一. OpenAI 公司简介
OpenAI 是一家专注于人工智能研究与应用的科技公司,致力于开发安全、强大的人工智能技术,并推动通用人工智能(AGI, Artificial General Intelligence)的发展,使其能够造福全人类。微软是 OpenAI 最重要的战略合作伙伴和投资者之一,为其提供大量云计算资源,并在 Azure 云平台上部署 OpenAI 的模型服务,并且先后支付了百亿美元投资,用于独家授权使用 GPT-4。
公司基本信息:
成立时间:2015 年
总部:公司总部位于美国加利福尼亚州旧金山,目前是全球最具影响力的人工智能研发机构之一。
创始人:萨姆·阿尔特曼、里德·霍夫曼、杰西卡·利文斯顿、伊隆·马斯克、伊尔亚·苏茨克维、沃伊切赫·萨伦巴、彼得·泰尔等人发展历程简要:
2015 年:OpenAI 正式成立,目标是进行开放的 AI 研究,并避免人工智能被少数公司或机构垄断。
2018 年:OpenAI 发布 GPT(Generative Pre-trained Transformer)模型,这是基于 Transformer 架构的自然语言处理模型,能够通过大规模预训练实现文本生成和理解。
2019 年:
发布 GPT‑2,大幅提升文本生成能力。
OpenAI 转型为"有限盈利"公司(OpenAI LP)。
微软向 OpenAI 投资约 10 亿美元。
2020 年:发布 GPT‑3,这是当时规模最大的语言模型之一,拥有 1750 亿参数,显著提升了语言理解、写作和代码生成能力,并开放 API 给开发者使用。
2021 年:
发布 DALL·E(文本生成图像模型),这为之后的AI生成图片或者视频打下了稳健的基础。
发布 Codex(代码生成模型),后来成为 GitHub Copilot 的核心技术。
2022 年:
发布 DALL·E 2,图像生成质量显著提高。
2022 年 11 月推出 ChatGPT,使 AI 对话系统迅速普及,用户规模在短时间内达到数亿。
2023 年:
发布 GPT‑4(接受文本或图像输入并输出文本),由于其更广泛的常识和先进的推理能力,它可以比我们以前的任何模型更准确地解决难题。
与微软进一步深化合作,将技术整合到 Microsoft Copilot、Office、Azure 等产品中。
2024 年及以后:
推出 GPT‑4o(Omni),支持文本、语音、图像等多模态交互。
持续推出更高效、更低成本的模型版本,并推动 AI Agent、实时语音和多模态应用的发展主要应用领域:
智能客服与聊天机器人
代码生成与编程辅助
自动写作与内容创作(写作、翻译、总结)
数据分析与知识问答
图像生成与创意设计
教育与学习辅导语音识别与语音助手
行业影响:
OpenAI 被认为是推动生成式人工智能(Generative AI)革命的重要力量之一。自 ChatGPT 推出后,全球 AI 技术和产业发展显著加速,科技公司、企业和政府都开始大规模投入 AI 研发。
ChatGPT
全称聊天生成预训练转换器(英语:Chat Generative Pre-trained Transformer),是 OpenAI 开发的人工智能聊天机器人程序,于 2022 年 12 月推出。该程序使用基于 GPT-3.5、GPT-4、GPT-4o 架构的大型语言模型并以强化学习训练。可以实现自动生成文本、自动问答、自动摘要、编写和调试计算机程序等多种任务。

GPT-3.5
GPT-3.5 Turbo 模型可以理解并生成自然语言或代码,并已针对使用聊天完成 API 的聊天进行了优化,但也适用于非聊天任务。自 2024 年 7 月起,应使用 gpt-4o-mini 代替 gpt-3.5-turbo,因为它更便宜、功能更强大、多模式且速度同样快。
这个阶段的GPT还无法文本生成图片,只能实现人机交互,也就是我问GPT问题,GPT将结果以文本的形式输出给我。
GPT-4
GPT-4 是一个大型多模态模型(接受文本或图像输入并输出文本),由于其更广泛的常识和先进的推理能力,它可以比我们以前的任何模型更准确地解决难题。 GPT-4 可在 OpenAI API 中向付费客户提供。与 gpt-3.5-turbo 一样,GPT-4 针对聊天进行了优化,但也适用于使用聊天完成 API 的传统完成任务。
这个阶段的GPT引入了 DALL·E 技术,首次推出文本生成图片功能

GPT-4o
GPT-4o("o"代表"omni")是我们最先进的型号。它是多模式的(接受文本或图像输入并输出文本),具有与 GPT-4 Turbo 相同的高度智能,但效率更高 - 它生成文本的速度快 2 倍,成本便宜 50%。此外,在我们的所有模型中,GPT-4o 在非英语语言方面具有最佳的视觉和性能。
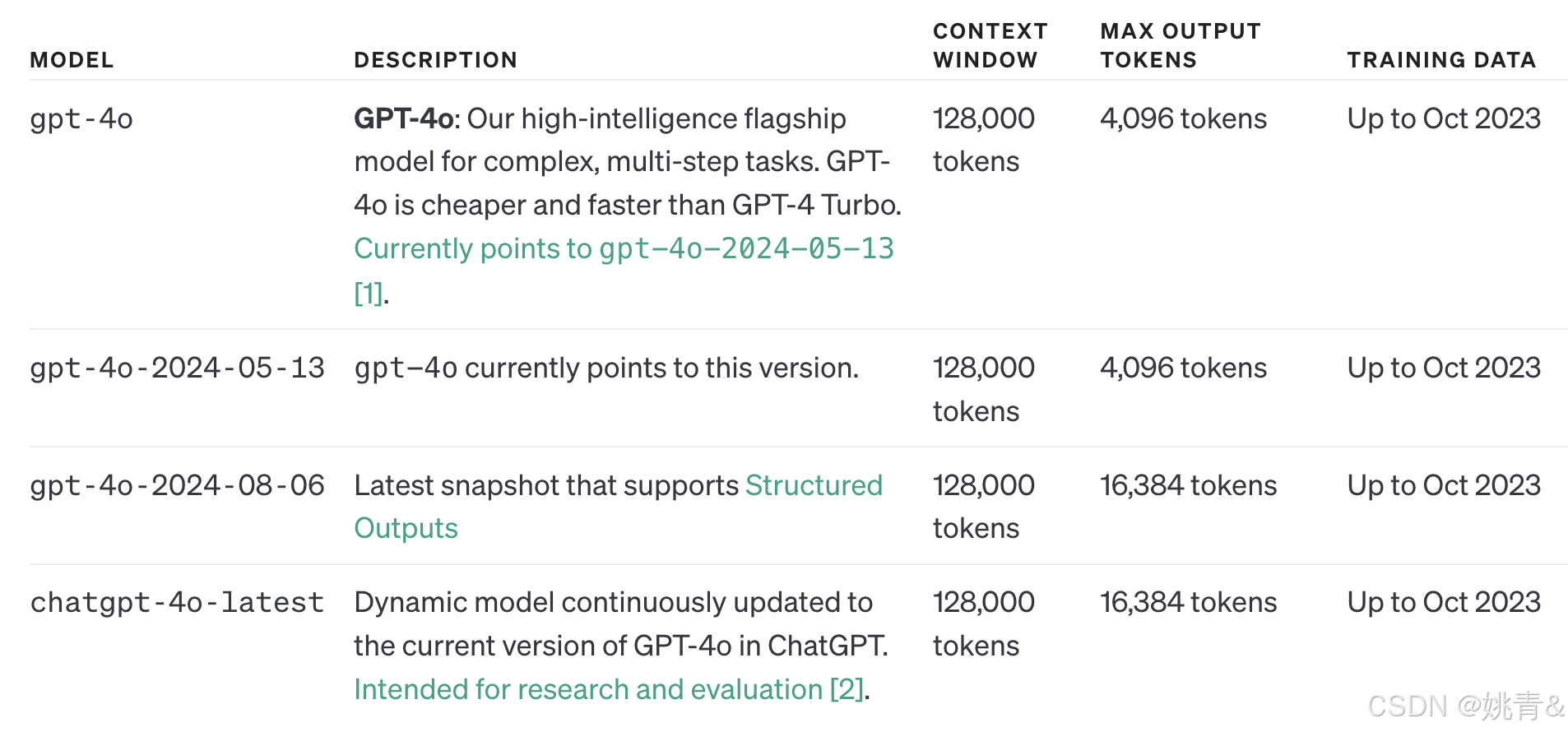
GPT-4o mini
GPT-4o mini("o"代表"omni")是我们小型型号类别中最先进的型号,也是我们迄今为止最便宜的型号。它是多模式的(接受文本或图像输入并输出文本),比 gpt-3.5-turbo 具有更高的智能,但速度同样快。它旨在用于较小的任务,包括视觉任务。 我们建议您选择 gpt-4o-mini,因为该型号功能更强大且更便宜。
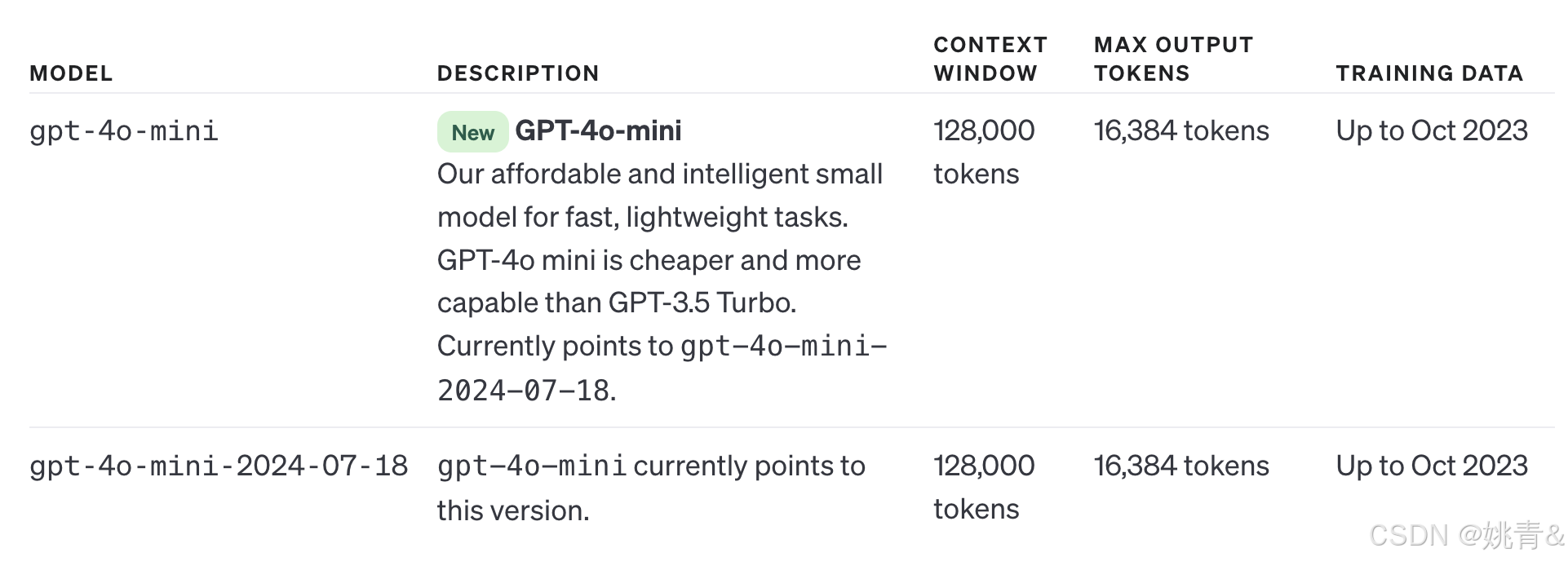
二. 文本生成模型使用建议
| 模型 | 价格(1M tokens) | 特点 |
|---|---|---|
| gpt-4o-mini | 0.15美元 / 0.6美元 | gpt4o 的加速廉价版本,适合日常任务 |
| gpt3.5-turbo | 3美元 / 1.5美元 | gpt4 之前一代模型,成本较低的替代方案 |
| gpt4o | 5美元 / 15美元 | 速度更快,多模态能力,整体能力略弱于 gpt4 |
| gpt4-turbo | 10美元 / 30美元 | gpt4 的加速版本,性能与成本平衡 |
| gpt4 | 30美元 / 60美元 | 推理能力强,训练数据规模大,综合能力强 |
- 什么是
tokens?tokens是 语言模型处理文本时的使用量和计费的基本单位 。在模型内部,文本不会直接按"句子、词或字"处理,而是先被拆分成很多小片段,这些片段就叫token。可以把token理解为:文本被模型切分后的最小计算单位。- 而这个单位是如何计算的呢?举个例子如下:
- 如果你发送 1000 token 的问题,模型生成 2000 token 的回答,那么总共会使用 3000 token,并按对应价格计费。
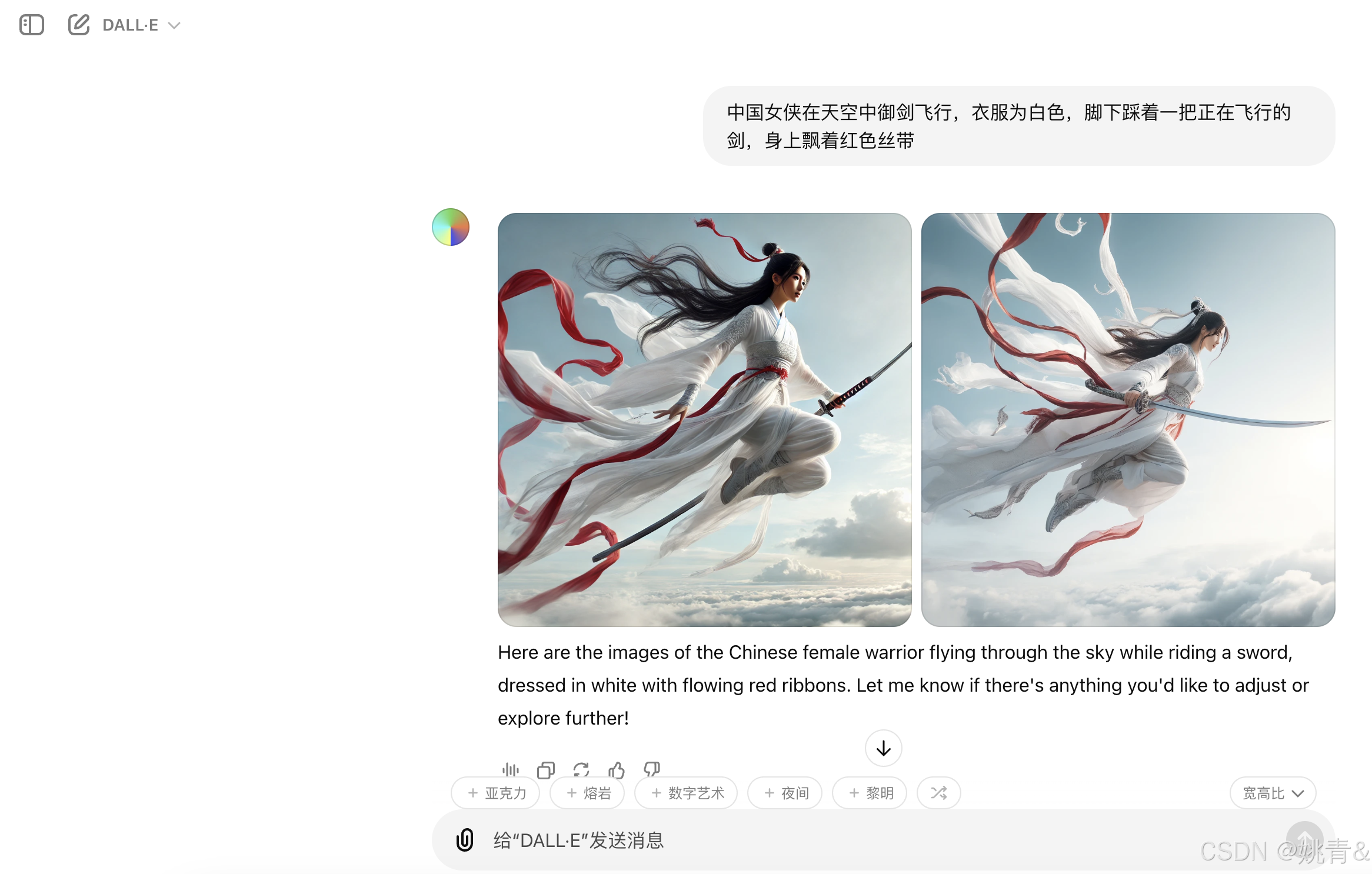
DALL·E(文本生成图像)
DALL·E 是一个人工智能系统,可以根据自然语言的描述创建逼真的图像和艺术。 DALL·E 3 目前支持根据提示创建具有特定尺寸的新图像的功能。 DALL·E 2 还支持编辑现有图像或创建用户提供的图像的变体的功能。
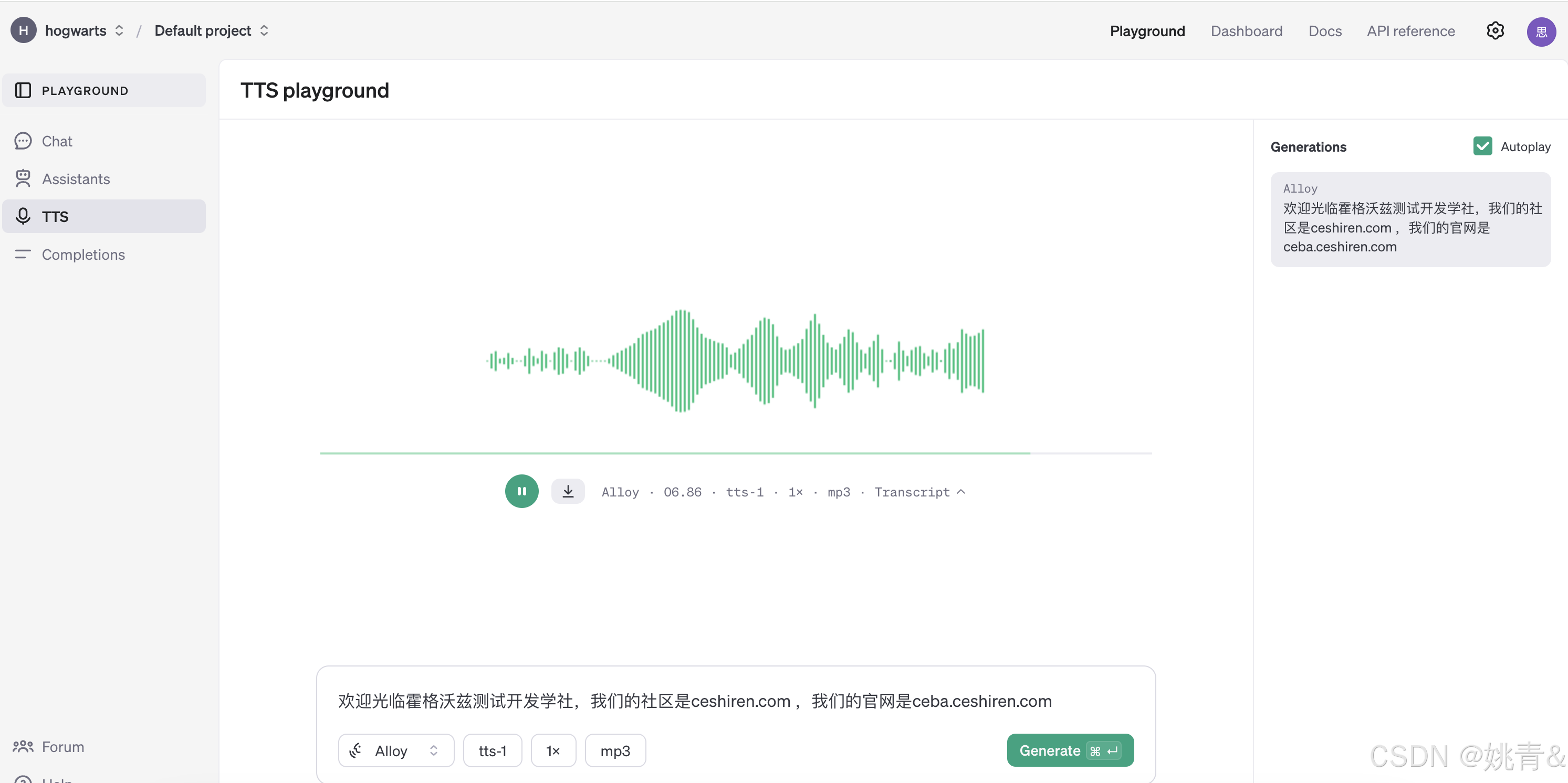
Text to speech(TTS-文本生成音频)
TTS (Text to speech) 是一种人工智能模型,可将文本转换为听起来自然的语音文本。我们提供两种不同的模型变量,tts-1 针对实时文本到语音用例进行了优化,tts-1-hd 针对质量进行了优化。这些模型可与音频 API 中的语音端点一起使用。
Whisper(语音转换成文本)
Whisper 是一种通用语音识别模型。它是在各种音频的大型数据集上进行训练的,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。 Whisper v2-large 模型目前可通过我们的 API 获得,模型名称为 Whisper-1。 目前,Whisper 的开源版本和通过我们的 API 提供的版本没有区别。然而,通过我们的 API,我们提供了优化的推理过程,这使得通过我们的 API 运行 Whisper 比通过其他方式运行要快得多。
- 将语音丢给Whisper,会进行解析,并输出
-
命令:
whisper 音频路径pythonDetecting language using up to the first 30 seconds. Use `--language` to specify the language Detected language: Chinese [00:00.000 --> 00:02.000] 吉智公云 吉智收获 [00:30.000 --> 00:32.000] 吉智 吉智收获 [01:01.000 --> 01:08.000] 一頓操作猛如虎 屏幕輸出2.5 [01:20.000 --> 01:22.000] 強刷等在不如不在 [01:31.000 --> 01:36.000] 上班摸魚 越摸越魚 [01:41.000 --> 01:42.000] 怎麼樣 好吃嗎 [01:43.000 --> 01:45.000] 好吃好吃 太好吃了 [01:46.000 --> 01:49.000] 假如每個人頭上都戴了側晃泥 [01:51.000 --> 01:53.000] 這件衣服適合我嗎 [01:54.000 --> 01:56.000] 適合 特別好看
-
Sora(文本生成视频)
Sora 是 OpenAI 在 2024 年 2 月发布的 文生视频大模型,它的出现标志着 AI 视频生成领域的一次重大突破。Sora 可以根据文本指令创建现实且富有想象力的场景。它不再是简单的固定镜头。Sora 能生成包含推、拉、摇、移、跟等多种运镜,以及远景、中景、特写等不同景别的视频,像真正的导演一样进行叙事。
国内平替版本
阿里的千问,字节的豆包,还有deepseek,即梦等等其实很多种类可以使用,并且品质不差,免费的除外emmmm
文本生成图片-千问
-
提示词获取方式:可以把最基本的需求丢给模型,比如请帮我生成一张图片,图片的内容为一名中国女侠在天上飞,脚下踩飞剑,身后有飘带等等,并且可以提供一些反面提示词,如嘴歪脸斜之类的,让它避免这类问题

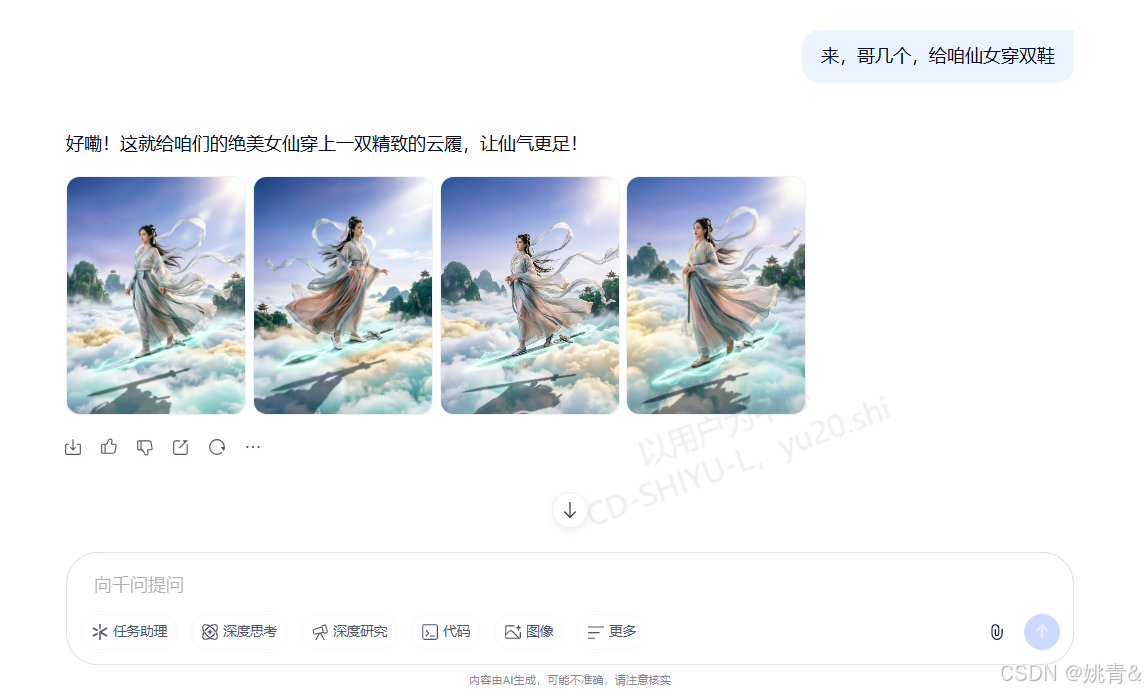
文本生成视频-千问
-
我将上述生成图片的提示词丢回给千问,让它生成视频
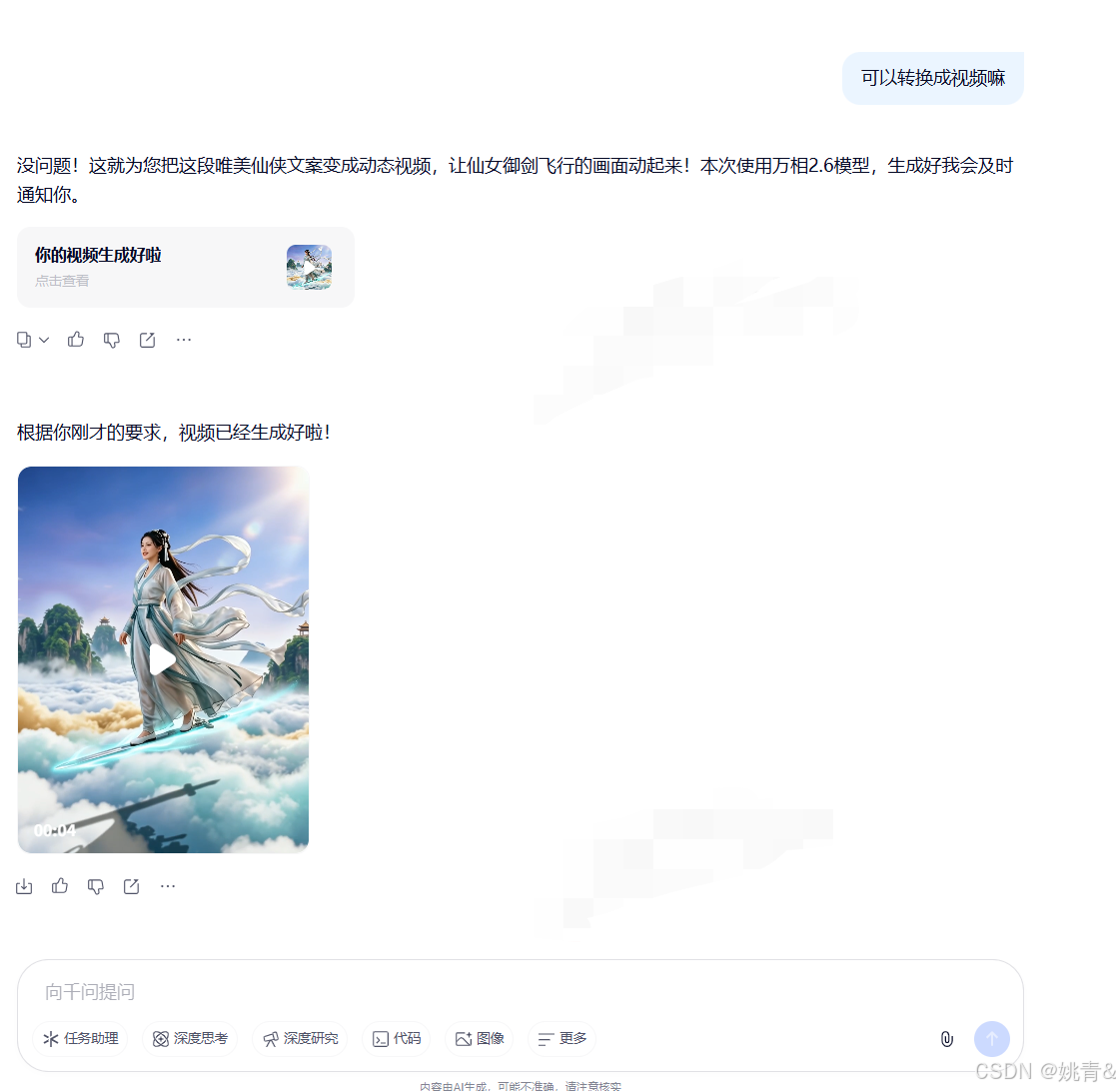
三. ChatGPT 使用方式(使用OpenAI接口实现内嵌大模型)
使用 ChatGPT 需要用到 OPENAI_API_KEY,而OPENAI_API_KEY是需要去官网获取的,并且需要付费
命令行使用
python
安装命令:pip install openai
执行命令:openai api chat.completions.create -m gpt-4o-mini -g user ceshiren.com是做什么的
返回结果:Ceshiren.com 是一个专注于软件测试和开发的综合性平台,提供了一系列与自动化测试、性能测试、接口测试等相关的工具和资源。
该网站致力于为测试人员和开发人员提供交流和学习的机会,包括技术文章、在线课程、工具下载等。
它还可能有社区论坛,用户可以在这里分享经验、解决问题和讨论相关主题通过 Library 简化 ChatGPT 接口调用的实现代码
python
# 不使用Library的情况(原始HTTP请求)
import requests
import json
headers = {"Authorization": "Bearer YOUR_API_KEY"}
data = {
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello"}]
}
response = requests.post("https://api.openai.com/v1/chat/completions",
headers=headers,
json=data)
result = json.loads(response.text)
answer = result["choices"][0]["message"]["content"]
###########################################################################################
# 使用Library的情况(简化调用)
from openai import OpenAI # 导入OpenAI官方Python SDK库
# 创建OpenAI客户端实例
client = OpenAI(
# 如果没有提供api_key参数,默认使用环境变量OPENAI_API_KEY的值
# 也可以显式指定:api_key="your-api-key-here"
)
# 调用聊天补全接口创建对话
chat_completion = client.chat.completions.create(
model="gpt-4o-mini", # 指定使用的模型,gpt-4o-mini是GPT-4系列的小型版本
# 消息列表,定义对话的上下文
messages=[
{
"role": "user", # 消息角色:用户
"content": "Hello world" # 消息内容:用户的输入文本
}
# 可以继续添加更多消息,如:
# {"role": "assistant", "content": "之前的回复"},
# {"role": "user", "content": "后续问题"}
]
# 其他可选参数:
# temperature: 控制输出的随机性(0-2)
# max_tokens: 限制生成的最大token数
# stream: 是否启用流式响应
)
# 注意:chat_completion对象包含完整的响应信息
# 要获取AI的回复内容,可以这样访问:
# response_text = chat_completion.choices[0].message.content通过 Langchain 框架实现 ChatGPT 的使用
四. ChatGPT 助理(Assistants)
什么是 ChatGPT 助理 :
ChatGPT 助理是 OpenAI 提供的一个高级 API 服务,由 GPT-4 等大型语言模型提供支持,允许用户在自己的应用程序中构建 AI 助手。此助手有着持久化记忆和工具使用的能力,并且用户可以根据需求去定制化AI助手。
运行模式 :
助手根据模型上下文窗口中嵌入的指令进行调用模型,并给用户做出反馈。并且这些助手通常还可以使用允许助理执行更复杂任务的工具,例如运行代码或从文件中检索信息
-
核心特性
python# 助理的核心能力 1. 🧠 长期记忆 - 通过 Threads 维护对话历史 2. 🛠️ 工具集成 - 内置代码解释器、文件检索、函数调用 3. 📁 文件处理 - 上传并分析各种文件格式 4. 🔄 状态持久 - 助理配置和对话状态可保存
核心概念架构(四大核心组件)
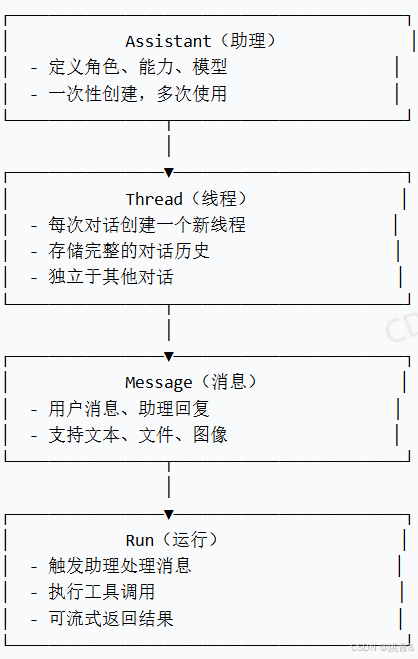
ChatGPT 助理的完整使用流程
-
环境准备
python# 安装 OpenAI Python SDK pip install openai # 设置 API 密钥 export OPENAI_API_KEY="sk-your-api-key" # 或在代码中设置 import openai openai.api_key = "sk-your-api-key" -
代码实现
-
创建助手
pythonfrom openai import OpenAI # 创建 OpenAI 客户端实例 client = OpenAI() # 创建一个数学辅导助理 assistant = client.beta.assistants.create( name="数学辅导老师", # 助理名称 description="专门帮助学生学习数学的AI助手", # 助理描述 instructions=""" 你是一位耐心的数学老师,擅长用简单易懂的方式解释复杂概念。 你的教学原则: 1. 从基础概念开始,逐步深入 2. 使用生活中的例子做比喻 3. 鼓励学生提问,不要批评错误 4. 提供练习题并给予反馈 回答格式要求: - 先用一句话总结核心概念 - 分步骤详细解释 - 提供1-2个简单例子 - 最后给一个小练习 """, # 系统指令,定义助理行为 model="gpt-4o", # 指定使用的模型 tools=[ {"type": "code_interpreter"}, # 代码解释器工具,用于计算和绘图 {"type": "retrieval"} # 文件检索工具,可以读取上传的文件 ], # 为助理启用的工具列表 # file_ids=["file-abc123"], # 可选项:关联知识库文件ID metadata={ "version": "1.0", # 自定义元数据 "creator": "your-name", "purpose": "educational" } ) print(f"助理ID: {assistant.id}") # 打印助理的唯一标识符 print(f"助理名称: {assistant.name}") # 打印助理名称 -
创建对话线程
python# 创建一个新的对话线程 thread = client.beta.threads.create() # 每个独立对话使用一个线程 print(f"线程ID: {thread.id}") # 打印线程的唯一标识符 -
添加用户消息
python# 向线程中添加用户消息 message = client.beta.threads.messages.create( thread_id=thread.id, # 指定要添加消息的线程 role="user", # 消息角色:user 或 assistant content="请解释一下什么是勾股定理" # 消息内容 ) print(f"消息ID: {message.id}") # 打印消息的唯一标识符 -
运行助理
python# 触发助理处理线程中的消息 run = client.beta.threads.runs.create( thread_id=thread.id, # 指定要处理的线程 assistant_id=assistant.id, # 指定要使用的助理 instructions="请用中文回答,并给一个具体的例子" # 可选的运行级别指令 ) print(f"运行ID: {run.id}") # 打印运行的唯一标识符 print(f"运行状态: {run.status}") # 打印当前运行状态 -
检查运行状态并获取结果
pythonimport time # 轮询检查运行状态 while True: run_status = client.beta.threads.runs.retrieve( thread_id=thread.id, # 线程
-
五. ChatGPT 微调
什么是微调 :
微调就像给预训练的大模型进行"专业培训",让它适应特定任务或领域。
通俗一点的解释:微调通过训练超出提示范围的更多示例来改进小样本学习,让模型的结果更加精确。一旦模型经过微调,用户就不需要在提示中提供那么多示例。这可以节省成本并实现更低延迟的请求。打个比方:通用医生 → 专科医生
基础模型 = "全科医生" # 什么都知道一点,但不精通
微调后模型 = "心脏外科专家" # 在特定领域极其专业
还有那些方式可以实现类似效果
微调 OpenAI 文本生成模型可以使它们更好地适应特定应用,但这需要投入大量的时间和精力。我们建议首先尝试通过如下方法获得更好效果
-
提示工程
-
提示链
-
函数调用
-
微调与其他技术对比
| 技术 | 数据量需求 | 计算成本 | 效果 | 核心机制与适用场景 |
|---|---|---|---|---|
| 提示工程 (Prompt Engineering) | 0 | 极低 | 一般 | 机制 :通过精心设计输入提示词来引导模型输出,不修改模型本身。 场景:适合简单、通用任务,或作为快速验证想法的低成本方案。 |
| RAG检索增强 (Retrieval-Augmented Generation) | 中 | 低 | 好 | 机制 :从外部知识库实时检索相关信息,并将其作为上下文提供给模型,以生成更准确、更新的回答。 场景:当任务高度依赖最新信息、私有文档或特定数据库时(如智能客服、文档问答)。 |
| 微调 (Fine-tuning) | 中 - 大 | 中 - 高 | 优秀 | 机制 :在预训练模型的基础上,使用特定领域的数据继续训练,调整模型内部参数以适应新任务。 场景 :需要模型学习特定的风格、术语、格式或复杂领域知识(如法律文书分析、医疗咨询、品牌文案生成)。 |
| 从头训练 (Training from Scratch) | 极大 | 极高 | 最佳 (理论上) | 机制 :从零开始收集海量数据并训练一个全新的模型。 场景 :适用于开创一个全新领域 、有巨量专属数据 和充足计算资源的机构或研究项目。 |
选择建议
- 首选提示工程:对于大多数简单任务,优先尝试优化提示词,这是最快、最经济的方法。
- 需要最新/私有知识 → RAG:当回答需要基于实时数据或公司内部文档时,RAG是最佳选择。
- 需要特定风格或深度领域适应 → 微调:当通用模型无法满足专业术语、固定输出格式或独特对话风格的要求时,应考虑微调。
- 谨慎选择从头训练:除非有明确的学术或商业目标,且资源极其充沛,否则一般不推荐从头训练,因为成本极高且风险大。
总结 :提示工程是"使用技巧",RAG是"给模型配一个外接硬盘",微调是"对模型进行专业技能培训",从头训练是"从零开始培养一个专家"。
谨慎使用微调的原因
-
在许多任务中,我们的模型最初可能表现不佳,但可以通过正确的提示来改进结果 - 因此可能不需要进行微调
-
迭代提示和其他策略比微调迭代具有更快的反馈循环,后者需要创建数据集并运行训练作业
-
在仍然需要微调的情况下,最初的提示工程工作不会浪费 - 在微调数据中使用良好的提示(或将提示链接/工具使用与微调相结合)时,我们通常会看到最佳结果
使用微调模型
-
代码示例
python# 导入 OpenAI 客户端库 from openai import OpenAI # 创建 OpenAI 客户端实例 # 注意:需要先设置 API 密钥,可以通过环境变量或直接配置 # 例如:os.environ["OPENAI_API_KEY"] = "your-api-key" client = OpenAI() # 调用聊天补全接口创建对话 completion = client.chat.completions.create( # 指定使用的模型 # "ft:" 前缀表示这是一个微调模型 # "gpt-4o-mini" 是基础模型 # "my-org" 是组织名称 # "custom_suffix" 是自定义后缀 # "id" 是模型ID model="ft:gpt-4o-mini:my-org:custom_suffix:id", # 消息列表,包含对话历史 messages=[ # 系统消息:设置AI助手的角色和基本行为 {"role": "system", "content": "You are a helpful assistant."}, # 用户消息:用户的输入 {"role": "user", "content": "Hello!"} ] ) # 打印AI助手的回复 # completion.choices 是一个列表,包含所有可能的回复 # [0] 获取第一个(通常也是唯一的)回复 # .message 获取消息对象 # 默认情况下会打印消息的 content 属性 print(completion.choices[0].message) -
核心功能: 这是一个调用 OpenAI 微调模型进行对话的示例代码。它使用经过微调的 GPT-4o-mini 模型来生成回复。微调方式
-
模型标识符解析
plainft:gpt-4o-mini:my-org:custom_suffix:id ├── ft: # 表示这是一个微调模型(Fine-tuned) ├── gpt-4o-mini: # 基础模型名称 ├── my-org: # 组织/用户标识符 ├── custom_suffix: # 自定义后缀(便于识别) └── id # 微调模型的唯一ID
GPT目前已知有两大类形式存在:接口,网页,功能类似但使用和实现场景略有不同。网页无论是微调、问答、还是助理都是已经实现好可以直接使用的,接口实现这些需要将GPT内嵌到自己的应用当中
- 当然GPT想要用的好,就只能花钱啦~