MatAnyone2 深度解析:视频抠图 SOTA 模型详解
GitHub 地址: https://github.com/pq-yang/MatAnyone2
MatAnyone2 是近期提出的视频抠图(Video Matting)深度学习模型。它属于计算机视觉领域中"前景分离/Alpha Matting"的研究方向,主要用于从视频中精确提取人物或物体。
核心亮点
即使是头发丝、半透明区域等细节,也能完美保留。
一、MatAnyone2 是什么?
源自论文《MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator》。
它的核心目标非常明确:
- 高质量:真实视频中的抠图效果更细腻。
- 高稳定:尤其在长视频中,保持帧间一致性。
二、它解决了什么痛点?
传统视频抠图方法往往面临三大难题:
- 数据不足:高质量数据集稀缺,精细 Alpha Matte 标注成本极高。
- 边界细节差:很多方法更像"分割",头发、烟雾、透明物体处理不好。
- 长视频不稳定:帧间闪烁严重,目标外观变化大时容易"崩"。
三、核心创新点(划重点)
1. MQE:Matting Quality Evaluator(质量评估器)
这是 MatAnyone2 的最大亮点。
-
功能:在**没有真值 (GT)**的情况下,判断抠图结果"哪里好 / 哪里错"。
-
输出:一个像素级质量图 (Quality Map)。
-
作用 :
- 训练时:抑制错误区域。
- 数据筛选:挑选高质量样本。
-
本质:让模型"自己评估自己"。
2. 大规模数据构建 (VMReal)
通过 MQE 自动筛选 + 融合多个模型结果,构建了新数据集:
- 名称:VMReal
- 规模:约 2.8 万视频,共 240 万帧。
- 意义:大幅提升了模型的泛化能力。
3. 长程参考帧训练 (Reference-frame training)
- 传统方法:只看局部帧(短窗口)。
- MatAnyone2:引入"远距离参考帧"。
- 作用:更好处理外观变化、遮挡及长视频一致性。
四、效果与性能对比
论文结果显示,MatAnyone2 在多个 Benchmark 上达到 SOTA(最先进)。
| 维度 | 旧方法 | MatAnyone2 |
|---|---|---|
| 边界精细度 | ⭐⭐ (头发/透明处理弱) | ⭐⭐⭐⭐⭐ (细节丰富) |
| 视频稳定性 | ⭐⭐⭐ (易闪烁) | ⭐⭐⭐⭐⭐ (帧间一致) |
| 真实场景 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
五、MatAnyone → MatAnyone2 的进化
- MatAnyone:基础视频抠图模型。
- MatAnyone2:+ MQE + 大规模数据 + 长程建模。
- 本质升级:从单纯的"模型优化"升级为"数据 + 训练机制全面升级"。
六、应用场景
- 视频背景替换:替代绿幕,无需专业设备。
- 短视频/直播:实时抠人像,特效更自然。
- VFX 特效制作:电影级细节提取。
- 虚拟人/数字人:驱动更流畅的 Avatar。
- AR/视频会议:沉浸式背景虚化或替换。
七、懒人包使用指南
MatAnyone2 更新仅一两周左右,官方提供了同时支持 MatAnyone 和 MatAnyone2 的离线包,界面为 WebUI。
- 下载:点击此处网盘下载(链接见原文)。
- 启动 :双击
start_offline.bat。 - 等待:等待终端启动完成。
- 操作:打开网址,选择视频,添加遮罩,获取绿幕和透明通道结果。
八、一句话总结
MatAnyone2 = 一个用"自评估 + 大数据 + 长程建模"提升的视频抠图 SOTA 模型。
懒人包使用
双击start_offline.bat
等待终端启动完成
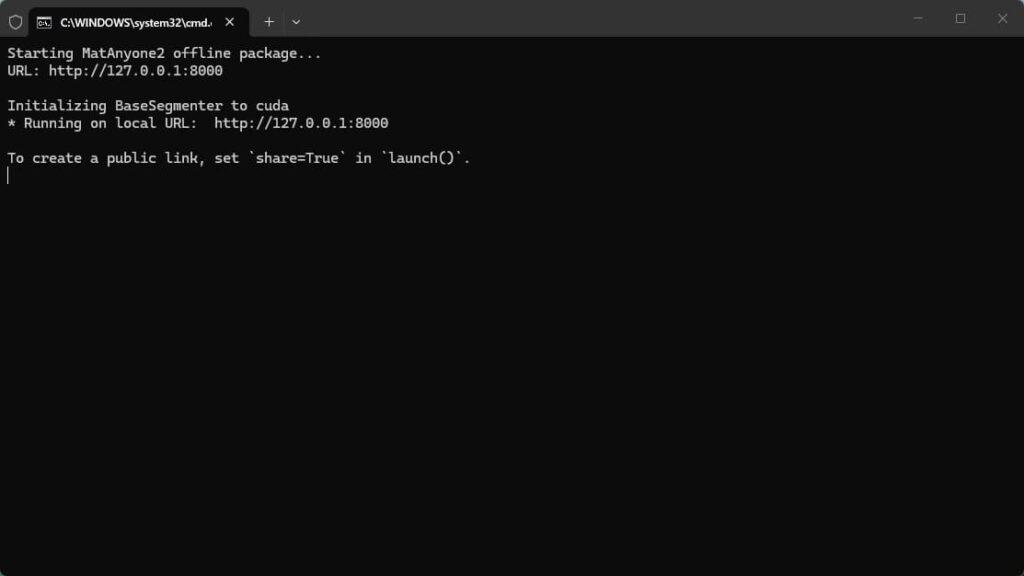
打开网址,选择视频,添加遮罩,获取绿幕和透明通道结果
Tips
点击此处 网盘下载
MatAnyone2才更新一两周左右
这个懒人包同时可以使用MatAnyone 和MatAnyone2,界面为官方提供的webui