算法刷题打卡 | 今天也是重点题 ------LeetCode146. LRU 缓存。刷过这道题的小伙伴,大概率都写过「双向链表 + 哈希表」的手写实现,毕竟这是面试的经典考点。但你知道吗?JDK 其实早就给我们内置了 LRU 的核心实现,只要读懂 LinkedHashMap 的源码,我们只需要不到 30 行代码就能搞定这道中等难度的题目,甚至还能写出比官方题解更优雅的封装。
一、题目回顾:LRU 缓存到底要做什么?
首先我们先回顾一下这道经典的题目,确保我们对需求没有偏差:
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现
LRUCache类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存
int get(int key)如果关键字key存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。
void put(int key, int value)如果关键字key不存在,则插入该键值对;如果关键字key已存在,则更新其对应的值;如果插入后缓存的键的数量超出容量capacity,则需要淘汰 最久未使用 的那个键。
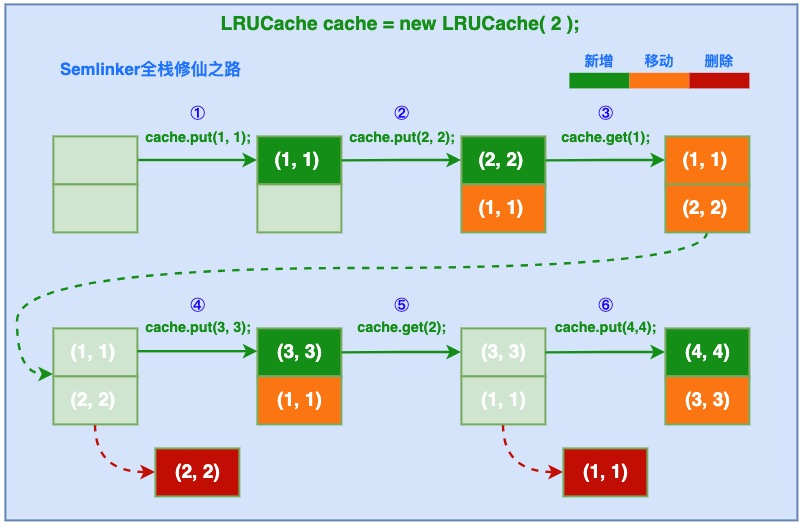
LRU 的核心逻辑非常好理解:缓存的空间是有限的,当空间满了的时候,我们把最近最久没有被访问过的数据淘汰掉,因为我们认为「最近被访问过的数据,未来被访问的概率更高」,这也是目前最常用的缓存淘汰策略之一。
二、阅读建议:循序渐进的学习路径
很多刚接触 LRU 的小伙伴,一上来就看手写双向链表的代码,很容易被各种指针操作搞晕。这里给大家整理了两种实现的阅读顺序建议:
如果你是刚接触 LRU 的新手,先看标准写法 ,快速理解 LRU 的核心逻辑,不用被链表细节卡住;
如果你已经理解了核心思路,想要搞懂底层的实现细节,或者准备面试,再看手写双向链表的原生实现。
三、标准实现:两行代码搞定核心逻辑
首先我们来看最简单的标准写法,不用自己写任何链表操作,利用 JDK 自带的 LinkedHashMap,就能快速实现 LRU,帮你快速理解核心逻辑。
写法一:手动维护顺序,新手友好版
这个写法非常简单,我们不用改 LinkedHashMap 的任何东西,直接利用它的插入顺序特性,手动维护元素的顺序:
-
每次我们访问一个元素,就把它从 Map 里删掉,再重新插回去,这样它就变成了最后插入的元素,跑到链表的尾部了。
-
当缓存满了的时候,我们删掉第一个元素,也就是最久没被访问的那个。
整个代码非常短,新手一眼就能看懂:
java
class LRUCache {
private final int capacity;
private final Map<Integer, Integer> cache = new LinkedHashMap<>(); // 利用插入顺序
public LRUCache(int capacity) {
this.capacity = capacity;
}
public int get(int key) {
// 删除 key,并利用返回值判断 key 是否在 cache 中
Integer value = cache.remove(key);
if (value != null) { // key 在 cache 中,重新插入,放到尾部
cache.put(key, value);
return value;
}
// key 不在 cache 中
return -1;
}
public void put(int key, int value) {
// 删除 key,并利用返回值判断 key 是否在 cache 中
if (cache.remove(key) != null) { // key 在 cache 中,更新后重新插入
cache.put(key, value);
return;
}
// key 不在 cache 中,插入前判断是否满了
if (cache.size() == capacity) { // cache 满了,删掉最久的第一个元素
Integer eldestKey = cache.keySet().iterator().next();
cache.remove(eldestKey);
}
cache.put(key, value);
}
}这个写法是不是超级简单?没有任何复杂的逻辑,完全就是把 LRU 的核心逻辑用最直白的方式写出来了,新手看完就能明白 LRU 到底是怎么回事,完全不用管链表的指针操作。
写法二:优雅的组合式封装,利用 JDK 原生特性
看完了新手版的写法,我们再来看更优雅的写法,利用 LinkedHashMap 的访问顺序特性,JDK 已经帮我们自动维护了元素的顺序,我们不用手动删了插,代码更简洁,性能也更好。
这个就是我们之前提到的,利用 LinkedHashMap 的钩子方法,重写淘汰规则,同时用组合的方式做封装,对外隐藏底层实现:
java
class LRUCache {
// 内部类实例,所有的LRU逻辑都委托给它
private final LRUCache1<Integer,Integer> LRU;
public LRUCache(int capacity) {
this.LRU=new LRUCache1(capacity);
}
// 对外暴露的get方法,用getOrDefault,不存在就返回-1
public int get(int key) {
return LRU.getOrDefault(key,-1);
}
// 对外暴露的put方法
public void put(int key, int value) {
LRU.put(key,value);
}
// 私有内部类,对外完全隐藏
private class LRUCache1<K,V> extends LinkedHashMap<K,V>{
private final int capacity;
public LRUCache1(int capacity){
// 核心:第三个参数true,开启访问顺序!
super(capacity,0.75F,true);
this.capacity=capacity;
}
// 重写淘汰规则
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest){
return size()>capacity;
}
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache obj = new LRUCache(capacity);
* int param_1 = obj.get(key);
* obj.put(key,value);
*/这个写法比手动维护的更优雅,JDK 帮我们做了所有的顺序维护,我们只需要定义淘汰规则就可以了,而且用组合的方式,完美封装了底层的 LinkedHashMap,对外只暴露我们需要的接口。
四、源码深度解析:LinkedHashMap 是怎么做到的?
很多小伙伴看完上面的写法,可能会好奇,LinkedHashMap 到底是怎么自动维护访问顺序的?为什么重写一个方法就能实现 LRU?这就要说到 LinkedHashMap 的底层源码了。
我们都知道,HashMap 是无序的,而 LinkedHashMap 作为它的子类,在哈希表的基础上,额外维护了一个 双向链表,用来维护元素的顺序。
更妙的是,LinkedHashMap 支持两种排序模式:
-
插入顺序:默认模式,元素的顺序和你插入的顺序一致,这也是我们平时最常用的模式。
-
访问顺序:当你开启这个模式之后,每次你访问(get 或者更新已存在的 key)一个元素,这个元素都会被自动移动到双向链表的尾部。
看到这里你是不是反应过来了?这不就是 LRU 缓存需要的排序逻辑吗?
我们来看一张示意图,就能很直观的理解这个结构:
在这个结构里:
-
链表的
head节点,就是最久没有被访问过的元素,也就是我们缓存满了之后要淘汰的元素。 -
链表的
tail节点,就是最近刚刚被访问过的元素。 -
每次我们访问一个元素,它都会被移动到
tail的位置,这样就能保证,越靠近 head 的元素,就是越久没被用的。
而这一切,都是 LinkedHashMap 通过三个预留的回调钩子函数自动完成的,这三个函数都是在 HashMap 里预留的空实现,LinkedHashMap 重写了它们,用来维护双向链表的顺序:
java
// 访问节点之后的回调:把访问的节点移到链表尾部
void afterNodeAccess(Node<K,V> p) { }
// 删除节点之后的回调:把节点从双向链表中移除
void afterNodeRemoval(Node<K,V> p) { }
// 插入节点之后的回调:判断是否需要淘汰最老的节点
void afterNodeInsertion(boolean evict) { }1. afterNodeAccess:访问节点后自动移到尾部
这个函数就是实现访问顺序的核心,每次我们调用 get 方法,或者更新一个已经存在的 key 的时候,这个函数就会被触发,把当前访问的节点移动到双向链表的尾部。
我们来看 JDK 里的源码,配合注释就能很容易看懂:
java
void afterNodeAccess(Node<K,V> e) {
// last 代表原来的尾节点
LinkedHashMap.Entry<K,V> last;
// 只有开启了访问顺序,并且当前节点不是尾节点,才需要移动
if (accessOrder && (last = tail) != e) {
// p: 当前节点,b: 前一个节点,a: 后一个节点
// 原来的结构:b <=> p <=> a
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
// 先把p的after指针置空,断开和a的连接
p.after = null;
// 如果b是空,说明p原来就是头节点,那新的头节点就是a
if (b == null)
head = a;
// 否则,把b和a连接起来,跳过p
else
b.after = a;
// 如果a不是空,把a的before指向b,完成b和a的双向连接
if (a != null)
a.before = b;
// 否则p本来就是尾节点,这里理论上不会触发,因为开头已经判断了p不是尾节点
else
last = b;
// 现在把p插入到尾节点的位置
p.before = last;
last.after = p;
// 更新tail指针,现在p就是新的尾节点了
tail = p;
++modCount;
}
}看完这个源码你就会明白,LinkedHashMap 已经帮我们把双向链表的节点移动逻辑写的非常优雅了,我们完全不需要自己写这些复杂的指针操作,JDK 已经帮我们做了所有的脏活累活。
2. afterNodeInsertion:插入后自动淘汰最老节点
那当缓存满了的时候,怎么自动淘汰最老的节点呢?这就要靠第二个钩子函数 afterNodeInsertion 了,这个函数会在我们插入新节点之后被触发。
我们来看它的源码:
java
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
// evict是触发标记,HashMap的putVal里一直是true
// 如果满足淘汰条件,就删除头节点(最老的节点)
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}这里的核心就是 removeEldestEntry 这个方法,这个方法默认返回 false,意思是永远不淘汰节点。但是!它是一个 protected 的方法,也就是说,我们可以继承 LinkedHashMap,然后重写这个方法,自定义我们的淘汰规则!
对于 LRU 缓存来说,我们的规则很简单:当缓存的大小超过了我们设定的容量,就淘汰最老的节点,所以我们只需要重写这个方法,返回 size() > capacity 就可以了!
是不是非常巧妙?LinkedHashMap 已经把所有的逻辑都写好了,我们只需要给它一个淘汰的条件,它就会自动帮我们完成淘汰!
五、面试必备:手写双向链表原生实现
看完了标准库的写法,我们再来看面试的时候必须会的手写实现,毕竟面试官可能会让你「不用 LinkedHashMap,自己手写一个」,这时候就需要我们自己实现双向链表 + 哈希表的结构了。
这个实现的核心思路和 LinkedHashMap 的底层是一样的:用哈希表做 O (1) 的查找,用双向链表维护元素的访问顺序,我们自己实现节点的移动和淘汰逻辑。
写法三:手写双向链表的底层实现
java
class LRUCache {
// 双向链表的节点
private static class Node {
int key, value;
Node prev, next;
Node(int k, int v) {
key = k;
value = v;
}
}
private final int capacity;
private final Node dummy = new Node(0, 0); // 哨兵节点,简化边界操作
private final Map<Integer, Node> keyToNode = new HashMap<>(); // 哈希表,快速查找节点
public LRUCache(int capacity) {
this.capacity = capacity;
// 初始化哨兵节点,自己指向自己,形成环
dummy.prev = dummy;
dummy.next = dummy;
}
public int get(int key) {
Node node = getNode(key); // getNode 会把对应节点移到链表头部
return node != null ? node.value : -1;
}
public void put(int key, int value) {
Node node = getNode(key); // getNode 会把对应节点移到链表头部
if (node != null) { // 节点已经存在,更新值就好
node.value = value;
return;
}
// 节点不存在,新建节点
node = new Node(key, value);
keyToNode.put(key, node);
pushFront(node); // 放到链表头部,代表最近访问
if (keyToNode.size() > capacity) { // 缓存满了,淘汰最久的节点
Node backNode = dummy.prev; // 尾部的节点就是最久的
keyToNode.remove(backNode.key); // 删掉哈希表的记录
remove(backNode); // 删掉链表的节点
}
}
// 获取节点,同时把节点移到头部
private Node getNode(int key) {
if (!keyToNode.containsKey(key)) { // 节点不存在
return null;
}
Node node = keyToNode.get(key);
remove(node); // 先把节点从原来的位置删掉
pushFront(node); // 插到头部
return node;
}
// 从链表中删除节点
private void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
}
// 把节点插到链表头部
private void pushFront(Node x) {
x.prev = dummy;
x.next = dummy.next;
x.prev.next = x;
x.next.prev = x;
}
}这个就是标准的手写 LRU 实现,也是面试的时候面试官想要看到的代码,所有的链表操作都是我们自己实现的,完全不依赖标准库的 LinkedHashMap。
六、不同写法的适用场景
现在我们有了三种不同的写法,可能有人会问,我到底该用哪一种?
| 写法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 手动维护 LinkedHashMap | 简单易懂,新手友好,不用改任何东西 | 每次访问都要删了插,性能稍差 | 新手学习,快速理解核心逻辑 |
| 继承重写 LinkedHashMap | 代码简洁,性能好,JDK 自动维护顺序 | 继承会暴露多余方法,我们用组合解决了这个问题 | 刷题快速过题,生产环境简单缓存 |
| 手写双向链表 | 不依赖标准库,完全自己实现 | 代码复杂,容易写错指针 | 面试,考察底层实现能力 |
总的来说:
-
刷题的时候,用继承重写的写法,最快最稳,一分钟就能写完过题。
-
学习的时候,先看手动维护的写法,理解核心逻辑,再看手写的,搞懂细节。
-
面试的时候,写手写双向链表的版本,让面试官看到你懂底层原理。
总结
总的来说,LRU 缓存的实现其实并不复杂,核心就是用哈希表做快速查找,用双向链表维护访问顺序。JDK 的 LinkedHashMap 已经帮我们把这些都实现好了,我们只要读懂源码,就能用很少的代码搞定这道题。
当然,面试的时候,我们还是要会手写原生的实现,毕竟这是考察我们对数据结构的掌握程度,但是不管是哪种写法,核心的思路都是一样的,只要你理解了 LRU 的核心逻辑,不管用什么方式,都能写出来。