温故知新
学C语言时,我们知道有全局变量,局部变量,自己申请的变量,字符串常量,它们分别处于内存的不同的区域,先来回顾一下。如下图所示(图片里画的地址是上边高地址下边低地址,反过来也行,但是推荐这样画),先来简单解释一下,代码都是由main函数开始从上往下执行的,所以所谓的正文代码其实指的是main函数的函数地址,在正文代码区内部还有一个字符串常量区。初始化数据指的是被初始化的全局变量,未初始化数据指的是未被初始化的全局变量,再往上就是堆区,它是由低地址向高地址生长的,然后就是共享区,这个暂时不用管,共享区上就是栈区(也叫堆栈),它是由高地址向低地址生长的,堆栈相对而生。对于栈区还要额外说一点,就是我们在里边开辟空间的时候,是从高地址向低地址按照变量所占的字节数开辟的,上一篇博客里提到过,就是&变量取到的地址是该变量所占的所有字节的地址中最小的那一个地址,又根据指针的知识,解引用的时候是会获取到该变量所有字节的数据,那也就是说我们获取栈上变量的数据的时候是从低地址向高地址获取的。
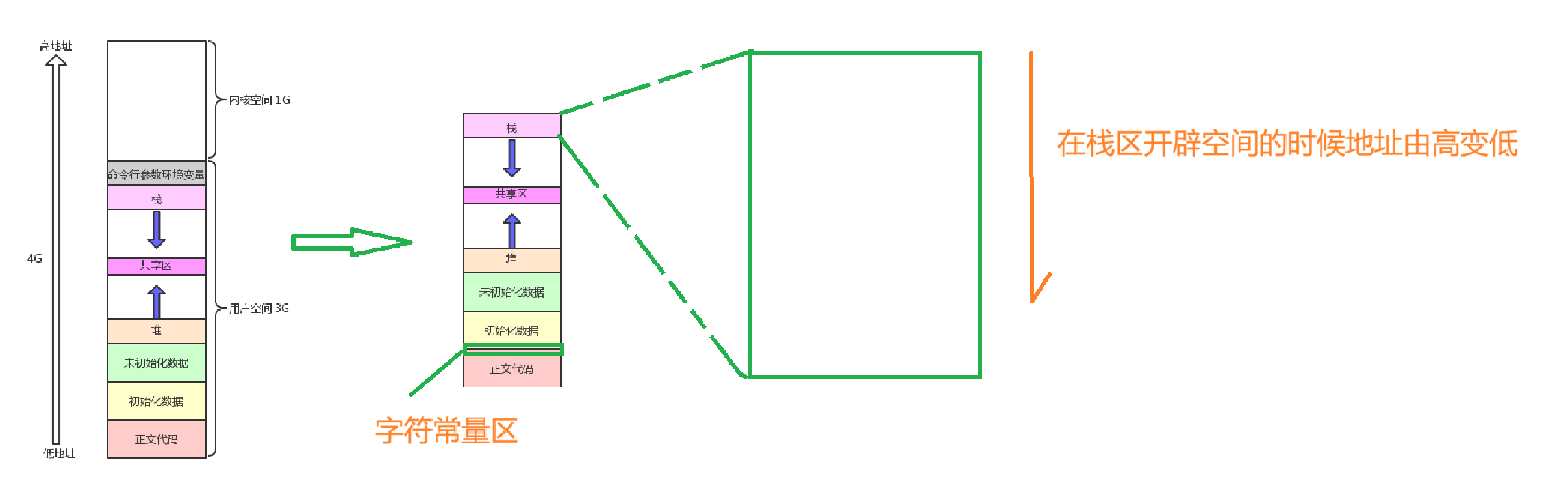
上述写的空间布局的所有内容不在内存里,而在进程地址空间里,或者叫虚拟地址空间,不叫程序地址空间(这个名字只是方便我们理解的)。
虚拟地址空间
先来看下图现象。之前在我的博客里提到过,父子进程共享代码和数据,其中对于数据来说只要不修改就可以共享,但是下边代码里我在子进程里修改了g_val的值,在打印的时候也确实发现g_val的值改了,父进程的没改,根据之前博客里写过的子进程可以继承父进程的全局变量以及进程之间的独立性和写时拷贝也确实是要这样,但是我们发现父子进程打印出来的g_val的地址是同一个,很显然这个地址就不是物理内存的真实地址了,因为如果是同一个物理内存,里边的值怎么会既是100又大于100呢?那这个地址是什么?答:虚拟地址。这里再补充一下,指针就是地址,那也就是说指针也不是物理地址。
cpp
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<sys/types.h>
4
5 int g_val = 100;
6
7 int main()
8 {
9 pid_t id = fork();
10 while(1)
11 {
12 if(id == 0)
13 {
14 printf("我是一个子进程PID: %d PPID: %d g_val: %d &g_val: %p\n", getpid(), getppid(), g_val, &g_val);
15 sleep(1);
16 g_val++;
17 }
18 else
19 {
20 printf("我是一个父进程PID: %d PPID: %d g_val: %d &g_val: %p\n", getpid(), getppid(), g_val, &g_val);
21 sleep(1);
22 }
23 }
24
25 return 0;
26 }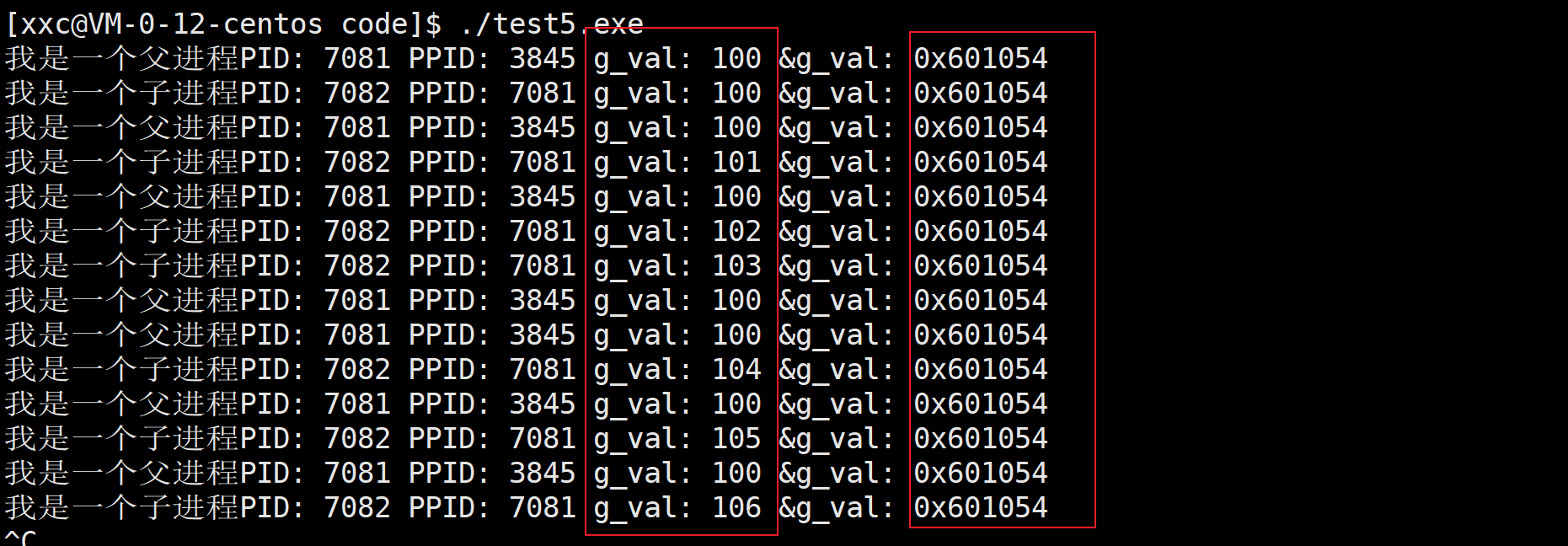
解释上边的现象
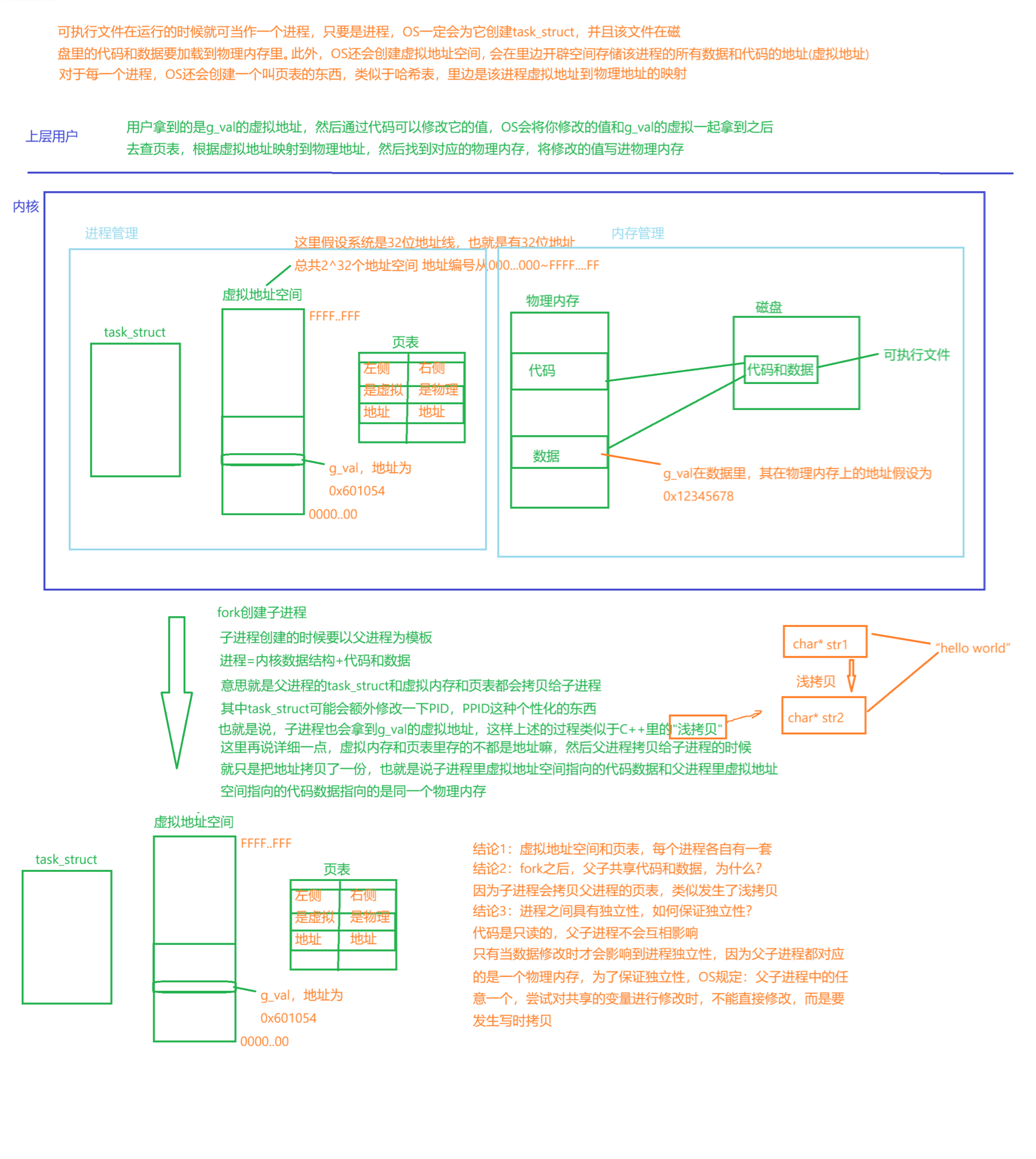
写时拷贝的意思当父子进程有一方要修改共享的数据时,OS会在物理内存当中,给子进程重新开辟一段空间,将父进程里的数据拷贝过来并给予新的地址,然后子进程里数据的虚拟内存不变,将页表里对应的物理内存地址部分改成新的地址,这样一来,子进程里对数据的修改就影响不到父进程了,这个就类似于C++里的深拷贝,但是用户看到父子进程里变量的地址都是一样的,因为用户看到的是虚拟地址,而父子进程里数据的虚拟地址是一样的,只是数据由虚拟地址所映射的物理地址不一样。
子问题:
1.物理地址我们能看到吗?
用户看不到,物理地址会被OS隐藏起来,因为直接访问物理内存比较危险,统一使用虚拟地址可以保护内存。
2.进程如何保证独立性呢?
进程的代码和数据全都是独立的,包括进程控制块(PCB)。
3.pid_t id = fork(),id会什么能接收两个返回值?
父子进程共享id变量的虚拟地址,但是底层映射到的是不同的物理内存地址。
什么叫虚拟地址空间?
讲一个故事吧,有一个大富翁,他有10亿资产,他在国外养了5个私生子,这几个私生子互相都以为自己就是大富翁唯一的子女,有一天,大富翁给每一个私生子都许诺,等将来我死了,我的全部资产就留给你,从旁观者视角来说,这是大富翁给每一个私生子画的饼,等饼画的越来越多的时候,今天许诺给你买套房子,明天许诺给你1000万.....渐渐的,大富翁想着我要将这些饼管理起来,那就先描述再组织吧。
每一个私生子相当于一个进程,彼此之前相互独立,而饼就相当于是虚拟地址空间,它需要被OS管理起来,也是先描述再组织,从C语言的视角,描述它无非就是一个结构体,叫做struct mm_struct{},怎么组织的之后说。值得一说的是,mm_struct也是我目前在博客里提到的第二个内核数据结构,注意进程=内核数据结构+代码数据,这个内核数据结构可不止只有task_struct。
所以到底什么叫虚拟地址空间,就是一个叫mm_struct的结构体,里边包含了许多表示区域划分的无符号整型变量表示每一个区域的开始和结束。
如何理解虚拟地址中的区域划分?
在本文开篇就说过,那些我们语法里学过的栈区,堆区,全局区,静态常量区....都是虚拟地址空间,那这些区域在里头怎么划分它们呢?再讲个故事,小学的时候你和你同桌公用一张桌子,但是你和你同桌互相看不惯,经常抢桌子用,有一天,你同桌小花突然说要不我们将桌子划分一下区域吧,你也同意了,于是你俩就把桌子一分为二,从今往后互不干预,这个过程的本质就是将桌子区域划分了,用计算机语言是怎么划分的呢?如下图,就是定义一个结构体,里边有四个变量,然后给结构体对象初始化的时候分别赋予这几个属性值,区域自然而然就划分出来了。
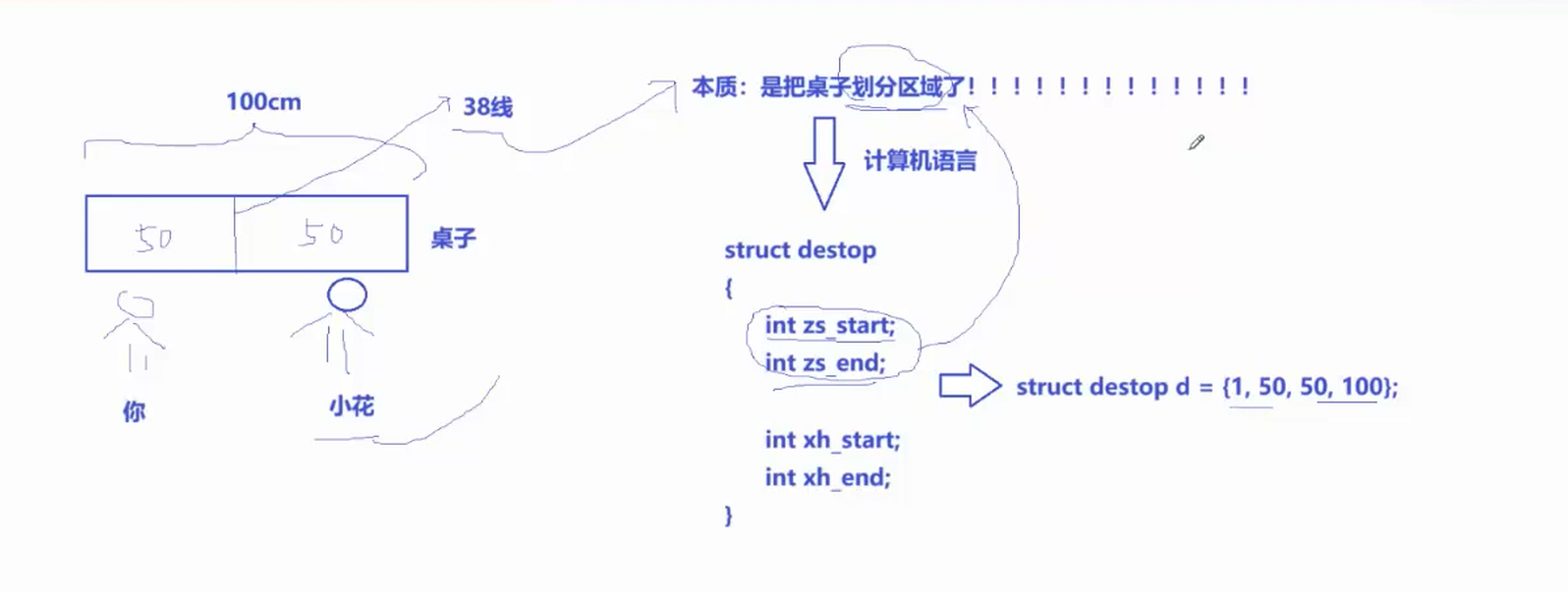
划分区域之后,区域内的任何一个位置,对应的人都可以直接使用,就比如上边那张桌子,我得到了1~50cm的区域,其实是得到了1,2,3......50这50个小空间,转换到计算机里,划分区域之后就相当于得到了一批有效地址。接下来来看看本文开篇说的那几个区域在mm_struct里(源码)是怎么划分的(下图所示),跟上边划分的桌子如出一辙。现在还有一个问题,上文说栈是由高地址向低地址生长的,堆是由低地址向高地址生长的,那意思不就是栈和堆的区域是变化的嘛,这个怎么实现呢?其实很简单,就是将表示对应区域开始和结束的变量值改改就行了。还有一个问题就是在虚拟地址空间中的那些表示每一个划分区域开始结束的变量不应该里边存的都是地址吗?为什么不是char*指针类型,而是无符号整数?原因就是在语言层面,指针可以去访问地址,但是对于OS来说,不关心这些,地址本质就是无符号整数,从0000....00~FFFF...FF。(注:mm_struct里有很多的属性,下图只是一个说白了区域划分的总纲,你从全局观的角度就可以说虚拟地址空间里各个区域是这样划分的,但其实还会更详细,本文最后会简单提一下)。

什么是页表?
可以将页表理解为是一个映射表,左边是虚拟地址,右边是由虚拟地址映射的物理地址,除了这两个部分,其实还有其他部分(标志位),比如说权限,有r,w,x,表示的是物理地址所指向数据的权限,这也就解释了为什么C语言里的常量字符串和代码是只读的,原因就是它们对应的物理地址在页表里的权限是r,用户上层使用它们的虚拟地址要做修改时候,OS就不会让用户修改,就是不让你的进程写入。除此之外,页表里还有一个部分叫是否存在,意思就是该物理地址所指向数据是否真的在内存里,1表示有,0表示没有,如果没有就说明该地址所指向的数据被挂起了,所以挂起跟task_struct,虚拟地址空间都没啥关系,挂起就是代码数据从物理地址挪到磁盘里去了。
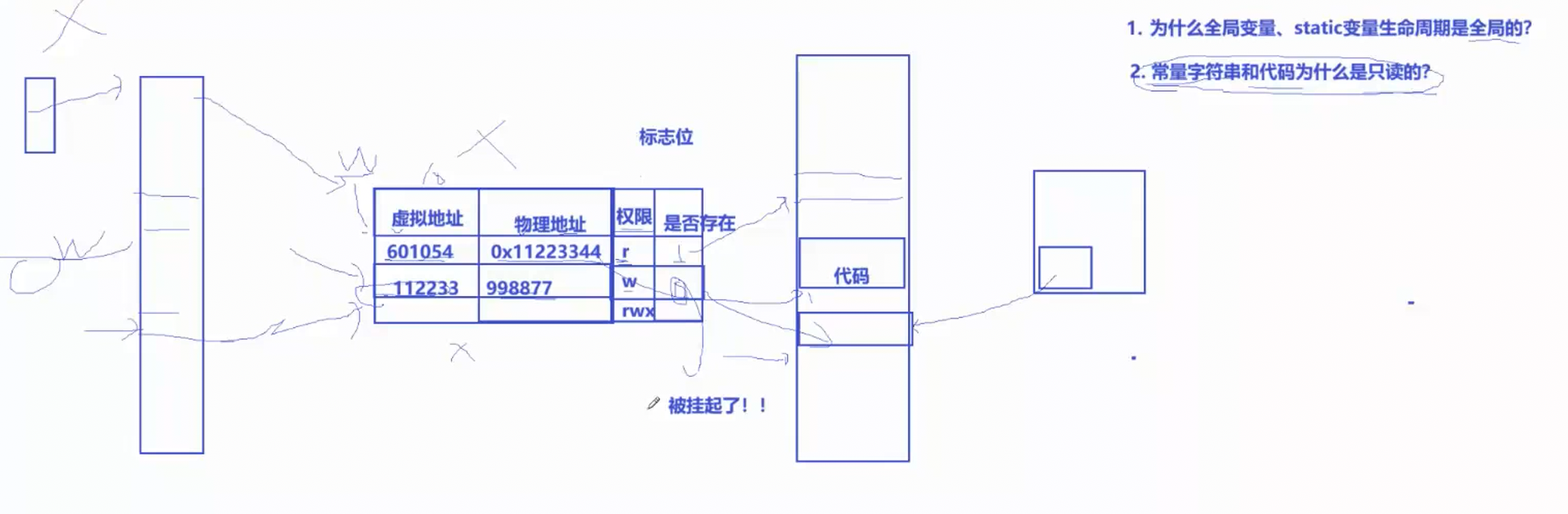
还有个问题,为什么全局变量、static变量生命周期是全局的?本质是生命周期随进程,进程只要还活着,其进程地址空间(虚拟地址空间)就会存在,那么里边的全局数据区(包括未初始化数据区,初始化数据区)和常量区就一直都会存在。
为什么要有虚拟地址空间?
1.控制进程的行为,拦截进程的非法行为(因),进而起到保护物理内存的效果(果)。在进程PCB和物理内存之间增加一层软件控制层(虚拟地址空间和页表),当进程有非法行为的时候,软件控制层会通过底层硬件触发错误,然后让OS介入进来拦截进程的非法操作。
2.有了虚拟地址空间和页表,原则上:将进程的内存空间布局,无序变有序。之前说过,程序文件里的代码和数据从磁盘加载到物理内存里是无序的,就是你不知道它到底加载到物理内存的哪个位置,但是虚拟地址空间里各个区域的排布是有序的,只不过可能不同进程对应的虚拟地址空间里各个区域的大小可能不一样,但是每个区域的相对位置肯定是一样的。通过页表的映射关系,可以将无序的变成有序的。同样一份代码和数据,从进程和内存的角度去看是不一样的。
3.让进程管理和内存管理解耦合,看上文"解释上边的现象"那一小节里的图片,属于进程的部分进程管,属于内存的部分内存管,互不影响,解耦了。所以在Linux系统中创建一个进程的时候会先创建内核数据结构(PCB,mm_struct,页表.....),然后再加载代码和数据。如果我不着急执行这个进程,可以当需要执行这个代码和访问数据的时候再进行加载数据吗?可以的,这是一种懒加载机制,当进程要用到代码和数据的时候我再加载给你,比如说进程运行5秒后才会用到,那么这个5秒空出的内存空间可以给别的进程用。像我们写C/C++代码的时候,经常会去malloc或者new,这个本质是在虚拟内存的堆区上申请,当你真正要用之前才给你动态申请物理内存,这叫做缺页中断引起内存二次申请(意思就是先在虚拟内存的堆区上申请了一块空间,然后将虚拟地址写入到页表里,但是其对应的物理内存地址先不写入,当要用到该空间时在再内存里申请,这也是属于空间的懒加载机制,这个过程是由OS自动完成的)。综上,进程运行起来的时候,其内核数据结构肯定会申请好,但是在磁盘里的代码和数是要用就申请物理内存,慢慢申请,不会一下子有的没的全部都加载到物理内存里,都这么搞,物理内存得多大才够用啊。
接下来来说最后一个跟虚拟地址空间有关的问题,区域划分的时候都是连续的,但是堆区不连续(因为动态开辟之后free掉了,那就可能free的是堆区中间某块位置),OS是怎么知道堆区哪里是哪里的?原因就是在mm_struct里有一个vm_area_struct,它是一个链表结点,在mm_struct里有许多这样的链表结点组成一个链表,通过链表结点里的指针就可以知道虚拟地址空间的每一个区域的划分,那其他区域是连续的,每个区域就对应一个vm_area_struct,里边的指针指向区域的开始和结束,堆区既然是不连续的,针对堆区里的每一个区域都会有一个vm_area_struct。上文说的区域划分的那张图里的是宏观划分,方便OS去找每一个区域的时候不用去便利链表。
补充:OS是怎么判断指针是否为野指针的?假如说int* p = malloc(100),申请了100个字节,在堆区上,OS会重新为这段区域申请一个vm_area_struct,其里边的指针会指向这段区域的开始和结尾,当这个指针越界的时候,也就代码指针的内容(地址)不属于vm_area_struct这段空间了,就会报野指针的错误。