导读
戴上智能眼镜,看到一家餐厅就能问"这家评分怎么样",AI 不仅看得懂还能帮你搜出来------这不是概念视频,而是一个已经跑通的开源项目。
VisionClaw 将 Meta 智能眼镜的摄像头画面实时传给 Google Gemini Live API,实现边看边聊的语音+视觉对话;同时通过本地网关 OpenClaw 接入 56 种以上技能,让 AI 不止能"看懂",还能"动手"------发消息、搜网页、加购物清单、控制智能家居,一句话完成。项目上线仅 7 周获得约 1,900 个 GitHub Star,iOS 和 Android 双平台完整实现。
本文将拆解 VisionClaw 的核心能力、技术架构设计、工程实现细节和社区生态。
项目信息
- 仓库地址 :github.com/Intent-Lab/...
- Stars:1,900
- 创建时间:2026 年 2 月 6 日
- 最近提交:2026 年 3 月 16 日
- 技术栈:Swift(iOS)/ Kotlin(Android)+ Gemini Live API + OpenClaw + WebRTC
- 许可证:自定义许可证(非标准 SPDX)
一、从"看见"到"做到":VisionClaw 能做什么
VisionClaw 的核心逻辑可以用一句话概括:眼镜负责看和听,Gemini 负责理解,OpenClaw 负责执行。
实时视觉对话。戴上 Meta 智能眼镜后,摄像头画面以约每秒 1 帧的频率(JPEG 格式,压缩质量 50%)通过 WebSocket 流式传输给 Gemini。用户可以随时通过语音提问"我面前是什么""这个标签上写了什么",Gemini 基于当前画面和对话上下文作出语音回答。音频采用 16kHz PCM 输入、24kHz PCM 输出,双向实时传输。
Agent 动作执行。当用户的请求超出"看和说"的范围------比如"帮我搜一下这家店的评价""把这个加到我的购物清单""给张三发条消息说我迟到五分钟"------Gemini 会调用工具,将任务委托给 OpenClaw。OpenClaw 是一个运行在本地 Mac 上的 Agent 网关,连接了 56 种以上技能,覆盖网页搜索、即时通讯(WhatsApp、Telegram、iMessage)、智能家居控制、备忘录、提醒等。
手机模式。没有 Meta 智能眼镜也能用。VisionClaw 支持直接调用手机摄像头作为视觉输入源,保留完整的语音+视觉+Agent 动作能力,降低了体验门槛。
第一人称直播。通过内置的 WebRTC 模块,用户可以将眼镜的实时画面分享到浏览器,生成一个 6 位房间码即可让远程观众看到佩戴者的第一视角,支持双向音视频。
二、技术架构:Gemini Live + OpenClaw 的双层设计
VisionClaw 的架构分为三层:感知层 (Meta 智能眼镜 + 手机)、理解层 (Gemini Live API)、执行层(OpenClaw)。
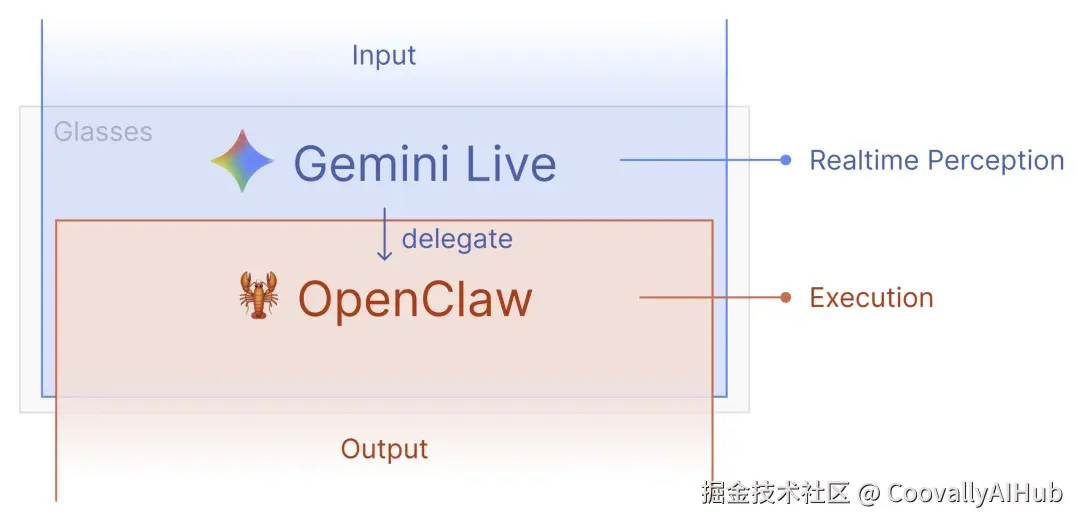
图片来源于Github Intent-Lab/VisionClaw 项目原文
感知层:Meta DAT SDK
Meta 智能眼镜的摄像头和麦克风数据通过 Meta 官方的 Wearables DAT SDK(Device Access Toolkit)获取。这个 SDK 目前处于开发者预览阶段,支持标准版和 Display 版,提供视频帧流(CMSampleBuffer,iOS 原生视频帧数据格式)、自适应码率和后台运行等能力。Android 端通过 GitHub Packages 分发。
VisionClaw 在本地以 24fps 接收眼镜视频流(手机摄像头模式为 30fps),但传给 Gemini 时降采样到约 1fps(每秒发送一帧),以平衡 API 带宽和视觉理解的实时性。
理解层:Gemini Live API
这是整个系统的核心。VisionClaw 通过 WebSocket 连接 Gemini 的 BidiGenerateContent接口(双向生成内容),使用的模型是 gemini-2.5-flash-native-audio-preview-12-2025。
从源码(GeminiLiveService.swift)可以看到,连接建立后发送的 setup 消息包含以下关键配置:
- 响应模态 :仅音频(
responseModalities: ["AUDIO"]),确保 AI 以语音回答 - 语音活动检测 :自动检测用户开始/停止说话,起始敏感度设为高(
START_SENSITIVITY_HIGH),结束敏感度设为低(END_SENSITIVITY_LOW),静音 500ms 后判定说话结束 - 打断处理 :用户开始说话时立即打断 AI 当前回复(
START_OF_ACTIVITY_INTERRUPTS) - 转写:同时输出用户语音和 AI 语音的文字转写
- 思考预算 :设为 0(
thinkingBudget: 0),追求最低延迟
值得注意的是上下文窗口压缩 的设计。Gemini Live 的 WebSocket 会话在持续音视频输入下,约 4 分钟即会触达 128K token 上限导致断连。VisionClaw 通过配置滑动窗口压缩(slidingWindow.targetTokens: 80000)来维持长时间会话------当上下文超过目标 token 数时,早期内容会被压缩而非丢弃,避免频繁断连重连。
执行层:单工具设计 + OpenClaw 网关
这里是 VisionClaw 最有意思的设计决策:Gemini 只注册了一个工具------execute。
从 ToolCallModels.swift的工具声明可以看到,这个工具的描述是"Your only way to take action... use this tool for everything"。无论用户要求搜索、发消息还是控制智能家居,Gemini 都通过同一个 execute工具将自然语言描述的任务委托出去。
这个设计选择意味着:Gemini 不需要知道下游有哪些具体能力,它只需要判断"用户的需求是否需要采取行动",然后用自然语言描述任务交给 OpenClaw 处理。这大幅简化了 Gemini 端的工具管理,也让下游技能的扩展完全解耦。
OpenClawBridge.swift的实现显示,OpenClaw 使用与 OpenAI 兼容的 /v1/chat/completions接口,VisionClaw 通过 HTTP POST 将任务发送给运行在本地 Mac 上的 OpenClaw 网关。每次会话维护最多 10 轮对话历史(maxHistoryTurns = 10),并通过固定的 session key(agent:main:glass)和 channel header(glass)保持会话连续性。
整个数据流可以简化为:
眼镜摄像头/麦克风 → 手机(DAT SDK)→ Gemini Live(WebSocket)→ 工具调用 execute→ OpenClaw 网关(HTTP)→ 真实世界动作
三、工程细节:解决可穿戴 AI 的实际问题
把 AI Agent 塞进眼镜的想法不难,难的是让它在真实场景中持续稳定运行。VisionClaw 的 commit 记录反映了开发者在解决这些实际问题上的迭代过程。
后台运行 。智能眼镜场景下,用户不可能一直盯着手机屏幕。VisionClaw 在 2026 年 3 月 7 日的一系列提交中实现了后台视频流支持------当手机锁屏时,通过 VTDecompressionSession(iOS 硬件视频解码接口)解码 HEVC(高效视频编码)帧,并切换到 CPU 渲染策略,保证 Gemini 持续接收画面。
回声消除 。默认情况下 AI 的语音回复通过蓝牙耳机(眼镜扬声器)播放,不会被麦克风拾取。但在 iPhone 模式下(音频通过手机扬声器播放),使用 .voiceChat音频会话模式进行回声消除,并在 AI 说话时静音麦克风,避免 AI 听到自己的声音形成回声循环。
音频独占模式。3 月 16 日新增的 Audio-Only 模式允许用户关闭视频流只保留语音对话,在不需要视觉理解时显著降低功耗和带宽消耗。
WebRTC 直播。通过 Node.js 信令服务器和 TURN 中继(使用 ExpressTURN 免费方案,每月 1000GB 流量),实现了 FaceTime 风格的双向视频画中画效果。用户生成房间码后,远程观众在浏览器中输入即可观看第一人称视角。
双平台对等 。Android 端在 2026 年 2 月 18 日一次性完成了完整的功能移植,包括 GeminiLiveService.kt、AudioManager.kt、OpenClawBridge.kt等核心模块的 Kotlin 重写,随后 3 月 16 日同步跟进了上下文压缩和音频独占模式。
四、社区反馈:开发者在用它做什么
从 GitHub Issues 来看,社区活跃度和开发者响应速度都较高。主要反馈集中在几个方向:
- 连接与适配:智能眼镜的蓝牙配对和连接稳定性是用户反馈最多的问题,这也反映了 Meta DAT SDK 仍处于早期阶段的现实
- 功能扩展:音频独占模式(已实现)、传感器权限管理、新用户引导页等需求持续涌现
- 社区贡献:有开发者提交了 Android Quick Settings 快捷启动、高尔夫球场 AI 球童模式等 PR,说明项目已开始吸引外部贡献者基于它做垂直场景的扩展
- 新方向探索:有开发者表示正在基于 VisionClaw 做实时翻译方向的尝试
五、总结与思考
VisionClaw 展示了一个完整的可穿戴 AI Agent 实现路径:用智能眼镜的摄像头和麦克风作为感知入口,Gemini Live API 作为实时多模态理解引擎,OpenClaw 网关作为动作执行层,三者通过 WebSocket 和 HTTP 串联成"感知→理解→决策→执行"的 Agent 闭环。
"可穿戴设备 + 多模态大模型 + Agent 工具调用"这个组合,正在成为可穿戴 AI 领域一个值得关注的方向。随着实时多模态能力持续增强、智能眼镜硬件加速普及,类似的项目可能会越来越多地出现。VisionClaw 的价值在于,它已经把这条路径从概念走通到了可运行的开源实现。