👨⚕️ 主页: gis分享者
👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅!
👨⚕️ 收录于专栏:AI大模型原理和应用面试题

文章目录
- 一、🍀Skills
-
- [1.1 ☘️概念](#1.1 ☘️概念)
- [1.2 ☘️作用](#1.2 ☘️作用)
- 二、🍀扩展知识
-
- [2.1 ☘️Skills 出现之前的痛点](#2.1 ☘️Skills 出现之前的痛点)
- [2.2 ☘️Skills 的技术实现原理](#2.2 ☘️Skills 的技术实现原理)
- [2.3 ☘️Skills 在主流 AI 编程工具中的应用](#2.3 ☘️Skills 在主流 AI 编程工具中的应用)
- [2.4 ☘️Skills 的设计原则](#2.4 ☘️Skills 的设计原则)
- 三、🍀追问
一、🍀Skills
1.1 ☘️概念
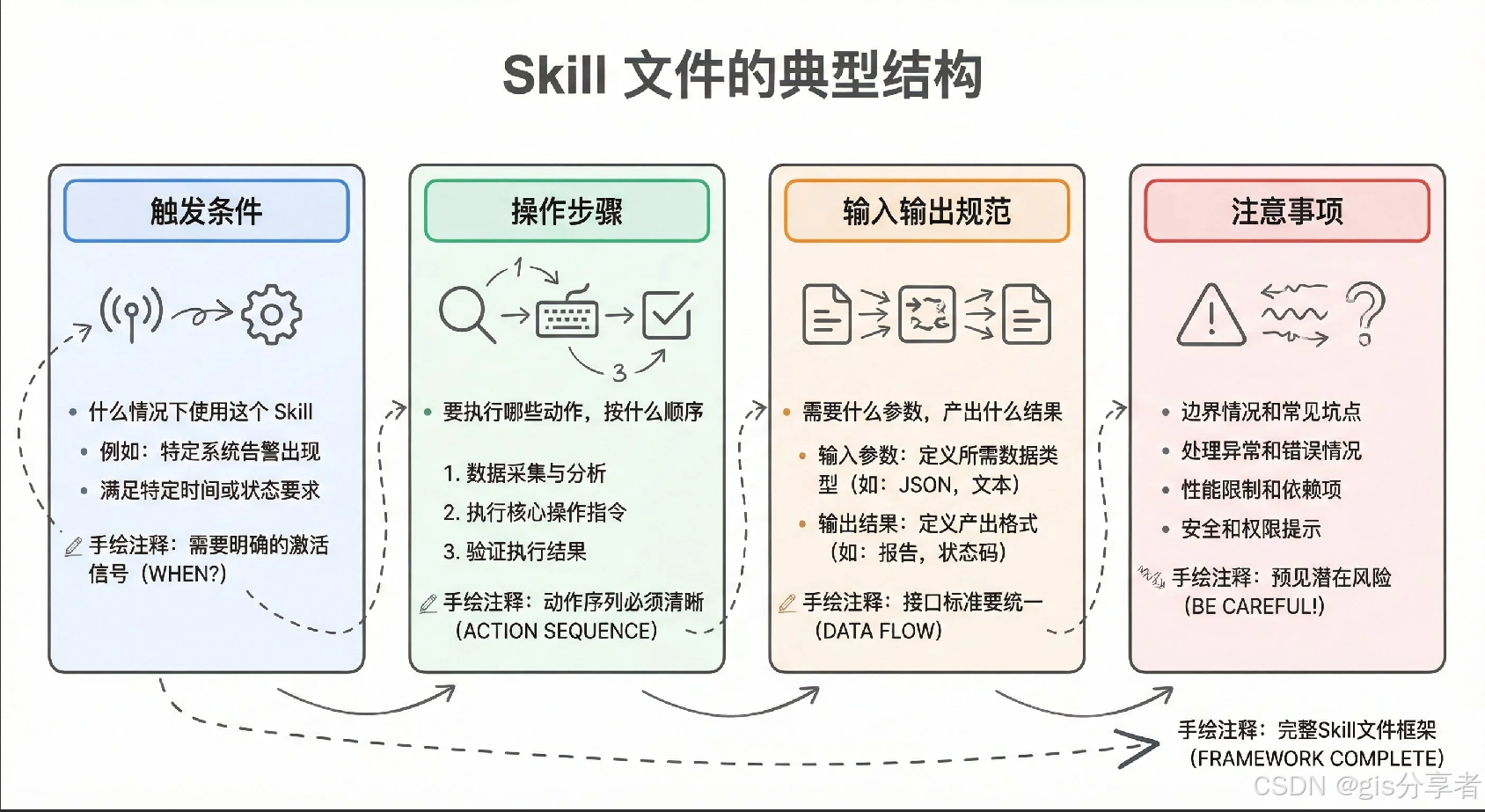
Skills 就是给 AI Agent 写的操作手册,本质上是一份结构化的指令文件。当 Agent 碰到某类任务,就去读对应的 Skill,按里面的步骤一步步执行,不用你每次从头教它。
比如你想让 AI 帮你创建 Cursor 的自定义规则文件,规则文件放哪个目录、格式长啥样、有哪些字段,这些东西写一个 create-rule 的 Skill 就搞定了。Agent 碰到相关任务自动加载,不需要你每次重复沟通。
1.2 ☘️作用
1)把某个领域的专业知识、操作步骤、注意事项打包成一个文件,Agent 读了就能干活,不需要每次重复教
2)同一个任务不管执行多少次,Agent 都按 Skill 定义的流程走,输出质量可预期
3)通过编写不同的 Skills,让一个通用 Agent 具备各种垂直领域的专业能力,不需要重新训练模型
一个典型的 Skill 文件通常是 Markdown 格式,包含触发条件、操作步骤、输入输出规范、常见坑点这几个核心部分。
二、🍀扩展知识
2.1 ☘️Skills 出现之前的痛点
没有 Skills 的时候,你每次让 Agent 干一件稍微有点规范要求的活儿,都得从头把要求说一遍。
比如你要求"代码文件头部必须加上版权声明、函数命名用驼峰、异常处理要统一格式",你说了一次 Agent 记住了,下次新对话又忘了。
更要命的是,不同的人给 Agent 的指令不一样,同一个团队里 10 个人可能写出 10 种风格的代码来。
Skills 就是来解决这个问题的:把这些反复出现的指令和规范固化成文件,让 Agent 每次都能自动读取,保证行为一致。
2.2 ☘️Skills 的技术实现原理
Skills 的底层原理其实不复杂,本质上就是一种 Prompt 注入机制。
在 Agent 执行任务之前,系统根据任务类型匹配合适的 Skill 文件,把文件内容注入到 LLM 的上下文中,相当于对话开始前先给 AI "补课"。
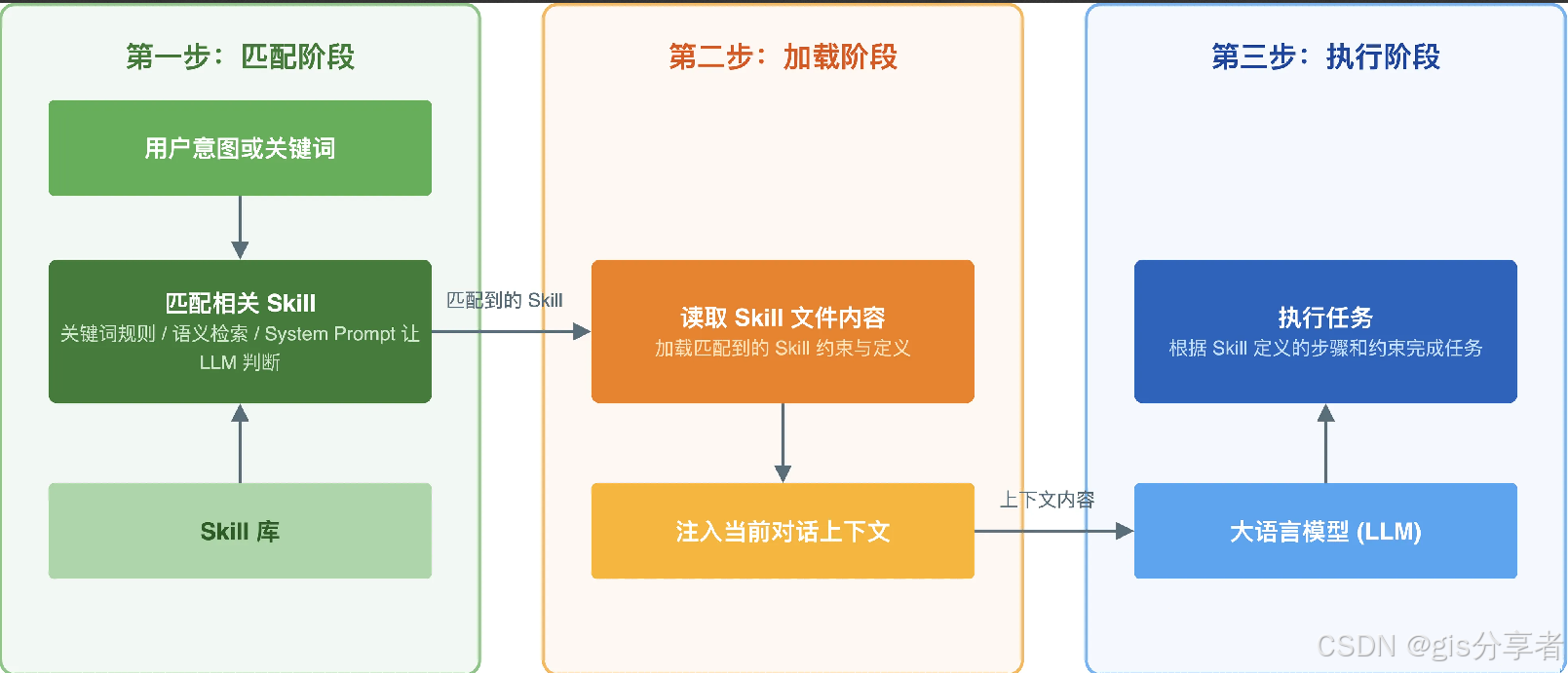
整个过程分三步走:
- 首先是匹配阶段,系统根据用户意图或关键词,从 Skill 库中找到相关的 Skill,匹配方式可以是关键词规则、语义检索,也可以直接在
Agent 的 System Prompt 里列出所有可用 Skill 让 LLM 自己判断。 - 然后是加载阶段,读取匹配到的 Skill 文件内容,注入到当前对话的上下文中。
- 最后是执行阶段,LLM 根据 Skill 中定义的步骤和约束来完成任务。
这跟 RAG 有点像,但关键区别在于:RAG 检索的是知识片段,目的是"回答问题";Skill 加载的是操作指令,目的是"指导行动"。
2.3 ☘️Skills 在主流 AI 编程工具中的应用
目前 Skills 在 AI 编程助手领域已经有比较成熟的落地:
| 工具 | Skills 实现形式 | 存放位置 | 触发方式 |
|---|---|---|---|
| Cursor | SKILL.md 文件 | .cursor/skills-cursor/ | Agent 根据任务自动匹配,或用户引用 |
| Claude Code | CLAUDE.md | 项目根目录或 ~/.claude/ | 每次对话自动加载 |
| GitHub Copilot | .github/copilot-instructions.md | .github/ 目录 | 自动注入上下文 |
| Windsurf | Rules 文件 | .windsurfrules | 自动加载 |
叫法不一样,核心思路都是一个:通过本地文件来持久化地影响 AI 的行为模式。
2.4 ☘️Skills 的设计原则
写一个好的 Skill 跟写一个好的 Prompt 一样需要技巧:
1)一个 Skill 只解决一类问题,别把所有东西塞到一个文件里。"创建规则文件"和"修改编辑器配置"应该是两个独立的 Skill
2)操作流程要清晰,每一步做什么、用什么工具都写明白,最好是编号列表
3)明确定义输入参数和输出格式,减少歧义
4)给出正确和错误的示例,比纯文字描述有效得多
5)Skill 不是写完就不管了,要根据实际使用效果不断迭代优化
三、🍀追问
提问:Skills 和 RAG 都是往上下文里塞内容,具体区别在哪?
回答:RAG 检索的是知识片段,目的是让模型基于这些信息回答问题,属于"给 AI 喂资料"。Skills 加载的是操作指令,目的是让模型按照固定流程执行任务,属于"给 AI 定规矩"。RAG 的检索粒度通常是段落级别,一次可能检索 5-10 个相关文档片段;Skills 通常是整份文件加载,一次加载 1-2 个 Skill。另外 RAG 需要向量数据库做语义检索,Skills 一般靠简单的关键词匹配或者让 LLM 自己选就够了。
提问:如果 Skill 文件内容特别长,塞进上下文会不会有问题?
回答:肯定有问题。LLM 的上下文窗口是有限的,比如 Claude 的上下文是 200K token,一个 Skill 文件如果写了好几千 token,再加上用户的对话历史和系统提示词,很容易把上下文撑满。一般解决办法有两个:一是控制 Skill 文件的长度,把非核心内容拆成子文件按需加载;二是做分层加载,先加载一个精简版的摘要,Agent 判断需要更多细节时再加载完整内容。Cursor 就是这么干的,鼓励你把大 Skill 拆分成多个小文件。
提问:怎么判断一个任务应该用 Skill 来解决还是用 Tool 来解决?
回答:看这个任务需不需要跟外部系统打交道。如果只是需要 AI 按照特定流程去思考和组织输出,比如生成代码要遵循某种规范、创建文件要按照特定模板,用 Skill 就够了。如果需要查数据库、调 API、操作文件系统这些实际的外部操作,那就得上 Tool。简单说,Skill 管的是"怎么想",Tool 管的是"怎么做"。两者也经常配合着用,Skill 里面会写明在某一步调用哪个 Tool。