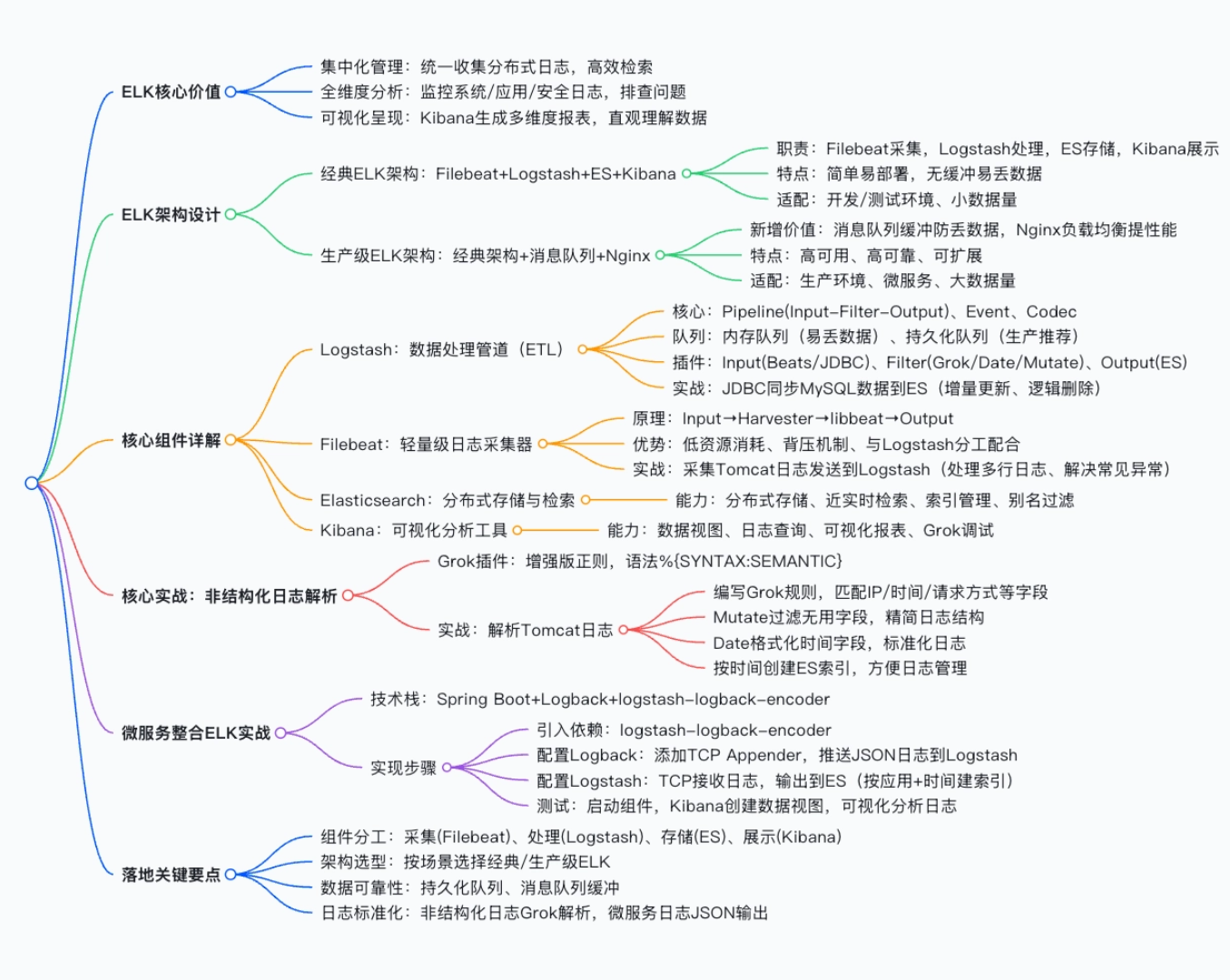
在微服务分布式架构下,日志数据呈现来源多、格式杂、体量剧增 的特点,传统单机日志查看方式已无法满足问题定位、系统监控、运维分析的需求。ELK(Elasticsearch、Logstash、Kibana)技术栈凭借分布式搜索、灵活的数据处理、可视化分析能力,成为微服务日志采集与分析的主流解决方案,再结合轻量级采集器 Filebeat,可构建高效、可扩展、高可用的日志管理体系。本文从 ELK 的核心价值出发,深入解析其架构设计、核心组件用法,并结合实战案例讲解微服务整合 ELK 的全流程,实现日志的集中化采集、处理、存储与分析。
一、为什么选择 ELK 做日志管理
在企业信息化建设中,日志来源覆盖服务器、操作系统、数据库、中间件、微服务应用、网络设备等全链路,传统日志管理的痛点日益凸显,而 ELK 的引入从根本上解决了这些问题,核心价值体现在三大方面:
1. 集中化管理与高效检索
ELK 构建集中式日志系统,将分布式节点的日志统一收集、存储,摆脱了逐台服务器查看日志的低效模式;Elasticsearch 提供强大的全文检索能力,支持多条件精准查询,可快速定位问题日志,大幅提升运维排障效率。
2. 全维度日志分析与系统监控
ELK 支持系统日志、应用日志、安全日志等多类型日志的管理与分析,能帮助开发和运维人员排查配置错误、掌握服务器软硬件状态;通过对日志的实时监控,可及时感知服务器负载、系统性能、网络安全等问题,做到事前预警、事中处理、事后追溯。
3. 直观的数据可视化呈现
Kibana 为 Elasticsearch 提供可视化 Web 界面,支持生成表格、折线图、柱状图、仪表盘等多维度可视化报表,将复杂的日志数据转化为直观的图形信息,降低日志分析的门槛,让非技术人员也能快速理解数据背后的业务与系统状态。
二、ELK 核心架构设计:从经典版到生产级
ELK 的架构并非单一形式,而是根据数据量、场景需求、可用性要求 分为经典 ELK 架构 和整合消息队列 + Nginx 的生产级 ELK 架构,二者各有适配场景,核心组件为 Filebeat、Logstash、Elasticsearch、Kibana。
2.1 经典 ELK 架构
核心组成
Filebeat + Logstash + Elasticsearch + Kibana(早期无 Filebeat,由 Logstash 直接采集日志,后因 Logstash 资源消耗问题引入轻量级的 Filebeat)。
各组件职责
- Filebeat:轻量级日志采集代理,部署在日志产生的客户端,低资源消耗,负责实时监控日志文件并采集数据;
- Logstash :数据处理管道,接收 Filebeat 采集的日志,进行过滤、转换、解析等处理,标准化日志格式;
- Elasticsearch:分布式搜索与分析引擎,负责日志数据的持久化存储,提供高效的检索和聚合能力;
- Kibana:可视化前端,对接 Elasticsearch,实现日志数据的可视化查询、分析与展示。
特点与适配场景
- 优点:架构简单、部署成本低、开发调试便捷;
- 缺点:无缓冲机制,Logstash 或 Elasticsearch 故障时易造成数据丢失;
- 适配场景:数据量较小的开发、测试环境,对日志可用性的要求较低。
2.2 整合消息队列 + Nginx 的生产级 ELK 架构
核心组成
在经典 ELK 架构基础上,新增消息队列(Redis/Kafka/RabbitMQ)和 Nginx,是企业生产环境的主流选型。
新增组件核心价值
- 消息队列 :作为日志数据的缓冲层,实现日志的削峰填谷;即使 Logstash/Elasticsearch 故障,日志数据会暂存于消息队列,故障恢复后继续消费,从根本上避免数据丢失;同时均衡网络传输,降低组件间的耦合;
- Nginx:高性能反向代理与负载均衡服务器,优化系统访问性能,提升 Kibana/Elasticsearch 的可用性,支持缓存、请求分发等能力。
特点与适配场景
- 优点:高可用、高可靠、扩展性强,支持大数据量处理,可动态调整各组件部署规模;
- 缺点:架构复杂度提升,运维成本有所增加;
- 适配场景:企业生产环境,尤其是微服务分布式架构、高并发、大数据量的日志处理场景。
三、ELK 核心组件详解:原理、安装与实战配置
3.1 数据处理管道:Logstash
Logstash 是免费开源的服务器端数据处理管道 ,核心定位为ETL 工具 / 数据采集处理引擎,支持多来源数据采集、实时转换、多目的地输出,是 ELK 中实现日志标准化的核心组件。
核心工作原理
Logstash 的核心是**Pipeline(管道)**,包含 Input(输入)- Filter(过滤,可选)- Output(输出)三个阶段,数据在内部以Event(Java Object)的形式流转,通过Codec(编解码) 实现原始数据与 Event 的相互转换。
- Input:从 Filebeat、文件、标准输入、TCP 等多来源采集数据;
- Filter:对采集的原始日志进行解析、过滤、字段增删改等处理(如 Grok 解析非结构化日志、Date 格式化时间、Mutate 过滤无用字段);
- Output:将处理后的标准化日志发送到 Elasticsearch、Kafka、控制台等目的地;
- Codec:在 Input/Output 阶段实现数据编解码,如 JSON、Line、Multiline(处理多行日志,如 Java 异常栈)。
关键特性:队列机制
Logstash 提供两种队列,决定数据可靠性:
- In Memory Queue(内存队列):默认模式,资源消耗低,但进程崩溃、机器宕机时会丢失数据;
- **Persistent Queue(持久化队列)**:将数据落地到磁盘,机器宕机数据不丢失,可替代简易消息队列的缓冲作用,生产环境推荐使用。
核心实战:MySQL 数据同步到 Elasticsearch
Logstash 可通过 JDBC Input Plugin 实现 MySQL 到 ES 的数据同步,支持增量更新、数据一致性保障,适用于将业务数据同步到 ES 做全文检索的场景,核心实现步骤:
- 拷贝 MySQL JDBC 驱动到 Logstash 指定目录;
- 编写配置文件,通过
tracking_column(如last_updated)记录同步位置,实现增量更新; - 配置 Elasticsearch 输出,指定
document_id保证数据更新幂等; - 对 MySQL 表增加
is_deleted逻辑删除字段,通过 ES 别名(Alias)过滤已删除数据,保证查询一致性。
常用插件
- Input 插件:Stdin、File、JDBC、Beats(接收 Filebeat 数据)、TCP;
- Output 插件:Elasticsearch、Stdout、Kafka、Email;
- Filter 插件:Grok(解析非结构化日志)、Date(时间格式化)、Mutate(字段处理);
- Codec 插件:Line、Multiline、JSON、Rubydebug。
3.2 轻量级日志采集器:Filebeat
Filebeat 是 Beats 生态下的轻量级日志采集工具 ,基于 Golang 开发,相比基于 JVM 运行的 Logstash,具有资源消耗低、启动快、轻量高效 的特点,是 ELK 架构中日志采集的首选组件,部署在所有日志产生的客户端节点。
核心工作原理
- Filebeat 启动 Input 监控指定路径的日志文件;
- 为每个日志文件启动**Harvester(收割机)**,逐行读取日志数据;
- 数据传递到 libbeat 进行聚合处理;
- 通过 Output 将数据发送到 Logstash/Elasticsearch/ 消息队列。
Filebeat 与 Logstash 的配合优势
- 背压机制:当 Logstash/Elasticsearch 负载过高时,会通知 Filebeat 减慢读取速度,拥堵解决后恢复,避免数据积压;
- 分工明确 :Filebeat 专注于轻量采集 ,Logstash 专注于复杂数据处理,二者配合实现 "采集 - 处理" 的解耦,提升系统整体性能。
核心实战:采集 Tomcat 日志并发送到 Logstash
- 编写 Filebeat 配置文件,配置日志路径,通过
multiline处理 Tomcat 多行日志,指定输出到 Logstash 的 Beats 端口(默认 5044); - 解决配置文件权限、端口连接等常见异常(如修改配置文件权限为 644,确保 Logstash 已启动并监听指定端口);
- 配置 Logstash 的 Beats Input 插件,接收 Filebeat 数据,通过 Stdout 或 Elasticsearch 输出。
3.3 分布式存储与检索:Elasticsearch
Elasticsearch 是基于 Lucene 的分布式搜索和分析引擎 ,是 ELK 的数据存储核心,为日志数据提供:
- 分布式存储:支持水平扩展,应对海量日志的存储需求;
- 近实时检索:秒级响应日志查询,支持全文检索、多条件过滤、聚合分析;
- 索引管理:支持按时间、业务创建索引,通过 ** 别名(Alias)** 实现索引的透明化访问,过滤无效数据(如逻辑删除的记录)。
3.4 可视化分析:Kibana
Kibana 是 Elasticsearch 的可视化前端工具,提供 Web 界面,核心能力包括:
- 数据视图创建:对接 Elasticsearch 的索引,创建可视化分析的基础数据视图;
- 日志查询与过滤:支持可视化的条件查询,快速定位指定日志(如 HTTP 状态为 403/500 的 Tomcat 访问日志);
- 可视化报表制作:生成折线图、柱状图、饼图、仪表盘等,实现系统性能、业务访问量、异常日志等维度的分析;
- Grok 调试:提供 Grok 模式调试工具,方便开发人员编写非结构化日志的解析规则。
四、核心实战:Logstash 解析非结构化日志
微服务场景下的日志(如 Tomcat 访问日志、Nginx 日志)多为非结构化文本 ,无法直接进行精准查询和分析,Logstash 的 Grok 插件 是解析非结构化日志的核心工具,结合 Mutate、Date 插件可实现日志的结构化、标准化,以 Tomcat 访问日志为例,核心步骤:
4.1 Grok 插件核心原理
Grok 是增强版正则表达式 ,提供 120 + 内置匹配模式,语法为 %{SYNTAX:SEMANTIC},其中 SYNTAX 为内置模式(如 IP、NUMBER、HTTPDATE),SEMANTIC 为匹配后的字段名(如 ip、status、date),支持将匹配结果转换为 int/float 类型。
4.2 解析 Tomcat 访问日志
- 分析 Tomcat 日志格式:
192.168.65.103 - - [23/Jun/2022:22:37:23 +0800] "GET /docs/images/docs-stylesheet.css HTTP/1.1" 200 5780; - 编写 Grok 匹配规则:
%{IP:ip} - - \\[%{HTTPDATE:date}\\] \\"%{WORD:method} %{PATH:uri} %{DATA:protocol}\\" %{INT:status:int} %{INT:length:int}; - 配置 Mutate 插件,过滤掉
message、tags等无用字段,精简日志结构; - 配置 Date 插件,将
date字段格式化为标准的 "年月日 时分秒" 格式,指定目标字段避免覆盖默认的@timestamp; - 配置 Elasticsearch 输出,按时间创建索引(如
tomcat_web_log_%{+YYYY-MM}),方便日志的按时间管理。
五、落地实战:微服务整合 ELK 实现日志全链路采集
以 Spring Boot 微服务为例,整合 ELK 实现日志的采集 - 处理 - 存储 - 分析 全流程,核心基于 Logback+logstash-logback-encoder 实现日志的结构化输出,对接 Logstash 完成后续处理。
5.1 实现思路
- Spring Boot 应用通过 Logback 框架记录日志,借助 logstash-logback-encoder 将日志以 JSON 格式发送到 Logstash;
- Logstash 接收 TCP 端口的 JSON 日志,进行轻量处理后发送到 Elasticsearch;
- Elasticsearch 存储结构化日志,创建索引实现日志分类;
- Kibana 对接 Elasticsearch,创建数据视图,实现日志的可视化查询与分析。
5.2 具体实现步骤
1. 引入依赖
在 Spring Boot 项目中引入 logstash-logback-encoder 依赖,实现日志向 Logstash 的 TCP 推送:
xml
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>6.3</version> </dependency>
2. 配置 Logback,推送日志到 Logstash
修改 logback-spring.xml,添加 Logstash TCP Appender,指定 Logstash 的 IP 和端口,添加自定义字段(如 appname)实现按应用区分日志:
xml
<appender name="logstash" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <destination>192.168.65.211:4560</destination> <encoder class="net.logstash.logback.encoder.LogstashEncoder" > <customFields>{"appname": "elk-demo"}</customFields> </encoder> </appender> <root level="INFO"> <appender-ref ref="STDOUT" /> <appender-ref ref="logstash" /> </root>
3. 配置 Logstash,接收并处理日志
编写 Logstash 配置文件,通过 TCP Input 接收 Spring Boot 应用的 JSON 日志,直接输出到 Elasticsearch(无需复杂过滤,因日志已结构化),按应用名 + 时间创建索引:
conf
input { tcp { host => "0.0.0.0" port => "4560" mode => "server" codec => json_lines } } output { stdout { codec => rubydebug } elasticsearch { hosts => ["127.0.0.1:9200"] index => "%{[appname]}-%{+YYYY.MM.dd}" } }
4. 启动组件并测试
- 依次启动 Elasticsearch、Kibana、Logstash;
- 启动 Spring Boot 应用,调用接口产生日志;
- 查看 Logstash 控制台,确认日志正常接收;
- 在 Kibana 中创建
elk-demo-*的数据视图,实现日志的可视化查询、过滤与分析。
六、总结
ELK 技术栈是微服务日志采集与分析的一站式解决方案,通过 Filebeat 实现轻量、分布式的日志采集,Logstash 实现日志的标准化处理,Elasticsearch 实现海量日志的存储与高效检索,Kibana 实现直观的可视化分析,再结合消息队列、Nginx 可构建生产级的高可用架构。
在实际落地中,核心要点在于组件的合理分工 (Filebeat 采集、Logstash 处理、ES 存储、Kibana 展示)、非结构化日志的结构化解析 (Grok 插件的灵活使用)、微服务日志的标准化输出 (Logback+logstash-logback-encoder),同时需根据场景选择合适的架构(开发环境用经典 ELK,生产环境用整合消息队列的 ELK),并做好数据可靠性保障(如 Logstash 持久化队列、消息队列缓冲)。
ELK 的价值不仅在于解决日志的 "查看问题",更在于通过对日志数据的分析与挖掘,实现系统性能监控、业务趋势分析、故障快速定位,为微服务架构的稳定性、可观测性提供核心支撑。