二叉树详解
目录
[一、 什么是二叉树?](#一、 什么是二叉树?)
[二、 常见二叉树的分类](#二、 常见二叉树的分类)
[💡 分类逻辑说明](#💡 分类逻辑说明)
[1. 满二叉树 (Full Binary Tree)](#1. 满二叉树 (Full Binary Tree))
[2. 完全二叉树 (Complete Binary Tree)](#2. 完全二叉树 (Complete Binary Tree))
[3. 完美二叉树 (Perfect Binary Tree)](#3. 完美二叉树 (Perfect Binary Tree))
[4. 平衡二叉树 (Balanced Binary Tree)](#4. 平衡二叉树 (Balanced Binary Tree))
[4.1. AVL树 - 严格平衡](#4.1. AVL树 - 严格平衡)
[4.2. 红黑树 - 近似平衡](#4.2. 红黑树 - 近似平衡)
[4.3. 对比AVL和红黑树](#4.3. 对比AVL和红黑树)
[5. 二叉搜索树 (Binary Search Tree, BST)](#5. 二叉搜索树 (Binary Search Tree, BST))
[6. 退化二叉树/斜树 (Degenerate/Skewed Tree)](#6. 退化二叉树/斜树 (Degenerate/Skewed Tree))
[三、 特殊二叉树类型](#三、 特殊二叉树类型)
[1. 线索二叉树 (Threaded Binary Tree)](#1. 线索二叉树 (Threaded Binary Tree))
[2. 哈夫曼树 (Huffman Tree)](#2. 哈夫曼树 (Huffman Tree))
[3. 表达式树 (Expression Tree)](#3. 表达式树 (Expression Tree))
[4. 堆 (Heap)](#4. 堆 (Heap))
[1. 插入 (Insert) - 向上调整 (Sift Up)](#1. 插入 (Insert) - 向上调整 (Sift Up))
[2. 删除堆顶 (Pop/Extract-Max) - 向下调整 (Sift Down)](#2. 删除堆顶 (Pop/Extract-Max) - 向下调整 (Sift Down))
[3. 获取极值 (Peek)](#3. 获取极值 (Peek))
[4. 建堆 (Heapify) - 自底向上构建](#4. 建堆 (Heapify) - 自底向上构建)
[✅ 操作总结](#✅ 操作总结)
[四、 二叉树的存储方式](#四、 二叉树的存储方式)
[1. 链式存储](#1. 链式存储)
[2. 数组存储(完全二叉树)](#2. 数组存储(完全二叉树))
[五、 二叉树的遍历方式](#五、 二叉树的遍历方式)
[六、 时间复杂度对比](#六、 时间复杂度对比)
[七、 实际应用](#七、 实际应用)
[八、 常用计算](#八、 常用计算)
[九、 如何选择合适的二叉树?](#九、 如何选择合适的二叉树?)
一、 什么是二叉树?
二叉树 是每个节点最多有两个子节点的树形数据结构。它是一种特殊的树,具有以下特性:
基本结构:
A ← 根节点
/ \
B C ← 子节点
/ \ \
D E F ← 叶子节点二叉树的5个核心性质:
-
每个节点最多有两个子节点:左子节点和右子节点
-
子树有左右之分:左子树 ≠ 右子树
-
第i层最多有 2^(i-1) 个节点
-
深度为k的二叉树最多有 2^k - 1 个节点
-
叶子节点数 = 度为2的节点数 + 1,(度 指的是节点拥有的子节点数量)
二、 常见二叉树的分类
二叉树分类速查表
| 分类维度 | 类型名称 | 核心定义 | 关键特征 |
|---|---|---|---|
| 结构形态 | 满二叉树 (Full) | 所有层都达到最大节点数 | 叶子节点全在最底层,节点总数 2h−1(h为高度) |
| 完全二叉树 (Complete) | 除最后一层外全满,最后一层靠左填满 | 数组存储效率高,无空间浪费 | |
| 平衡二叉树 (Balanced) | 左右子树高度差不超过1 | 如AVL、红黑树,保证操作复杂度为 O(logn) | |
| 退化二叉树/斜树 (Degenerate) | 每个节点最多只有一个子节点 | 失去树的结构优势,操作复杂度退化为 O(n) | |
| 数据特性 | 二叉搜索树 (BST) | 左子树所有节点 < 根 < 右子树所有节点 | 支持高效的搜索、插入、删除(平均 O(logn)) |
| 堆 (Heap) | 根节点是最大/最小值(大顶堆/小顶堆) | 常用于优先队列、快速找极值,不保证整体有序 | |
| 线索二叉树 (Threaded) | 利用空指针指向遍历前驱/后继 | 优化中序遍历,无需递归或栈即可遍历 |
💡 分类逻辑说明
-
形态是骨架 :满二叉树、完全二叉树等描述的是树的"物理形状"。在实际应用中,完全二叉树因其适合用数组紧凑存储(无指针开销),在堆结构中被广泛使用。
-
特性是灵魂 :二叉搜索树(BST)和堆描述的是节点数据的"逻辑关系"。BST 维护了有序性,而堆只关心极值。
-
平衡是关键 :普通的BST在插入有序数据时会退化成链表。平衡二叉树 (如AVL树、红黑树)通过自平衡机制,确保树的高度始终可控,是大多数语言标准库(如
std::map)的实现基础。
记忆口诀 :满则全,全未必满;查用BST,极值用堆;防退化,必平衡。
1. 满二叉树 (Full Binary Tree)
定义 :除了叶子节点外,每个节点都有两个 子节点
特点:
-
所有叶子都在同一层
-
节点总数 = 2^k - 1(k为深度)
-
是"最丰满"的二叉树
示例(深度3,7个节点):
1
/
2 3
/ \ /
4 5 6 7
2. 完全二叉树 (Complete Binary Tree)
定义 :除了最后一层,其他层都是满的,且最后一层的节点尽量靠左排列
特点:
-
可以用数组紧凑存储
-
堆排序、优先队列的基础
-
高度 = ⌊log₂n⌋ + 1 (深度为k的二叉树最多有 2^k - 1 个节点)
有效完全二叉树:
1
/
2 3
/ \ /
4 5 6无效完全二叉树(6不在左边):
1
/
2 3
/ /
4 5 6
3. 完美二叉树 (Perfect Binary Tree)
定义:所有叶子节点都在同一层,且每个非叶子节点都有两个子节点
注意:完美二叉树一定是满二叉树,但满二叉树不一定是完美二叉树(深度可以不同)
4. 平衡二叉树 (Balanced Binary Tree)
定义 :任意节点的左右子树高度差不超过1
常见类型:
-
AVL树:严格平衡,|左高-右高| ≤ 1
-
红黑树:近似平衡,保证最长路径 ≤ 2×最短路径
平衡二叉树示例:
5
/
3 8
/ \
2 4 9
/
1
高度差 ≤ 1
AVL树和红黑树都属于BBT(平衡二叉树)。它们是平衡二叉搜索树(Balanced Binary Search Tree)的两种经典实现,都通过特定的平衡机制来保证树的高度为O(log n),从而确保搜索、插入、删除等操作的高效性。
4.1. AVL树 - 严格平衡
(AVL 是两个人名姓氏的缩写,来源于其发明者 G. M. Adelson-Velsky 和 Evgenii Landis。)
核心特性 :通过旋转操作保持绝对平衡,任意节点的左右子树高度差不超过1。
示例AVL树结构(数值:10, 20, 30, 40, 50, 25):
python
30
/ \
20 40
/ \ \
10 25 50平衡特征:
-
节点30:左子树高2(20,10,25),右子树高2(40,50),高度差=0
-
节点20:左子树高1(10),右子树高1(25),高度差=0
-
节点40:左子树高0,右子树高1(50),高度差=1
4.2. 红黑树 - 近似平衡
核心特性 :通过红黑着色规则保持近似平衡,最长路径不超过最短路径的2倍。
示例红黑树结构(数值:10, 20, 30, 40, 50, 60, 70):
python
40(B)
/ \
20(R) 60(B)
/ \ / \
10(B)30(B)50(R)70(R)着色规则:
-
每个节点非红即黑
-
根节点为黑色B
-
红色节点的子节点必须为黑色
-
从任一节点到其所有叶子节点的路径包含相同数量的黑色节点
-
叶子节点(NIL)视为黑色
4.3. 对比AVL和红黑树
| 特性 | AVL树 | 红黑树 |
|---|---|---|
| 平衡严格度 | 严格(高度差≤1) | 宽松(最长路径≤2×最短路径) |
| 旋转频率 | 高(插入/删除常需多次旋转) | 低(通常最多3次旋转) |
| 适用场景 | 搜索密集型(如数据库索引) | 插入删除频繁(如STL map/set) |
| 时间复杂度 | 搜索O(log n),插入/删除O(log n) | 搜索O(log n),插入/删除O(log n) |
| 实现复杂度 | 较高 | 相对较低 |
5. 二叉搜索树 (Binary Search Tree, BST)
定义:对于每个节点:
-
左子树所有节点的值 < 当前节点的值
-
右子树所有节点的值 > 当前节点的值
特点:
-
中序遍历得到有序序列
-
查找、插入、删除:平均O(log n),最坏O(n)
二叉搜索树示例:
6
/
3 8
/ \
1 5 9
2
6. 退化二叉树/斜树 (Degenerate/Skewed Tree)
定义:每个节点都只有一个子节点
特点:
-
退化成链表
-
时间复杂度退化为O(n)
左斜树: 右斜树:
1 1
/
2 2
/
3 3
三、 特殊二叉树类型
1. 线索二叉树 (Threaded Binary Tree)
-
利用空指针域指向遍历序列的前驱/后继
-
加快遍历速度
核心:将原本为 NULL的指针,指向 该节点在 某种遍历顺序下 的前驱或后继,从而在不使用栈或递归的情况下实现快速遍历。
**线索化:**
将二叉树中的空指针域重新利用:
• 左空指针 →指向前驱
• 右空指针 →指向后继
**标记位:**
每个指针增加标志位(tag):
• tag=0:指向孩子(原树结构)
• tag=1:指向线索(前驱/后继)
**遍历方式:**
通常基于中序遍历(LNR)建立线索,也可前序、后序
2. 哈夫曼树 (Huffman Tree)
- 带权路径最短的二叉树
权: 就是一个权重值,通常代表某种"重要性"或"代价"。
在哈夫曼树中 :权就是字符出现的频率(或概率)。
例如:字符 A出现 50 次,它的权就是 50。
直观理解:权越大,说明这个节点(字符)越重要、用得越多,我们就希望它离根节点越近(路径越短),这样整体效率才高。
路径长度 就是从根节点 走到该节点 所经过的边数(注意:不是节点数)。
带权路径长度(WPL) = 权 × 路径长度。
哈夫曼树 用于数据压缩,带权路径长度(WPL) 越小,意味着高频字符的路径越短,整体编码或查找的平均代价就越低。
哈夫曼树的目标就是构造一棵二叉树,使得这个 WPL 值最小。这就是为什么它被称为"最优二叉树"。
3. 表达式树 (Expression Tree)
-
叶子节点是操作数
-
内部节点是运算符
表达式 (a+b)*(c-d) 的树:
*
/
+ -
/ \ /
a b c d
4. 堆 (Heap)
-
特殊的完全二叉树
-
最大堆:父节点 ≥ 子节点
-
最小堆:父节点 ≤ 子节点
堆(Heap)是一种基于完全二叉树 实现的高效数据结构,它通过父子节点间的大小约束 来快速获取极值,是**优先队列(Priority Queue)**的标准底层实现。
| 特性 | 最大堆 (Max Heap) | 最小堆 (Min Heap) |
|---|---|---|
| 结构基础 | 完全二叉树(可用数组紧凑存储) | 完全二叉树(可用数组紧凑存储) |
| 核心规则 | 父节点值 **≥** 任一子节点值 | 父节点值 **≤** 任一子节点值 |
| 堆顶极值 | 根节点是最大值 | 根节点是最小值 |
| 局部有序 | 只保证"父大于子",不保证整体有序 | 只保证"父小于子",不保证整体有序 |
关键操作与性能
| 操作 | 逻辑 | 时间复杂度 |
|---|---|---|
| **插入 (Insert)** | 元素放末尾,向上调整 (Sift Up) | O(logn) |
| **删除堆顶 (Pop)** | 末尾元素换到根,向下调整 (Sift Down) | O(logn) |
| **获取极值 (Peek)** | 直接返回根节点(数组首元素) | O(1) |
| **建堆 (Heapify)** | 从最后一个非叶子节点开始向下调整 | O(n) |
这四种操作是堆(Heap)的核心。
以最常见的最大堆 (父 ≥ 子)为例,配合图示来讲解每个操作的原理、步骤和复杂度。
1. 插入 (Insert) - 向上调整 (Sift Up)
目标:将一个新元素加入堆,并维持堆的性质。
操作步骤:
-
放末尾 :将新元素插入到数组的末尾(即完全二叉树的最后一个叶子位置)。
-
向上调整 (Sift Up):
-
比较新元素与其父节点。
-
如果新元素 > 父节点,则交换它们的位置。
-
重复此过程,直到新元素 ≤ 其父节点,或到达根节点。
-
图解示例 (向最大堆 10, 7, 8, 3, 2 插入 12):
对应的完全二叉树为:
10
/ \
7 8
/ \
3 2插入新元素 12:
按照完全二叉树的规则,新元素必须添加到最后一层的最左空闲位置(即数组末尾)。插入后数组变为 [10, 7, 8, 3, 2, 12],对应的树结构为:
10
/ \
7 8
/ \ /
3 2 12-
节点 12 的索引是 5,其父节点索引为
(5-1)//2 = 2,即节点 8。 -
因此,12 的父节点是 8,而不是 7。
正确的向上调整过程:
-
比较 12 与其父节点 8:12 > 8,交换它们,树变为:
10 / \ 7 12 / \ / 3 2 8 -
现在 12 的索引是 2,父节点索引为
(2-1)//2 = 0,即根节点 10。比较 12 与 10:12 > 10,交换,得到:12 / \ 7 10 / \ / 3 2 8 -
调整结束,最终数组为
[12, 7, 10, 3, 2, 8]。
时间复杂度:O(logn),因为调整路径最长等于树的高度。
2. 删除堆顶 (Pop/Extract-Max) - 向下调整 (Sift Down)
目标:移除并返回堆顶元素(最大值/最小值),并重新调整堆。
操作步骤:
-
记录并移除 :记录堆顶(根节点)的值作为返回值。将堆的最后一个叶子节点的值移到根节点,并删除最后一个叶子。
-
向下调整 (Sift Down):
-
从新的根节点开始,比较它与其左右子节点。
-
如果它小于任何一个子节点 ,则与较大的那个子节点交换。
-
重复此过程,直到该节点 ≥ 其所有子节点,或到达叶子。
-
图解示例 (从最大堆 12, 10, 8, 3, 7, 2 删除堆顶 12):
初始堆:
12
/ \
10 8
/ \ /
3 7 2
1. 移除堆顶 12,将最后一个元素 2 移到根:
2
/ \
10 8
/ \ /
3 7
2. 向下调整:2 与较大的子节点 10 比较,2 < 10,交换:
10
/ \
2 8
/ \ /
3 7
3. 继续向下:2 与较大的子节点 7 比较,2 < 7,交换:
10
/ \
7 8
/ \ /
3 2
调整完成。新堆为 [10, 7, 8, 3, 2],返回 12。时间复杂度:O(logn)。
3. 获取极值 (Peek)
目标:查看堆顶元素而不移除它。
操作:直接返回数组的第一个元素(即根节点)。
堆顶:12
数组:[12, 10, 8, 3, 7, 2]
返回 12,堆结构无任何变化。时间复杂度:O(1)。
4. 建堆 (Heapify) - 自底向上构建
目标:将一个无序的数组(或完全二叉树)在 O(n)时间内调整成一个合法的堆。
操作步骤:
-
找到起点 :从最后一个非叶子节点 开始(即从索引
n/2 - 1开始)。 -
自底向上向下调整 :对从该节点到根节点的每一个节点,执行一次 **向下调整 (Sift Down)** 操作。
原理:向下调整操作能保证以当前节点为根的子树满足堆的性质。从下往上做,可以确保调整每个节点时,其子树已经是合法的堆。
图解示例 (将无序数组 4, 10, 3, 5, 1 建为最大堆):
初始完全二叉树:
4
/ \
10 3
/ \
5 1
1. 最后一个非叶子节点是 10(索引 1)。
2. 对 10 向下调整:10 ≥ 5 且 10 ≥ 1,无需调整。
3. 对上一个节点 4(索引 0)向下调整:
4 与较大的子节点 10 比较,交换:
10
/ \
4 3
/ \
5 1
4. 继续对交换后的节点 4(现在在索引 1)向下调整:
4 与较大的子节点 5 比较,交换:
10
/ \
5 3
/ \
4 1
建堆完成,得到最大堆 [10, 5, 3, 4, 1]。时间复杂度 :看似是 O(nlogn),但经过数学推导,实际是 O(n),这使其非常高效。
✅ 操作总结
| 操作 | 核心方法 | 时间复杂度 | 关键步骤 |
|---|---|---|---|
| **插入(Insert)** | 末尾添加,向上调整 (Sift Up) | O(logn) | 1. 放末尾 2. 向上比较交换 |
| **删除堆顶(Pop)** | 首尾交换,向下调整 (Sift Down) | O(logn) | 1. 首尾互换 2. 末尾移除 3. 新根向下调整 |
| **获取极值(Peek)** | 直接访问根节点 | O(1) | 返回 array[0] |
| **建堆(Heapify)** | 自底向上向下调整 | O(n) | 从 n/2-1开始,对每个节点向下调整 |
记忆口诀 :插尾向上浮,删顶换尾向下沉;看顶 O(1),自底建堆 O(n)。
数组存储映射(完全二叉树特性)
利用完全二叉树的特性,堆通常用数组实现,父子关系通过下标计算(假设根节点索引为 0):
-
父节点索引 :
parent(i) = (i - 1) // 2 -
左孩子索引 :
left_child(i) = 2*i + 1 -
右孩子索引 :
right_child(i) = 2*i + 2数组: [1, 2, 3, 4, 5, 6, 7]
对应的树:
1(0)
/
2(1) 3(2)
/ \ /
4(3) 5(4) 6(5) 7(6)
应用场景
-
优先队列:任务调度(总是处理优先级最高的任务)。
-
Top K 问题:用最小堆维护当前最大的 K 个数。
-
堆排序:利用最大堆不断取出最大值进行排序。
记忆口诀 :堆是棵完全树,数组能存储;最大堆爹最大,最小堆爹最小;取极值 O(1),插删 O(log n)。
四、 二叉树的存储方式
1. 链式存储
struct TreeNode {
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
};2. 数组存储(完全二叉树)
-
索引从0开始:
-
父节点i → 左子节点:2i+1
-
父节点i → 右子节点:2i+2
-
子节点i → 父节点:(i-1)/2
数组: [1, 2, 3, 4, 5, 6, 7]
对应的树:
1(0)
/
2(1) 3(2)
/ \ /
4(3) 5(4) 6(5) 7(6)
-
五、 二叉树的遍历方式4种
| 遍历方式 | 顺序 | 应用场景 |
|---|---|---|
| 前序遍历 | 根 → 左 → 右 | 复制树、求表达式 |
| 中序遍历 | 左 → 根 → 右 | BST得到有序序列 |
| 后序遍历 | 左 → 右 → 根 | 删除树、计算高度 |
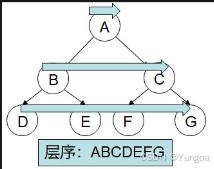
| 层序遍历 | 按层从上到下 | 求宽度、序列化 |
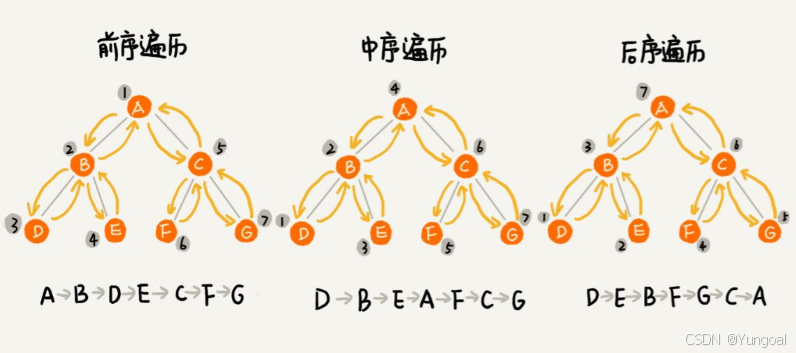
// 前序遍历示例
void preorder(TreeNode* root) {
if (!root) return;
cout << root->val << " "; // 访问根
preorder(root->left); // 遍历左子树
preorder(root->right); // 遍历右子树
}六、 时间复杂度对比
| 类型 | 查找平均 | 查找最坏 | 插入平均 | 插入最坏 | 空间 | 应用 |
|---|---|---|---|---|---|---|
| 普通二叉树 | O(log n) | O(n) | O(log n) | O(n) | O(n) | 通用 |
| 平衡BST | O(log n) | O(log n) | O(log n) | O(log n) | O(n) | 数据库索引 |
| 完全二叉树 | O(log n) | O(log n) | O(log n) | O(log n) | O(n) | 堆排序 |
| 斜树 | O(n) | O(n) | O(n) | O(n) | O(n) | 应避免 |
七、 实际应用
-
数据库索引:B树、B+树(多路平衡树)
-
文件系统:目录结构
-
编译器:语法分析树
-
数据压缩:哈夫曼编码
-
游戏AI:决策树
-
路由算法:最短路径树
-
排序算法:堆排序
八、 常用计算
-
二叉树节点数:n = n₀ + n₁ + n₂
-
边与节点关系:边数 = n - 1
-
叶子节点计算:n₀ = n₂ + 1
-
高度h的二叉树:最少h个节点,最多2^h-1个节点
九、 如何选择合适的二叉树?
-
需要快速查找 → 平衡BST(AVL/红黑树)
-
需要优先队列 → 堆
-
需要数据压缩 → 哈夫曼树
-
需要表达式求值 → 表达式树
-
需要紧凑存储 → 完全二叉树