参考链接:
论文原文:RoboForge: Physically Optimized Text-guided Whole-Body Locomotion for Humanoids (arXiv preprint coming soon)
摘要: 如何让一个人形机器人仅凭一句"做一个后空翻"的文本指令,就能在现实世界中流畅、稳定地执行?当前,将文本生成动作的AI模型(如Sora在视频领域的应用)与机器人物理控制相结合,面临一个巨大的鸿沟:生成的动画看起来再优美,一旦要机器人真实执行,就可能出现脚底打滑、陷入地面、失去平衡等"物理上不可能"的问题。南洋理工大学MARS Lab的研究团队在RoboForge中提出了一套全新方案,通过一个名为物理合理性优化模块(PP-Opt) 的双向优化闭环,将"生成"与"控制"两大步骤紧密耦合,成功地在Unitree G1人形机器人上实现了更稳定、更精准的文本引导全身运动。
引言:当"想象力"遭遇"物理法则"
近年来,基于扩散模型的文本到运动生成技术取得了令人瞩目的进展,能够从文字描述中生成流畅、多样的3D人体动画。然而,将这些"视觉上合理"的动画直接应用到人形机器人上,却困难重重。
传统方法遵循"生成 -> 重定向 -> 跟踪"的流程(见Figure 1)。这种"断崖式"的串联存在三大致命伤:
- 重定向瓶颈:将人体骨架的运动数据映射到形态不同的机器人上,本身就是一项容易引入误差的工作。
- 物理不一致:动画模型不关心物理定律,允许脚底滑步、穿透地面,而这些在机器人控制中是绝对的禁忌。
- 数据稀缺:真实的机器人交互数据昂贵且难以获取。
这些问题在关键的地面接触瞬间会被急剧放大,导致机器人最终失控。RoboForge的核心洞见在于:生成和控制在物理层面应该是双向耦合、协同优化的,而非割裂的步骤。
核心创新:物理合理性优化模块(PP-Opt)
RoboForge的核心是其精心设计的物理合理性优化模块(PP-Opt) ,它像一个"双向转换器",连接着"富有想象力的"运动生成器和"务实的"机器人控制器(见Figure 2)。
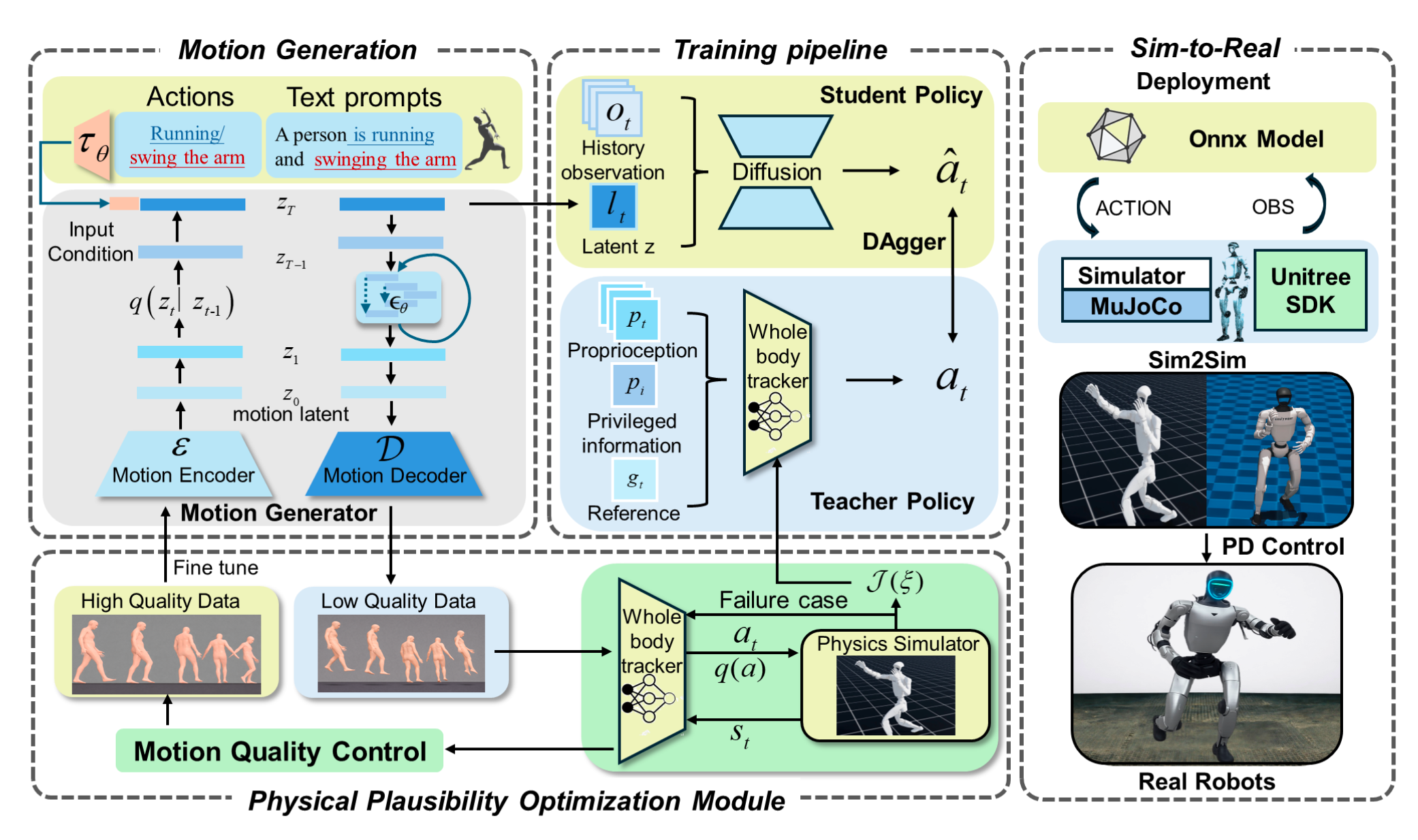
1. 前向优化:让机器人"学得会"
在"前向"流程中,PP-Opt负责训练一个全身跟踪控制器。这个控制器的目标是跟踪运动生成器给出的隐式运动潜码(Motion Latent),而不是传统的、具体的关节轨迹。
- 奖励函数驱动 :PP-Opt使用一个精心设计的物理合理性奖励函数
I(ξ),来指导控制器学习。这个函数会严厉惩罚三种常见的"非物理"行为:- 脚底打滑:在脚本该接触地面的瞬间,出现不应有的移动。
- 脚底悬浮:在脚理应接触地面时,却悬浮在空中。
- 地面穿透:脚部陷入地面以下。
- 隐式接口:控制器直接接收运动潜码作为输入,跳过了耗时且易出错的重定向环节,大大减少了误差累积。
2. 后向优化:让生成器"想得对"
这是RoboForge闭环思想最精妙的部分。经过前向优化,机器人在仿真中执行动作,会产生大量的轨迹数据。PP-Opt会筛选出那些执行得物理上合理的轨迹 ,并利用它们反过来微调(fine-tune)运动生成器。
- 运动质量控制:通过比较优化前后的运动差异,过滤掉优化失败或不合理的运动。
- 分布矫正:通过这种方式,运动生成器被"引导"去学习一个"物理上可行的"潜空间分布。它不再仅仅生成视觉上漂亮的动画,而是生成一个"机器人能稳定执行"的动画蓝图。
这个"生成 -> 执行 -> 过滤 -> 再生成"的闭环,构成了一个自我强化的飞轮:生成器生成的运动越物理可行,控制器就执行得越好;控制器执行得越好,反馈给生成器的数据质量就越高。
实验验证:效果如何?
研究者在Unitree G1人形机器人上进行了大量实验,验证了RoboForge的有效性。
1. PP-Opt能显著提升生成质量吗?
是的。与原始的MLD(Motion Latent Diffusion)模型相比,应用PP-Opt后,生成的动画在物理合理性指标上取得了巨大进步(见Table 1):
- 地面穿透 几乎降为0(从0.042到0.000)。
- 脚底悬浮 大幅减少(从1.744降至0.713)。
- 同时,生成质量指标(如R-Precision, FID)也得到提升或保持,说明它并没有牺牲语义的准确性,而是"清理"了不合理的细节。
2. PP-Opt能让跟踪控制更稳定吗?
是的。使用PP-Opt优化后的生成器数据来训练跟踪策略,机器人在两个仿真环境(IsaacLab和MuJoCo)中的表现都更好(见Table 2):
- 成功率更高(例如,MuJoCo中从0.63提升到0.71)。
- 跟踪误差更低 (例如,IsaacLab中关节位置误差从0.14降至0.11)。
这表明,PP-Opt通过清理训练数据,让学到的控制器更准确、更鲁棒。
3. 迭代优化会带来累计增益吗?
是的。论文进一步探索了将PP-Opt的闭环过程进行多个周期(Round)。结果显示,每一轮优化都会带来微小但一致的改进,在三轮后趋于饱和。这验证了闭环优化的有效性------生成器和控制器在相互促进中共同进化。
4. 隐式潜码接口比传统重定向好在哪里?
好很多。实验对比了"隐式潜码驱动"和"显式重定向"两种控制接口。结果是压倒性的:
- 隐式接口在所有指标上都优于显式重定向。
- 显式重定向引入的误差在接触瞬间被放大,导致成功率降低、跟踪误差变大。
- 隐式接口直接利用物理约束下的潜码,绕过了这个脆弱的环节,实现了更精准的控制。
总结与展望:人形机器人智能的稳健路径
RoboForge为我们展示了一条通往"文本引导人形机器人智能"的稳健路径。它的核心思想------通过一个双向的物理优化闭环,将生成式AI的"想象力"锚定在物理世界的"可行性"上------为解决机器人领域从"虚拟生成"到"真实执行"的鸿沟提供了全新的视角。
这项工作的贡献可总结为:
- 提出了一种统一的、隐式潜码驱动的框架,用直接的"潜码到动作"映射取代了传统的"解码-重定向-跟踪"流程。
- 设计了PP-Opt模块,作为连接生成器和控制器的双向桥梁,通过物理奖励函数和运动质量筛选,实现了两者性能的相互提升。
- 在真实机器人仿真平台上验证了方法的有效性,展示了在文本指令下更稳定、更精准的全身运动。
RoboForge不仅仅是技术上的突破,它更是一种思维方式的转变。它告诉我们,在构建真正"智能"的机器人时,我们不能只追求模型"生成"的想象力,更要思考如何让这份想象力在物理世界中"安全落地"。这项工作无疑为未来更复杂、更灵巧的人形机器人控制开辟了新的可能。