前言
本集探究langchain官网的SQL Agent案例,这是掌握 AI Agent 落地场景的关键一步,这个官方教程展示了一个具有自我纠错能力和多步推理能力的完整闭环。
官网示例链接:https://docs.langchain.com/oss/python/langchain/sql-agent

理解
官网给出了8 个步骤
1.Fetch the available tables and schemas from the database
2.Decide which tables are relevant to the question
3.Fetch the schemas for the relevant tables
4.Generate a query based on the question and information from the schemas
5.Double-check the query for common mistakes using an LLM
6.Execute the query and return the results
7.Correct mistakes surfaced by the database engine until the query is successful
8.Formulate a response based on the results
我们将其拆解为三个核心阶段
第一阶段:环境感知与上下文构建(Steps 1-3)
-
获取表名与 Schema: Agent 调用
SQLDatabase工具查看库里有哪些表(如users,orders)。 -
筛选相关表: 如果你的问题是"上个月销售额是多少?",Agent 会意识到
users表可能没用,从而缩小关注范围,节省 Token。 -
深度读取: 仅针对相关的表,获取详细的列名、数据类型和示例数据(Sample Rows)。这是为了让 LLM 明白
price是DECIMAL还是INT。
第二阶段:策略生成与质量控制 (Steps 4-5)
-
生成查询: 结合问题和 Schema,LLM 编写 SQL。
-
静态检查 (Self-Correction): 这是一个巧妙的设计。Agent 会再次调用 LLM 扮演"高级 DBA",检查是否存在语法错误、拼写错误或漏掉的 Join 条件。这在复杂的嵌套查询中非常有效。
第三阶段:执行、容错与总结 (Steps 6-8)
-
尝试执行: 将 SQL 发送到数据库。
-
循环纠错 (Re-act Loop): * 如果数据库报错(例如
Column 'name' not found),Agent 不会直接把错误扔给用户。它会阅读错误信息,意识到自己可能写错了字段名,然后回到第 3 步重新看 Schema,再次生成 SQL。这个过程会循环直到成功或达到重试上限。 -
人类语言总结: Agent 拿到类似
[(500.0,)]的结果后,会翻译成:"上个月的销售总额是 500 元。"
编码及说明
先贴上完整代码,下面将会对每一步的作用作出详细解释:
python
# 初始化模型
from langchain_openai import ChatOpenAI
kimi_model = ChatOpenAI(
model="kimi-k2.5",
api_key="sk-uQ***",
base_url="https://api.moonshot.cn/v1",
# 重点:这里严格对应 Kimi 的 API 结构
extra_body={
"thinking": {"type": "disabled"}
}
)
# 准备了数据源
import requests, pathlib
url = "https://storage.googleapis.com/benchmarks-artifacts/chinook/Chinook.db"
local_path = pathlib.Path("Chinook.db")
if local_path.exists():
print(f"{local_path} already exists, skipping download.")
else:
response = requests.get(url)
if response.status_code == 200:
local_path.write_bytes(response.content)
print(f"File downloaded and saved as {local_path}")
else:
print(f"Failed to download the file. Status code: {response.status_code}")
# 连接数据库
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(f"Dialect: {db.dialect}")
print(f"Available tables: {db.get_usable_table_names()}")
print(f'Sample output: {db.run("SELECT * FROM Artist LIMIT 5;")}')
# 配置工具箱
from langchain_community.agent_toolkits import SQLDatabaseToolkit
# Toolkit 是 LangChain 的一种组织方式,它把一组相关的工具(比如查表名、查结构、跑 SQL)打包在一起。这比你手动一个一个去定义工具要高效得多。
toolkit = SQLDatabaseToolkit(db=db, llm=kimi_model)
# 告诉工具箱要操作哪个数据库,工具箱需要哪个模型
tools = toolkit.get_tools()
for tool in tools:
print(f"{tool.name}: {tool.description}\n") #遍历并打印每个工具的名称和描述
# 创建 Agent
# 针对 Kimi 优化的中文系统提示词
system_prompt_zh = """你是一个专门负责与 SQL 数据库交互的 AI 助手。
你的目标是根据用户提出的问题,构建语法正确的 {dialect} 查询语句并执行,最后根据查询结果给出准确的回答。
### 核心规则:
1. **限制结果数量**:除非用户明确要求获取更多数据,否则请务必将查询结果限制在最多前 {top_k} 条(使用 LIMIT 语句)。
2. **精简字段**:不要使用 SELECT *。根据问题只查询必要的列,以节省性能。
3. **结果排序**:根据相关列对结果进行排序,以便返回数据库中最具代表性的数据。
4. **双重检查**:在执行查询之前,必须仔细检查 SQL 语法。如果执行报错,请根据错误信息重新编写并重试。
5. **只读权限**:严禁执行任何 DML 语句(如 INSERT, UPDATE, DELETE, DROP 等)修改数据库。
### 执行流程:
1. **首先**,你必须先查看数据库中的所有表名,了解你可以查询的内容。**严禁跳过此步骤。**
2. **接着**,针对与问题最相关的表,查询其具体的 Schema(表结构)和示例数据。
3. **最后**,基于获取的结构信息生成并执行 SQL。
""".format(
dialect=db.dialect,
top_k=5,
)
# 创建 SQL Agent
# 注意:这里我们直接把中文系统提示词传进去
from langchain.agents import create_agent
agent = create_agent(
kimi_model,
tools,
system_prompt=system_prompt_zh
)
# 2. 运行官方的流式循环
question = "哪个音乐类型的平均歌曲长度最长?"
for step in agent.stream(
{"messages": [{"role": "user", "content": question}]},
stream_mode="values",
):
# 这样你会看到 Kimi 调用工具、获取结果、最后回答的全过程
step["messages"][-1].pretty_print()第一步:初始化模型以及数据源
初始化模型的操作,我们在学习过程中已经说了无数次了,这里不做过多赘述。
数据源准备的操作,就是去下载了官方提供的一个Chinook 数据库(这是一个模拟音像店业务的示例库,包含歌手、专辑、账单等表,结构非常适合练手)。判断了如果它存在本地,则跳过下载。你也可以提前手动下载好放在本地运行路径下,代码运行的时候就不会再去下载了。
python
# 初始化模型
from langchain_openai import ChatOpenAI
kimi_model = ChatOpenAI(
model="kimi-k2.5",
api_key="sk-uQ***",
base_url="https://api.moonshot.cn/v1",
# 重点:这里严格对应 Kimi 的 API 结构
extra_body={
"thinking": {"type": "disabled"}
}
)
# 准备了数据源
import requests, pathlib
url = "https://storage.googleapis.com/benchmarks-artifacts/chinook/Chinook.db"
local_path = pathlib.Path("Chinook.db")
if local_path.exists():
print(f"{local_path} already exists, skipping download.")
else:
response = requests.get(url)
if response.status_code == 200:
local_path.write_bytes(response.content)
print(f"File downloaded and saved as {local_path}")
else:
print(f"Failed to download the file. Status code: {response.status_code}")第二步:配置数据库以及连接工具箱
连接SQLite数据库的操作我们以前也说过了,不再过多说明。
这里从 LangChain 的社区库中导入 SQL 工具箱类,Toolkit 是 LangChain 的一种组织方式,它把一组相关的工具(比如查表名、查结构、跑 SQL)打包在一起。这比你手动一个一个去定义工具要高效得多。
我们从工具箱里"取出"具体的工具列表,并打印每个工具的名称和描述。
python
# 连接数据库
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(f"Dialect: {db.dialect}")
print(f"Available tables: {db.get_usable_table_names()}")
print(f'Sample output: {db.run("SELECT * FROM Artist LIMIT 5;")}')
# 配置工具箱
from langchain_community.agent_toolkits import SQLDatabaseToolkit
# Toolkit 是 LangChain 的一种组织方式,它把一组相关的工具(比如查表名、查结构、跑 SQL)打包在一起。这比你手动一个一个去定义工具要高效得多。
toolkit = SQLDatabaseToolkit(db=db, llm=kimi_model)
# 告诉工具箱要操作哪个数据库,工具箱需要哪个模型
tools = toolkit.get_tools()
for tool in tools:
print(f"{tool.name}: {tool.description}\n") #遍历并打印每个工具的名称和描述第三步,创建agent以及运行
官方给的提示词是英文的,我使用的是kimi的大模型,所以我把我的提示词写成了中文。
创建create_agent这个功能,我们之前章节也讲过了,不做多的赘述,主要就是将上一步的SQL 工具箱类放了进去。
因为我们知道数据库里都是模拟音像店业务的数据,所以问了个问题:哪个音乐类型的平均歌曲长度最长?
python
# 创建 Agent
# 针对 Kimi 优化的中文系统提示词
system_prompt_zh = """你是一个专门负责与 SQL 数据库交互的 AI 助手。
你的目标是根据用户提出的问题,构建语法正确的 {dialect} 查询语句并执行,最后根据查询结果给出准确的回答。
### 核心规则:
1. **限制结果数量**:除非用户明确要求获取更多数据,否则请务必将查询结果限制在最多前 {top_k} 条(使用 LIMIT 语句)。
2. **精简字段**:不要使用 SELECT *。根据问题只查询必要的列,以节省性能。
3. **结果排序**:根据相关列对结果进行排序,以便返回数据库中最具代表性的数据。
4. **双重检查**:在执行查询之前,必须仔细检查 SQL 语法。如果执行报错,请根据错误信息重新编写并重试。
5. **只读权限**:严禁执行任何 DML 语句(如 INSERT, UPDATE, DELETE, DROP 等)修改数据库。
### 执行流程:
1. **首先**,你必须先查看数据库中的所有表名,了解你可以查询的内容。**严禁跳过此步骤。**
2. **接着**,针对与问题最相关的表,查询其具体的 Schema(表结构)和示例数据。
3. **最后**,基于获取的结构信息生成并执行 SQL。
""".format(
dialect=db.dialect,
top_k=5,
)
# 创建 SQL Agent
from langchain.agents import create_agent
agent = create_agent(
kimi_model,
tools,
system_prompt=system_prompt_zh
)
# 2. 运行官方的流式循环
question = "哪个音乐类型的平均歌曲长度最长?"
for step in agent.stream(
{"messages": [{"role": "user", "content": question}]},
stream_mode="values",
):
# 这样你会看到 Kimi 调用工具、获取结果、最后回答的全过程
step["messages"][-1].pretty_print()运行结果详解
运行了之后打印了非常多的内容,我们一步一步分析
第一步:
输出显示,我们数据库已存在,跳过了下载。
然后打印了数据库的一些信息。

第二步:
这是我们在配置工具箱时,打印了它的工具列表。
sql_db_list_tables:只返回表名。Agent 第一步通常先调用它,看看库里有哪些表,避免一次性读取所有 Schema 导致上下文过长(Token 溢出)。
sql_db_schema:传入表名,返回该表的 CREATE TABLE 语句和前几行示例数据。这是 Agent 写出准确 SQL 的核心依据。
sql_db_query:真正去数据库执行 SQL 的工具。如果执行报错,它会返回错误信息(Traceback),Agent 看到报错后会尝试修复。
sql_db_query_checker:这是一个"防错层"。在执行之前,Agent 会把生成的 SQL 丢给这个工具,检查是否有 SQLite 不支持的语法或常见的逻辑漏洞。

第三步:
下面就是我们发送问题之后的大模型的完整返回了,我们一步步看:

这是程序发送给大模型的问题。

AI开始思考,得出结论要用tool去看表名,调用sql_db_list_tables工具。

sql_db_list_tables工具返回了表名给AI。

AI根据表名推测出要去看哪些张表,并且决定用什么工具。
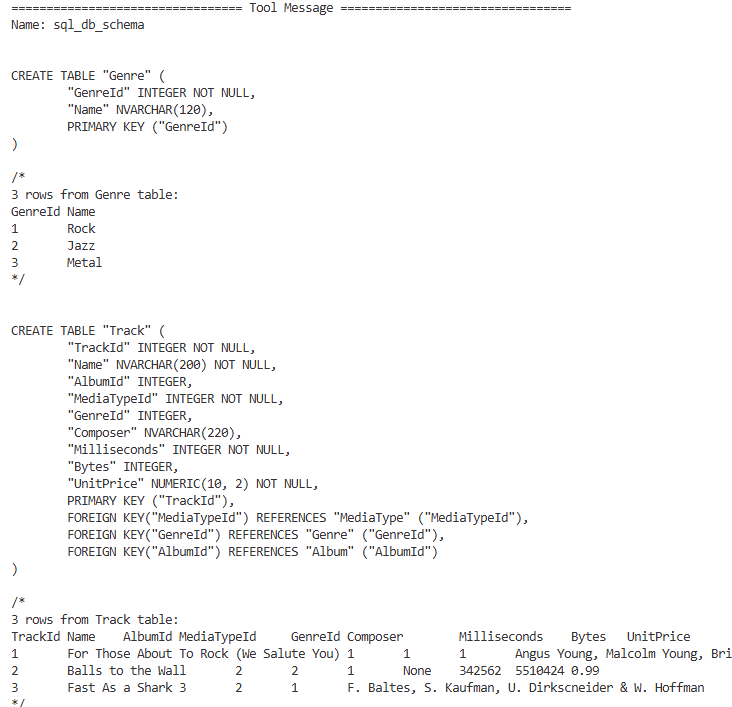
AI使用工具获得这两张表的结构。

AI拿到了表结构信息后,开始思考使用什么工具去获得歌曲长度

AI进行了一系列的调整,将SQL语句改正确了。

AI反复执行SQL,获取到了数据。

AI最终返回结果长度信息。
总结
本课我们通过 LangChain 的 SQL Agent 实现了从"自然语言"到"数据库自愈查询"的自动化闭环,理解了模型如何利用工具自主感知 Schema 并修正错误;而在下一课中,我们将打破这种"全自动"模式,引入核心的 Human-in-the-loop(人在回路) 机制,探索如何在 Agent 执行关键 SQL 或高风险操作前接入人工审核,实现 AI 效率与人类经验的完美协作。