该代码实现了一个基于扩散模型 进行数据增强,并结合BP神经网络进行回归预测的完整流程。
1. 研究背景
在回归预测任务中,若原始训练样本量较少,模型容易出现过拟合、泛化能力差的问题。扩散模型作为近年来的生成模型,可通过学习数据分布生成高质量新样本,从而扩充训练集,提升下游回归模型的稳定性与预测精度。
2. 主要功能
- 读取原始数据集,划分训练集与测试集;
- 训练扩散模型(去噪网络)学习原始特征分布;
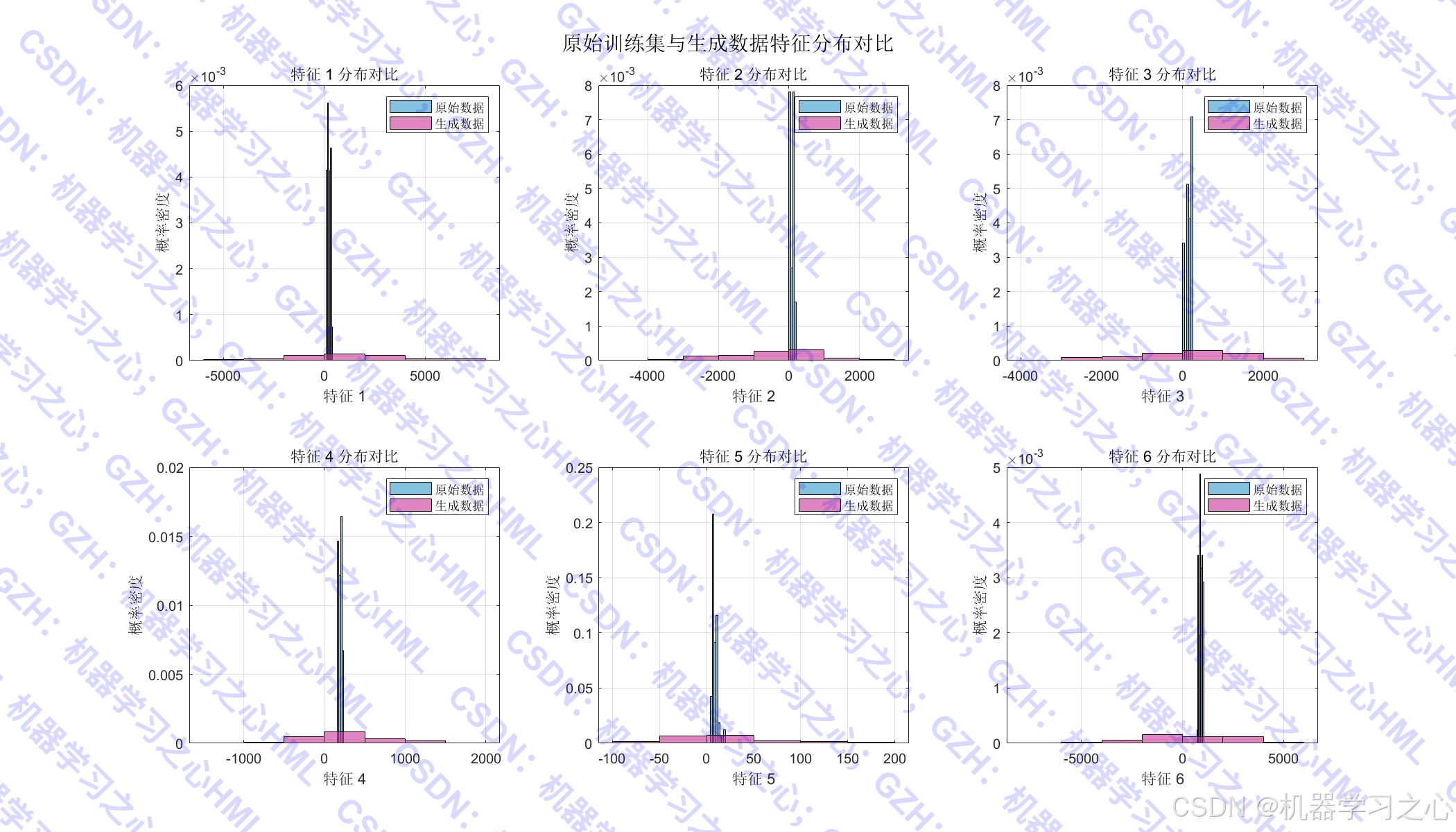
- 反向扩散生成与原始样本分布相似的新特征样本;
- 利用原始+生成样本共同训练BP神经网络回归模型;
- 输出训练集与测试集的MAE、RMSE、R²等评价指标;
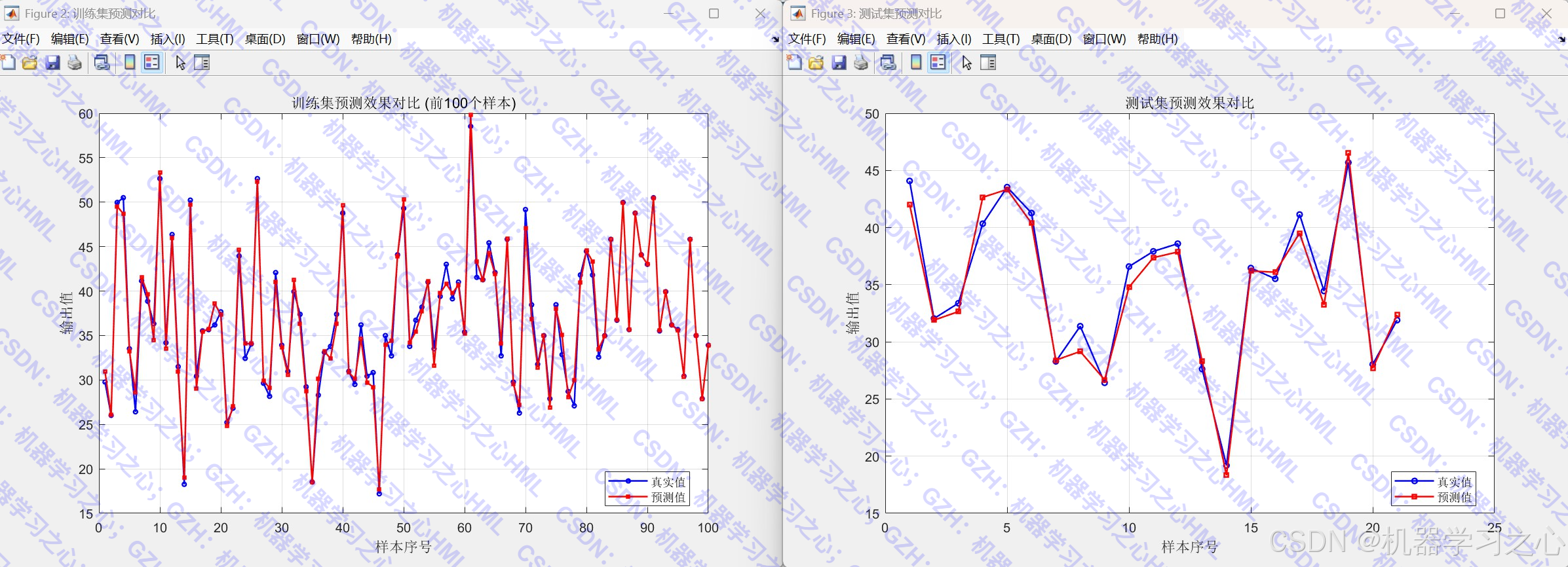
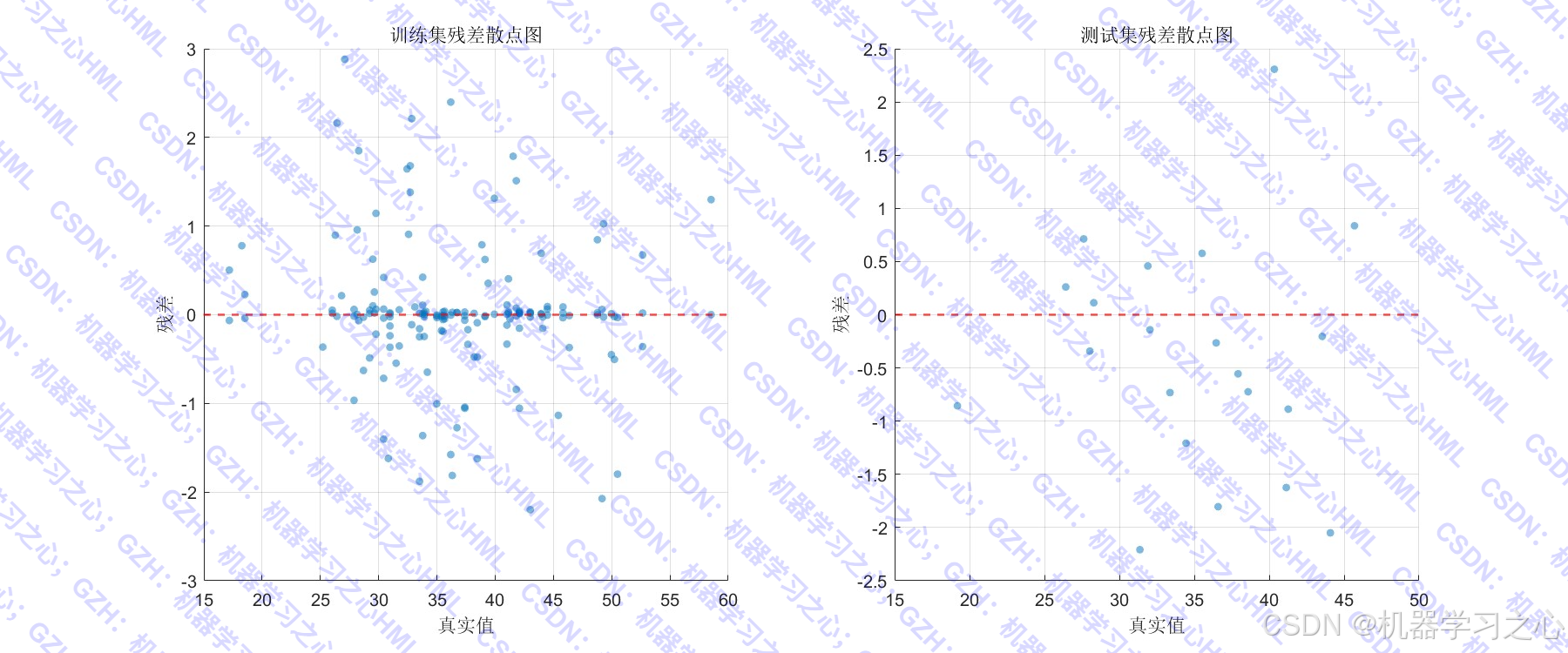
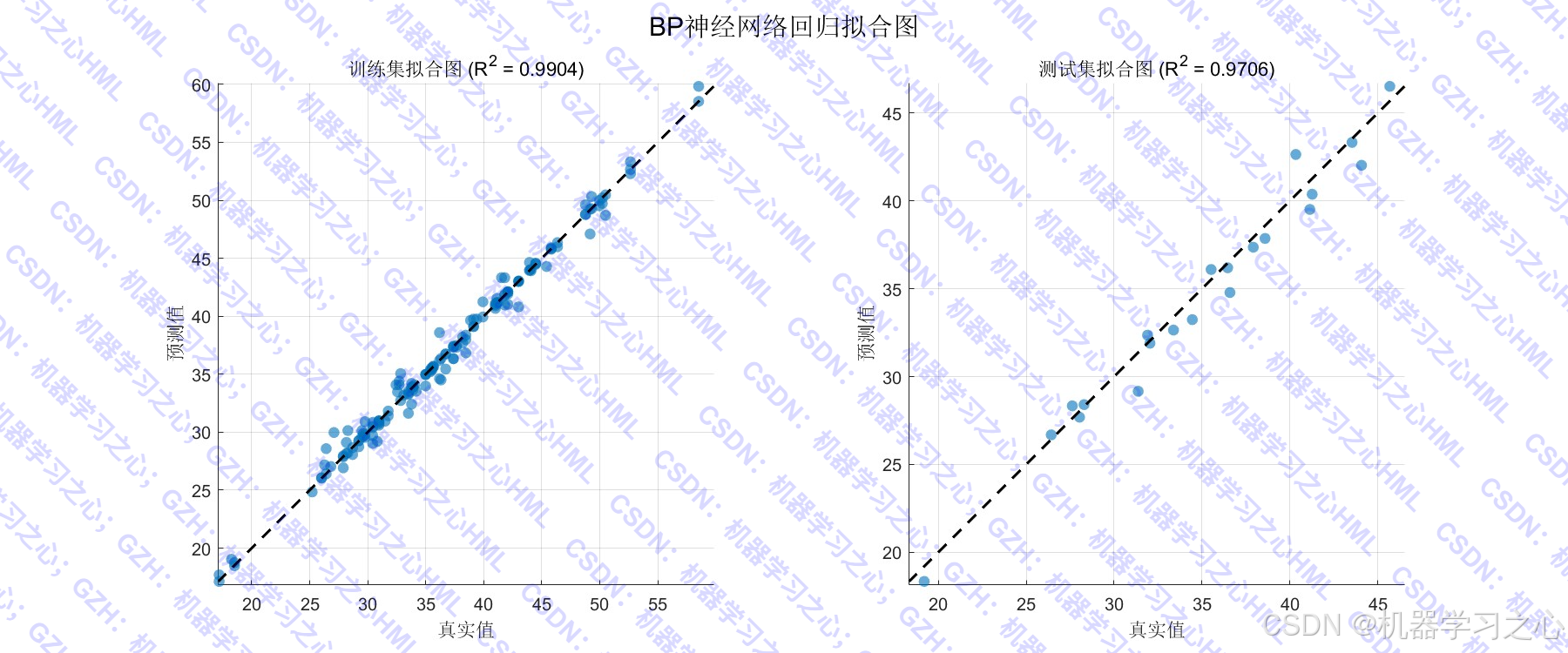
- 生成多组对比可视化图表,直观展示数据分布、预测效果及误差分析。
3. 算法步骤
- 数据预处理:读取数据、划分训练/测试集、Z-score标准化。
- 扩散模型训练
- 定义前向加噪过程:对训练样本随机加噪;
- 构建去噪网络(dlnetwork);
- 通过预测噪声进行训练,优化MSE损失。
- 新样本生成
- 从标准正态分布采样初始噪声;
- 按反向扩散公式逐步去噪,生成新的特征向量;
- 对生成的标签采用有放回采样方式从原始训练集中抽取。
- BP神经网络训练
- 用增强后的训练集训练BP网络;
- 在测试集上进行预测并反标准化。
- 结果评估与可视化
- 计算回归指标;
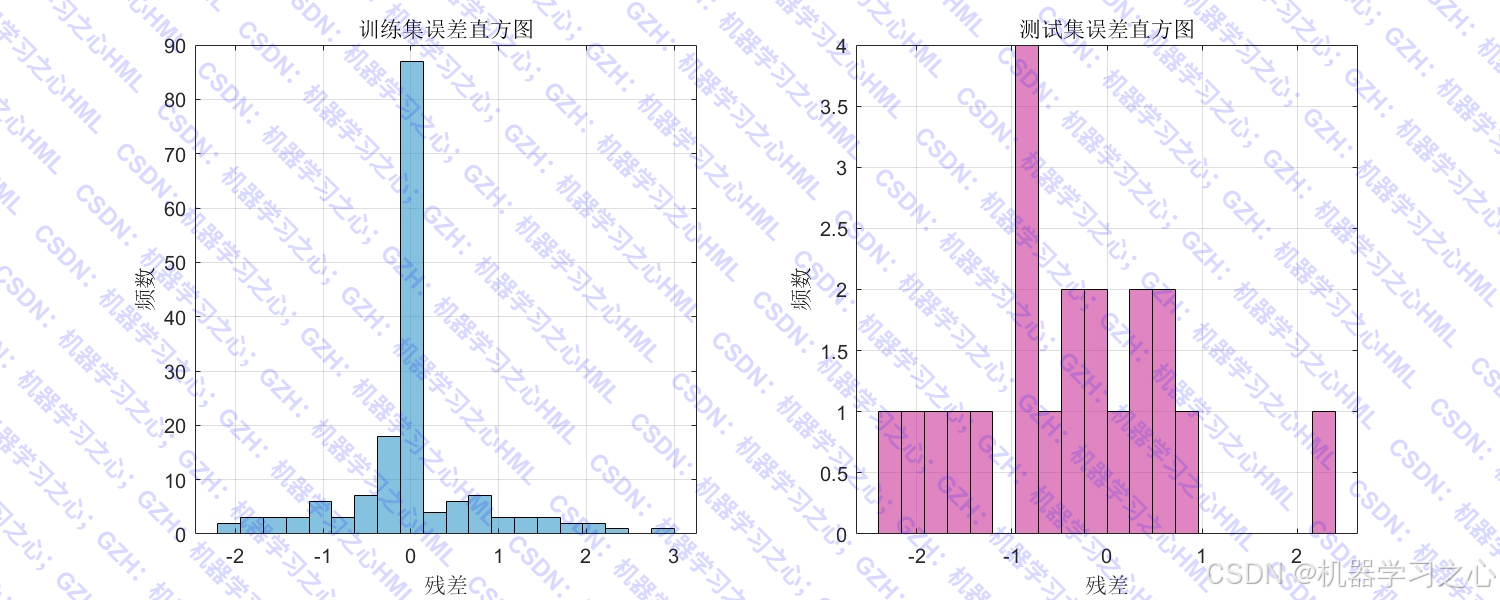
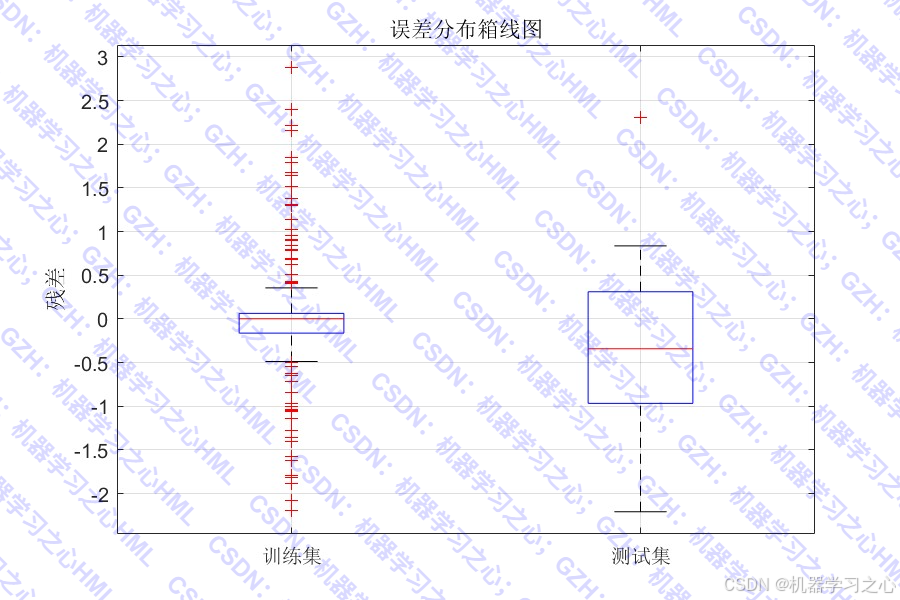
- 绘制数据分布对比、预测曲线、残差散点图、误差箱线图、拟合图、误差直方图等。
4. 技术路线
- 扩散模型:采用DDPM风格的加噪与去噪结构,前向过程逐步添加高斯噪声,反向过程学习噪声预测。
- 去噪网络:使用全连接网络 + 时间步嵌入,输入为加噪样本与时间步的拼接向量。
- 回归网络:两层隐藏层的BP神经网络,使用Levenberg-Marquardt优化算法。
- 数据增强:生成样本数量与原始训练集相同,有效扩充训练样本量。
5. 公式原理
-
前向加噪 :
xt=αˉt x0+1−αˉt ϵ x_t = \sqrt{\bar{\alpha}_t}\, x_0 + \sqrt{1-\bar{\alpha}_t}\,\epsilon xt=αˉt x0+1−αˉt ϵ其中αˉt\bar{\alpha}tαˉt === ∏i=1t(1−βi)\prod{i=1}^t (1-\beta_i)∏i=1t(1−βi),ϵ∼N\epsilon \sim \mathcal{N}ϵ∼N(0,I)$。
-
反向去噪 :
xt−1=1αt(xt−1−αt1−αˉtϵθ(xt,t))+βt z x_{t-1} = \frac{1}{\sqrt{\alpha_t}} \left( x_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}t}} \epsilon\theta(x_t, t) \right) + \sqrt{\beta_t}\, z xt−1=αt 1(xt−1−αˉt 1−αtϵθ(xt,t))+βt z当t>1t>1t>1时 z∼N(0,I)z \sim \mathcal{N}(0,I)z∼N(0,I),否则z=0z=0z=0。
-
损失函数 :
L=Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥2 \mathcal{L} = \mathbb{E}_{t, x_0, \epsilon} \left \\\|\\epsilon - \\epsilon_\\theta(x_t, t)\\\|\^2 \\right L=Et,x0,ϵ∥ϵ−ϵθ(xt,t)∥2即去噪网络预测的噪声与真实噪声的均方误差。
6. 参数设定
| 模块 | 参数 | 设定值 |
|---|---|---|
| 扩散模型 | 时间步数TTT | 1000 |
| β\betaβ范围 | 10−4∼0.0210^{-4} \sim 0.0210−4∼0.02(线性) | |
| 时间嵌入维度 | 128 | |
| 去噪网络隐藏层 | 128, 128, 128 | |
| 训练轮数 | 50 | |
| 批次大小 | 512 | |
| 学习率 | 1×10−31\times10^{-3}1×10−3(Adam) | |
| BP网络 | 隐藏层结构 | 10, 10 |
| 训练算法 | trainlm(Levenberg-Marquardt) | |
| 最大迭代轮数 | 200 | |
| 目标误差 | 1×10−51\times10^{-5}1×10−5 | |
| 数据划分 | 训练集比例 | 80% |
| 生成样本数 | 与原始训练集相同 |
7. 运行环境
- 软件:MATLAB2024b
- 输入文件:
数据集.xlsx,最后一列为目标变量,其余为特征变量
8. 应用场景
- 小样本回归问题:如工业过程参数预测、材料性能估算、生物医学指标建模等,原始数据获取成本高、样本量少。
- 数据增强:通过生成与真实分布相近的样本,提升回归模型的泛化能力与鲁棒性。
- 对比研究:可用于验证扩散模型在表格数据生成中的有效性,以及数据增强对回归性能的提升效果。
完整代码私信回复扩散模型(Diffusion Model)数据生成+BP神经网络回归预测,Matlab完整代码
matlab
原始训练集样本数: 82
开始训练扩散模型...
Epoch 10/50, Loss: 3.421500
Epoch 20/50, Loss: 3.147189
Epoch 30/50, Loss: 2.919070
Epoch 40/50, Loss: 3.025227
Epoch 50/50, Loss: 2.431991
扩散模型训练完成!
生成新样本数: 82,增强后训练集总样本数: 164
开始训练BP神经网络...
========== 回归结果 ==========
训练集 - MAE: 0.4457, RMSE: 0.7685, R2: 0.9904
测试集 - MAE: 0.8983, RMSE: 1.1279, R2: 0.9706