对大模型而言,架构必然是对模型能力产生决定性的影响。问题在于模型确定之后,模型的训练则是重中之重。对于参数数量达到千亿乃至万亿的模型而言,模型训练是非常复杂的工程问题,这也是世界上只有中美两国
才能搞出大模型的原因。模型的训练不仅仅要有大量的GPU,而且如何系统性的将这些GPU调度起来并行运行是非常复杂的系统设计问题,因此大模型的设计,训练这些困难度就连日韩欧这些发达国家都搞不定。
假设我们已经有了好的模型架构,有了足够多的GPU训练卡,也有了满足需求的调度系统,那么模型的训练是不是就比如水到渠成呢,答案是否定的。可以看到有不少开源大模型在给出详细的架构和算法时,他们总会遮遮掩掩一个信息,那就是模型的初始化参数,通常情况下,如果初始化参数调节不对,后续的训练极有可能失败,而一次大模型的训练迭代花费有几千万,因此缺失了模型参数初始化数值,即使把模型架构和相应算法全部公开给你,你依然未必能实现给定的性能。
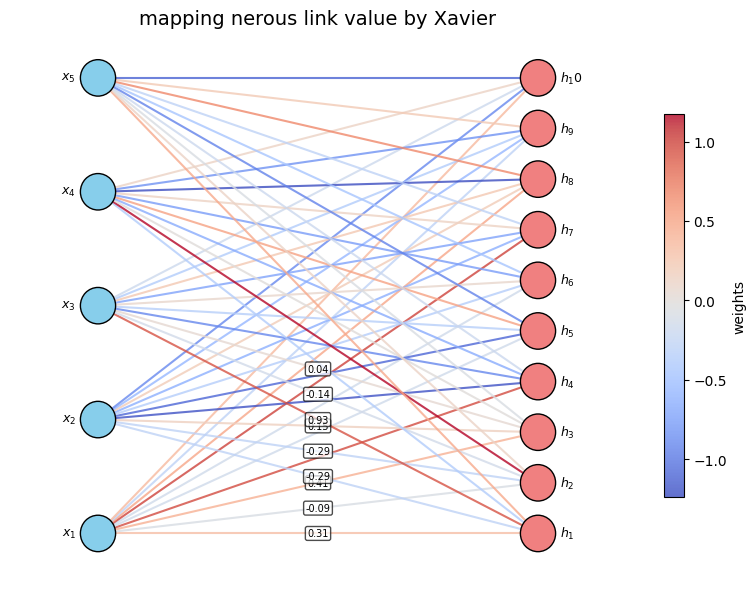
模型参数初始化的算法多种多样,但大多数都基于两种算法,分别为Xavier/Glorot 和He初始化算法。我们先看前者的原理和实现。Xavier/Glorot初始化算法试用与模型采用激活函数为Sigmod,tanh等所谓S形函数情况,它的核心思想是,让网络在前向传播和反向传播时,确保数值的变化方差在一定的范围内。具体做法是,假设有两层神经元,你一层神经元个数为N_in,第二层神经元个数为N_out,那么根据这两个数据构造参数a = sqrt(6/(N_in + N_out)), 然后两层神经元直接的连接参数在初始化时在区间-a, a内随机抽样。我们用代码走一遍算法流程就更加容易明白了:
py
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.collections import LineCollection
'''
模拟两层神经元,第一层5个神经元,第二层10个神经元,然后使用Xavier进行连接权重的初始化
'''
np.random.seed(42)
#第一层神经元个数
n_input = 5
#第二层神经元个数
n_output = 10
#构造参数a
a = np.sqrt(6 / (n_input + n_output))
#在范围[-a, a]内随机抽取,给每个连接权重进行初始化
#size=(n_input,n_output)是一个行为n_input,列为n_output的矩阵,每个矩阵元素对应连接的权重
weights = np.random.uniform(-a, a, size=(n_input, n_output))
print("Xavier权重初始化区间[{:.4f}, {:.4f}]".format(-a, a))
print("生成的权重矩阵(前几个值):\n", weights[:3, :3])
#以下绘制两层网络,第一层有5个神经元,第二层有10个,然后显示两层神经元连接在上面初始化后对应的数值
x_left=0.0 #第一层神经元所在坐标
x_right=1.0 #第二层神经元所在坐标
y_left=np.linspace(0, 1, n_input)
y_right=np.linspace(0, 1, n_output)
fig, ax = plt.subplots(figsize=(8,6))
ax.set_xlim(-0.2,1.2)
ax.set_ylim(-0.1,1.1)
ax.axis('off')
ax.set_title("mapping nerous link value by Xavier", fontsize=14)
#绘制原型节点表示神经元,
for i, y in enumerate(y_left):
circle = plt.Circle((x_left, y), 0.04, color='skyblue', ec='black', zorder=3)
ax.add_patch(circle)
ax.text(x_left-0.05, y, f'$x_{i+1}$', ha='right', va='center',fontsize=9)
for j, y in enumerate(y_right):
circle=plt.Circle((x_right,y),0.04,color='lightcoral',ec='black',zorder=3)
ax.add_patch(circle)
ax.text(x_right+0.05,y,f'$h_{j+1}$', ha='left',va='center',fontsize=9)
segments=[]
weight_values=[]
for i, y1 in enumerate(y_left):
for j, y2 in enumerate(y_right):
segments.append([(x_left,y1),(x_right,y2)])
weight_values.append(weights[i,j])
lc=LineCollection(segments, array=np.array(weight_values), cmap="coolwarm", linewidths=1.5, alpha=0.8, zorder=2)
ax.add_collection(lc)
cbar=plt.colorbar(lc, ax=ax,shrink=0.7)
cbar.set_label('weights', fontsize=10)
for i in range(min(3, n_input)):
for j in range(min(3, n_output)):
xm = (x_left + x_right) / 2
ym = (y_left[i] + y_right[j]) / 2
ax.text(xm, ym, f'{weights[i,j]:.2f}', fontsize=7, ha='center', va='center', bbox=dict(boxstyle='round,pad=0.2',facecolor='white',alpha=0.7))
plt.tight_layout()
plt.show()以上代码模拟了两层神经元,第一层有5个神经元,第二层有10个,第一层每个神经元都与第二层有连接,在代码中使用矩阵来表示神经元连接的权重数值,这个矩阵对应weights,它是一个5行10列的矩阵,weight01就代码第一层编号为0的神经元跟第二层编号为1的神经元连接之间的权重。
上面代码中要点在于两部分,一部分是计算参数a,对应代码为:
a = np.sqrt(6 / (n_input + n_output))
它根据第一层和第二层神经元的数量先计算初始化范围参数,第二部分在于在给定参数形成的范围里进行抽样,将数值初始化到连接:
weights = np.random.uniform(-a, a, size=(n_input, n_output))
其他代码主要有用于绘制图形,因此代码量虽然大,但是不是核心。上面代码运行后效果如下:
由于连接数量较大,我们在示例图里只选取了若干个把初始化后的数值标注出来。
第二种初始化方法教He初始化。该方法主要针对激活函数是ReLU的情况。通过前面一节可以看到ReLU激活函数在输入数值小于0时,它统一取值为0,这样就使得反向传播时,对该函数求导,如果求导的数值点小于0,那么求导结果就是0,这意味着我们无法对网络进行训练,因为求导结果为0的话,我们不知道怎么通过求导结果数值来修正当前链接的权重。
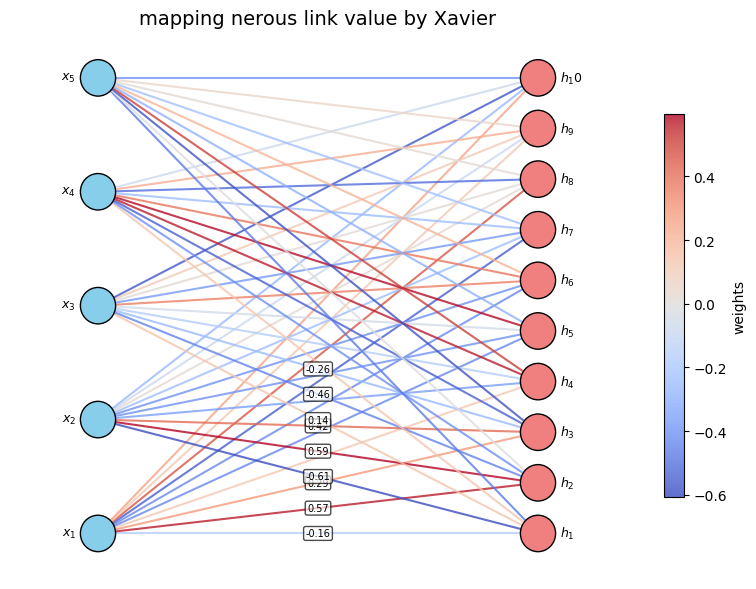
He方法是先构造方差为2/N_in的正太分别,然后在该分布里随机抽样来初始化连接权重,我们用一段python代码来模仿其算法:
py
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.collections import LineCollection
'''
模拟两层神经元,第一层5个神经元,第二层10个神经元,然后使用Xavier进行连接权重的初始化
'''
np.random.seed(42)
#第一层神经元个数
n_input = 5
#第二层神经元个数
n_output = 10
#构造参数a
# a = np.sqrt(6 / (n_input + n_output))
# #在范围[-a, a]内随机抽取,给每个连接权重进行初始化
# #size=(n_input,n_output)是一个行为n_input,列为n_output的矩阵,每个矩阵元素对应连接的权重
# weights = np.random.uniform(-a, a, size=(n_input, n_output))
# print("Xavier权重初始化区间[{:.4f}, {:.4f}]".format(-a, a))
# print("生成的权重矩阵(前几个值):\n", weights[:3, :3])
'''
He 初始化是构造方差为sqrt(2/N_in)的正太分布,然后进行随机抽样
'''
std=np.sqrt(2/n_input)
weights = np.random.normal(loc=0.0, scale=std,size=(n_input,n_output))
#以下绘制两层网络,第一层有5个神经元,第二层有10个,然后显示两层神经元连接在上面初始化后对应的数值
x_left=0.0 #第一层神经元所在坐标
x_right=1.0 #第二层神经元所在坐标
y_left=np.linspace(0, 1, n_input)
y_right=np.linspace(0, 1, n_output)
fig, ax = plt.subplots(figsize=(8,6))
ax.set_xlim(-0.2,1.2)
ax.set_ylim(-0.1,1.1)
ax.axis('off')
ax.set_title("mapping nerous link value by Xavier", fontsize=14)
#绘制原型节点表示神经元,
for i, y in enumerate(y_left):
circle = plt.Circle((x_left, y), 0.04, color='skyblue', ec='black', zorder=3)
ax.add_patch(circle)
ax.text(x_left-0.05, y, f'$x_{i+1}$', ha='right', va='center',fontsize=9)
for j, y in enumerate(y_right):
circle=plt.Circle((x_right,y),0.04,color='lightcoral',ec='black',zorder=3)
ax.add_patch(circle)
ax.text(x_right+0.05,y,f'$h_{j+1}$', ha='left',va='center',fontsize=9)
segments=[]
weight_values=[]
for i, y1 in enumerate(y_left):
for j, y2 in enumerate(y_right):
segments.append([(x_left,y1),(x_right,y2)])
weight_values.append(weights[i,j])
lc=LineCollection(segments, array=np.array(weight_values), cmap="coolwarm", linewidths=1.5, alpha=0.8, zorder=2)
ax.add_collection(lc)
cbar=plt.colorbar(lc, ax=ax,shrink=0.7)
cbar.set_label('weights', fontsize=10)
for i in range(min(3, n_input)):
for j in range(min(3, n_output)):
xm = (x_left + x_right) / 2
ym = (y_left[i] + y_right[j]) / 2
ax.text(xm, ym, f'{weights[i,j]:.2f}', fontsize=7, ha='center', va='center', bbox=dict(boxstyle='round,pad=0.2',facecolor='white',alpha=0.7))
plt.tight_layout()
plt.show()上面代码跟前面几乎相同,唯一不同的是如何初始化连接权重,唯一的改变如下:
py
std=np.sqrt(2/n_input)
weights = np.random.normal(loc=0.0, scale=std,size=(n_input,n_output))代码首先计算方差sqrt(2/n_input),然后创建相应的正太分别函数,将方差设置为给定值,然后权重的初始化就在给定的正太分布下随机采样即可,上面代码运行后结果如下: