∑N(f(xi;w)−yi)2+2λ∥w∥22
- ∥ w ∥ 2 2 = ∑ w j 2 \|w\|_2^2=\sum w_j^2 ∥w∥22=∑wj2:惩罚所有参数平方和;
- 效果:把参数整体缩小,曲线变平滑,抑制过拟合;参数不会变成0;
- λ \lambda λ越大,惩罚越重,太大会反过来造成欠拟合。
② L1 正则化(Lasso 回归)
L ( w ) = 1 N ∑ i = 1 N ( f ( x i ; w ) − y i ) 2 + λ ∥ w ∥ 1 L(w) = \frac{1}{N} \sum_{i=1}^N (f(x_i;w)-y_i)^2 + \lambda \|w\|_1 L(w)=N1i=1∑N(f(xi;w)−yi)2+λ∥w∥1
- ∥ w ∥ 1 = ∑ ∣ w j ∣ \|w\|_1=\sum |w_j| ∥w∥1=∑∣wj∣:惩罚参数绝对值之和;
- 效果:能把不重要特征的参数直接压成0,自动筛掉无用项,兼具正则化+特征选择。
③ 正则化核心对比
| 正则化类型 | 惩罚形式 | 核心效果 | 适用场景 |
|---|---|---|---|
| L2(岭回归) | 惩罚参数平方和 | 参数整体缩小、曲线平滑 | 保留所有特征,只单纯防过拟合 |
| L1(Lasso) | 惩罚参数绝对值和 | 部分参数归零、自动筛特征 | 数据特征多,需要精简模型 |
关键:
- λ = 0 \lambda=0 λ=0:等于没加正则,容易过拟合;
- λ \lambda λ过大:惩罚过头,模型变笨、出现欠拟合;
- 最优 λ \lambda λ一般靠交叉验证选出。
2.6 过拟合(Over-Fitting)通俗定义
模型太复杂,把训练数据背得滚瓜烂熟(训练误差极低),但看不懂新数据、预测新样本极差(测试误差很高);本质是记住了噪声,没学到真实规律。
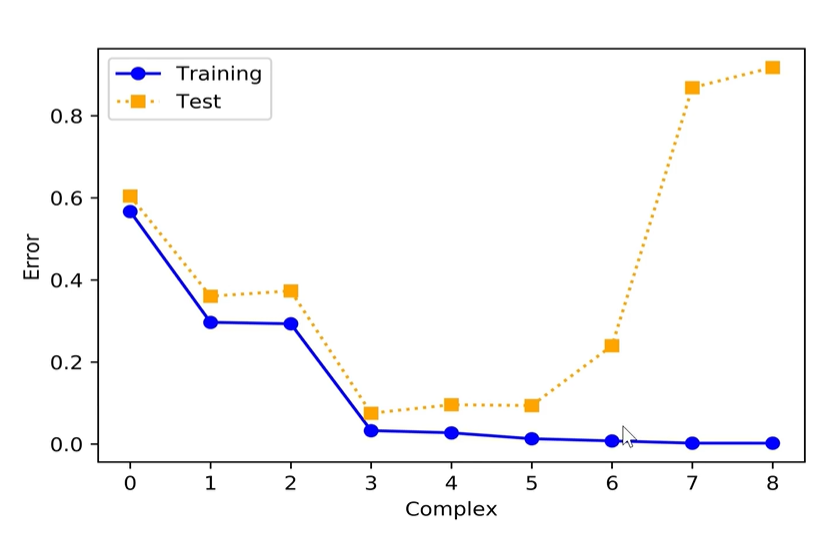
图表解读
- 蓝色训练误差:模型越复杂,误差一路走低,甚至趋近于0;
- 黄色测试误差:前期跟着降低,复杂度超标后快速飙升;
- 拐点之前:模型在学真实规律;拐点之后:模型在死记硬背训练数据。
3. 泛化误差与泛化误差上界
3.1 泛化误差(Generalization Error)
模型在未知数据 上的期望风险,是衡量模型泛化能力的核心指标:
R e x p ( f ^ ) = E P L ( Y , f \^ ( x ) ) = ∫ X × Y L ( y , f ^ ( x ) ) P ( x , y ) d x d y \mathcal{R}_{exp}(\hat{f}) = \mathbb{E}PL(Y,\\hat{f}(x)) = \int{X \times Y} L(y,\hat{f}(x)) P(x,y)dxdy Rexp(f^)=EPL(Y,f\^(x))=∫X×YL(y,f^(x))P(x,y)dxdy
严谨保留:该积分遍历全部输入、输出空间,依托真实全局概率分布 P ( x , y ) P(x,y) P(x,y),计算损失函数的数学期望,是泛化能力的理论真值。
通俗理解:你手里只有一套练习题(训练集),但泛化误差是把全世界所有同类题目都拿来测试,算出的平均错题率;这个数值才代表模型真正的实力,不是靠死记练习题刷出来的分数。
3.2 泛化误差上界(Generalization Error Bound)
泛化误差的概率上界,严格刻画经验风险 与真实期望风险之间的最大差距。
通俗理解:我们算不出真实的「全世界平均分」,就给它定一条最高不会超过的红线;真实误差一定低于这条红线,用来预判模型会不会翻车。
二分类问题的泛化误差上界
已知条件:
- 训练集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ... , ( x N , y N ) } T = \{(x_1,y_1),(x_2,y_2),\dots,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}, N N N 为样本量,独立同分布于 P ( X , Y ) P(X,Y) P(X,Y);
- X ∈ R n X \in \mathbb{R}^n X∈Rn, Y ∈ { − 1 , + 1 } Y \in \{-1,+1\} Y∈{−1,+1},损失为 0-1 损失;
- 假设空间 F = { f 1 , f 2 , ... , f d } \mathcal{F}=\{f_1,f_2,\dots,f_d\} F={f1,f2,...,fd}, d d d 为函数个数。
通俗理解:就是最简单的二选一分类(比如正/负、猫/狗),对错只记 0 0 0 和 1 1 1;同时划定所有可选模型的集合,一共 d d d 种候选。
核心数学结论 :
对 ∀ f ∈ F \forall f \in \mathcal{F} ∀f∈F,至少以概率 1 − δ 1-\delta 1−δ( 0 < δ < 1 0<\delta<1 0<δ<1)满足:
R ( f ) ≤ R ^ ( f ) + ε ( d , N , δ ) \mathcal{R}(f) \leq \hat{\mathcal{R}}(f) + \varepsilon(d,N,\delta) R(f)≤R^(f)+ε(d,N,δ)
其中,泛化误差上界:
ε ( d , N , δ ) = 1 2 N ( log d + log 1 δ ) \varepsilon(d,N,\delta) = \sqrt{\frac{1}{2N} \left( \log d + \log \frac{1}{\delta} \right)} ε(d,N,δ)=2N1(logd+logδ1)
通俗理解:
真实考试误差 ≤ \le ≤ 平时刷题误差 + + + 安全浮动余量 ε \varepsilon ε
只要置信水平设为 1 − δ 1-\delta 1−δ,这个结论大概率成立。
严谨解读:
- 真实泛化误差 R ( f ) \mathcal{R}(f) R(f) 由两部分构成:训练集拟合误差 R ^ ( f ) \hat{\mathcal{R}}(f) R^(f) + + + 统计波动余项 ε \varepsilon ε;
- ε ∝ 1 N \varepsilon \propto \dfrac{1}{\sqrt{N}} ε∝N 1: ε \varepsilon ε 是 N N N 的单调递减函数,样本量 N N N 越大,泛化上界越紧致;
- ε ∝ log d \varepsilon \propto \sqrt{\log d} ε∝logd : ε \varepsilon ε 随假设空间规模 d d d 对数增长,模型集合越复杂,泛化容错上限越高,过拟合风险越大。
通俗补充:
① 样本越多( N N N 变大),刷题量充足,训练分数越贴近真实水平,浮动红线变小;
② 可选模型越多、结构越复杂( d d d 变大),模型容易死记训练数据,只能拉高误差红线兜底,更容易过拟合。
证明基础:Hoeffding 不等式(原式完整保留)
P X ˉ − E ( X ˉ ) ≥ t ≤ exp ( − 2 N 2 t 2 ∑ i = 1 n ( b i − a i ) 2 ) P\\bar{X}-\\mathbb{E}(\\bar{X}) \\geq t \leq \exp \left( -\frac{2N^2 t^2}{\sum_{i=1}^n (b_i - a_i)^2} \right) PXˉ−E(Xˉ)≥t≤exp(−∑i=1n(bi−ai)22N2t2)
通俗理解:这是概率论的误差约束工具------保证「样本平均分」不会离谱偏离「真实平均分」,把随机波动锁在可控范围里。
严格推导关键步骤(数学链路完整):
- 令逐样本损失随机变量: X i = L ( y i , f ( x i ) ) X_i = L(y_i,f(x_i)) Xi=L(yi,f(xi)),则样本均值 X ˉ = R ^ ( f ) \bar{X} = \hat{\mathcal{R}}(f) Xˉ=R^(f),数学期望 E ( X ˉ ) = R ( f ) \mathbb{E}(\bar{X}) = \mathcal{R}(f) E(Xˉ)=R(f);
通俗:把每一道题的对错看成一个随机值,刷题平均分就是经验误差,全局平均分就是真实泛化误差。
- 0-1 损失满足有界性 X i ∈ 0 , 1 X_i \in 0,1 Xi∈0,1,代入 Hoeffding 不等式化简得:
P ( R ( f ) − R ^ ( f ) ≥ ε ) ≤ exp ( − 2 N ε 2 ) P(\mathcal{R}(f)-\hat{\mathcal{R}}(f) \geq \varepsilon) \leq \exp(-2N\varepsilon^2) P(R(f)−R^(f)≥ε)≤exp(−2Nε2)
通俗:对错只有 0 0 0/ 1 1 1,取值范围固定,就能把「真实误差比训练误差大很多」的概率压得极低。
- 对有限假设空间全体函数取联合界 ,置置信参数: δ = d exp ( − 2 N ε 2 ) \delta = d \exp(-2N\varepsilon^2) δ=dexp(−2Nε2),等价变形解得:
ε = 1 2 N ( log d + log 1 δ ) \varepsilon = \sqrt{\frac{1}{2N} \left( \log d + \log \frac{1}{\delta} \right)} ε=2N1(logd+logδ1)
通俗:给所有候选模型统一兜底,算出最终的安全余量 ε \varepsilon ε,保证整组模型在大概率下泛化误差不超红线。
4. 总结
监督学习核心逻辑:明确模型范围→定义评判标准→找到最优模型→保证泛化能力。
核心脉络
-
三要素:方法 = 模型 + 策略 + 算法
- 模型:从假设空间选择,分决策函数( Y = f θ ( x ) Y=f_\theta(x) Y=fθ(x))和条件概率模型( P θ ( Y ∣ x ) P_\theta(Y|x) Pθ(Y∣x));
- 策略:以损失函数定评判标准,通过ERM(样本多)、SRM(样本少+正则化)选最优模型;
- 算法:实现风险最小化的具体步骤。
-
关键概念
- 损失函数:单次预测误差(分类→0-1损失,回归→平方损失,概率模型→对数损失);
- 泛化误差:未知数据上的真实误差,泛化误差上界约束其与训练误差的差距;
- 欠拟合/过拟合:前者提升模型复杂度,后者通过L1/L2正则化或增样本缓解。
终极结论
监督学习本质是在假设空间中,找到结构风险最小的模型,兼顾训练拟合度与未知数据泛化能力,为后续具体模型学习奠定理论基础。