这一章会带你沿着"维度轴"再往前走一步。你是从最原始的 Transformer------也就是语言------出发的,然后走到了时间序列;接着你又探索了视觉和视频;现在,你要进入音频领域了。先剧透一句:Transformer 再一次展现出了惊人的适应性。事实证明,无论你建模的是离散 token、图像 patch,还是声谱图帧,底层逻辑都没有变。这正是 Transformer 的优雅之处:你改变的是轴,但不是基本架构。我相信,到现在你应该已经亲眼看到了:Transformer 不只是一个模型,它更像是一种抽象框架。这也是为什么它不是一阵短暂潮流,而是一种能够跨领域统一建模与泛化的新方法。
音频之所以特别有意思,是因为它正好位于时间结构与频谱表示的交叉点上。乍一看,音频似乎就是一种经典时间序列------也就是波形随时间变化------但它真正的丰富性其实在频率域中。这也是为什么许多音频模型会先把原始波形转换成声谱图(spectrogram)或 mel 频率特征,然后再进行 token 化。
声谱图展示的是:一个信号中不同频率成分的能量如何随时间变化,也就是用时间---频率联合视角来观察声音。mel 频率表示则会把这些频率映射到一个更符合人类听觉感知的尺度上,它会更强调低频部分,因为人耳对低频更敏感。图 6-1 对比了电子舞曲(EDM)与古典音乐的声谱图和 mel 声谱图,你可以明显看到它们呈现出不同的频谱模式。具体来说,EDM 信号会呈现出密集而重复的垂直条纹,代表在广泛频段上持续出现的高能量节拍;而古典音乐的信号则更细腻,能量随时间变化更丰富,且主要集中在低频区域。正是这种作为"原始声音数据形式"的表示,让 Transformer 模型能够对环境声音进行分类、识别语音模式,甚至连贯且可控地生成不同音乐风格。
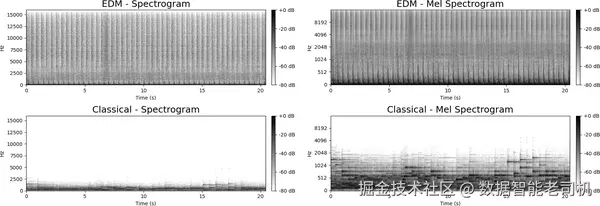
图 6-1. EDM 与古典音乐 20 秒片段的对比,每个片段都分别展示了线性声谱图(左)和 mel 声谱图(右)。
在这一章中,你会了解一系列核心音频任务,包括文本转语音(TTS)、自动语音识别、语音转文本(S2T)、语音情感识别,以及音乐生成。为了聚焦现代架构,像 Whisper 这样的经典模型只会被简要介绍。
虽然 Whisper 至今仍然被很多 SOTA 模型用作编码器,但我会把重点转向更新一代的音频基础模型。这些模型可以在同一套架构中处理多种任务。它们通常被称为大型音频---语言模型(LALM),其中包括 Qwen2-Audio 和 Kimi-Audio。这类模型已经不再局限于单任务处理,而是展示出跨识别、生成、分类和音频---语言对齐的统一能力。本章也会介绍基于 Transformer 的音乐生成模型,并展示如何通过文本来生成在长程结构与风格控制上都更加连贯的音乐序列。
和时间序列一样,音频模型也必须在长上下文中推理、适应不同采样率,并处理变长输入。但与时间序列不同的是,音频更加稠密、更依赖感知细节,而且往往还是多通道的。这让问题更复杂,同时也为生成模型带来了非常强大的机会,使其能够生成极具真实感的输出。
从波形到声谱图:理解音频数据的结构
在处理音频数据时,尤其是在基于 Transformer 的建模场景下,理解音频信号的结构与特性非常重要。本节会从概念和数学两个层面,概览数字音频的基本形式,包括它在时域与频域中的性质,以及在送入模型之前常见的各种变换。
作为波形的音频
声音本质上是空气压力随时间变化而形成的连续信号。在数字音频中,这种连续信号会在离散的时间点上进行采样,从而形成一个数值序列,这个序列就叫波形(waveform)。波形表示的是:振幅(也就是响度)如何随时间变化。图 6-2 展示了不同音乐风格对应的波形。
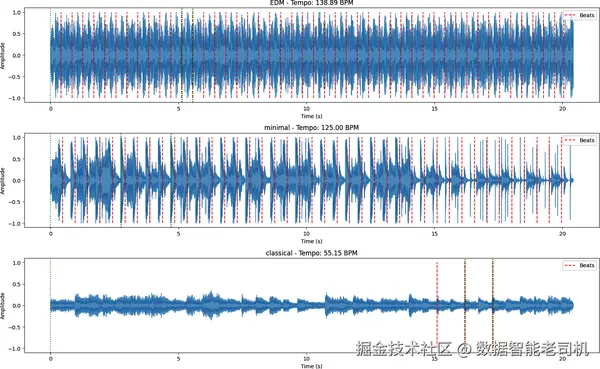
图 6-2. 不同音乐类型会展现出不同的波形结构。图中展示的是 EDM、极简 techno 和古典音乐的 20 秒片段。它们的节奏和韵律模式差异明显:EDM 有快速而稳定的脉冲;极简 techno 更偏 groove,振幅变化更动态;古典音乐则呈现出更流动、低节奏、细微动态更丰富的结构。这些差异正是 Transformer 模型可以学习、识别、分类,甚至在适当表示下复现的内容。
从数学上说,一个被采样后的音频信号可以表示为一串振幅值:
xn=x(nT),n=0,1,2,...,N−1
这里, x(nT) 表示时间 t=nT 处采样得到的振幅值,其中 T=fs1 是采样间隔,而 fs 是采样率,单位为 Hz(每秒采样数)。
一个音频信号的时长 D(单位为秒)则为:
D=fsN
例如,在 16,000 Hz 的采样率下,一个 5 秒音频片段就包含 80,000 个离散采样点。
采样率与 Nyquist 定理
采样率决定了信号中能够被准确捕捉到的最高频率。这一约束由 Nyquist 定理决定:为了避免混叠(aliasing),采样率必须至少是信号中最高频率的两倍:
fmax≤2fs
这个上界 2fs 被称为 Nyquist frequency。对于通常低于 8 kHz 的语音信号来说,16 kHz 的采样率一般就足够了。更高的采样率(例如音乐中常见的 44.1 kHz)可以保留更多细节,但也会增加内存和计算成本。
振幅、位深与量化
每一个采样值都对应某一时刻信号的振幅,通常用分贝(dB)来衡量。在数字音频中,振幅会被量化为离散级别,而这些级别由位深(bit depth)决定。表 6-1 展示了概览。
表 6-1. 数字音频中的位深与振幅分辨率
| 位深 | 振幅值数量 | 用途 |
|---|---|---|
| 16-bit | 65,536 | 标准音频(如 CD 音质) |
| 24-bit | 16,777,216 | 专业级音频录制 |
| 32-bit float | 理论上约 42.9 亿 | 高动态范围、基于机器学习的合成与训练 |
量化会引入一种噪声,这种噪声在低位深下更明显。形式上,量化误差 (\epsilon) 定义为:
ϵn=xn−x^n
这里, xn 是原始信号, x^n 是量化后的版本。位深越高,平均而言 ∣ϵn∣ 就越小。
频域与 Fourier 变换
Fourier 变换会把一个音频信号分解成它所包含的各个频率成分。当这个过程应用在离散信号上时,它就叫离散 Fourier 变换(DFT)。长度为 N 的信号 xn 的 DFT 定义如下:
Xk=n=0∑N−1xne−j2πkn/N,k=0,1,...,N−1
其中, ∣Xk∣ 给出了第 k 个频率成分的幅度,而相位则编码在复数角度中。
图 6-3 展示了一段小号(trumpet)音符的频谱图,其中谐波会以峰值形式显现出来。 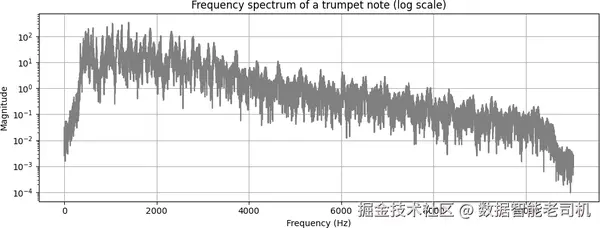
图 6-3. 小号音符的频谱(对数坐标)。
Python 中的音频与音乐信号分析
Librosa 是一个用于音乐和音频分析的 Python 包,专门支持音乐信息检索(MIR)系统的开发。它提供了丰富的信号处理工具,包括:加载和播放音频、计算声谱图、提取特征、检测 onset 和 beat、分离谐波与打击乐源,以及可视化音频数据。
声谱图与短时 Fourier 变换
为了观察频率如何随时间变化,通常会计算短时 Fourier 变换(STFT)。STFT 会把信号切成带重叠的多个窗口,并对每个窗口分别应用 DFT,于是就得到一个声谱图:
S(m,ω)=n=−∞∑∞xnwn−me−jωn
其中, wn 是窗函数,例如 Hanning window,而 m 表示窗口位置索引。Hanning window 是一种平滑的钟形函数,用来作用在信号片段上,从而减少边界不连续性,并在 Fourier 分析时尽量降低频谱泄漏。声谱图本质上是一个二维矩阵:横轴表示时间,纵轴表示频率,而颜色强度表示幅度。图 6-4 展示了一个小号信号的声谱图,可以看到它的频率内容是如何随时间变化的。
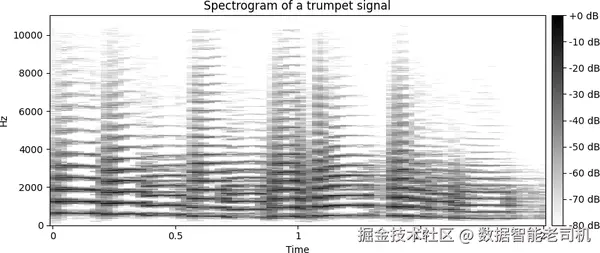
图 6-4. 小号信号的声谱图。
Mel 声谱图与感知尺度
Mel 声谱图是一种经过感知加权的声谱图,它把线性频率映射到 mel 尺度,而 mel 尺度是对人类听觉敏感度的近似。Mel 频率 m 的公式是:
m=2595⋅log10(1+700f)
这会强化低频,因为人类对低频更敏感。Mel 声谱图广泛用于语音处理、自动语音识别和音频分类任务。图 6-5 展示了一个示例。
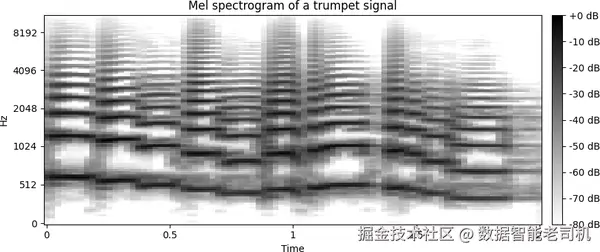
图 6-5. 小号信号的 mel 声谱图。
相位、重建与 Vocoder
基于声谱图的表示通常会丢弃相位信息,但相位其实对精确重建波形非常关键。Vocoder 是一种模型或算法,它会根据声谱图等声学特征重建音频波形,通常需要同时处理相位和振幅,才能生成可懂或自然的语音。虽然从原理上说,STFT 产生的是复数值,其中同时编码了振幅与相位,但在很多机器学习流水线中,模型往往只处理幅度谱,或者由其派生出的 mel 声谱图。传统信号处理方法,例如 Griffin-Lim 这类迭代式相位估计算法,会尝试去近似补回缺失的相位,但通常会产生伪影,感知质量也不高。Griffin-Lim 算法本质上是一种相位重建方法,它通过反复约束声谱图一致性,利用 STFT 中频率 bin 之间的冗余来迭代估计相位。当一个声谱图保留了 STFT 原有的频率 bin 依赖关系时,就称它是一致的。不过,尽管 Griffin-Lim 在早期 TTS 系统中被广泛使用,如今它的感知质量通常被认为明显弱于现代学习型 vocoder。在现代深度学习管线中,这种"同时生成合理相位和振幅"的复杂任务,已经由神经 vocoder 接手。
为了理解这些声谱图表示是如何得到的(包括幅度和相位),可以看示例 6-1 中 STFT 的核心组件。这个实现抽象自 Mooncast 的原始代码。
示例 6-1. 简化版短时 Fourier 变换
ini
class SimplifiedSTFT(nn.Module):
def __init__(
self,
n_fft: int,
hop_length: int,
win_length: int,
center: bool = True,
):
super().__init__()
self.n_fft = n_fft
self.hop_length = hop_length
self.win_length = win_length
self.center = center
window = torch.hann_window(win_length)
self.register_buffer("window", window)
def forward(self, x: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
stft_spec = torch.stft(
x,
self.n_fft,
hop_length=self.hop_length,
win_length=self.win_length,
window=self.window,
center=self.center,
return_complex=False,
)
real_part = stft_spec[:, :, :, 0]
imag_part = stft_spec[:, :, :, 1]
magnitude = torch.sqrt(real_part.pow(2) + imag_part.pow(2) + 1e-5)
phase = torch.atan2(imag_part, real_part)
return magnitude, phase- 创建 Hann window(STFT 中常用)。
- 把 window 注册成 buffer,这样它会随模型一起保存。
- 使用 PyTorch 内置函数执行 STFT。
- 不直接使用复数张量,而是把实部和虚部分开处理。
- 从最后一个维度中取出实部和虚部。
- 计算幅度(加入 epsilon 保证数值稳定)。
- 使用
atan2计算相位,以正确覆盖所有象限。
上面的 SimplifiedSTFT 类展示的是分析过程:如何把原始波形转换成幅度和相位两个声谱图分量。从内部机制上看,STFT 会把信号分解为实部和虚部,它们分别对应对余弦基函数和正弦基函数的投影。这里的"虚部"不是日常语言中的"虚构",而是来自复数的数学定义,即乘以虚数单位 j,表示在复平面中旋转 90 度。实部和虚部共同构成一个复数表示,用于同时编码每个频率成分的振幅和相位。虽然相位信息在这里被显式计算出来,但很多下游机器学习模型通常还是只处理幅度,或者由幅度进一步转换得到的 mel 声谱图,因为它更容易解释,也与人类感知更相关。但这种简化也意味着:后续必须有足够强的重建机制。
波形重建则需要用到逆短时 Fourier 变换(ISTFT):
xn=m∑S(m,ω)wn−mejωn
正如示例 6-2 中的 SimplifiedISTFT 类所展示的,只有在输入的复数声谱图中同时准确提供了幅度和相位时,这种逆变换(不论是自定义实现,还是在支持的情况下使用 torch.istft)才能得到真实感较强的结果。而当你手里只有幅度谱,或者是生成模型产生的 mel 声谱图时,就必须借助神经 vocoder。
示例 6-2. 简化版逆短时 Fourier 变换
ini
class SimplifiedISTFT(nn.Module):
def __init__(
self, n_fft: int, hop_length: int, win_length: int, center: bool = True
):
super().__init__()
self.n_fft = n_fft
self.hop_length = hop_length
self.win_length = win_length
self.center = center
window = torch.hann_window(win_length)
self.register_buffer("window", window)
def forward(self, complex_spec: torch.Tensor) -> torch.Tensor:
waveform = torch.istft(
complex_spec,
self.n_fft,
hop_length=self.hop_length,
win_length=self.win_length,
window=self.window,
center=self.center,
)
return waveform- 为逆变换创建 Hann window。
- 把它注册成 buffer(确保保存在模型状态中)。
- 应用逆 STFT,从复数声谱图重建波形。
- 输出时域波形(形状为
[Batch, Time])。
Vocoder 会学习推断一种合理的相位信号,使它与输入的频谱结构对齐,从而补上缺失相位,并通过 ISTFT 过程重建出高保真音频波形。这些 vocoder 可以是自回归的(如 WaveNet)、基于 GAN 的(如 HiFi-GAN),也可以基于扩散等其他生成技术。如今,它们已经成为 TTS、音乐生成和音频修复任务中的标准组件,负责联合生成合理的相位和振幅。
现在你已经理解了音频是如何被表示和重建的,接下来的问题就是:你到底能拿它做什么?换句话说,音频领域里的核心机器学习任务有哪些?而 Transformer 又是如何嵌入其中的?
和语言任务类似,音频任务也覆盖了多个方向:分类、生成、识别、翻译等等。区别主要在于输入表示不同。下一节会带你快速浏览其中的主要类别。
不同应用领域中的音频建模
基于 Transformer 的模型,正在像重塑语言和视觉那样,重塑音频任务的整个版图。音频既有连续形式,也有离散形式,因此它支持一系列覆盖语音、音乐和一般声音处理的任务,包括分类、生成、识别和翻译。本节会概览这些核心音频任务,并附上简要应用示例。
文本转语音(TTS)
文本转语音会把书面文本转换成语音音频。典型应用包括语音助手、有声书、无障碍工具,以及交互式系统。高质量 TTS 不仅要能说出来,还需要控制情感、说话人身份和韵律(prosody),因此它是一个很典型的条件生成任务。所谓 prosody,也就是语音的"旋律":包括节奏、重音、语调和强调方式,它们共同塑造了我们对说话内容、情绪和意图的感知。
自动语音识别(ASR)
自动语音识别会把口语音频转写成文本。应用包括转录工具、字幕、会议纪要和免手控制。Whisper 是一个非常强的多语言基线模型,它在噪声环境和口音变化下都表现得很好。
语音翻译(ST)
语音翻译会把一种语言的口语音频翻译成另一种语言的文本或语音。传统管线通常是先做 ASR,再做机器翻译,必要时再加一层 TTS。而现在,Transformer 模型越来越多地支持端到端语音翻译。这对于实时翻译、全球交流工具和多语言无障碍支持都很关键。
语音情感识别(SER)
语音情感识别会根据音高、语速和 prosody 等语音线索,检测说话者的情绪,比如喜悦、愤怒、悲伤或中性。它被广泛用于客服、人机交互和自适应学习系统。
说话人识别与说话人分离(diarization)
说话人识别用于判断"谁在说话";而 diarization 则进一步把音频按说话人轮次分段。这类任务通常使用基于 embedding 的方法,例如 x-vectors 或 ECAPA,并经常结合 Transformer 进一步精炼。它们在会议转录、呼叫中心分析和法庭音频等场景中很有价值。
音乐生成
音乐生成是指根据符号输入或文本提示来创作音乐。像 MusicGen 这样的 Transformer 模型能够生成在流派、节奏和结构上都连贯的音乐序列。其应用包括配乐生成、交互式音乐工具和数字作曲。
音频分类
这类任务会给音频片段打标签,比如流派、乐器,或者环境声音(如警笛、雨声)。它广泛用于智能设备、声学监控、声音标签和媒体整理。
音频分割与事件检测
这类任务负责识别某些事件发生的时间位置,比如语音起点、枪声或音乐段落切换。Transformer 能建模长上下文序列和事件共现关系,因此适用于监控、播客索引和场景分析。
这些任务的输出各不相同,但它们的输入通常都很相似,例如波形或声谱图。接下来的关键问题是:Transformer 模型到底如何处理这些表示?从 Whisper 这种相对专用的系统,到 Qwen2-Audio 和 Kimi-Audio 这样的基础模型,架构已经发生了快速演进。
音频中的 Transformer 架构:从感知到基础智能
这一节会把你对音频表示形式的理论理解,连接到它们在 Transformer 模型中的具体应用上。你会先从 Whisper 这类任务特化模型开始,它为语音识别和语音翻译中的鲁棒性建立了新标准。然后,你会看到更新一代的音频基础模型,是如何跳出单一目标,开始统一语音、音乐和一般声音理解能力的。这些模型不只是"转写"或"生成",它们开始具备倾听、推理和结合上下文进行响应的能力,同时还拥有长程记忆和多模态对齐能力。
语音 Transformer 的崛起:Whisper 的影响
Whisper 通过一套稳健的基于 Transformer 的架构,标志着 ASR 和音频翻译的重要进展。与早期那些严重依赖监督微调、或单纯依赖无监督预训练的系统不同,Whisper 展示了:如果把大规模弱监督数据,与一个强大的 encoder-decoder Transformer 结合起来,就能够重新定义语音处理中的泛化能力与鲁棒性边界。
从结构上看,Whisper 接收的音频输入会先被转换成 mel 声谱图,这种表示非常适合 Transformer。声谱图先经过卷积层,再被 Transformer block 编码。解码器则在音频编码和先前文本的条件下,生成转录结果或翻译结果。这种 sequence-to-sequence 方式,把转录、翻译和语音活动检测等任务统一进了一条语音管线里,也让这些任务的性能表现更加一致。Whisper 的整体架构见图 6-6。
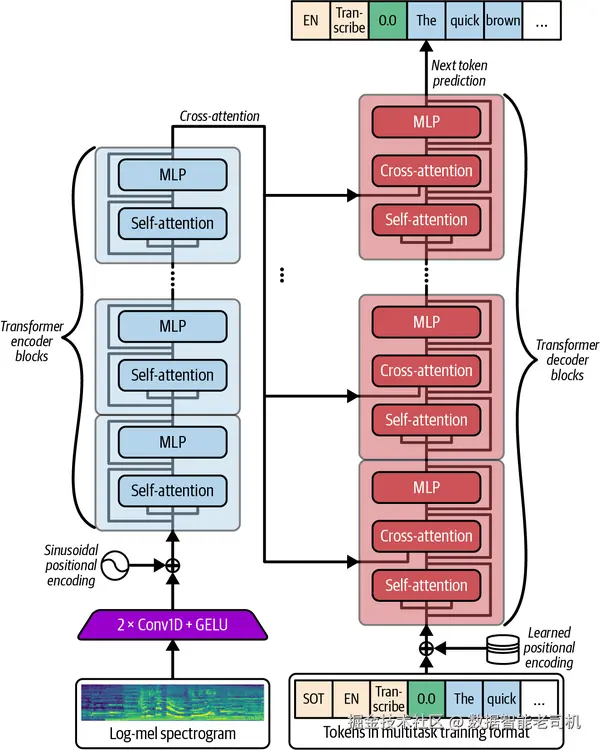
图 6-6. Whisper 的统一 token 预测架构可以同时处理多语言 ASR、翻译、语言识别和语音活动检测。图片改编自 Alec Radford 等人(2022)。
在实践中,Whisper 通过两个核心步骤,把信号桥接成序列:先把音频转换成 mel 声谱图,再把声谱图解码成文本。示例 6-3 展示了如何把音频转换成可供 Transformer 使用的表示,而示例 6-4 则展示了如何利用已学习到的多语言、多任务先验来执行推理解码。这两个函数都基于 Whisper 原始代码做了简化,目的是说明核心机制。
示例 6-3. 简化版 log-mel 声谱图计算
ini
def log_mel_spectrogram(audio: torch.Tensor, sample_rate:
int = 16000) -> torch.Tensor:
mel_spec = torchaudio.transforms.MelSpectrogram(
sample_rate=sample_rate,
n_fft=400,
hop_length=160,
n_mels=80
)(audio)
log_mel_spec = torch.log1p(mel_spec)
return log_mel_spec- 把波形转换成 mel 声谱图,使用 25 ms 窗口和 10 ms 步长。
- 施加对数缩放,以强化感知上的响度差异。
- 输出 80 通道的 log-mel 声谱图,作为 Whisper 的输入。
示例 6-4. 面向 mel 声谱图输入的简化版 Whisper 解码
less
@torch.no_grad()
def decode(
model: "Whisper",
mel: torch.Tensor,
options: DecodingOptions = DecodingOptions(),
**kwargs,
) -> Union[DecodingResult, List[DecodingResult]]:
if single := mel.ndim == 2:
mel = mel.unsqueeze(0)
if kwargs:
options = replace(options, **kwargs)
result = DecodingTask(model, options).run(mel)
return result[0] if single else result- 关闭梯度跟踪,以优化推理过程(不需要反向传播)。
- 如果输入是单个 mel 声谱图,则加上 batch 维度。
- 如果有额外参数,则覆盖默认解码选项。
- 在输入上运行 Whisper 的解码流程。
- 返回解码结果,同时兼容单样本和 batch。
音频基础模型:统一理解、生成与对话
很多年来,AI 模型总是把语音识别、情感检测或声音事件分类这些音频任务当成彼此独立的问题来解决,每个任务都需要专门的系统和方法。但就像自然语言处理领域后来出现了能够统一处理多种文本任务的大语言模型一样,音频处理也在经历类似的革命。
这种变化的推动力,正是 LALM,也就是音频基础模型。它们通常是强大的基于 Transformer 的系统,目标是把多种音频相关能力统一进一个整体框架中。与上一代模型不同,这些模型被设计为能够处理各种音频信号、理解其中不同的内容、分析声音本身,甚至基于自然语言指令,直接生成文本回应,或者生成新的音频。
像 Qwen2-Audio 和 Kimi-Audio 就属于这一类新范式模型。它们利用海量数据进行训练,通常达到数百万小时级别,数据覆盖语音、环境音和音乐。通过在预训练阶段引入自然语言 prompt,这些模型获得了极强的指令跟随能力。无论面对的是多个声音同时出现的音频片段、多说话人对话、语音命令,还是开放式语音聊天,它们都能够理解音频内容并做出相应响应。
Qwen2-Audio
从结构上看,Qwen2-Audio 是一个 82 亿参数的音频---语言模型,它可以接收音频和文本输入,并输出文本结果。它的架构由音频编码器和一个大语言模型组成。其中,音频编码器初始化自 Whisper-large-v3。对于原始音频,它会先把波形重采样到 16 kHz,再转成 128 通道的 mel 声谱图,然后通过一个池化层来缩短表示长度。语言模型部分则基于 Qwen-7B。
Qwen2-Audio 会针对不同数据和任务使用自然语言 prompt。这种策略,再加上更大规模的训练数据,以及后续使用直接偏好优化(DPO)的指令微调,共同提升了模型的指令跟随能力与泛化能力。图 6-7 展示了这一训练过程。
Qwen2-Audio 提供了两种不同交互模式,以支持更灵活的用户使用方式。在音频分析模式下,它可以接收多种音频类型(语音、环境音、音乐或混合音频),再结合文本或语音指令进行分析。模型甚至可以直接从音频中识别出命令,并给出解释与回应。在语音聊天模式下,用户则可以不输入任何文本、也不手动切换模式,就直接与模型进行开放式多轮语音对话。
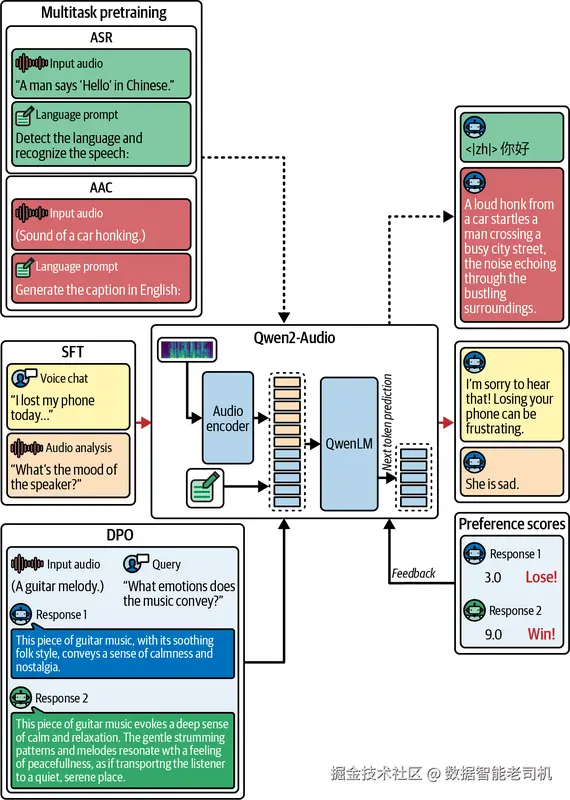
图 6-7. Qwen2-Audio 的训练流程。图片改编自 Yunfei Chu 等人(2024)。
示例 6-5 展示了 Qwen2-Audio 的不同使用场景。
示例 6-5. Qwen2-Audio 的典型用法
ini
processor = AutoProcessor.from_pretrained("Qwen/Qwen2-Audio-7B-Instruct")
model = Qwen2AudioForConditionalGeneration.from_pretrained(
"Qwen/Qwen2-Audio-7B-Instruct", device_map="auto"
)
conversation1 = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs
.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
{"type": "text", "text": "What's that sound?"},
]},
]
conversation2 = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs
.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
{"type": "text", "text": "What does the person say?"},
]},
]
conversation3 = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "/content/gunshots.wav"},
{"type": "text", "text": "What is that sound, and what does the person say?"},
]},
]
conversations = [conversation1, conversation2, conversation3]
text = [processor.apply_chat_template(conv, add_generation_prompt=True,
tokenize=False) for conv in conversations]
sr = processor.feature_extractor.sampling_rate
audios = []
for conversation in conversations:
for message in conversation:
if isinstance(message["content"], list):
for ele in message["content"]:
if ele["type"] == "audio":
audio_path = ele['audio_url']
if audio_path.startswith("http"):
# Remote URL
audio, _ = librosa.load(BytesIO(urlopen(audio_path).
read()), sr=sr)
else:
# Load local file
if not os.path.exists(audio_path):
raise FileNotFoundError(
f"Local audio file not found: {audio_path}")
audio, _ = librosa.load(audio_path, sr=sr)
audios.append(audio)
inputs = processor(text=text, audio=audios, return_tensors="pt",
padding=True)
device = model.device
inputs = {k: v.to(device) if isinstance(v, torch.Tensor) else v for
k, v in inputs.items()}
generate_ids = model.generate(**inputs, max_new_tokens=512)
generate_ids = generate_ids[:, inputs["input_ids"].size(1):]
responses = processor.batch_decode(generate_ids, skip_special_tokens=True,
clean_up_tokenization_spaces=False)
for i, r in enumerate(responses):
print(f"Response {i+1}: {r}")- 进行 batch 处理。
- 生成响应。
- 解码输出。
模型输出如下:
vbscript
Response 1: It is the sound of glass breaking.
Response 2: The original content of this audio is: "Mister Quiller is the apostle of the middle classes and we are glad to welcome his gospel."
Response 3: In the audio, there is the sound of gunfire and artillery fire happening in the distance, and a male voice speaking English saying: "Can you guess where I am right now?", with a neutral mood.这些响应都是正确的。两个带口语内容的示例(conversation2 和 conversation3)都被准确转写出来了。除此之外,在第三个例子中,模型还正确预测了说话人的情绪,也就是说它同时完成了 SER。这在分析说话人是否处于困境中会非常有帮助,尤其是考虑到背景里还有枪声。
图 6-7 所示的 Qwen2-Audio 训练设置,由音频编码器和大语言模型组成。对于一对音频与文本序列 (a,x),其中 a 表示音频输入, x 表示对应文本,模型的目标是预测文本序列中的下一个 token。训练目标可以写成:在给定音频表示和前文 token 的条件下,最大化下一个 token 的条件概率:
Pθ(xt∣x<t,Encoderϕ(a))
这里, θ 和 ϕ 分别表示语言模型和音频编码器的可学习参数。
这种统一方式,使得 Qwen2-Audio 能够理解复杂音频内容,即使面对重叠声音、多说话人对话和语音命令,也能像示例 6-5 里的 conversation3 那样,做出恰当响应。
使用 Kimi-Audio 转录会议
在 Qwen2-Audio 之后,Kimi-Audio 是另一款开源音频基础模型,于 2025 年 4 月发布,具备音频理解、音频生成和音频对话能力。Kimi-Audio 直接针对以往工作的几个限制做出回应:它强调真正通用的任务覆盖、大规模多模态预训练,以及完整开源可得性。
Kimi-Audio 使用一套统一架构,主要由三个核心部分组成:
音频 tokenizer
这一部分会把原始输入音频转换成双重表示。一方面,它会产生离散的语义音频 token,帧率较低,为 12.5 Hz;这些 token 来源于一个在 Whisper 编码器架构中通过向量量化实现的监督式语音 tokenizer。另一方面,它还会生成互补的连续声学向量,这些向量来自一个预训练 Whisper 模型,并从 50 Hz 下采样到 12.5 Hz。这种混合式 token 化策略,目的是在语义效率和丰富的声学细节之间取得平衡,从而同时支持感知与生成。
音频 LLM
这部分是整个系统的中央处理单元。它初始化自一个预训练文本 LLM(Qwen2.5 7B),并通过共享的 Transformer 层处理多模态输入。它之后会分叉出两个并行头:一个文本头,用于自回归预测文本 token(例如转录结果或对话回复);一个音频头,用于预测离散的语义音频 token。
音频 detokenizer
这一部分负责最终的音频波形合成。它会把 LLM 生成的离散语义音频 token 转换回连贯的语音。实现方式是:先通过一个 flow-matching 模块把这些 token 转换成 mel 声谱图,再利用高保真的 BigVGAN vocoder 生成真正的音频波形。Kimi-Audio 还加入了一个按 chunk 进行流式 detokenize 的机制,并配有 look-ahead 设计,以保证在实时语音对话场景中的低延迟语音生成。整体架构如图 6-8 所示。
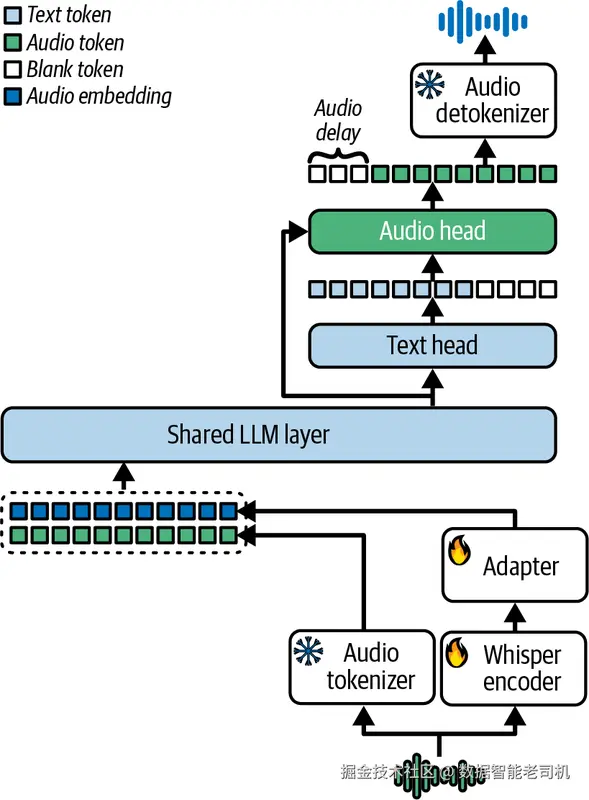
图 6-8. Kimi-Audio 把音频 tokenizer 生成的离散 token、Whisper 编码器生成的连续特征,以及音频语言模型结合在一起,来生成文本或音频;而音频 detokenizer 则负责从音频 token 重建波形。图片改编自 KimiTeam 等人(2025)。
Kimi-Audio 的预训练语料超过 1300 万小时原始音频,数据覆盖语音、各种环境声音和音乐。这些大规模数据集是通过一个高效的自动音频处理流水线构建出来的,其中包括语音增强、说话人 diarization,以及利用 Whisper-large-v3 做复杂转录。所谓 speaker diarization,就是把包含人类语音的音频流,按说话人身份划分成统一片段的过程。
模型的训练采用多阶段方式:它从一个预训练文本 LLM 初始化音频 LLM,从 Whisper-large-v3 初始化连续声学特征提取器。预训练任务包括:单模态任务(纯音频、纯文本)、音频到文本映射任务(如 ASR、TTS),以及音频---文本交织任务,以便把两种模态对齐到共享 latent 空间中。之后,再在广泛任务上做大规模基于指令的监督微调,从而激活 Kimi-Audio 的指令跟随能力,并让它能在多种对话上下文中生成具有表现力的语音。
正是这种架构创新、大规模多模态预训练和指令微调的结合,使 Kimi-Audio 成为相对于 Whisper 和 Qwen2-Audio 更通用的替代方案。为了更清楚地理解它们之间的功能差异,表 6-2 总结了这几个模型在关键音频处理能力上的对比。
表 6-2. Whisper、Qwen2-Audio 与 Kimi-Audio 对比
| 特性 | Whisper | Qwen2-Audio | Kimi-Audio |
|---|---|---|---|
| Diarization 支持 | 否 | 否 | 仅外部支持 |
| ASR(基础转录) | 是 | 是(通过 prompt) | 是(通过 message type) |
| 指令跟随 | 否 | 是(Instruct 模型) | 是 |
| 多轮音频问答 | 否 | 部分支持 | 是 |
| 音频到音频 / 文本生成 | 否 | 否 | 是 |
| 消息类型区分 | 否 | 否 | 是 |
| 输出音频生成 | 否 | 否 | 是 |
| 多语言与中文支持 | 有限 | 有限 | 是 |
有了这些架构背景之后,我们就来构建一个"带说话人感知能力"的音频转录管线:把 pyannote-audio 用于说话人分离,再把 Kimi-Audio-7B-Instruct 用于基于指令的转录。目标是:把一段多说话人录音切分成不同说话段,识别每个人轮次,并生成能够指出"谁在什么时间说了什么"的自然语言转录结果。
这个过程首先会从 concatenated_librispeech 数据集中加载一个整理过的样本。这个数据集把两位说话人的对话拼接成一个单一音频文件,因此非常适合测试模型的说话人切分能力。示例 6-6 展示了如何加载音频文件。
示例 6-6. 加载 concatenated_librispeech 数据集
ini
dataset = load_dataset("sanchit-gandhi/concatenated_librispeech")为了把对话中不同说话人的发言切分出来,你可以使用 pyannote/speaker-diarization@2.1 流水线。它会输出输入音频中带有时间戳的说话人片段。代码如示例 6-7 所示。
示例 6-7. 使用 pyannote 做说话人分离
ini
diarization_pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization@2.1",
use_auth_token=True)
sample = dataset[0]
audio_array = sample["audio"]["array"]
sr = sample["audio"]["sampling_rate"]
waveform = torch.tensor(audio_array[None, :]).float()
annotation = diarization_pipeline({"waveform": waveform, "sample_rate": sr})
segments = []
for turn, _, speaker in annotation.itertracks(yield_label=True):
segments.append({
"start": turn.start,
"end": turn.end,
"speaker": speaker
})完成 diarization 之后,你就可以像示例 6-8 那样,把波形切成每个说话轮次对应的独立音频片段。这些片段之后会被送给 Kimi-Audio 进行转录。
示例 6-8. 把说话人片段切成音频块
sql
speaker_segments = []
for seg in segments:
start = int(seg["start"] * sr)
end = int(seg["end"] * sr)
audio_chunk = audio_array[start:end]
speaker_segments.append({
"speaker": seg["speaker"],
"start": seg["start"],
"end": seg["end"],
"audio": audio_chunk
})在内存中完成切片之后,下一步就是像示例 6-9 那样,把每个片段保存成 .wav 文件,以便作为模型输入。这些音频文件会与明确的用户指令配对,再传入 Kimi-Audio,返回相应转录。
示例 6-9. 为 Kimi-Audio 准备数据
ini
os.makedirs("tmp_segments", exist_ok=True)
for i, seg in enumerate(speaker_segments):
filename = f"tmp_segments/speaker_{i}.wav"
sf.write(filename, seg["audio"], sr)
speaker_segments[i]["file_path"] = filename有了这些保存好的说话人片段之后,你就可以通过显式 prompt 使用 Kimi-Audio 对每个片段做转录了。示例 6-10 展示了如何加载 Kimi-Audio 并配置生成参数。
示例 6-10. 加载 Kimi-Audio 并设置生成参数
makefile
model_path = "moonshotai/Kimi-Audio-7B-Instruct"
model = KimiAudio(model_path=model_path, load_detokenizer=True)
sampling_params = {
"audio_temperature": 0.8,
"audio_top_k": 10,
"text_temperature": 0.0,
"text_top_k": 5,
"audio_repetition_penalty": 1.0,
"audio_repetition_window_size": 64,
"text_repetition_penalty": 1.0,
"text_repetition_window_size": 16,
}你还可以加一个可选 prompt 来控制输出,如示例 6-11 所示。
示例 6-11. 加入可选 prompt 来控制输出
python
messages = []
for seg in speaker_segments:
# Add optional prompt to control output
messages.append({
"role": "user",
"message_type": "text",
"content": f"What is {seg['speaker']}
saying between {seg['start']:.1f}s and {seg['end']:.1f}s?"
})
messages.append({
"role": "user",
"message_type": "audio",
"content": seg["file_path"]
})
_, text_output = model.generate(messages, **sampling_params, output_type="text")
print(">>> Transcribed Multi-speaker Output:\n")
print(text_output)接着,示例 6-12 展示了如何把每个音频片段和对应指令 prompt 配对,再逐一送给模型做转录。最终得到的结果,是一个结构化的、带说话人归属的转录文本,同时保持与原始音频的时间对齐。
示例 6-12. 使用 Kimi-Audio 转录每个说话人片段
ini
transcriptions = []
for seg in speaker_segments:
msgs = [
{"role": "user", "message_type":
"text", "content": f"Transcribe what {seg['speaker']} says:"},
{"role": "user", "message_type": "audio", "content": seg["file_path"]}
]
_, output = model.generate(msgs, **sampling_params, output_type="text")
transcriptions.append({
"speaker": seg["speaker"],
"start": seg["start"],
"end": seg["end"],
"text": output
})通过示例 6-13 中的函数,你就可以把带说话人标签、带时间戳并附有转录文本的结果打印出来。
示例 6-13. 简单文本输出
python
for t in transcriptions:
print(f"{t['speaker']} ({t['start']:.1f}s - {t['end']:.1f}s): {t['text']}\n")模型输出如下:
vbnet
SPEAKER_01 (0.0s - 14.5s): The second in importance is as follows sovereignty
may be defined to be the right of making laws in france the king really exercises
a portion of the sovereign power since the laws have no weight.
SPEAKER_00 (15.4s - 21.3s): He was in a fevered state of mind, owing to
the blight his wife's action threatened to cast upon his entire future.这个结果在时间和文本内容上都完全准确。
这类输出清楚说明:经过指令微调的音频基础模型不仅能转录语音,而且还能以细粒度控制说话人身份和时间上下文,把传统 diarization 和现代生成式建模衔接起来。你甚至可以用 Kimi-Audio 去问更有针对性的问题,比如:"speaker A 在 4.2 秒到 11.7 秒之间说了什么?" 这就让转录变得更加交互式、模块化。最终输出的是一个带说话人归属、时间对齐的转录文本,它不仅保留了内容,也保留了对话结构。
具备工具调用能力的原生语音 Agent
如果你正在探索不止于简单转录的语音型 agent,那么可以考虑采用一种级联式架构:把 ASR、LLM 推理和 TTS 结合起来,并加入工具调用能力。AURA 就是一个很强的开源候选,它支持多轮、speech-to-speech 的交互,还能接入真实世界 API,比如邮件、日历和 Web 搜索。
AURA 使用的是 ReAct 风格推理,并且它的模块化程度很高,可以通过自然语言 prompt 轻松接入你自己的工具。在基准测试中,它在 VoiceBench 上的表现能够与 GPT-4o 相抗衡。这个 agent 已经开源,并提供了基于 Gradio 的实现,代码可以在 GitHub 仓库中找到。对于任何正在做多模态或任务导向助手的人来说,这是一个非常不错的起点。
音频中的 Segment Anything
你在第 4 章里已经学习过 diffusion transformer,但那一章的重点是图像生成。而这一节会给你一个不同视角:你在第 4 章见过的那些组件,现在会被拿来做音频分割。这也是我决定写一本"跨领域 Transformer"书的原因之一:一旦你理解了核心部件,每当出现新模型时,你就不需要从零开始理解,而是可以直接识别出熟悉的模块,然后把注意力放在"它们是如何被重新组合的"上。
SAM Audio 就是一个很好的例子。这个模型建立在 diffusion transformer 架构之上,也就是你在"可扩展的基于 Transformer 的扩散模型"那节里遇到过的模型。它也使用了类似的 VAE 设定。一个非常有趣的设计是:SAM Audio 的作者把音频分割建模为一个生成式建模问题,而不是传统的判别式学习问题。传统思路往往是让模型去预测声谱图上的一个 mask,而这一直是音频分割最常见的处理方式。
Diffusion transformer 并不是这里唯一一个你会感到熟悉的组件。你在"图像与视频中的 Segment Anything"一节里见过的 SAM 2,也再次出现在了 SAM Audio 中。它在视频里提供视觉 prompt,因为视频是多模态音频数据的一个常见来源,而视觉区域往往也是隔离声源最自然的方式。为了从视频中提取一个声音,你可以像在 SAM 2 里做的那样,通过点击或边界框来标出感兴趣区域。图 6-9 展示了整体架构。
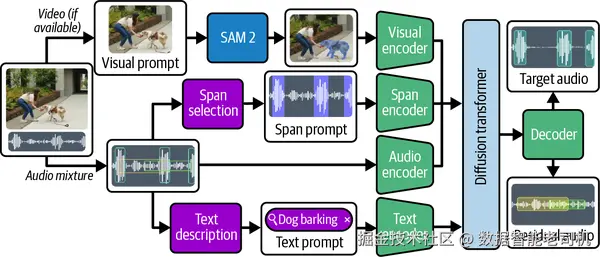
图 6-9. SAM Audio 总览。图片改编自 Bowen Shi 等人(2025)。
下面这几个示例(示例 6-14 到 6-16)展示了:如何通过简单的文本描述,用 SAM Audio 从同一个音频片段中分离出不同声音。首先,先加载模型和 processor(示例 6-14)。Processor 负责准备模型输入,同时处理音频重采样和 batch。
示例 6-14. 初始化 SAM Audio
ini
model = SAMAudio.from_pretrained("facebook/sam-audio-large").to(device).eval()
processor = SAMAudioProcessor.from_pretrained("facebook/sam-audio-large")示例 6-15 会启动声音分离过程,并对每一组(音频,描述)输入返回对应的目标声音和剩余声音。
示例 6-15. 基于文本的声源分离
ini
audio_file = "/content/gunshots.wav"
descriptions = ["gunshots", "male voice"]
audios = [audio_file] * len(descriptions)
batch = processor(
audios=audios,
descriptions=descriptions,
).to("cuda")
with torch.inference_mode():
result = model.separate(batch, predict_spans=True,
reranking_candidates=8)- 描述你想分离出的声音。
- 对每个描述使用同一段音频。
- 执行预处理并完成分离。
示例 6-16 会把这些分离出的音轨分别保存成独立文件。
示例 6-16. 保存分离后的音频轨道
scss
sample_rate = processor.audio_sampling_rate
gunshots_target = ensure_2d(result.target[0])
male_voice_target = ensure_2d(result.target[1])
gunshots_residual = ensure_2d(result.residual[0])
male_voice_residual = ensure_2d(result.residual[1])
torchaudio.save("gunshots_target.wav", gunshots_target.cpu(), sample_rate)
torchaudio.save("male_voice_target.wav", male_voice_target.cpu(), sample_rate)
torchaudio.save("gunshots_residual.wav", gunshots_residual.cpu(), sample_rate)
torchaudio.save("male_voice_residual.wav", male_voice_residual.cpu(), sample_rate)保存分离后的音频。
result.target 和 result.residual 都是 tensor 列表,每一组(音频,描述)对应一个。
target 表示你描述的那类声音。
residual 表示剩余的一切。
只用几行代码,SAM Audio 就能把复杂混合声音切分成清晰、可直接使用的独立音轨。这里有一个很重要的点:target 和 residual 是一对互补输出。target 是你描述的那种特定声音,而 residual 则是"其余的一切",也就是从原始音频中把目标声音挖掉之后剩下的内容。
这个模型并不只是把枪声单独隔离出来;它还会生成一份"枪声被移除"的音频版本,因此男性说话声就完整地保留在 residual 轨道中。这种"target + residual"的处理方式,让 SAM Audio 不只是一个滤波器,它还是一个真正意义上的音频编辑器。无论你是想把某个乐器单独提出来做 remix,还是想通过隔离背景嗡声来清理一段有噪音的采访,它都能保证各个分离音轨重新合成后,能完美还原原始音频信号。
超越文本与语音:作为音乐作曲家的 Transformer
音乐生成是一项独特而困难的任务,它远远不只是简单序列预测那么直接。与语音不同,音乐会使用整个频谱范围,而且通常需要更高的采样率(例如 44.1 kHz 或 48 kHz)。它把多种乐器的和声、旋律和节奏交织在一起,形成复杂结构,而人类听众对于错误和不和谐非常敏感。除此之外,音乐创作者通常还希望精确控制流派、乐器编制、调性和旋律推进,这又额外增加了生成难度。
MusicGen 是条件音乐生成领域中的一个先驱性模型。它提出了一种具有范式转移意义的方法:利用单阶段 Transformer 语言模型来生成高质量音乐。这个单阶段设计会在多条压缩离散音乐表示流上运行。它不再需要像以往很多音乐生成系统那样,通过层级式或上采样式的级联模型来逐层合成音乐。这种简化使得生成过程更加高效、更加流畅。
MusicGen 的基础,是它的音频 token 化方式。它采用 EnCodec------一个基于卷积自编码器并使用残差向量量化(RVQ)的系统------把原始音频转换成多条并行的离散 token 流。所谓 RVQ,是一种通过逐步量化"原始输入与前一步量化结果之间残差"的方式来编码数据的技术,它可以获得更紧凑、也更准确的表示。在音频中,每一个时间步都由来自多个已学习 codebook 的多个量化值来表示,帧率是 50 Hz。这些离散 token 构成了 Transformer 语言模型所学习建模的输入序列。
MusicGen 的核心是一个基于自回归 Transformer 的解码器,它会建模这些声学 token 流。它并不会简单地把所有 token 流展平成一条很长的单序列,而是更聪明地把它们交织起来,例如用"delay"或"parallel"这类模式。这样做使模型能够高效地捕捉平行流之间的依赖关系,从而生成连贯音乐,同时又显著减少了自回归步数,相比直接全量展平要高效得多。
MusicGen 支持条件生成。它可以根据文本描述作曲,例如"带有吉他 riff 的 90 年代摇滚歌曲",并通过像 T5 这样的文本编码器来理解提示。若要根据文本生成你自己的音乐,第一步是加载模型和 processor,如示例 6-17 所示。
示例 6-17. 加载模型和 processor
ini
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-large",
to_device="auto")
processor = AutoProcessor.from_pretrained("facebook/musicgen-large")之后,你只需要像示例 6-18 那样定义 prompt。
示例 6-18. 定义流派与 prompt
makefile
genre_prompts = {
"classical": "classical piano music",
"minimal": "minimal house rather monoton in rhythm",
"EDM": "EDM hardcore Techno sound",
}接着,你就可以很方便地生成并保存每段音频,如示例 6-19 所示。
示例 6-19. 生成并保存音频文件
ini
for genre, prompt in genre_prompts.items():
inputs = processor(text=[prompt], padding=True,
return_tensors="pt").to(device)
audio_values = model.generate(
**inputs,
do_sample=True,
guidance_scale=3,
max_new_tokens=1024
)
audio_np = audio_values[0].cpu().numpy().squeeze()
audio_np = np.clip(audio_np, -1.0, 1.0)
audio_int16 = (audio_np * 32767).astype(np.int16)
filename = f"{genre}.wav"
write_wav(filename, sampling_rate, audio_int16)
display(Audio(audio_np, rate=sampling_rate))- 准备输入。
- 生成音频。
- 转成 NumPy 并裁剪范围。
- 保存为 WAV。
- 回放:这里会显示一个播放按钮,可以直接试听音频。
它还支持无监督的旋律条件生成,这通过 chromagram 来实现。Chromagram 是一种可视化或数值表示,它记录了 12 个音高类(例如 C、C#、D 等)随时间变化的强度,从而在不区分八度的前提下,捕捉音频信号中的和声与调性内容。借助这个特性,你可以提供一段旋律结构(例如一段哼唱,或另一条音频轨),模型就会生成既遵循这段旋律输入、又仍受文本 prompt 引导的音乐。要使用这个功能,你可以从任意 .wav 或 .mp3 文件开始。为了便于演示,我这里使用 Facebook Research 的 audiocraft 库中提供的音频文件。我先克隆这个仓库,再打印目录内容,以便选取其中一个文件,如示例 6-20 所示。
示例 6-20. 克隆仓库并显示音频文件
bash
!git clone https://github.com/facebookresearch/audiocraft.git
asset_folder = "audiocraft/assets"
print(f"Listing contents of {asset_folder}:\n")
for file_name in os.listdir(asset_folder):
print(file_name)本节对应的 notebook 里也提供了代码,可以播放这些音频文件。
模型和 processor 的加载方式与示例 6-17 相同。由于音频文件本身的采样率不同,加载后需要先做重采样。示例 6-21 展示了这个过程。
示例 6-21. 加载并重采样音频文件
ini
file_path = "audiocraft/assets/CJ_Beatbox_Loop_05_90.wav"
waveform, orig_sr = torchaudio.load(file_path)
if waveform.shape[0] > 1:
waveform = waveform.mean(dim=0, keepdim=True)
target_sr = 32000
if orig_sr != target_sr:
resampler = Resample(orig_freq=orig_sr, new_freq=target_sr)
waveform = resampler(waveform)
waveform_np = waveform.squeeze().numpy()- 加载音频文件。
- 转成单声道。
- 重采样到 32 kHz。
接下来,像示例 6-22 那样准备 processor 的输入。
示例 6-22. 准备输入
ini
inputs = processor(
audio=waveform_np,
sampling_rate=target_sr,
text=["Hip hop with nuances of soul and funk"],
padding=True,
return_tensors="pt",
)然后,你就可以像示例 6-23 那样,基于这个样本和文本提示,生成并保存延展后的音乐。
示例 6-23. 生成音乐并保存输出
ini
audio_values = model.generate(
**inputs,
do_sample=True,
guidance_scale=3.0,
max_new_tokens=512
)
output = audio_values[0].numpy()
output = output / np.max(np.abs(output) + 1e-8)
output_int16 = (output * 32767).astype(np.int16)
if output_int16.ndim > 1:
output_int16 = output_int16.squeeze()
write("hiphop_generated.wav", int(target_sr), output_int16)
display(Audio("hiphop_generated.wav"))- 生成音乐。
- 归一化到 ( −1,1)。
- 转换成 16-bit PCM。
- 确保结果是一维。
- 以正确采样率写入文件。
- 显示播放按钮。
现在你已经看到了 MusicGen 的工作方式,接下来就轮到你亲自尝试了。只需一个 prompt,或者一段很短的音频样本,你就可以生成完整的音乐作品,不管是古典、EDM,还是某种全新的风格。MusicGen 的魅力不只在于技术上的优雅,还在于它几乎把创作控制权直接交到了你手里。你可以试着混合不同风格、用自己的声音或 beatbox loop 去引导模型,或者干脆让模型自己给你一些惊喜。无论你是音乐人、研究者,还是单纯好奇的人,这都是一个非常强大的音乐探索 playground。让你的想法真正变成声音。
总结
在这一章中,你把对 Transformer 的理解进一步扩展到了音频领域,而在这里,时间、频率和感知会交织在一起。建立在文本和时间序列这些早先领域的基础上,你已经看到:同样的架构基础,是如何继续在不同模态中适配和延展的。从波形,到声谱图;从离散 token,到学习型表示,Transformer 再次证明了自己是一套灵活而强大的建模框架。
你也看到了,音频同时具备时间推进和频谱丰富性。与纯时间序列不同,声音中的模式会同时出现在这两个维度上,因此需要更细致的预处理和更符合领域特性的表示方式。声谱图、mel 尺度,以及量化后的音频 token,共同构成了现代模型"理解"和"生成"声音的基础。像 Whisper、Qwen2-Audio、Kimi-Audio 和 SAM Audio 这样的模型,就体现了这一演进过程。它们都建立在 Transformer 骨干之上,但分别解决不同任务:转录、分类、分割、情感识别,乃至音频生成,而且是通过统一架构来完成的。
这些模型也反映出一个更大的转变:我们不再为每个任务分别搭建完全独立的系统,而是开始通过音频基础模型,把识别、生成与理解统一到一起。无论是响应用户指令、转写重叠语音,还是根据文本作曲,Transformer 都在提供既可扩展又具泛化性的解决方案,并逐渐接近人类对音频系统的自然期待。
在这一章里,你还学习了:latent space、注意力机制以及神经 vocoder,是如何一起作用,从而高保真地重建和生成音频的。从自回归解码,到经过指令微调的模型,Transformer 仍然在不断拓展机器"听见""理解"和"创造"声音的边界。
而这种适应能力,在你进入第 7 章时会变得更加关键。强化学习会引入一种全新的"结构"------它不在数据中,而在决策中。此时,问题的重点不再是建模"观察到了什么",而是学习"应该做什么"。Transformer 现在必须开始在状态、动作和长期结果之间进行推理,而且往往是在不确定且可交互的环境里完成的。
正如音频会沿着时间与频率展开,行为也会沿着试错与奖励展开。第 7 章会展示:Transformer 是如何越来越多地被用于建模那些会行动、会探索,并会在时间中不断改进的 agent。