在 Linux 系统中,进程是操作系统进行资源分配和调度的基本单位,掌握进程控制的核心机制,是开发高性能、高稳定性系统程序的基础。本文将围绕进程创建、进程终止、进程等待和进程程序替换四大核心环节,结合底层原理、代码实例和实际应用场景,带你全面掌握 Linux 进程控制的精髓。
一、进程创建:fork 函数的 "分身术"
进程创建的核心是通过fork()函数从已存在的进程(父进程)中衍生出一个新进程(子进程),这一过程就像施展了一次 "分身术",让系统中多了一个功能独立却又与父进程有着千丝万缕联系的执行单元。
1. fork 函数的基本用法与返回值
fork()函数定义在<unistd.h>头文件中,函数原型为:
c
pid_t fork(void);其返回值是区分父子进程的关键:
- 子进程中返回 0,代表自身是新创建的子进程;
- 父进程中返回子进程的 PID(进程 ID),用于后续管理子进程;
- 调用失败时返回 - 1,通常是系统资源不足或进程数超出限制。
当进程调用fork()后,内核会完成一系列关键操作:为子进程分配新的内存块和内核数据结构(如 PCB)、拷贝父进程的部分数据结构内容(如进程上下文)、将子进程添加到系统进程列表中,最后由调度器决定父子进程的执行顺序。
2. 经典实例:fork 后的执行流
来看一个经典的fork()使用实例:
c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ((pid = fork()) == -1)
perror("fork()"), exit(1);
printf("After: pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}运行结果如下:
bash
[root@localhost linux]# ./a.out
Before: pid is 43676
After: pid is 43676, fork return 43677
After: pid is 43677, fork return 0这里出现了一行 "Before" 和两行 "After";
原因是:fork()调用前,只有父进程在执行,所以仅打印一次 "Before";fork()调用后,父子进程各自独立执行,从fork()返回处继续往下运行,因此会打印两次 "After"。需要注意的是,fork()后父子进程的执行顺序完全由系统调度器决定,无法预知。
3. 写时拷贝:高效的内存共享机制
很多人会误以为fork()创建子进程时,会完整拷贝父进程的内存空间,这会导致内存浪费和效率低下。但实际上,Linux 采用了写时拷贝(Copy-On-Write, COW)技术来优化这一过程。
写时拷贝的核心逻辑是:fork()刚执行完时,父子进程共享代码段和数据段,通过页表映射到同一块物理内存,且页表项被标记为只读。只有当任意一方试图修改数据时,内核才会为修改方分配新的物理内存页,并拷贝原数据,实现内存的独立。这种延时分配策略既保证了进程独立性,又提高了系统内存利用率,是 Linux 进程管理的重要优化。
4. fork 的常见用法与失败场景
fork()的应用场景主要有两类:
- 父子进程执行不同代码段:比如父进程监听客户端连接,每当有新连接到来时,fork()一个子进程专门处理该连接,父进程继续监听,这是网络服务器的经典设计;
- 子进程执行新程序:子进程从fork()返回后,通过调用exec系列函数替换为新的程序,实现功能扩展。
fork()调用失败的情况主要有两种:一是系统中进程数量过多,超出了内核的进程数限制;二是实际用户的进程数超过了系统对单个用户的进程数限制。因此,在实际开发中,必须对fork()的返回值进行错误处理。
二、进程终止:资源释放的 "优雅谢幕"
进程终止的本质是释放进程占用的系统资源,包括内核数据结构、内存空间、文件描述符等。进程的终止分为正常终止和异常终止两种情况,不同的终止方式对应着不同的资源清理逻辑。
1. 进程退出的三大场景
- 正常终止且结果正确:程序按预期执行完毕,达成预设目标,例如ls命令成功列出目录内容;
- 正常终止但结果错误:程序执行流程完整,但输出结果不符合预期,例如计算程序因逻辑错误得到错误结果;
- 异常终止:程序执行过程中遇到意外情况,被迫中断,例如访问非法内存、被信号终止(如Ctrl+C)。
2. 进程退出的常用方法
(1)正常终止的三种方式
- return退出:这是最常用的退出方式,main函数中的return n等价于exit(n),其中n为进程退出码;
- exit()函数:定义在<stdlib.h>中,在终止进程前会完成三项重要工作:执行atexit或on_exit注册的清理函数、关闭所有打开的文件流并刷新缓存、最终调用_exit()函数;
- _exit()函数:定义在<unistd.h>中,是最底层的退出函数,直接终止进程并释放资源,不会处理缓存或执行清理函数。
下面的实例清晰展示了exit()和_exit()的区别:
c
// 使用exit(),会刷新缓存
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("hello");
exit(0);
}
// 运行结果:hello[root@localhost linux]#
// 使用_exit(),不刷新缓存
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("hello");
_exit(0);
}
// 运行结果:[root@localhost linux]#(2)异常终止的常见情况
异常终止通常由信号触发,例如Ctrl+C会发送SIGINT信号(对应退出码 130),kill -9会发送SIGKILL信号(强制终止,进程无法捕获)。当进程收到无法处理的致命信号时,会立即终止并释放资源。
3. 退出码:进程的 "最后遗言"
退出码是进程终止时留给父进程的状态信息,通过echo $?命令可以查看最近一次执行程序的退出码。退出码的核心规则的是:0 表示执行成功,非 0 表示执行失败,不同的非 0 值对应不同的错误类型。
Linux 中常见的退出码含义:
- 0:命令执行成功,无错误;
- 1:通用错误,如权限不足、非法操作(如除以 0);
- 126:权限被拒绝,无法执行目标程序;
- 127:未找到命令或 PATH 环境变量配置错误;
- 128+n:进程被信号 n 终止(如 130=128+2,对应SIGINT信号);
- 255:退出码超出 0-255 范围,系统会自动取模计算(如_exit(-1)返回 255)。
可以通过strerror()函数获取退出码对应的具体描述,例如strerror(1)会返回 "Operation not permitted",帮助开发者快速定位问题。
三、进程等待:避免僵尸进程的 "关键一步"
子进程退出后,如果父进程未及时处理其退出状态,子进程会变成僵尸进程(Zombie Process)。僵尸进程会保留 PID 和退出状态等信息,占用系统资源,若大量存在会导致系统资源泄漏,甚至无法创建新进程。进程等待就是父进程回收子进程资源、获取退出信息的核心机制。
1. 进程等待的必要性
回收子进程资源,避免僵尸进程产生;
获取子进程的退出状态,判断任务执行结果(成功 / 失败、退出码、终止信号等);
协调父子进程执行顺序,确保父进程在需要时能获取子进程的执行结果。
2. 进程等待的两种核心方法
(1)wait 函数
wait()函数定义在<sys/wait.h>中,函数原型为:
c
pid_t wait(int* status);- 返回值:成功返回被等待子进程的 PID,失败返回 - 1;
- 参数status:输出型参数,用于存储子进程的退出状态,若不关心可设为 NULL;
- 特性:阻塞等待,父进程会暂停执行,直到有子进程退出。
(2)waitpid 函数
waitpid()函数功能更强大,支持指定子进程和非阻塞等待,函数原型为:
c
pid_t waitpid(pid_t pid, int *status, int options);- 参数pid:-1 表示等待任意子进程(与wait等效),大于 0 表示等待指定 PID 的子进程;
- 参数options:0 表示阻塞等待,WNOHANG表示非阻塞等待(子进程未退出时返回 0);
- 返回值:成功返回子进程 PID,非阻塞时子进程未退出返回 0,出错返回 - 1。
3. 解读 status 参数:子进程的 "退出报告"
status不能简单当作整数处理,其低 16 位存储了子进程的退出信息,可按位图解析:
-
低 7 位:存储终止信号(若不为 0,说明子进程被信号终止);
-
第 8 位:core dump 标志(是否生成核心转储文件);
-
高 8 位:正常退出时的退出码(仅当低 7 位为 0 时有效)。
可以通过以下宏函数快速解析status:
- WIFEXITED(status):判断子进程是否正常退出(返回非 0 为正常退出);
- WEXITSTATUS(status):提取正常退出时的退出码;
- WIFSIGNALED(status):判断子进程是否被信号终止;
- WTERMSIG(status):提取终止子进程的信号编号。
下面的测试代码展示了如何通过wait()获取子进程退出状态:
c
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int main(void)
{
pid_t pid;
if ((pid = fork()) == -1)
perror("fork"), exit(1);
if (pid == 0) { // 子进程
sleep(20);
exit(10); // 正常退出,退出码10
} else { // 父进程
int st;
int ret = wait(&st);
if (ret > 0 && (st & 0X7F) == 0) { // 正常退出
printf("child exit code:%d\n", (st >> 8) & 0XFF);
} else if (ret > 0) { // 异常退出(被信号终止)
printf("sig code : %d\n", st & 0X7F);
}
}
}运行结果:
-
等待 20 秒子进程正常退出:child exit code:10;
-
其他终端执行kill -9 子进程PID:sig code : 9。
4. 阻塞等待与非阻塞等待
-
阻塞等待:父进程调用wait()或waitpid(pid, &status, 0)后,会暂停执行,直到子进程退出,适用于父进程无需处理其他任务的场景;
-
阻塞等待:父进程调用waitpid(pid, &status, WNOHANG)后立即返回,若子进程未退出,父进程可以继续处理其他任务,之后通过循环再次检查子进程状态,适用于需要并发处理多个任务的场景(如服务器同时处理多个客户端请求)。
四、进程程序替换:换 "芯" 不换 "身" 的神奇操作
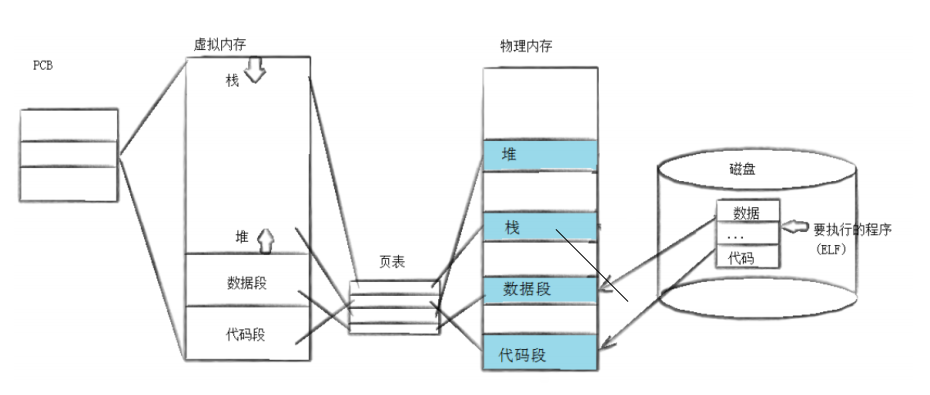
fork()创建的子进程默认执行与父进程相同的代码,但实际开发中,子进程往往需要执行全新的程序,这就需要进程程序替换机制 ------ 通过exec系列函数,将新程序的代码和数据加载到当前进程的地址空间,替换原有内容 ,实现 "换芯不换身"(PID 不变)的效果。
1. 程序替换的核心原理
当进程调用exec系列函数后,用户空间的代码段、数据段、堆和栈会被新程序完全替换,从新程序的启动例程开始执行。需要注意的是,程序替换不会创建新进程,进程的 PID、PPID、文件描述符等内核数据结构保持不变,仅进程的执行内容发生变化。
例如,子进程通过exec执行ls命令后,就变成了ls进程,但 PID 依然是原来的子进程 PID,执行完成后会退出,父进程通过wait回收其资源。
2. exec 系列函数:六种替换方式

| 函数名 | 参数格式 | 是否自动搜索 PATH | 是否使用当前环境变量 |
|---|---|---|---|
| execl | 列表形式 | 否 | 是 |
| execlp | 列表形式 | 是 | 是 |
| execle | 列表形式 | 否 | 否(需自定义 envp) |
| execv | 数组形式 | 否 | 是 |
| execvp | 数组形式 | 是 | 是 |
| execve | 数组形式 | 否 | 否(需自定义 envp) |
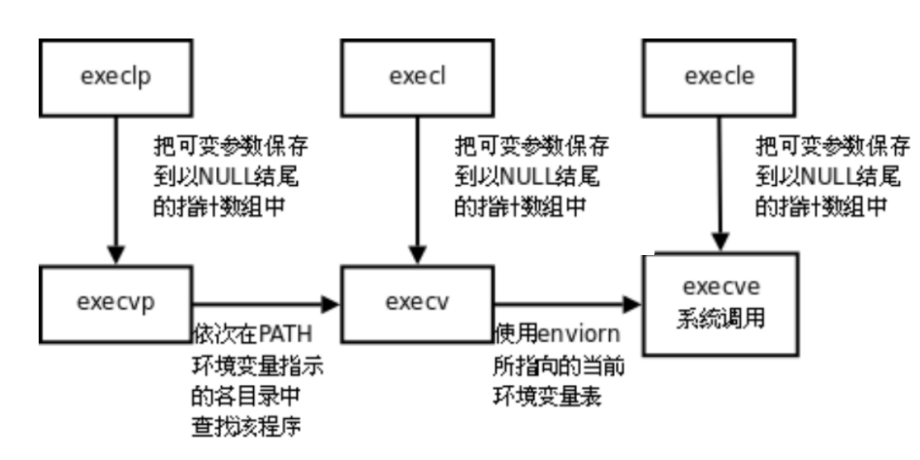
函数命名规律:
-
l(list):参数采用列表形式,以 NULL 结尾(如execl("/bin/ls", "ls", "-l", NULL));
-
v(vector):参数采用字符串数组形式(如char *argv\[\] = {"ls", "-l", NULL}; execv("/bin/ls", argv));
-
p(path):自动搜索 PATH 环境变量,无需指定完整路径(如execlp("ls", "ls", "-l", NULL));
-
e(env):自定义环境变量,需传入环境变量数组(如char *envp\[\] = {"PATH=/bin", NULL}; execle("ls", "ls", "-l", NULL, envp))。
exec函数调用成功后不会返回(代码已被替换),只有出错时才返回 - 1,因此后续通常会调用exit()处理错误。所以exec函数只有出错的返回值而没有成功的返回值。
cpp
#include <unistd.h>
int main()
{
char *const argv[] = {"ps", "-ef", NULL};
char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};
execl("/bin/ps", "ps", "-ef", NULL);
// 带p的,可以使用环境变量PATH,⽆需写全路径
execlp("ps", "ps", "-ef", NULL);
// 带e的,需要⾃⼰组装环境变量
execle("ps", "ps", "-ef", NULL, envp);
execv("/bin/ps", argv);
// 带p的,可以使用环境变量PATH,⽆需写全路径
execvp("ps", argv);
// 带e的,需要⾃⼰组装环境变量
execve("/bin/ps", argv, envp);
exit(0);
}事实上,只有execve是真正的系统调用,其它五个函数最终都调用execve,所以execve在man手册 第2节,
其它函数在man手册第3节。这些函数之间的关系如下图所示。
3. 实际应用场景
程序替换常与fork()配合使用,构成 Shell、命令行工具等的核心工作流程:
- 父进程(如 Shell)获取用户输入的命令;
- 解析命令参数;
- fork()创建子进程;
- 子进程通过exec系列函数替换为目标程序(如ls、ps);
- 父进程通过wait等待子进程执行完成,回收资源并获取退出状态。
这种模式实现了命令的并发执行和资源的高效管理,是 Linux 系统多任务处理的基础。
Linux 进程控制的四大环节 ------ 创建(fork)、终止(exit/_exit)、等待(wait/waitpid)、替换(exec)------ 环环相扣,构成了系统多任务处理的核心骨架。fork()实现进程的 "分身",exec实现进程的 "换芯",wait实现资源的 "回收",exit实现进程的 "谢幕",这四大机制的灵活运用,是编写高效、稳定的 Linux 程序的关键。
理解进程控制不仅能帮助我们解决实际开发中的问题(如避免僵尸进程、实现并发任务处理),还能让我们深入体会操作系统的资源管理与调度思想。无论是开发网络服务器、命令行工具,还是实现自定义 Shell,都离不开对这些核心机制的掌握。