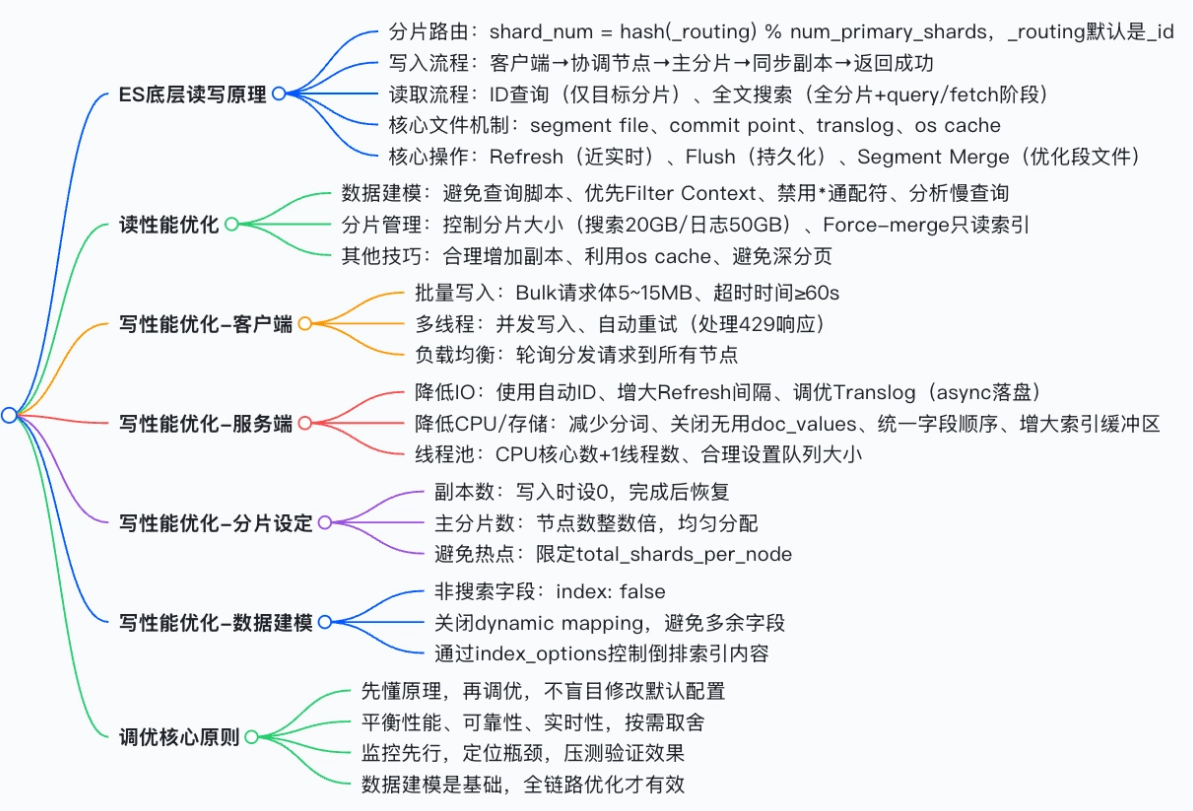
Elasticsearch(ES)的性能直接决定了业务的读写体验。性能调优的核心在于理解底层读写原理,并从数据建模、分片管理、集群配置及客户端操作四个维度进行针对性优化。
本文将从底层原理出发,结合生产环境最佳实践,为你提供一套可落地的性能优化方案,解决查询缓慢、写入吞吐量低等常见痛点。
🔑 第一部分:底层原理------调优的基石
要做好 ES 性能调优,必须先理解其分片路由规则 和底层读写流程。这是所有调优手段的设计依据。
_routing:路由字段,默认为文档_id,支持自定义(如按业务字段路由),可让相同特征文档落在同一分片。num_primary_shards:主分片数,创建后不可修改。
2. 读写流程差异
| 操作类型 | 核心特点 | 关键流程 |
|---|---|---|
| 写入 (Write) | 单点写入 | 请求 -> 协调节点 -> 主分片-> 同步副本 -> 确认 |
| 读取 (Read) | 负载均衡 | 请求 -> 协调节点 -> 轮询选择主/副本分片 -> 返回 |
💡 深度解析:写入底层的四大核心文件
- Segment File(段文件:存储倒排索引,每秒生成一个(Refresh),过多会触发合并(Merge)。
- Commit Point(提交点 :记录可用段文件,维护
.del删除标记。- Translog(事务日志:数据先写入 Translog 落盘,防止宕机丢失。
- OS Cache(操作系统缓存 :数据写入磁盘前先进入内存缓存,充分利用 OS Cache 是提升性能的关键。
📖 第二部分:读取性能优化------从查询到分片
读性能瓶颈主要集中在全文搜索的多分片遍历 、结果聚合 及低效查询语句 。核心策略是:减少计算、降低分片访问量、利用缓存。
1. 数据建模与查询优化(源头治理)
- 🚫 避免 Script 脚本计算 :脚本计算消耗大量 CPU。建议:将需计算字段(如标题长度)在写入时计算好存入,查询时直接过滤。
- ✅ 优先使用 Filter Context :
filter不进行算分且结果可缓存(Filter Cache),非算分场景应全部使用filter替代must。 - 🚫 禁止 * 开头的通配符 :如
白云*会导致全索引扫描。建议:使用分词查询、前缀查询或模糊插件。 - 🔍 分析慢查询 :利用
profile和explainAPI 定位耗时环节,判断是否走索引。
2. 分片管理优化
- 控制分片大小 :
- 搜索类场景:单分片 ≤ 20GB
- 日志类场景:单分片 ≤ 50GB
- Force-merge 只读索引 :对不再写入的索引(如按天归档的日志),执行
POST /my_index/_forcemerge,将段文件合并为 1 个,减少查询时的文件遍历开销。 - 合理增加副本:副本越多,读请求负载均衡能力越强,可提升查询吞吐量(但会牺牲写入性能)。
✍️ 第三部分:写入性能优化------全链路压榨
写性能的核心目标是提升吞吐量 。瓶颈通常在于磁盘 IO、CPU 开销及分片同步。核心原则是:批量处理、减少 IO、平衡负载。
1. 客户端优化(第一道关口)
- Bulk 批量写入 :单个请求体建议 5~15MB,避免过小产生网络开销或过大导致超时。
- 多线程并发:开启多线程写入,但需监控 HTTP 429 错误,实现自动重试与流量控制。
- 轮询分发:将请求轮询发送到集群所有节点,避免单点协调节点瓶颈。
2. 服务端配置调优(核心参数)
A. 降低磁盘 IO
- 使用 ES 自动生成 ID:跳过自定义 ID 的哈希计算,减少 CPU 开销。
- 增大 Refresh Interval :默认 1s,可调整为
10s或30s,大幅减少段文件生成和 IO 压力(牺牲实时性换取性能)。 - Translog 异步落盘 :将
index.translog.durability设为async,降低数据可靠性以换取极致写入速度。
B. 降低 CPU 与存储开销
- 减少分词 :非全文检索字段设为
keyword。 - 关闭 Doc Values :无需聚合/排序的字段关闭
doc_values。 - 关闭 Dynamic Mapping :设置
dynamic: false,避免自动创建多余字段索引。
3. 分片设定策略
- 写入时副本设为 0:写入完成后再恢复副本数,可大幅提升写入吞吐量。
- 主分片数设定:建议为主节点数的整数倍,确保负载均衡。
- 避免热点分片:限制单节点分片数,防止资源倾斜。
🏆 第四部分:极致写入配置示例(生产可用)
以下配置适用于日志采集 或冷数据迁移场景(牺牲实时性与可靠性换取极致写入性能)。
json
DELETE myindex
PUT myindex
{
"settings": {
"index": {
"refresh_interval": "30s", // 30秒刷新一次
"number_of_shards": 2, // 根据节点数调整
"number_of_replicas": 0 // 写入时无副本
},
"index.translog": {
"durability": "async", // 异步落盘
"sync_interval": "30s", // 30秒同步一次
"flush_threshold_size": "1gb" // 达到1GB触发Flush
}
},
"mappings": {
"dynamic": false, // 禁用动态映射
"properties": {
"content": { "type": "text" },
"source": { "type": "keyword", "index": false } // 不建索引
}
}
}📝 第五部分:核心总结与注意事项
1. 调优三要素(不可兼得)
- 性能:通过增大 Refresh 间隔、异步 Translog 提升。
- 可靠性:同步 Translog 保证数据不丢失。
- 实时性 :1s Refresh 保证近实时查询。 原则:日志场景选性能,金融场景选可靠性,搜索场景选实时性。
2. 黄金法则
- 先压测,后上线:切勿直接在生产环境盲目修改参数。
- 监控先行:利用 Kibana 或 Cerebro 定位瓶颈(CPU、IO、内存)。
- 默认配置优先:ES 默认配置已平衡通用场景,仅在必要时调整。
- 数据建模是基础:糟糕的建模会让后续所有调优失效。