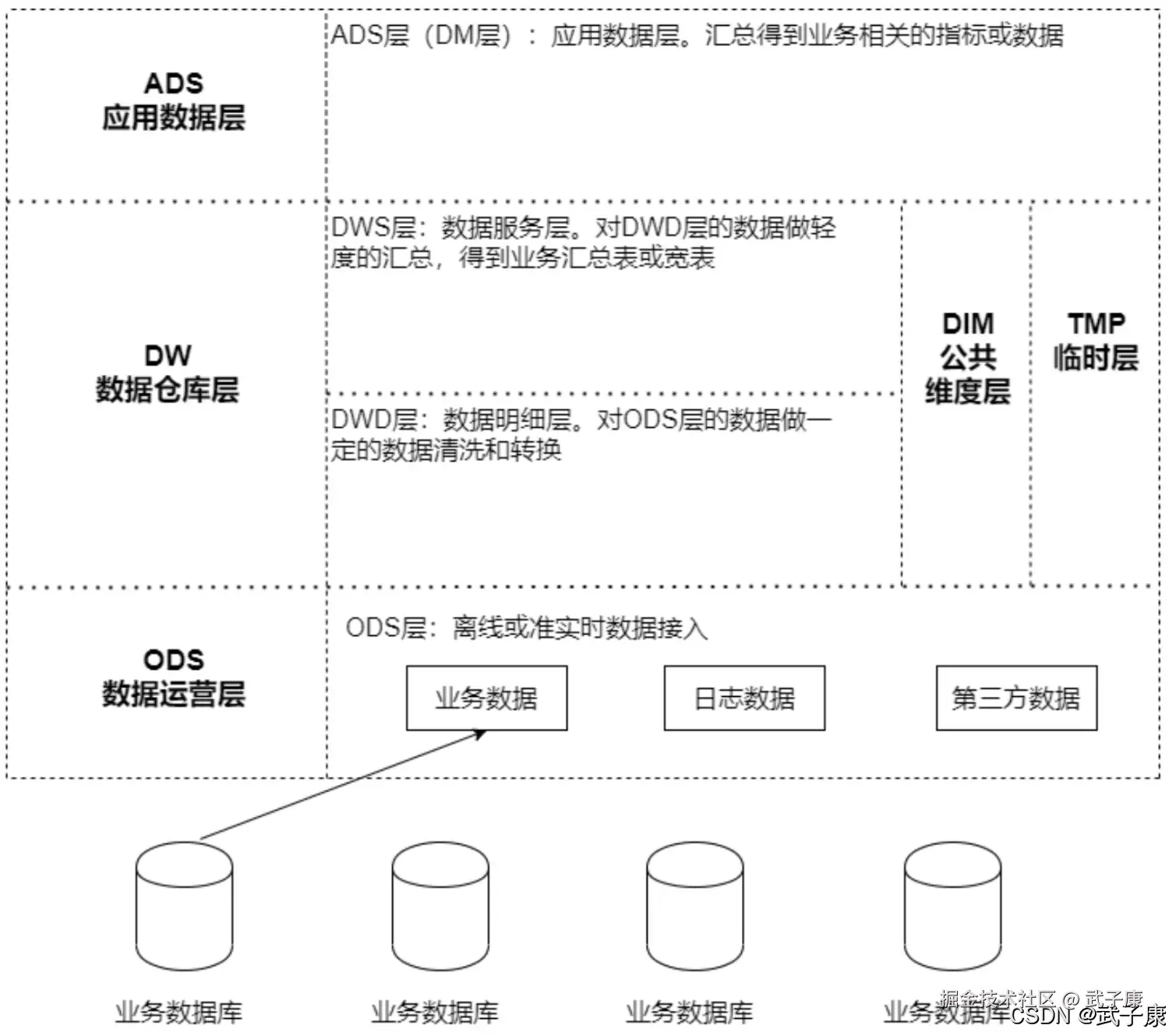
TL;DR
- 场景:在 Hadoop/Spark 大数据环境中,需要对 Hive、HDFS 等数据源进行多维度质量监控与自动化检测。
- 结论:通过修改 5 个配置文件并执行 Maven 编译,可在 YARN 集群上成功部署 Apache Griffin 0.5.0 数据质量管理平台。
- 产出:可访问 Griffin Web 控制台(:9876),具备批量数据质量评估、ElasticSearch 结果持久化与 Quartz 定时调度能力。

版本矩阵
| 组件 | 版本 | 状态 | 说明 |
|---|---|---|---|
| Apache Griffin | 0.5.0 | ✅ 已验证 | 文章所用版本 |
| MySQL | 8.x | ✅ 已验证 | 需使用 com.mysql.jdbc.Driver,注意驱动类名 |
| ElasticSearch | 7.x | ✅ 已验证 | Sink 写入 griffin/accuracy 索引 |
| Spark (YARN) | 2.x | ✅ 已验证 | griffin-measure.jar 须预上传至 HDFS |
| Hive Metastore | thrift 协议 | ✅ 已验证 | 需提前启动 Metastore 服务(端口 9083) |
| Livy | 0.x | ⚠️ 需确认 | livy.uri 默认 8998,需与集群实际地址一致 |
| Kafka / HBase | - | ⚠️ 待验证 | 文章未涉及流处理模式配置 |
主要特点
数据质量评估
Apache Griffin 支持基于规则和模型的质量评估。用户可以为数据集定义不同的质量规则,例如完整性、准确性、一致性、有效性和及时性等。通过这些规则,系统可以自动识别和标记质量问题。
质量规则定义和管理
用户可以自定义规则,使用 JSON 或其他标准格式来描述数据质量的各项要求。这些规则能够对数据进行周期性检查,并在发现问题时发出警报或进行自动修复。
灵活的数据源支持
Griffin 可以与多种数据源和平台集成,支持数据从 HDFS、Hive、Kafka、HBase 等数据存储中读取。它能够处理批处理和流处理两种模式的数据。
多维度数据质量监控
Apache Griffin 提供了多维度的数据质量监控功能,允许用户基于时间、地点、数据源等多个维度进行数据质量评估。这使得用户能够灵活地设置监控指标,获得更精细的质量控制。
可视化界面
Griffin 提供了一个可视化的界面,用户可以在其中查看数据质量评估的结果、数据质量报告、警告信息等。该界面使得管理者能够直观地监控和分析数据质量问题。
集成与兼容性
Griffin 与多种大数据平台高度集成,能够与现有的大数据基础设施兼容使用。例如,它可以与 Hadoop、Spark 等数据处理引擎协同工作,确保数据处理过程中的质量问题被及时发现和修正。
自动化修复
除了检测数据质量问题,Apache Griffin 还支持自动修复部分数据质量问题,比如自动填补缺失值或调整数据格式,减少人工干预。
扩展性
Griffin 提供了扩展的接口和插件机制,允许用户根据需要扩展数据质量检测功能,适应不同场景下的需求。
上节到了Griffin配置部分 下面继续
配置修改
pom.xml
修改 pom:
shell
cd /opt/servers/griffin-0.5.0
vim service/pom.xml修改内容约113行,加入MySQL的依赖:
xml
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.java.version}</version>
</dependency>修改结果如下(这里注意MySQL的版本,我这里是MySQL8版本): 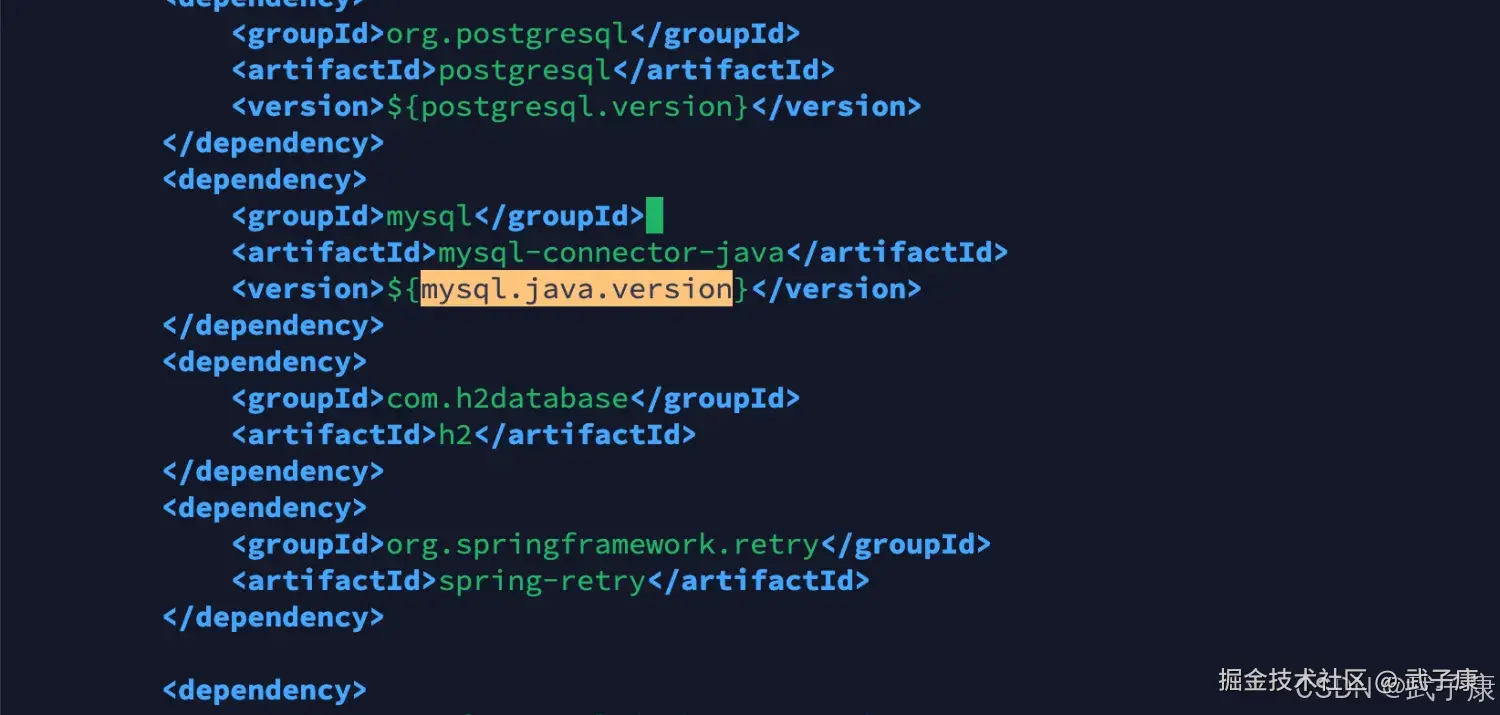
application.properties
shell
cd /opt/servers/griffin-0.5.0
vim service/src/main/resources/application.properties
shell
server.port = 9876
spring.application.name=griffin_service
spring.datasource.url=jdbc:mysql://h123.wzk.icu:3306/quartz?autoReconnect=true&useSSL=false
spring.datasource.username=hive
spring.datasource.password=hive@wzk.icu
spring.jpa.generate-ddl=true
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.jpa.show-sql=true
# Hive metastore
hive.metastore.uris=thrift://h123.wzk.icu:9083
hive.metastore.dbname=hivemetadata
hive.hmshandler.retry.attempts=15
hive.hmshandler.retry.interval=2000ms
# Hive cache time
cache.evict.hive.fixedRate.in.milliseconds=900000
# Kafka schema registry
kafka.schema.registry.url=http://localhost:8081
# Update job instance state at regular intervals
jobInstance.fixedDelay.in.milliseconds=60000
# Expired time of job instance which is 7 days that is604800000 milliseconds.Time unit only supports milliseconds
jobInstance.expired.milliseconds=604800000
# schedule predicate job every 5 minutes and repeat 12 timesat most
#interval time unit s:second m:minute h:hour d:day,onlysupport these four units
predicate.job.interval=5m
predicate.job.repeat.count=12
# external properties directory location
external.config.location=
# external BATCH or STREAMING env
external.env.location=
# login strategy ("default" or "ldap")
login.strategy=default
# ldap
ldap.url=ldap://hostname:port
ldap.email=@example.com
ldap.searchBase=DC=org,DC=example
ldap.searchPattern=(sAMAccountName={0})
# hdfs default name
fs.defaultFS=
# elasticsearch
elasticsearch.host=h123.wzk.icu
elasticsearch.port=9200
elasticsearch.scheme=http
# elasticsearch.user = user
# elasticsearch.password = password
# livy
livy.uri=http://0.0.0.0:8998/batches
livy.need.queue=false
livy.task.max.concurrent.count=20
livy.task.submit.interval.second=3
livy.task.appId.retry.count=3
# yarn url
yarn.uri=http://h123.wzk.icu:8088
# griffin event listener
internal.event.listeners=GriffinJobEventHook对应的截图如下所示: 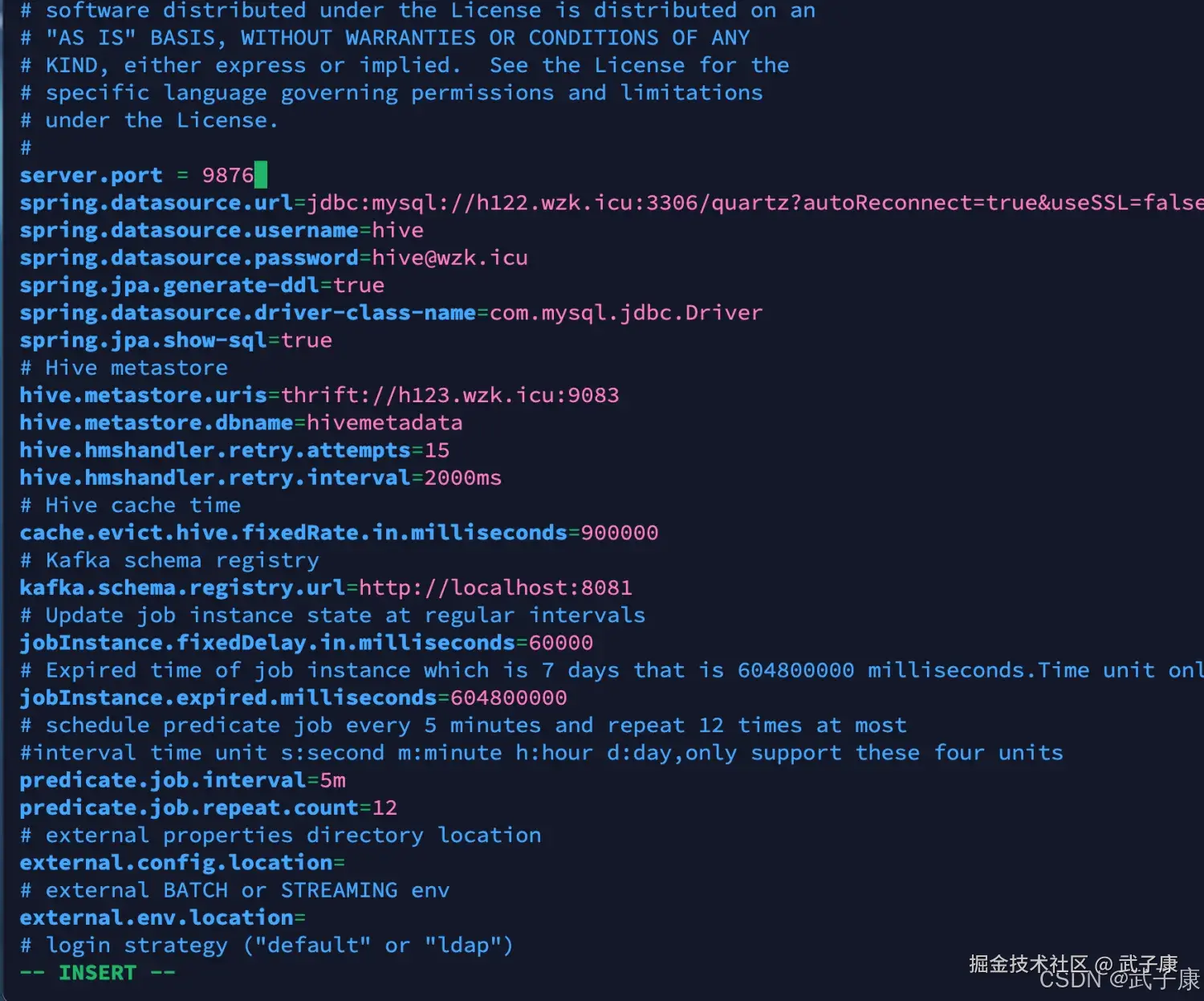 备注:
备注:
- 默认是8080,防止冲突修改为9876
- 需要启动Hive的Metastore服务
- 如果Griffin、MySQL没有在同一台节点上,需要确认可以远程登录!
quartz.properties
shell
cd /opt/servers/griffin-0.5.0
vim service/src/main/resources/quartz.properties修改内容:
shell
# 将第26行修改为以下内容
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate修改内容如下所示: 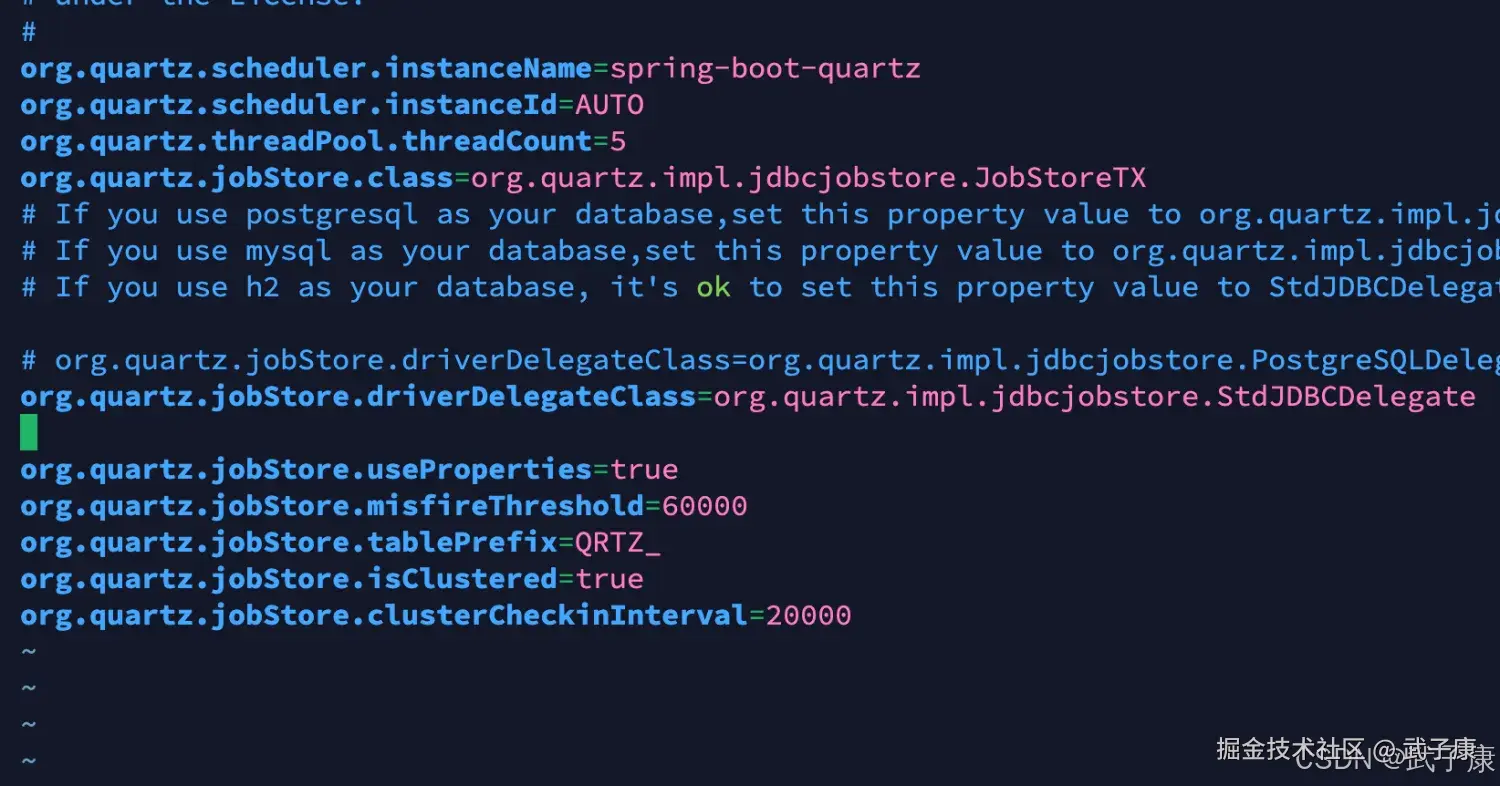
sparkProperties.json
修改配置文件
shell
cd /opt/servers/griffin-0.5.0
vim service/src/main/resources/sparkProperties.json修改内容如下:spark.yarn.dist.files
json
{
"file": "hdfs:///griffin/griffin-measure.jar",
"className": "org.apache.griffin.measure.Application",
"name": "griffin",
"queue": "default",
"numExecutors": 2,
"executorCores": 1,
"driverMemory": "1g",
"executorMemory": "1g",
"conf": {
"spark.yarn.dist.files": "hdfs:///spark/spark_conf/hive-site.xml"
},
"files": [
]
}修改的内容如下所示: 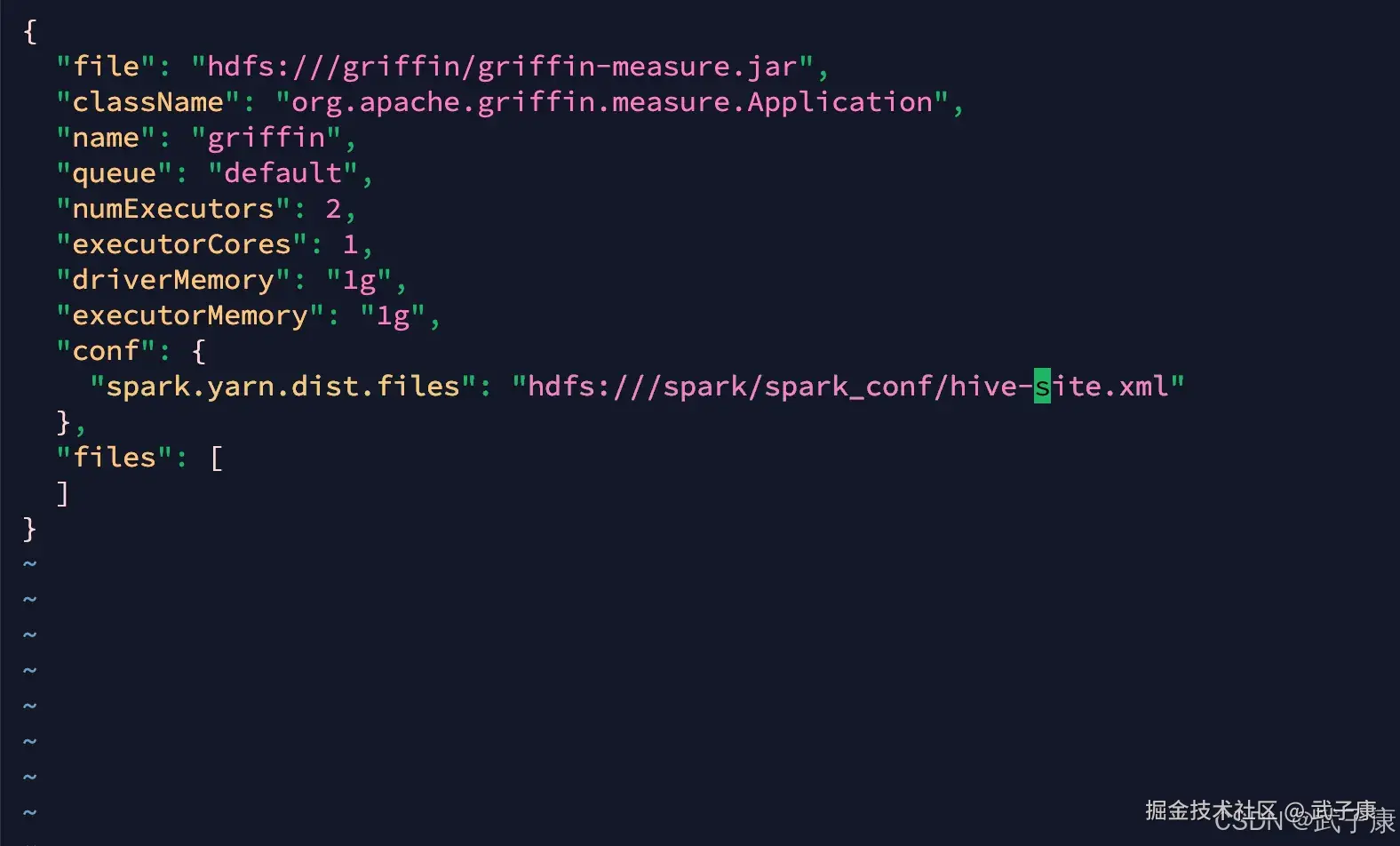
env_batch.json
继续修改对应的配置文件:
shell
cd /opt/servers/griffin-0.5.0
vim service/src/main/resources/env/env_batch.json修改的内容如下:
json
{
"spark": {
"log.level": "WARN"
},
"sinks": [
{
"type": "CONSOLE",
"config": {
"max.log.lines": 10
}
},
{
"type": "HDFS",
"config": {
"path": "hdfs:///griffin/persist",
"max.persist.lines": 10000,
"max.lines.per.file": 10000
}
},
{
"type": "ELASTICSEARCH",
"config": {
"method": "post",
"api": "http://h123.wzk.icu:9200/griffin/accuracy",
"connection.timeout": "1m",
"retry": 10
}
}
],
"griffin.checkpoint": []
}备注:
- 修改config.api的地址
正式编译
shell
cd /opt/servers/griffin-0.5.0
mvn -Dmaven.test.skip=true clean install备注:
- 编译过程中需要下载500M的jar包
- 如果修改了前面的配置文件 需要重新编译
执行过程如下所示: 
Jar拷贝
编译完成之后,会在service和measure模块的target目录下分别看到service-0.5.0.jar 和 measure-0.5.0.jar 两个jar,将这两个jar分别拷贝到服务器de 目录下:
shell
cd /opt/servers/griffin-0.5.0/service/target
cp service-0.5.0.jar /opt/servers/griffin-0.5.0/
cd /opt/servers/griffin-0.5.0/measure/target
cp measure-0.5.0.jar /opt/lagou/servers/griffin-0.5.0/griffin-measure.jar
cd /opt/lagou/servers/griffin-0.5.0
hdfs dfs -mkdir /griffin
hdfs dfs -put griffin-measure.jar /griffin备注:Spark在YARN集群上执行任务时,需要到HDFS的/griffin目录下加载griffin-measure.jar,避免发生org.apache.griffin.measure.Application找不到的错误
启动服务
启动Griffin管理后台:
shell
cd /opt/servers/griffin-0.5.0
nohup java -jar service-0.5.0.jar>service.out 2>&1 &启动之后,我们需要访问地址:
shell
http://h122.wzk.icu:9876访问的结果如下图所示: 
错误速查卡
| 症状 | 根因 | 定位 | 修复 | |
|---|---|---|---|---|
ClassNotFoundException: org.apache.griffin.measure.Application |
griffin-measure.jar 未上传至 HDFS |
hdfs dfs -ls /griffin/ 确认文件存在 |
hdfs dfs -put griffin-measure.jar /griffin |
|
| Griffin 启动后无法连接 MySQL | spring.datasource.url 地址/端口错误,或 MySQL 未开启远程访问 |
查看 service.out 中 Connection refused 报错 |
确认 MySQL grant 权限,检查防火墙 3306 端口 | |
| Hive 元数据加载失败 | Hive Metastore 未启动 | `netstat -tlnp | grep 9083` 确认端口 | hive --service metastore & 启动 Metastore |
| Maven 编译下载依赖超时 | 网络问题或 Maven 仓库不可达 | 查看 BUILD FAILURE 具体依赖报错 | 配置国内镜像(aliyun/华为云)或手动下载 jar | |
| Livy 任务提交失败 | livy.uri 填写了 0.0.0.0,需替换为实际节点 IP |
查看 Griffin 日志中 8998 端口 Connection refused | 将 livy.uri 改为实际 Livy 节点地址 |
|
| ElasticSearch 数据写入失败 | ES 节点地址或端口有误,或 ES 未启动 | curl http://host:9200/_cat/health |
修正 env_batch.json 中 config.api 地址 |
|
| Web 界面 9876 无法访问 | 服务未启动或端口被防火墙屏蔽 | tail -f service.out 查看启动日志 |
检查防火墙规则,确认 java -jar service-0.5.0.jar 进程运行 |