Transformer实战(38)------视觉Transformer
-
- [0. 前言](#0. 前言)
- [1. 视觉 Transformer](#1. 视觉 Transformer)
-
- [1.1 图像表示](#1.1 图像表示)
- [1.2 使用 Transformer 处理图像数据](#1.2 使用 Transformer 处理图像数据)
- [2. 使用 Transformer 进行图像分类](#2. 使用 Transformer 进行图像分类)
- [3. 使用 Transformer 进行语义分割和目标检测](#3. 使用 Transformer 进行语义分割和目标检测)
-
- [3.1 使用 DETR 进行目标检测](#3.1 使用 DETR 进行目标检测)
- [3.2 使用 DETR 进行语义分割](#3.2 使用 DETR 进行语义分割)
- 小结
- 系列链接
- 系列链接
0. 前言
Transformer 在自然语言处理 (Natural Language Processing, NLP) 领域取得了显著成就,在许多不同的任务中都表现出色。在本节中,我们将探索视觉 Transformer (Vision Transformer, ViT) 模型。正如 NLP 领域创建了多种模型一样,视觉领域也开发了多种模型,每种模型都为计算机视觉提供了新的视角。通过本节,将学习如何使用 ViT 等模型进行计算机视觉任务,了解基于 Transformer 的预训练计算机视觉模型的工作原理,以及如何针对特定任务进行微调。
1. 视觉 Transformer
Transformer 解决了自然语言处理 (Natural Language Processing, NLP) 领域的许多问题并取得了良好的效果,研究人员开始将其应用于文本以外的其他领域,计算机视觉是 Transformer 应用的一个重要领域。在本节中,将学习如何将 Transformer 应用于计算机视觉。
1.1 图像表示
NLP 处理的数据通常是纯文本,通常被视为基于时间序列的字符输入及其相应的输出。但计算机视觉问题通常是以图像作为输入,输出可以是数值或矩阵。对于灰度图像,可以表示为具有相应宽度和高度的矩阵,最简单的理解方式是将其视为黑白图像:
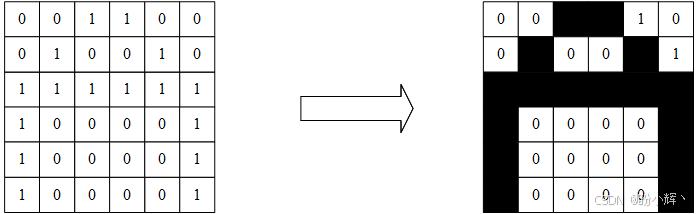
如上图所示,矩阵中的每个单元格对应一个二进制值( 0 或 1)。值为 0 表示白色,值为 1 表示黑色,矩阵最终在图像中显示为字符 A。
对于灰度图像,取值范围不仅是 0 和 1,而是从 0 到 255 (256 个颜色,从全黑到全白)。对于 RGB 图像,需要三个矩阵(而不是单个矩阵),每个矩阵分别代表一种颜色(红色、绿色或蓝色)的强度,特定颜色可以由红、绿和蓝值分量合成表示,将像素值表示为 RGB 三元组 (r, g, b)。
我们已经了解了计算机视觉中的核心------图像,接下来我们继续探讨如何通过 Transformer 处理、学习和使用图像数据。
1.2 使用 Transformer 处理图像数据
Transformer 非常擅长处理时间序列数据,图像在某种程度上也可以视为时间序列。例如,将图像分解成大小为 16 x 16 的小块,如果我们按顺序将这些图像块依次输入模型,那么这些块也具有序列格式。这与卷积神经网络非常相似,在卷积神经网络 (Convolutional Neural Network, CNN)中,我们也将图像视为多个小块,并在块上应用卷积核(即创建一个卷积核并在图像上移动)。Transformer 会在在此基础上,增加一个基于全连接层的嵌入 (embedding) 层,这将使得每个块的大小不再是 16 x 16,而是该图像部分的密集表示,此外,还需要添加位置嵌入 (positional embedding)。
这些模型也可以仅包含编码器。例如,可以在每个操作的开头添加一个额外的词元,以创建整个图像的表示。在分类过程中,我们可以使用该词元将整个图像分类为给定的类别。ViT 架构如下图所示:
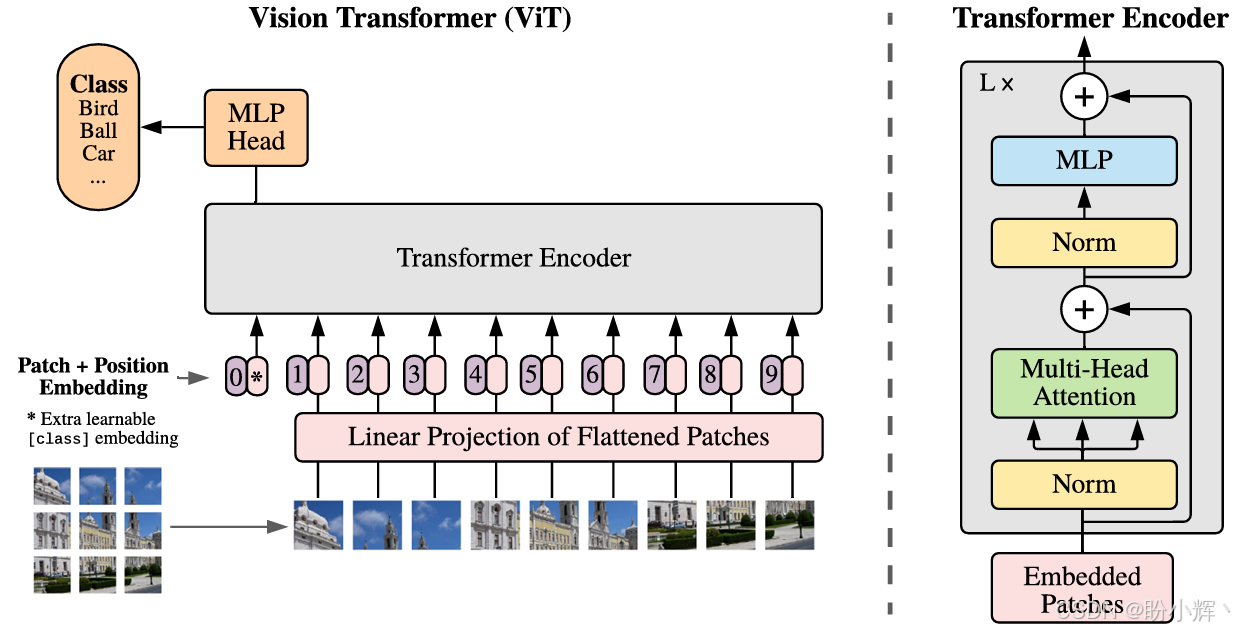
架构的其余部分与 Transformer 编码器块相同。ViT 架构的主要思想是分块并在图像块上应用位置嵌入。
此外,研究人员还提出许多类似 ViT 的方法。例如,数据高效图像 Transformer (Data-Efficient Image Transformer, DeiT) 模型使用另一个词元获取来自其他模型(如 ResNet )的知识。主要的区别在于训练过程中使用了两个损失函数:一个用于 [CLS] 词元的分类交叉熵损失,另一个用于教师模型预测的蒸馏词元。这进一步帮助模型从教师模型中获取知识,并加速预训练阶段。DeiT 模型架构如下图所示:
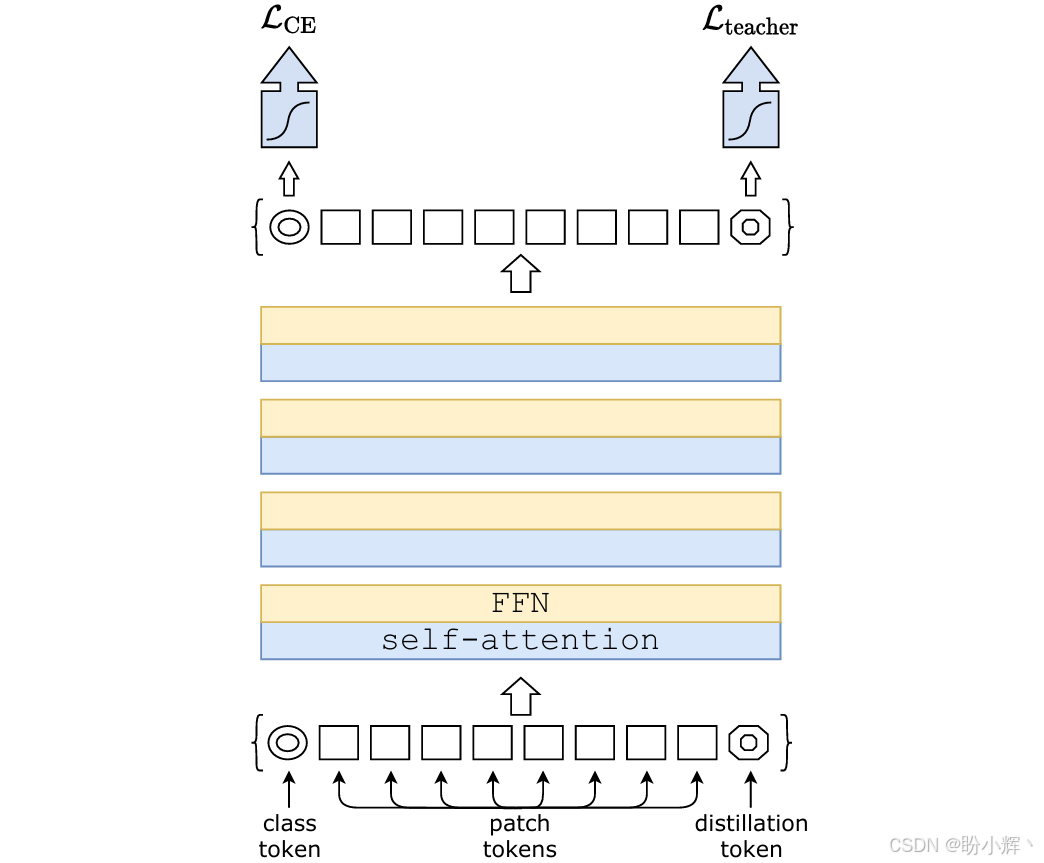
ImageGPT (iGPT) 使用了类似方法,模型训练用于预测下一个像素值,非常类似于基于 GPT 的 NLP 模型。这有助于模型根据给定的初始像素预测图像的其余部分。
检测 Transformer (Detection Transformer, DETR) 模型用于目标检测等任务,该架构结合了卷积和 Transformer 模块。首先,使用一个骨干网络生成图像的 2D 表示。这些图像的 2D 向量表示被传递到 Transformer 编码器块,随后会通过解码器块进行处理,解码器块用于生成相应的目标检测输出。对于每个目标,解码器块还会接收一个查询向量,帮助其预测图像中存在哪些目标:
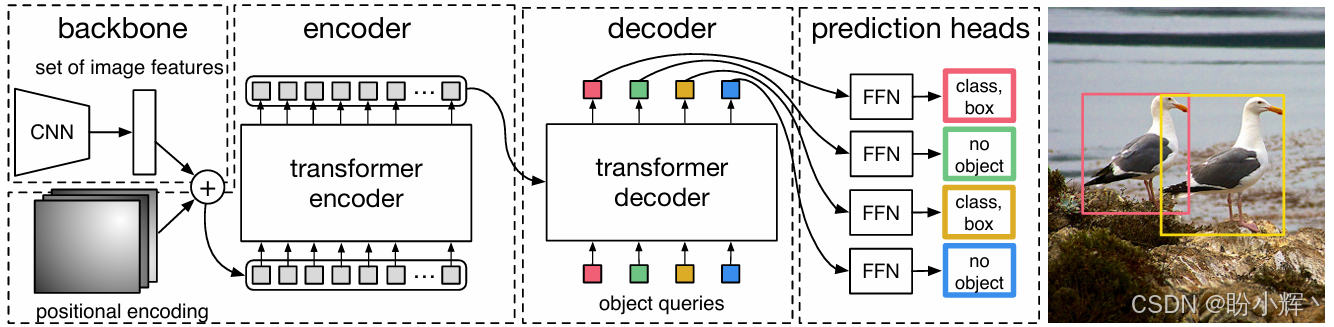
基于 Transformer 的视觉模型与基于 CNN 的模型表现大致相当。最重要的是这些模型所使用的表示方案,能够以相同形式(基于词元和基于图像块)表示文本和图像的模型,相比于将图像视为像素、文本视为词元的 CNN 模型,能够适用更多的应用场景。另一方面,与基于 CNN 的模型相比,这些模型能够更高效地同时学习多个任务,并且可以用于创建该领域的基础模型。视觉领域的基础模型是指通过在大量数据上进行预训练创建的模型,类似于语言模型。
我们已经了解了基于视觉的 Transformer 的基础知识,并掌握了该领域中不同方法的相关工作原理。在下一节中,我们将深入探讨如何使用这些模型进行图像分类。
2. 使用 Transformer 进行图像分类
视觉 Transformer (Vision Transformer, ViT) 是使用 Transformer 进行图像分类的一个很好的选择。可以通过加载 transformers 库的预训练模型使用 ViT 进行图像分类。
(1) 从 transformers 库中导入 ViT,并加载预处理器和模型:
python
from transformers import ViTForImageClassification, ViTImageProcessor
model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224")
processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224")(2) 加载图像。在本节中,我们从 COCO 数据集中下载并加载一张示例图像:
python
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000439715.jpg'
image = Image.open(requests.get(url, stream=True).raw)(3) 使用预处理器,将图像的格式转换为ViT所需的格式:
python
inputs = processor(images=image, return_tensors="pt")(4) 将图像输入模型并获得类别概率输出:
python
outputs = model(inputs.pixel_values)(5) 与大多数基于深度学习和 softmax 的分类方法类似,使用 argmax 获取具有最高概率的类别 ID:
python
prediction = outputs.logits.argmax(-1)(6) 使用模型的预定义函数打印出类别名称:
python
print("Class label: ", model.config.id2label[prediction.item()])输出结果如下所示:
python
Class label: bearskin, busby, shako我们已经学会了如何使用 ViT 进行图像分类。如果想在自己的数据集上训练 ViT 分类模型,需要使用相同的预处理器来转换图像数据集,以确保它符合模型所需的格式。在下一节中,我们将学习如何将 Transformer 应用于语义分割和目标检测等其它计算机视觉任务。
3. 使用 Transformer 进行语义分割和目标检测
在本节中,我们将重点介绍计算机视觉中的两个重要任务:语义分割 (semantic segmentation) 和目标检测 (object detection),学习如何使用 Transformer 来完成这些任务。我们将使用 DETR 模型进行目标检测和语义分割。通过使用预训练的 Transformer 模型,可以非常方便的完成这些任务。
3.1 使用 DETR 进行目标检测
接下来,首先介绍如何使用 DETR 检测图像中出现的目标对象。
(1) 加载模型和预处理器:
python
from transformers import DetrImageProcessor, DetrForObjectDetection
import torch
from PIL import Image
import requests
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")(2) 加载图像。在本节中,我们从 COCO 数据集中下载并加载一张示例图像:
python
url = "http://images.cocodataset.org/val2017/000000439715.jpg"
image = Image.open(requests.get(url, stream=True).raw)(3) 将下载的图像输入模型,生成相应的输出,在目标检测中称为边界框 (bounding box):
python
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)(4) 为边界框设置阈值。在本节中,我们将其设置为 0.9,表示只有当检测到的目标物体的得分高于这个阈值时,才会保留该目标物体:
python
target_sizes = torch.tensor([image.size[::-1]])
results = processor.post_process_object_detection(
outputs, target_sizes=target_sizes, threshold=0.9)[0](5) 打印检测结果:
python
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} \
with confidence "
f"{round(score.item(), 3)} at location {box}"
)结果如下所示:

(6) 为了便于理解。更好的方法是定义函数对结果进行可视化:
python
COLORS = [
[0.0, 0.5, 0.8],
[0.9, 0.3, 0.1],
[0.9, 0.6, 0.1],
[0.4, 0.1, 0.5],
[0.4, 0.6, 0.1],
[0.3, 0.7, 0.9],
]
def visualize_prediction(pil_img, output_dict, threshold):
keep = output_dict["scores"] > threshold
boxes = output_dict["boxes"][keep].tolist()
scores = output_dict["scores"][keep].tolist()
labels = output_dict["labels"][keep].tolist()
labels = [model.config.id2label[x] for x in labels]
plt.figure(figsize=(8, 5))
plt.imshow(pil_img)
ax = plt.gca()
colors = COLORS * 100
for score, (xmin, ymin, xmax, ymax), label, color in zip(
scores, boxes, labels, colors
):
ax.add_patch(
plt.Rectangle(
(xmin, ymin),
xmax - xmin,
ymax - ymin,
fill=False,
color=color,
linewidth=3,
)
)
ax.text(xmin, ymin, label, fontsize=8, bbox=dict(facecolor="yellow", alpha=0.5))
plt.axis("off")
plt.show()(7) 调用 visualize_prediction() 函数:
python
from matplotlib import pyplot as plt
visualize_prediction(image, results, 0.9)结果如下所示,可以看到一个带有检测结果的图像,模型已经检测并对结果进行了标注:

3.2 使用 DETR 进行语义分割
同时,DETR 模型也可以用于进行语义分割。语义分割是对图像中的每个像素进行标记并将其分配到相应类别的过程。与目标检测处理边界框中的物体不同,语义分割以像素级别的方式对物体进行处理。
(1) 首先,加载模型:
python
from transformers import (DetrImageProcessor, DetrFeatureExtractor, DetrForSegmentation)
import torch
from PIL import Image
import requests
# processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50-panoptic")
model = DetrForSegmentation.from_pretrained("facebook/detr-resnet-50-panoptic")
feature_extractor = DetrFeatureExtractor.from_pretrained("facebook/detr-resnet-50-panoptic")(2) 接下来,下载要进行分割的图像:
python
import io
import requests
from PIL import Image
import torch
import numpy
url = "https://farm4.staticflickr.com/3487/3925656789_1b64654c91_z.jpg"
image = Image.open(requests.get(url, stream=True).raw)(3) 使用处理器处理图像后,输入模型获得输出:
python
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)(4) 然后,使用以下函数提取结果:
python
processed_sizes = torch.as_tensor(inputs["pixel_values"].shape[-2:]).unsqueeze(0)
result = feature_extractor.post_process_panoptic(outputs, processed_sizes)[0](5) 可视化结果图像:
python
import itertools
import io
import seaborn as sns
import numpy
from transformers.image_transforms import rgb_to_id, id_to_rgb
from matplotlib import pyplot as plt
palette = itertools.cycle(sns.color_palette())
panoptic_seg = Image.open(io.BytesIO(result['png_string']))
panoptic_seg = numpy.array(panoptic_seg,
dtype=numpy.uint8).copy()
panoptic_seg_id = rgb_to_id(panoptic_seg)
panoptic_seg[:, :, :] = 0
for id in range(panoptic_seg_id.max() + 1):
panoptic_seg[panoptic_seg_id == id] = numpy.asarray(next(palette)) * 255
plt.figure(figsize=(12,12))
plt.subplot(121)
plt.imshow(panoptic_seg)
plt.axis('off')
plt.subplot(122)
plt.imshow(image)
plt.axis('off')
plt.show()以上代码会将模型的输出转换为适当可视化的格式,可以得到如下图像,即原始图像的语义分割结果:

小结
在本节中,我们学习了视觉 Transformer 及其在各种任务中的应用,包括语义分割、目标检测和图像分类,还介绍了 DETR、DeiT 和 ViT 等模型。
系列链接
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩
Transformer实战(33)------高效自注意力机制
Transformer实战(34)------多语言和跨语言Transformer模型
Transformer实战(35)------跨语言相似性任务
Transformer实战(36)------Transformer模型部署
Transformer实战(37)------Transformer模型训练追踪与监测