1. 部署目标
在 AKS 集群中,通过 Helm 部署完整监控平台,包括:
-
Prometheus
-
Grafana
-
Alertmanager
-
kube-state-metrics
-
node-exporter
-
Prometheus Adapter
适用于:
-
国内网络环境
-
节点可访问公网,但访问 Docker Hub、registry.k8s.io 容易超时
-
通过
--kubeconfig ./kubeconfig.yaml远程操作 AKS 集群 -
使用国内镜像源避免 ImagePullBackOff
2. 前置条件
确保本地机器已具备:
kubectl
helm检查集群连接:
kubectl get nodes --kubeconfig ./kubeconfig.yaml创建 monitoring 命名空间:
kubectl create namespace monitoring --kubeconfig ./kubeconfig.yaml3. 添加 Helm 仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update查看可用版本:
helm search repo prometheus-community/kube-prometheus-stack --versions | head4. 下载 资源包(适用于离线环境)
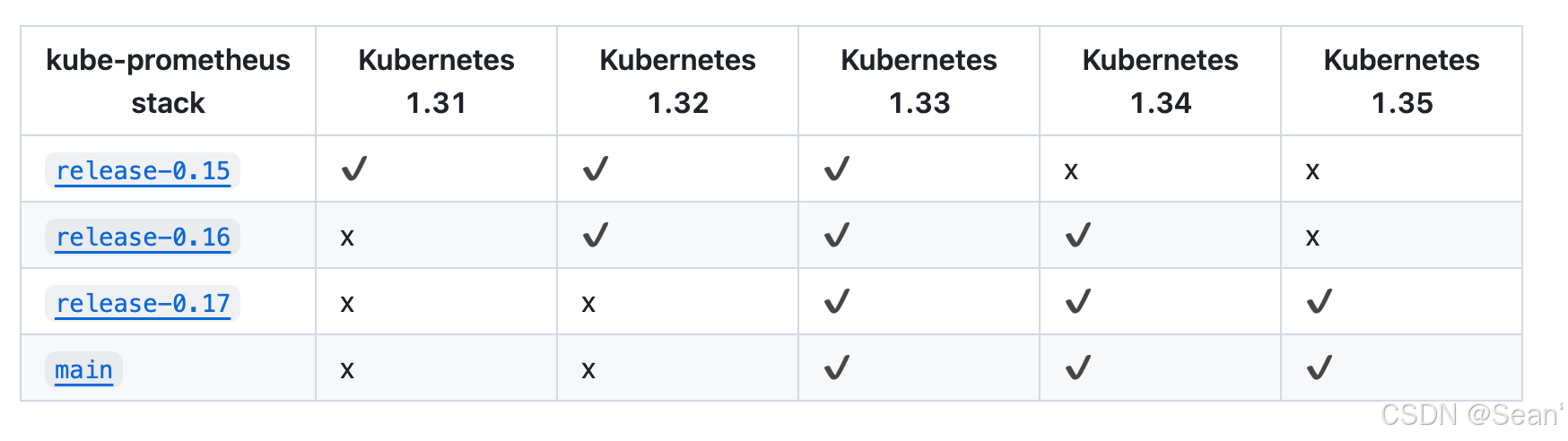
https://github.com/prometheus-operator/kube-prometheus/tree/release-0.17#
到github上下载离线资源包,根据集群版本下载对应版本的资源包,并上传服务器
5. 检查文件
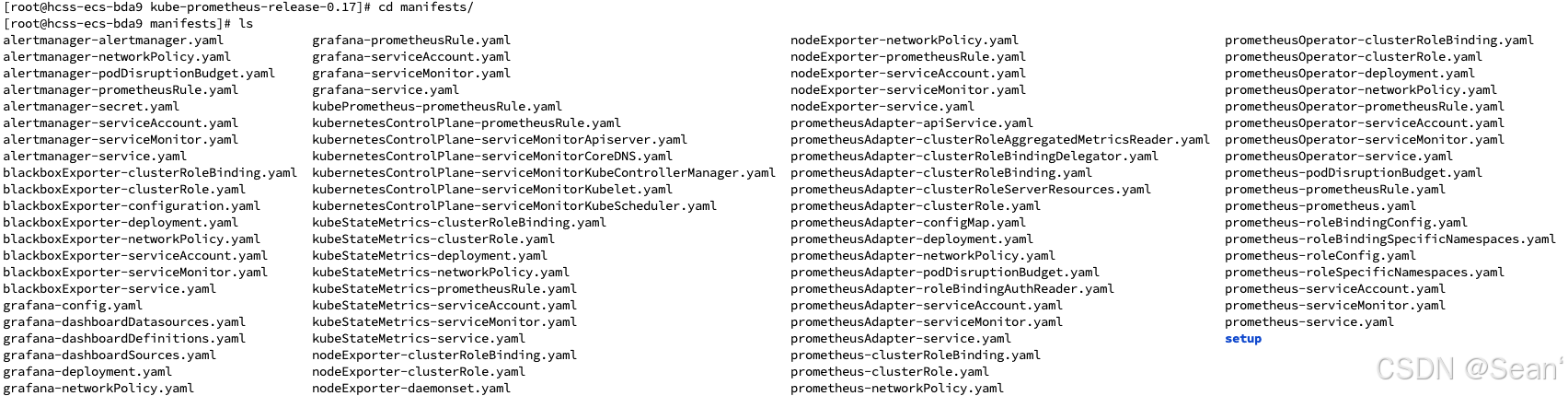
此时,进入 kube-prometheus 目录下,安装 manifest/setup 目录下的所有 yaml 文件,具体如下:
kubectl apply --server-side -f manifests/setup --force-conflicts
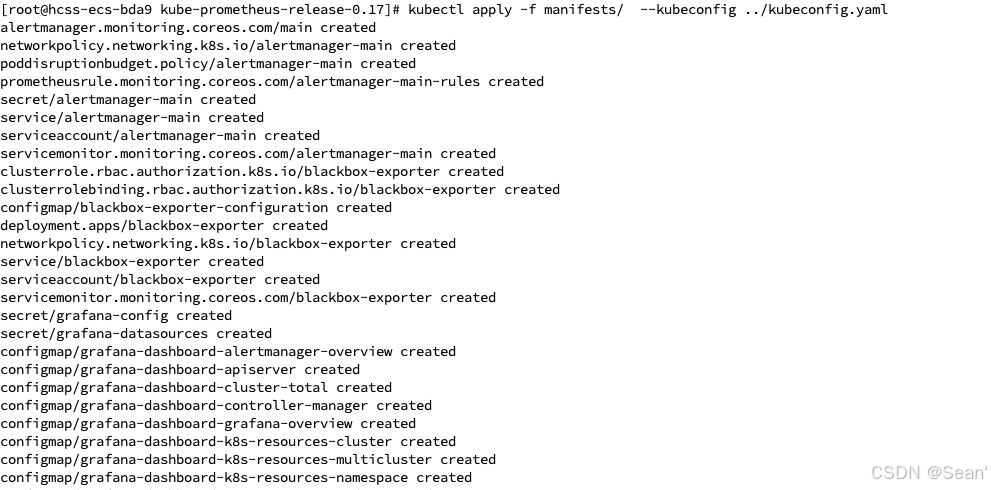
6. 安装监控平台
kubectl apply -f manifests/
7. 查看 Pod 状态
kubectl get pods -n monitoring --kubeconfig ./kubeconfig.yaml正常情况下应看到类似:
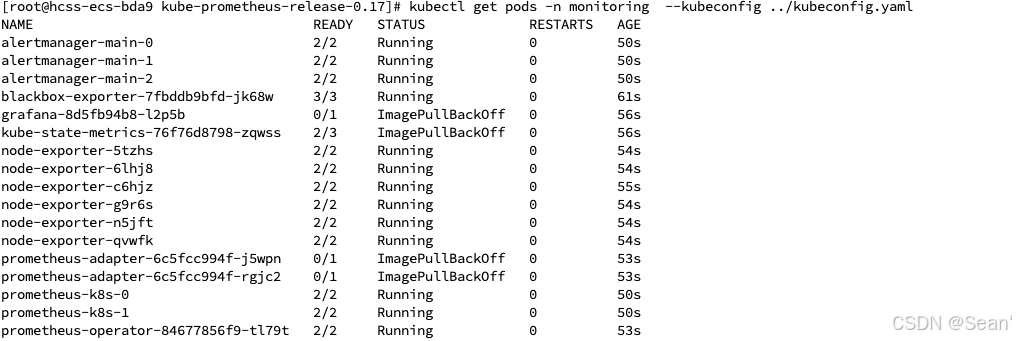
如果出现:
ImagePullBackOff
ErrImagePull说明镜像无法从 Docker Hub 或 registry.k8s.io 拉取。
8. 常见镜像拉取失败处理
Grafana 镜像失败
kubectl set image deployment/prometheus-grafana \
grafana=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/grafana/grafana:12.4.1 \
-n monitoring --kubeconfig ./kubeconfig.yamlkube-state-metrics 镜像失败
kubectl set image deployment/prometheus-kube-state-metrics \
kube-state-metrics=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.18.0 \
-n monitoring --kubeconfig ./kubeconfig.yamlprometheus-adapter 镜像失败
kubectl set image deployment/prometheus-prometheus-adapter \
prometheus-adapter=swr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0 \
-n monitoring --kubeconfig ./kubeconfig.yaml删除异常 Pod:
kubectl delete pod -n monitoring --all --kubeconfig ./kubeconfig.yaml重新检查:
kubectl get pods -n monitoring --kubeconfig ./kubeconfig.yaml9. 查看 Service
kubectl get svc -n monitoring --kubeconfig ./kubeconfig.yaml示例:
grafana LoadBalancer 10.0.131.131 20.x.x.x 3000:31054/TCP
prometheus-kube-prometheus-prometheus ClusterIP
alertmanager-prometheus-kube-prometheus-alertmanager ClusterIP10. 将 Grafana 改为 LoadBalancer
如果 Grafana 默认不是 LoadBalancer,可执行:
kubectl patch svc prometheus-grafana -n monitoring \
-p '{"spec":{"type":"LoadBalancer"}}' \
--kubeconfig ./kubeconfig.yaml查看公网 IP:
kubectl get svc prometheus-grafana -n monitoring --kubeconfig ./kubeconfig.yaml等待 EXTERNAL-IP 分配完成后,访问:
http://<EXTERNAL-IP>:300011. Grafana 登录
默认账号:
admin默认密码:
admin123如果忘记密码,可以查看 Secret:
kubectl get secret -n monitoring | grep grafana
kubectl get secret prometheus-grafana -n monitoring -o yaml --kubeconfig ./kubeconfig.yaml12. 配置 Prometheus 数据源
Grafana 登录后:
-
Connections
-
Data Sources
-
Add data source
-
选择 Prometheus
-
URL 填写:
http://prometheus-kube-prometheus-prometheus.monitoring.svc:9090
点击 Save & Test。
13. 推荐 Dashboard ID
Grafana → Dashboards → Import
推荐导入以下 Dashboard:
-
315:Kubernetes cluster monitoring
-
1860:Node Exporter Full
-
15757:Kubernetes / Compute Resources / Cluster
-
15759:Kubernetes / Views / Nodes
-
15760:Kubernetes / Views / Pods
-
15761:Kubernetes / API Server
-
13332:kube-state-metrics
优先建议导入:
-
1860
-
15757
-
15759
-
15760
这些 Dashboard 基本覆盖:
-
节点 CPU
-
节点内存
-
节点磁盘
-
Pod 状态
-
Pod 重启
-
Deployment
-
Namespace
-
API Server
-
容器资源使用率
15. 查看 Prometheus Targets
访问:
http://<prometheus-service-ip>:9090/targets或通过端口转发:
kubectl port-forward svc/prometheus-kube-prometheus-prometheus 9090:9090 \
-n monitoring --kubeconfig ./kubeconfig.yaml本地访问:
http://127.0.0.1:9090/targets检查 Targets 是否都是 UP。
16. 后续可扩展监控
后续可继续监控:
-
Nginx Ingress
-
Redis
-
MySQL
-
PostgreSQL
-
Kafka
-
RabbitMQ
-
Elasticsearch
-
JVM
-
Spring Boot
-
自定义业务服务
通常只需部署对应 exporter,然后导入 Grafana Dashboard 即可。
17. 常见排查命令
查看 Pod:
kubectl get pods -n monitoring --kubeconfig ./kubeconfig.yaml查看 Service:
kubectl get svc -n monitoring --kubeconfig ./kubeconfig.yaml查看 Deployment:
kubectl get deploy -n monitoring --kubeconfig ./kubeconfig.yaml查看镜像:
kubectl get deploy -n monitoring -o yaml | grep image:查看异常事件:
kubectl describe pod <pod-name> -n monitoring --kubeconfig ./kubeconfig.yaml查看日志:
kubectl logs <pod-name> -n monitoring --kubeconfig ./kubeconfig.yaml查看镜像拉取失败:
kubectl get pods -n monitoring | grep ImagePullBackOff删除异常 Pod:
kubectl delete pod <pod-name> -n monitoring --kubeconfig ./kubeconfig.yaml重启 Deployment:
kubectl rollout restart deployment <deployment-name> -n monitoring --kubeconfig ./kubeconfig.yaml灵感来自,感谢博主