前言
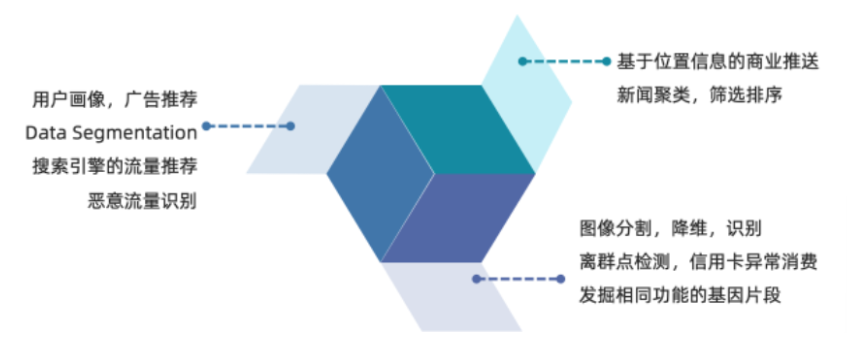
聚类算法在现实中可以应用于用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别,基于位置信息的商业推送,新闻聚类,筛选排序,图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段,今天我们来学习一下聚类算法!
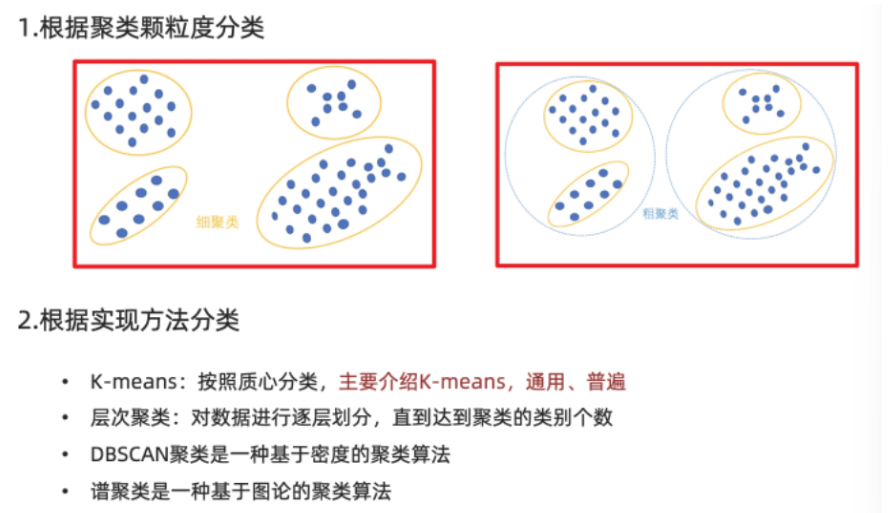
一、分类
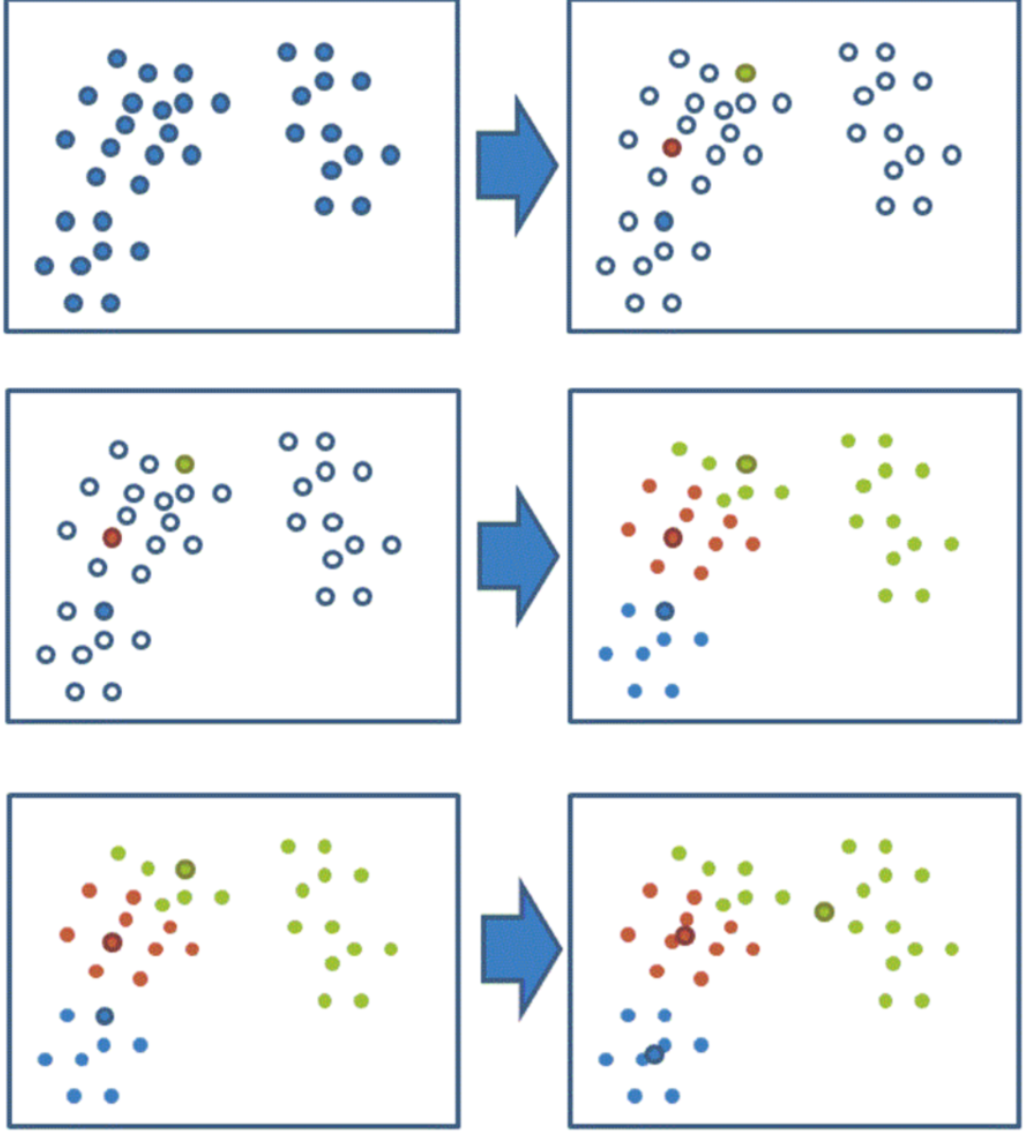
二、K-means算法流程
1、随机设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
案例分析
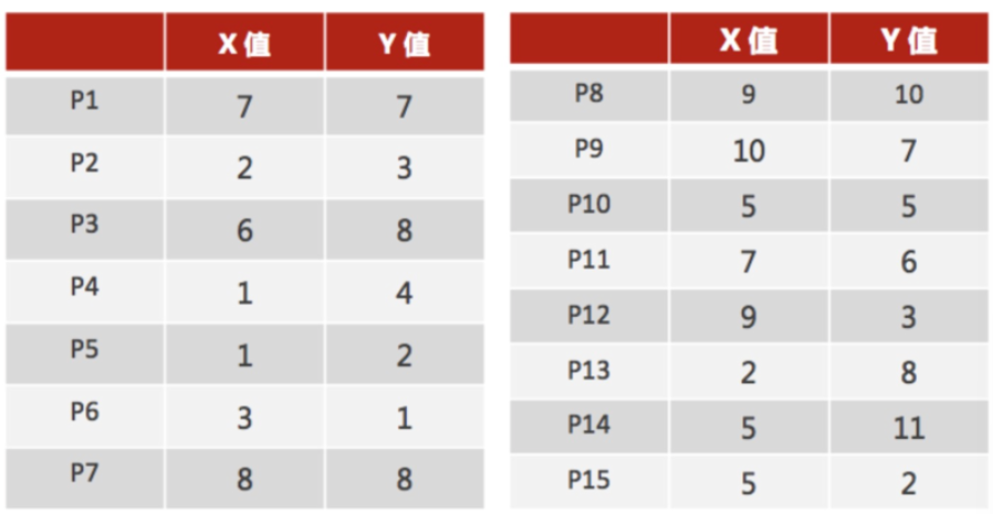
1、随机设置K个特征空间内的点作为初始的聚类中心(本案例中设置p1和p2)
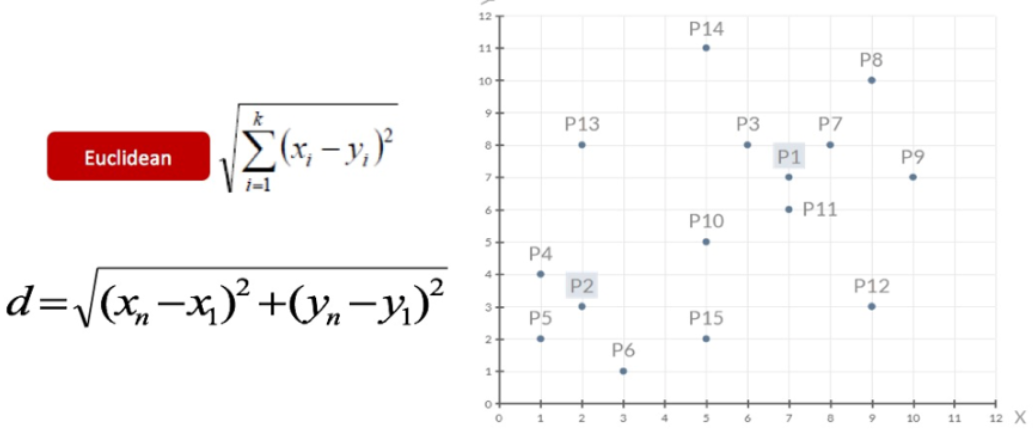
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
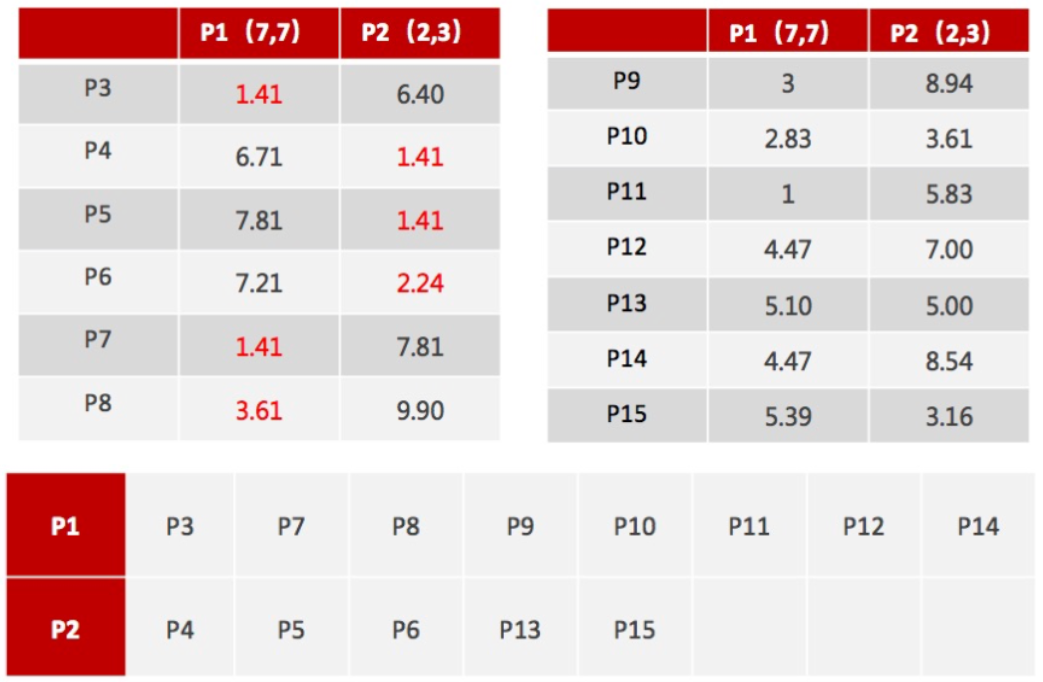
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
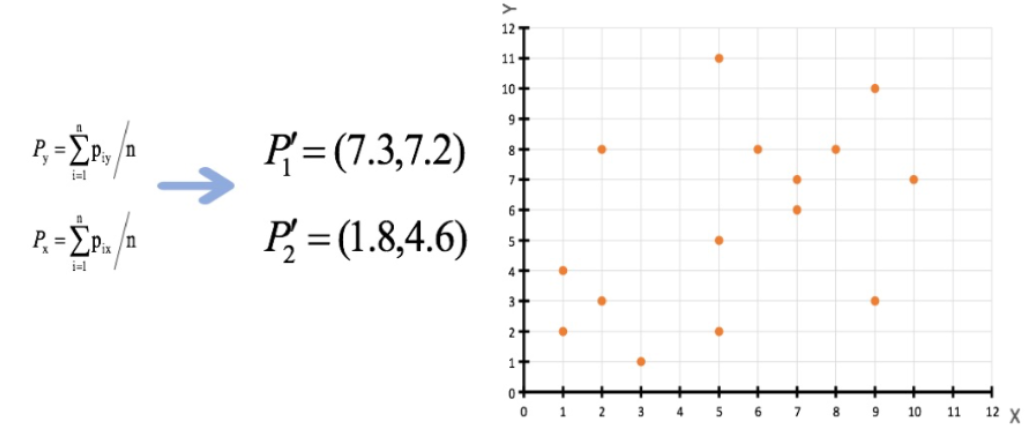
注意:这里P2′=(2.3,3.3),下同。
4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程【经过判断,需要重复上述步骤,开始新一轮迭代】
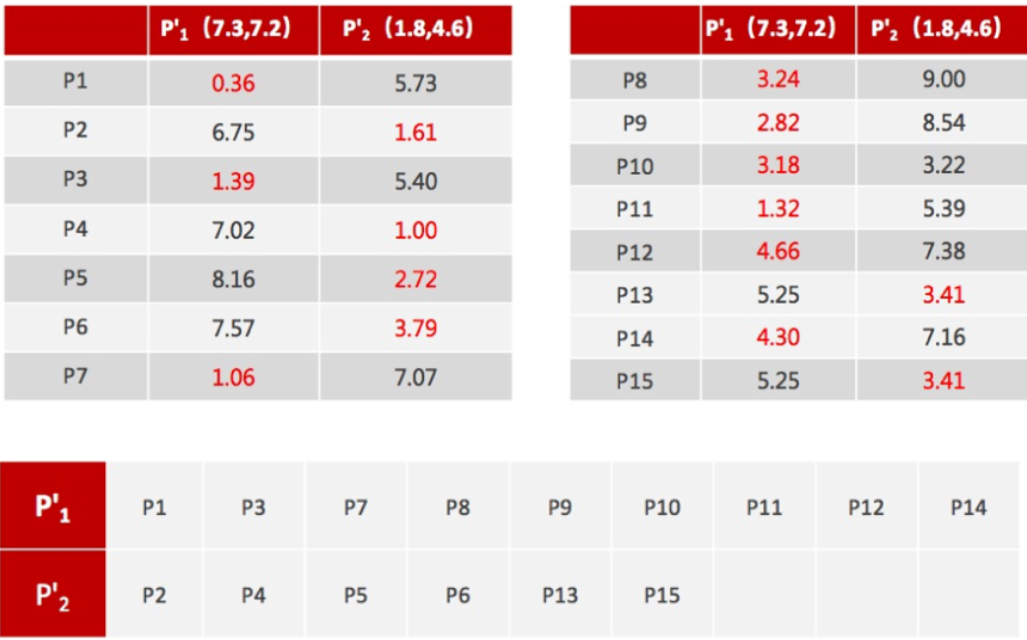
5、当每次迭代结果不变时,认为算法收敛,聚类完成,K-Means一定会停下,不可能陷入一直选质心的过程。
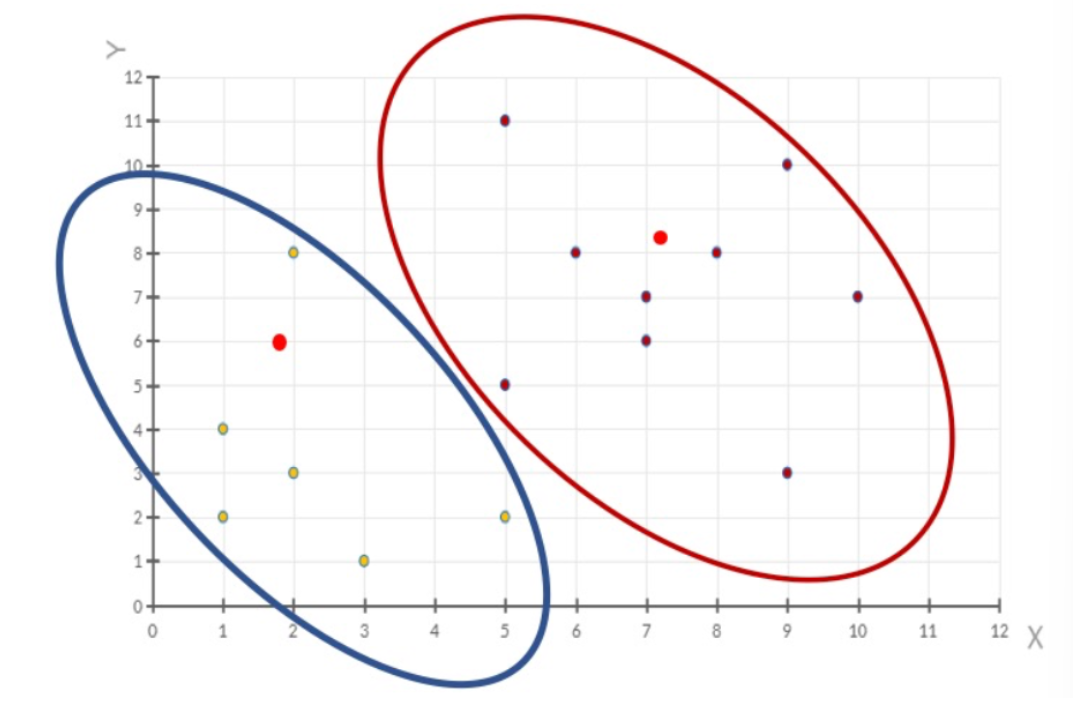
三、评价指标
1. SSE-误差平方和
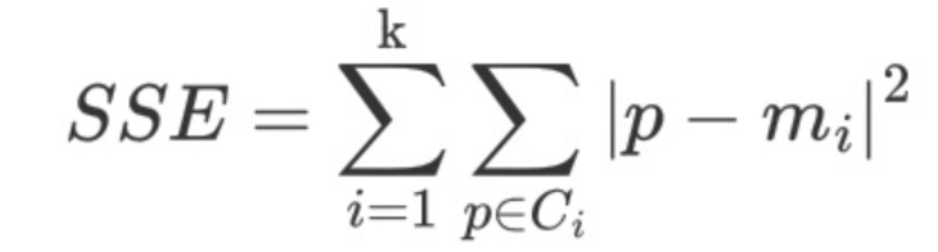
-
K 表示聚类中心的个数
-
Ci 表示簇
-
p 表示样本
-
mi 表示簇的质心
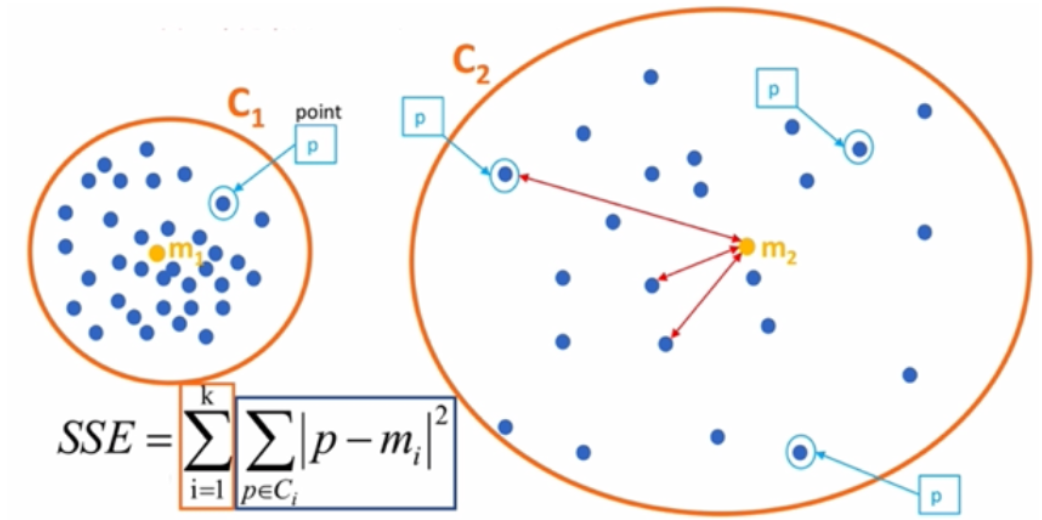
SSE 越小,表示数据点越接近它们的中心,聚类效果越好。
2. SC 系数
结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。
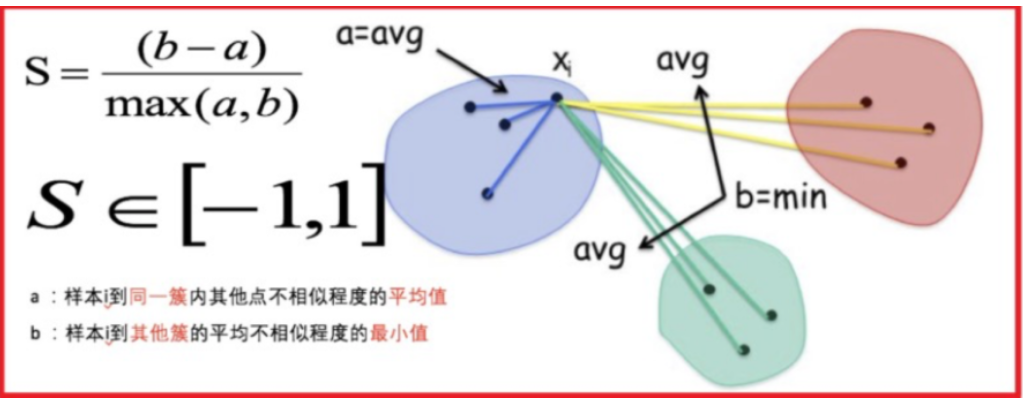
其计算过程如下:
- 计算每一个样本 i 到同簇内其他样本的平均距离 ai,该值越小,说明簇内的相似程度越大
- 计算每一个样本 i 到最近簇 j 内的所有样本的平均距离 bij,该值越大,说明该样本越不属于其他簇 j
- 计算所有样本的平均轮廓系数
- 轮廓系数的范围为:-1, 1,值越大聚类效果越好
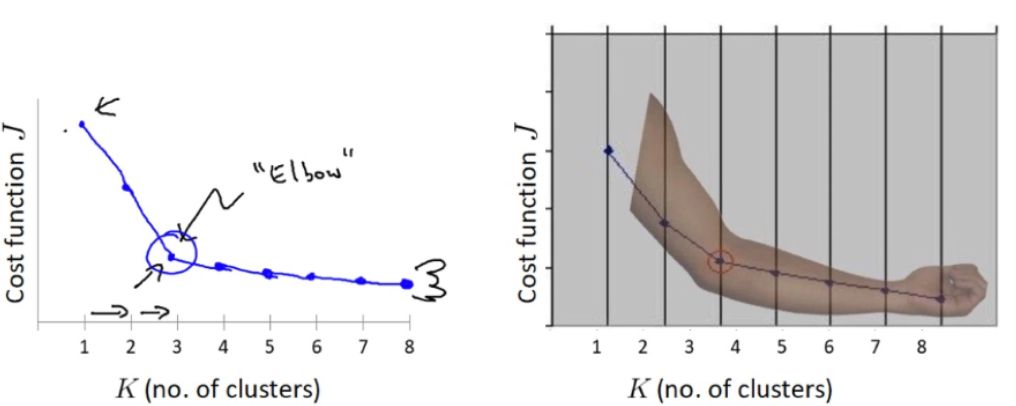
2.1 肘部法
肘部法可以用来确定 K 值.
- 对于n个点的数据集,迭代计算 k from 1 to n,每次聚类完成后计算 SSE
- SSE 是会逐渐变小的,因为每个点都是它所在的簇中心本身。
- SSE 变化过程中会出现一个拐点,下降率突然变缓时即认为是最佳 n_clusters 值。
- 在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
3. CH系数
CH 系数结合了聚类的凝聚度(Cohesion)和分离度(Separation)、质心的个数,希望用最少的簇进行聚类。
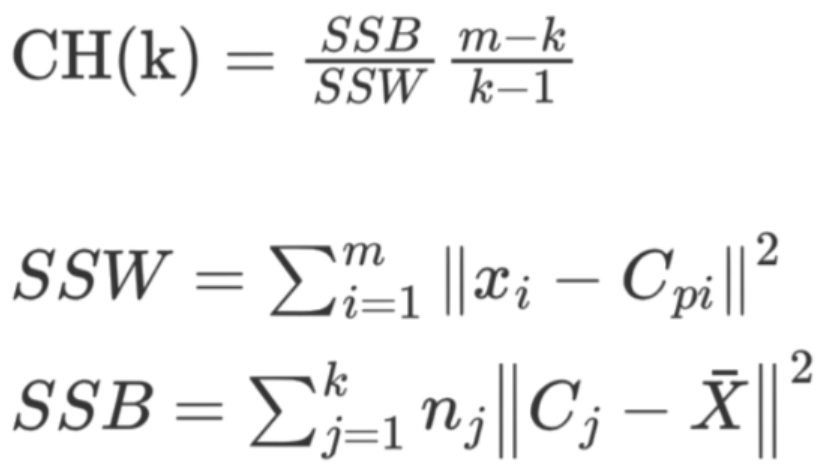
SSW 的含义:
- Cpi 表示质心
- xi 表示某个样本
- SSW 值是计算每个样本点到质心的距离,并累加起来
- SSW 表示表示簇内的内聚程度,越小越好
- m 表示样本数量
- k 表示质心个数
SSB 的含义:
- Cj 表示质心,X 表示质心与质心之间的中心点,nj 表示样本的个数
- SSB 表示簇与簇之间的分离度,SSB 越大越好