本次实战旨在Linux环境下完成Spark单机版环境的搭建。首先确保JDK已正确安装,随后获取Spark安装包并上传至服务器指定目录。接着,将安装包解压至系统路径,并通过修改配置文件设置环境变量,使系统能够识别Spark命令。最后,通过验证命令检查安装版本,确认环境配置无误,为后续进行Spark大数据处理应用的开发与运行奠定坚实基础。
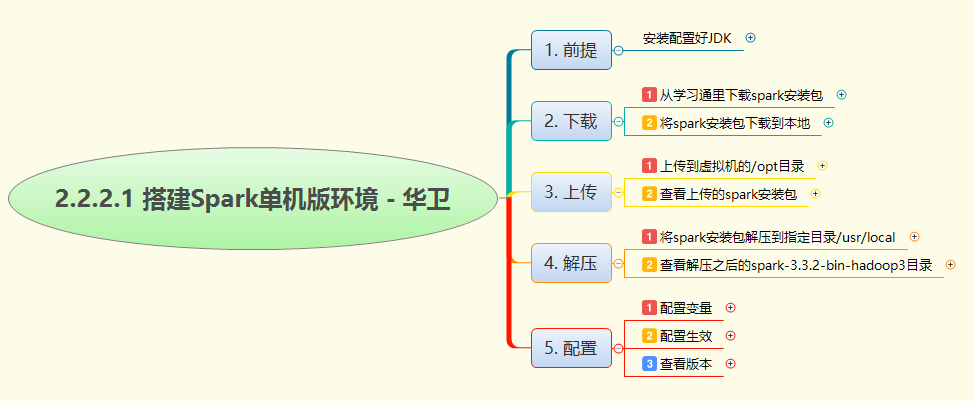
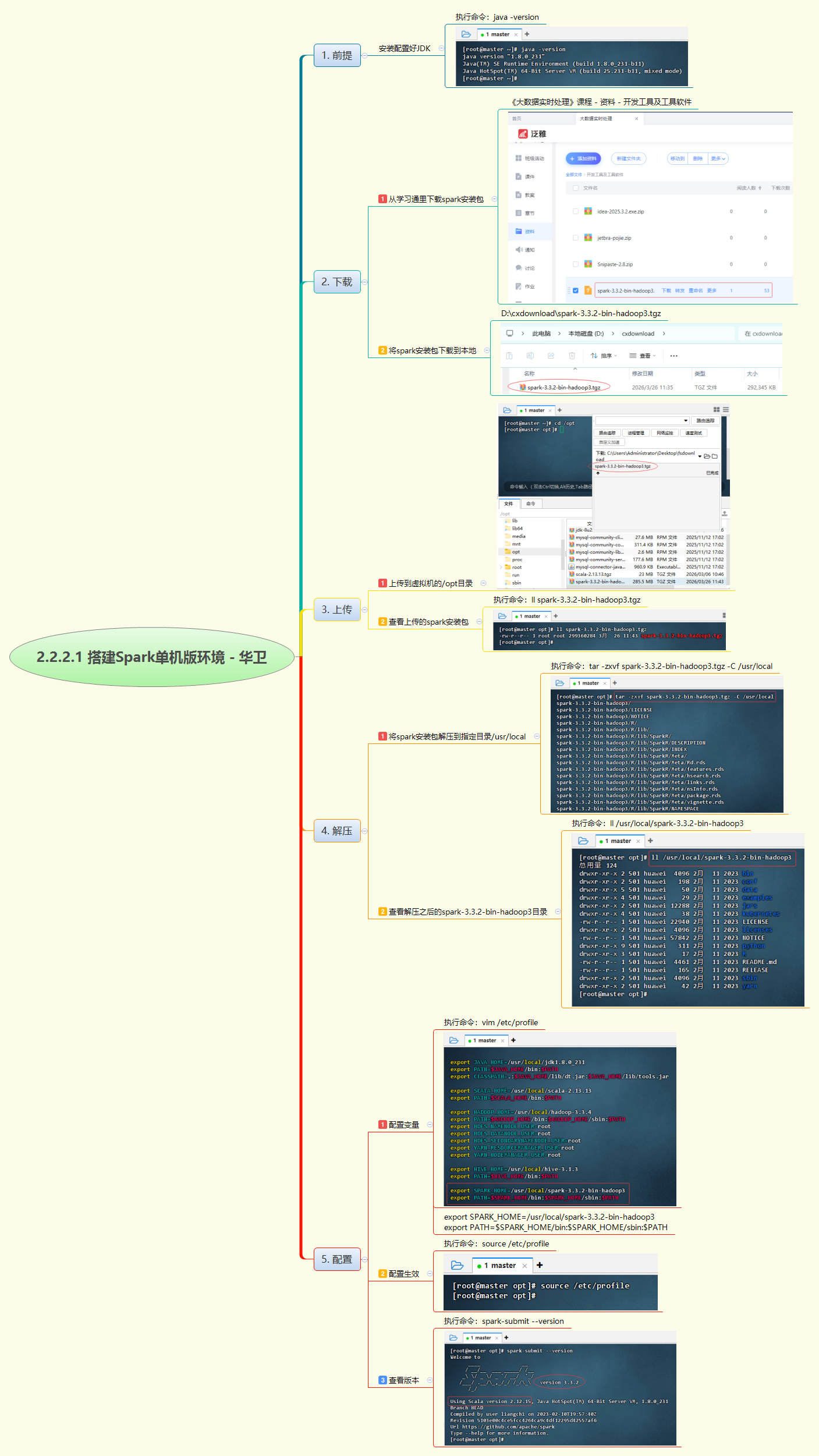
本次实战旨在Linux环境下完成Spark单机版环境的搭建。首先确保JDK已正确安装,随后获取Spark安装包并上传至服务器指定目录。接着,将安装包解压至系统路径,并通过修改配置文件设置环境变量,使系统能够识别Spark命令。最后,通过验证命令检查安装版本,确认环境配置无误,为后续进行Spark大数据处理应用的开发与运行奠定坚实基础。