前言
上一集解读了官方提供的SQL Agent的demo,这一集跟着官方的文档进入了 Agent 落地最核心的安全课题:Human-in-the-loop (HITL, 人在回路)。
在处理数据库(尤其是生产环境)时,AI 可能会生成效率极低、消耗资源巨大,甚至带有潜在风险的 SQL。引入"人在回路"机制,本质上是在 Agent 的"思考"与"执行"之间加了一个人工审批按钮。
官方文档中的位置如下:
编码
我们沿用上一集的代码,只修改核心创建agent的部分
python
# 创建 SQL Agent
# 1. 使用 LangGraph 方式创建 Agent (替代之前的 create_sql_agent)
# 注意:这里我们直接把中文系统提示词传进去
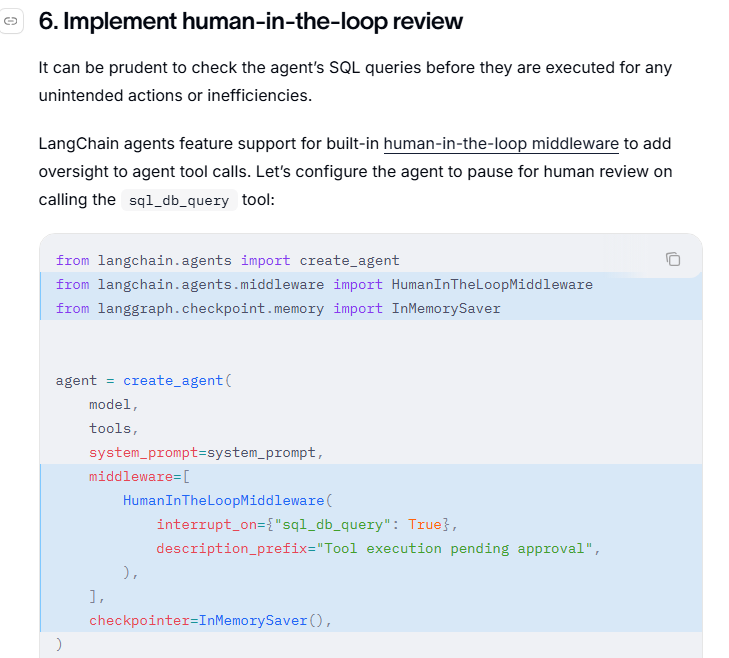
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
# 配置拦截中间件
middleware = [
HumanInTheLoopMiddleware(
# 只针对执行 SQL 的工具进行拦截
interrupt_on={"sql_db_query": True},
description_prefix="[安全审计] 准备执行 SQL,请审核"
)
]
agent = create_agent(
kimi_model,
tools,
system_prompt=system_prompt_zh ,
middleware=middleware,
checkpointer=InMemorySaver(), # 必须提供存储,否则无法在中断后恢复
)
# 2. 运行官方的流式循环
question = "哪个音乐类型的平均歌曲长度最长?"
config = {"configurable": {"thread_id": "1"}}
for step in agent.stream(
{"messages": [{"role": "user", "content": question}]},
config,
stream_mode="values",
):
if "__interrupt__" in step:
print("INTERRUPTED:")
interrupt = step["__interrupt__"][0]
for request in interrupt.value["action_requests"]:
print(request["description"])
elif "messages" in step:
step["messages"][-1].pretty_print()
else:
pass
from langgraph.types import Command
for step in agent.stream(
Command(resume={"decisions": [{"type": "approve"}]}),
config,
stream_mode="values",
):
if "messages" in step:
step["messages"][-1].pretty_print()
elif "__interrupt__" in step:
print("INTERRUPTED:")
interrupt = step["__interrupt__"][0]
for request in interrupt.value["action_requests"]:
print(request["description"])
else:
pass1. 配置刹车:中间件与存档点
定义了HumanInTheLoopMiddleware,规则是Agent 想要调用 sql_db_query 工具(即真正去跑 SQL),中间件就会强行挂起程序。
InMemorySaver:这是 Agent 的存档,之前内容详解过,不做过多赘述。
python
# 配置拦截中间件
middleware = [
HumanInTheLoopMiddleware(
interrupt_on={"sql_db_query": True}, # 核心:只拦截执行 SQL 的动作
description_prefix="[安全审计] 准备执行 SQL,请审核"
)
]
agent = create_agent(
# ...
middleware=middleware,
checkpointer=InMemorySaver(), # 存档点:没有它,Agent 停下后就"失忆"了
)2. 触发拦截:第一次运行循环
thread_id:告诉 InMemorySaver 当前的"进度"
python
config = {"configurable": {"thread_id": "1"}} # 存档位 ID
for step in agent.stream(
{"messages": [{"role": "user", "content": question}]},
config,
stream_mode="values",
):
if "__interrupt__" in step:
# 捕获拦截信号
interrupt = step["__interrupt__"][0]
# 打印 Agent 打算干什么(即生成的 SQL 描述)
for request in interrupt.value["action_requests"]:
print(request["description"])
elif "messages" in step:
step["messages"][-1].pretty_print()"__interrupt__" in step:当 Agent 跑到 sql_db_query 这一步时,循环会检测到这个信号。此时 Agent 会停止思考,程序进入 if 分支,打印出 AI 刚刚写好的、还没运行的 SQL。
3. 人工放行:第二次运行循环
Command(resume=...):这是**"唤醒指令"**。它告诉 Agent:"我看过了,你刚才写的 SQL 没问题,现在去执行吧(type: approve)。"
python
from langgraph.types import Command
for step in agent.stream(
# 发送一个"批准"命令,唤醒挂起的 Agent
Command(resume={"decisions": [{"type": "approve"}]}),
config, # 必须带上 thread_id: "1",否则找不到之前的存档
stream_mode="values",
):
# 恢复运行后的处理逻辑
if "messages" in step:
step["messages"][-1].pretty_print()结果解读
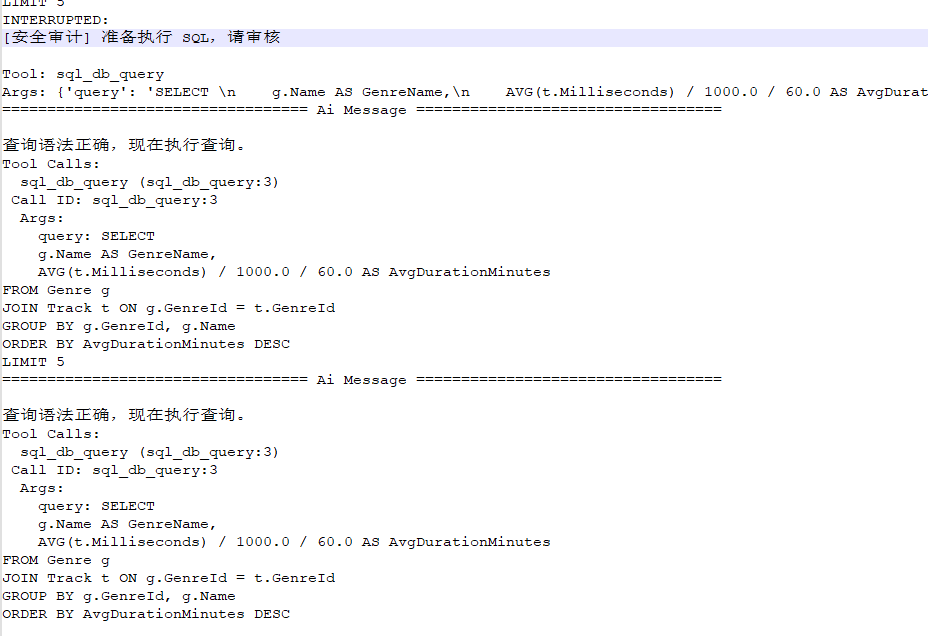
当我们运行这段代码的时候,前期的输出和上一集的一致,

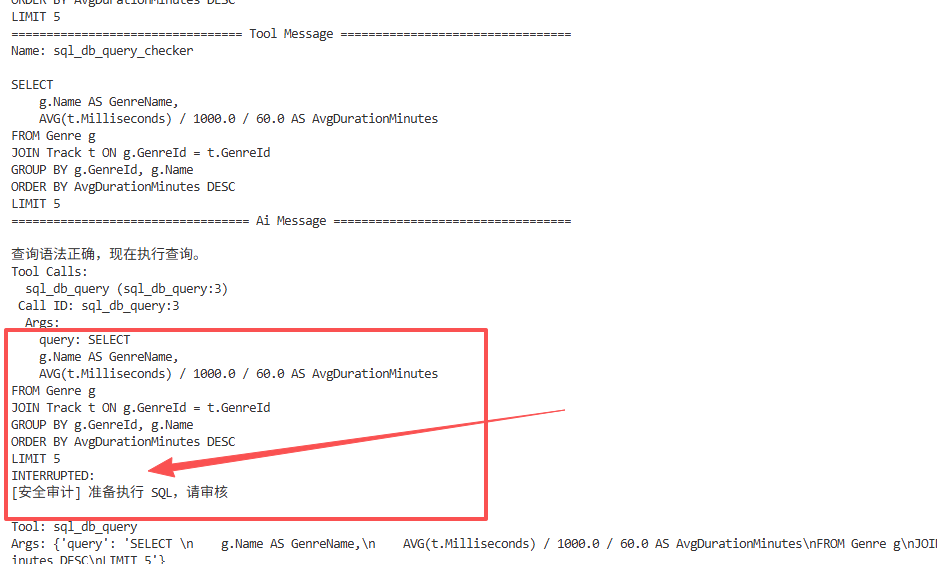
直到第一次AI准备好了sql语句,即将使用sql_db_query这个工具去执行的时候,停住了,需要确认,而在我们给了approve信号后,它接下去执行sql,并整理结果了。
在我们的middleware 配置中,有一行核心定义: interrupt_on={"sql_db_query": True}
这意味着 Agent 在整个任务执行过程中,只有在伸手去碰数据库写权限/查询工具(即调用 sql_db_query)时,系统才会强行拉下闸门。
之前的步骤: Agent 调用 sql_db_list_tables 查看表名、调用 sql_db_schema 查看结构。这些都是"只读"且"低风险"的探测行为,所以系统没有拦截,流程顺滑通过。
拦截点: 当 Agent 准备好 SQL 语句,正式发起 sql_db_query 请求时,中间件识别到了匹配动作,于是立刻触发 INTERRUPTED。
在屏幕上看到 INTERRUPTED 时,程序实际上已经运行完了第一个 for 循环。此时进程并没有结束,它只是退出了第一个循环。
状态已存档:由于你配置了 InMemorySaver,AI 的这条 SELECT 语句和当前的上下文已经保存在了 thread_id: "1" 对应的内存块里。
等待指令:直到你运行下半段代码(发送 Command(resume=...)),Agent 才会重新"活"过来,跳过拦截器去执行 SQL。
如果日志里出现了多次INTERRUPTED的打印,那也是可能发生的,因为可能会发生:AI 第一次执行 SQL 失败了(比如语法错),它会尝试修复并再次调用 sql_db_query。因为那是第二次调用工具,所以会再次触发拦截。这在生产环境中非常有意义------每一次写操作,人类都必须过目。
总结
在日志中我们清晰地看到,Agent 的自动化流程在涉及核心数据查询的 sql_db_query 环节精准'刹车'。这种设计确保了 AI 既能利用强大的推理能力完成复杂的 SQL 逻辑编写(如多表 Join 和聚合计算),又将最终的'扣动板机'权牢牢掌握在人类手中。