Kun-peng(鲲鹏)实现可扩展且准确的泛域宏基因组分类

研究论文
● 期刊:Briefings in Bioinformatics(IF:7.7)
● DOI:https://doi.org/10.1093/bib/bbag119
●原文链接: https://academic.oup.com/bib/article/27/2/bbag119/8525000
●2026年3月16日,浙江大学蒋超团队在Briefings in Bioinformatics发表了题为" Kun-peng enables scalable and accurate pan-domain metagenomic classification "研究成果,推出新一代宏基因组分类软件 Kun-peng(鲲鹏)。其名取自中国神话中"鲲化为鹏"的意象,寓意兼具宏阔视野与迅捷之势,象征工具在不同计算环境与复杂数据场景中的适应、转化与扩展能力。面向跨域宏基因组分析中长期存在的高内存、高成本和高门槛难题,Kun-peng (鲲鹏)以极低内存、高速度、高灵敏度和低假阳性的综合优势,实现了性能与可及性的同步提升,为复杂环境样本和超大参考数据库的高效解析提供了新的技术路径,也推动超大规模泛域宏基因组分析从少数高性能平台走向个人电脑和更广泛实验室场景中的实际应用。
● 第一作者:陈琼、张博良
● 通讯作者:蒋超(jiang_chao@zju.edu.cn)
● 发表日期:2026-3-16
● 主要单位:
浙江大学生命科学研究院(Life Sciences Institute, Zhejiang University, Hangzhou, Zhejiang 310030, China)
摘要
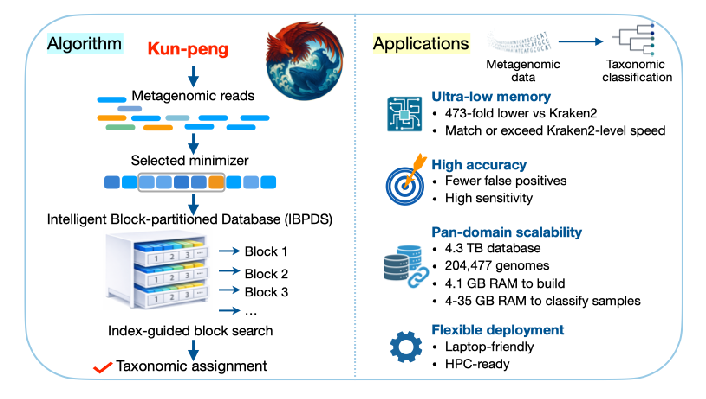
随着参考基因组数量持续增长,构建和检索泛域宏基因组参考数据库所需的内存与运行时间,正成为限制全面分类分析的关键瓶颈。研究团队提出 Kun-peng(鲲鹏),这是一种由智能分块数据库结构和优化检索策略驱动的分类器,可实现超大规模、内存高效的泛域宏基因组分析。基于 CAMI II 基准数据,Kun-peng(鲲鹏)在数据库构建与查询过程中可将内存占用最多降低 24 倍,并将样本分类速度相较 Kraken2 最多提升 4.73 倍。与此同时,它在保持高灵敏度的前提下,实现了具有竞争力的准确性,并且假阳性少于 Kraken2、Centrifuger,甚至优于 KrakenUniq。在针对 586 个真实宏基因组样本(覆盖空气、水体、土壤和人体相关环境)的评估中,作者使用了一个由 204,477 个基因组组成、总序列量达 4.3 TB 的泛域数据库;而 Kun-peng(鲲鹏)构建该数据库时的峰值内存仅为 4.1 GB。对单个样本的分析耗时为 0.2--11.2 分钟,峰值内存为 4.0--35.4 GB,相比 Kraken2 相当于内存占用降低了 54--473 倍。与 Sylph 相比,Kun-peng(鲲鹏)最高可实现 46 倍加速,同时仅需其约 1/21 的内存。Kun-peng(鲲鹏)能够注释 69.8%--94.3% 的 reads,相比使用 62,026 个基因组的标准 Kraken2 数据库,注释率提升约 20%--60%。总体而言,Kun-peng(鲲鹏)有效打破了泛域数据库构建与分类长期受制于内存的难题,为复杂环境、生态和暴露组样本的大规模宏基因组注释提供了快速、可扩展且更普适的解决框架。
关键点
● Kun-peng(鲲鹏)在运行时间与 Kraken2 相当或更快的同时,可将峰值内存最高降低 473 倍。
● Kun-peng(鲲鹏)在 CAMI II 基准测试中兼具较高准确度、较少假阳性和持续稳定的高灵敏度。
● Kun-peng(鲲鹏)能够实际使用超大泛域参考数据库(如4.3 TB;204,477 个基因组),在复杂环境样本中实现约 70%--94% 的 reads 分类率。
● 双模式架构使其既适合个人电脑上的低内存分析,也适合高性能平台上的高速处理。
引言
宏基因组学能够在不依赖培养的前提下,对混合微生物群落进行整体解析,已成为研究环境与宿主相关体系中微生物多样性、生态结构及功能的重要手段。对这类复杂样本进行准确的分类学分析,越来越依赖于泛域参考数据库:整合细菌、古菌、病毒、真菌以及其他真核生物的高质量基因组,从而提供更广的分类覆盖范围和跨域分析能力。
现有宏基因组分类工具大体可分为三类:基于比对的方法、基于标记基因的方法和基于 k-mer 的方法。BLAST 等比对型方法灵敏度高,但计算资源需求较大;MetaPhlAn4 等标记基因方法占用内存较小、分类较精确,但数据库主要覆盖细菌、古菌和部分单细胞真核生物,难以支撑真正的泛域分析。相比之下,k-mer 方法在速度、可扩展性与资源消耗之间取得了较好平衡,因此得到广泛关注。
不过,随着参考数据库不断增长,k-mer 方法也暴露出新的资源瓶颈。KrakenUniq 通过内存映射和低内存分块模式降低 RAM 占用,但速度明显受限;Kraken2 通过 minimizer 和 spaced seed 等策略提升效率,却依然需要与数据库规模相当甚至更高的内存。Centrifuge / Centrifuger、Sylph 等工具则分别在索引结构、压缩和统计建模方面做出改进,但常常需要在速度、准确性和灵敏度之间重新权衡。尤其是在环境样本、非人体样本和暴露组研究中,样本组成复杂、跨域性强,传统工具在超大数据库条件下面临明显挑战。
为解决上述问题,作者提出了基于 Rust 开发的 Kun-peng(鲲鹏)。该工具沿用了 Kraken2 以 minimizer 与 LCA(最低共同祖先)为核心的计算框架,但在数据库组织形式和检索策略上进行了关键创新。其最核心的改进,是引入了智能分块数据库结构(intelligent block-partitioned database structure, IBPDS),使数据库能够按块按需加载,在显著降低内存占用的同时维持较高查询速度。作者还通过改进滑动窗口策略减少假阳性,并借助并行处理进一步提升速度。Kun-peng(鲲鹏)提供两种运行模式:内存高效模式 Kun-peng-M,以及高速模式 Kun-peng-F,从而兼顾资源受限平台与高内存平台的不同需求。值得注意的是,Kun-peng(鲲鹏)兼容 Kraken2 数据库及 Bracken 丰度估计流程,便于用户迁移。
结果
Kun-peng(鲲鹏)的架构与执行框架
Kun-peng(鲲鹏)使用 Rust 编写,整体沿用 Kraken2 的 k-mer 分类逻辑,但在可扩展性与内存效率上做了大量改进 (图1)。默认参数与 Kraken2 保持一致,即 k = 35、ℓ = 31、s = 7,以兼顾准确性、速度和资源消耗。工具首先通过滑动窗口从 35 bp 的 k-mer 中提取 31 bp 的 minimizer;与 Kraken2 不同的是,Kun-peng(鲲鹏)只保留唯一 minimizer,从源头上减少重复计数和潜在假阳性。随后,对 minimizer 施加 spaced seed 掩码,以增强对测序误差或局部突变的容忍度;掩码后的 minimizer 会被哈希为紧凑数值编码,用于确定其所在数据库块及哈希表中的搜索起始位置,若发生冲突再通过线性探测解决。
Kun-peng(鲲鹏)的核心是 IBPDS。该结构将完整哈希表划分为一系列有序索引块(1 到 n),从而支持数据库按块加载、按需检索。基于这一设计,作者构建了双模式执行框架:Kun-peng-M 面向资源受限场景,侧重降低峰值内存;Kun-peng-F 面向高内存平台,追求最高速度。
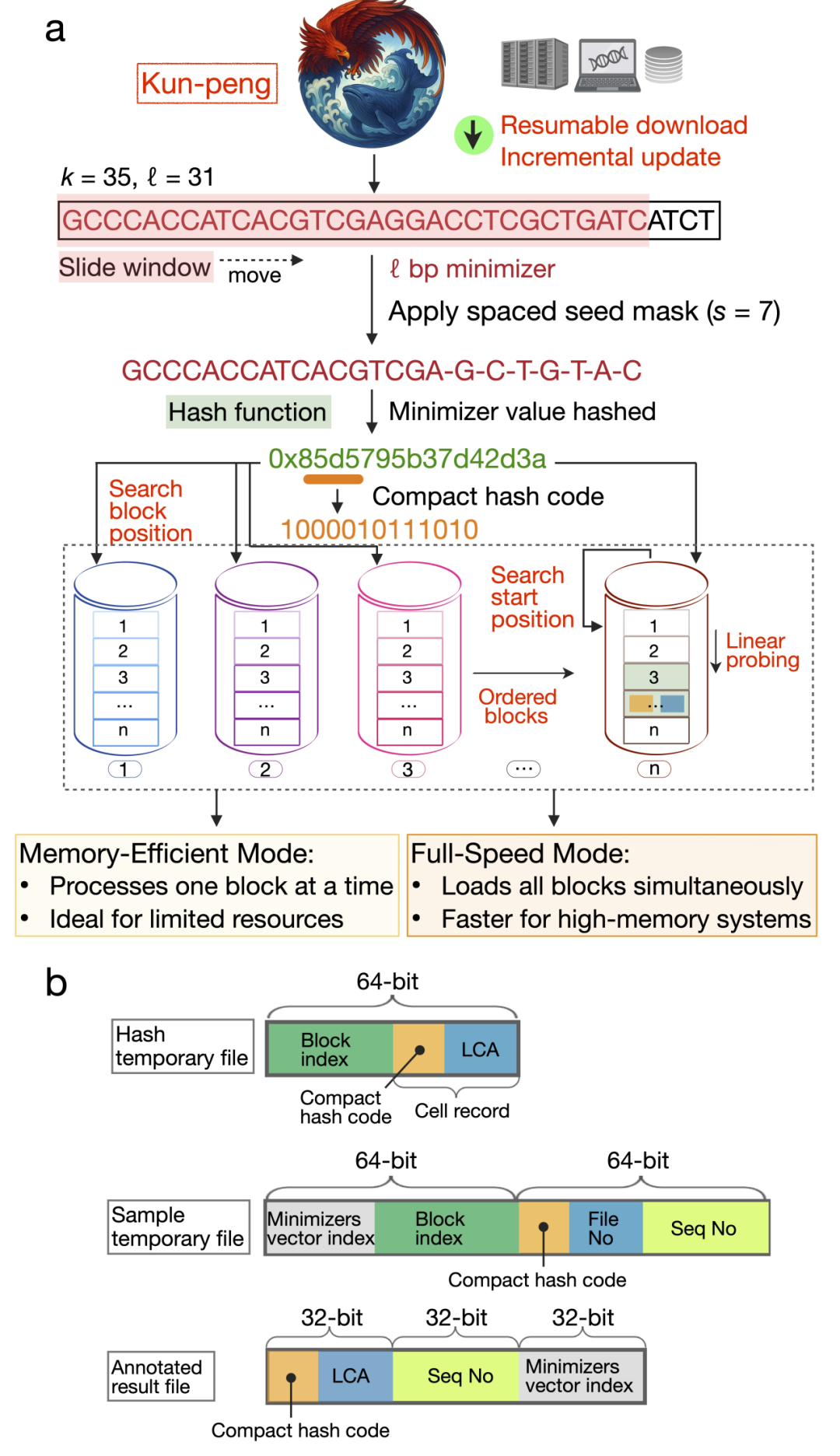
图1 | Kun-peng(鲲鹏)的数据获取、minimizer 生成与 IBPDS 整体流程示意图
Kun-peng(鲲鹏)在 CAMI II 模拟宏基因组中的表现
在 CAMI II 模拟数据上,作者将 Kun-peng(鲲鹏)与 6 种代表性分类工具进行基准比较。所使用的五类数据集在群落结构上差异明显(图2a),其中海洋样本具有最高 Shannon 多样性与均匀度,而 strain-madness 数据集则具有最高的最大属水平基因组计数(maximum genus-level genome count,MGLGC),代表最具挑战性的同属多菌株混合场景。
与预期一致,所有工具在属水平的表现都优于种水平(图2b-c)。但无论在属水平还是种水平,Kun-peng(鲲鹏)都表现出较高的灵敏度、较好的 AUPRC,以及与真实丰度高度一致的 abundance concordance(1 -- Bray--Curtis)。更重要的是,Kun-peng(鲲鹏)在多种数据类型中均表现出低于 Kraken2、KrakenUniq 和 Centrifuger 的假阳性水平。MetaPhlAn4 与 mOTUs 作为标记基因方法,整体假阳性更低,但代价是灵敏度下降。Sylph 虽因激进的 k-mer 子采样而在某些场景下假阳性较少,但支持证据也随之减少,灵敏度容易受损。相比之下,Kun-peng(鲲鹏)在灵敏度与精确度之间取得了更均衡的折中。
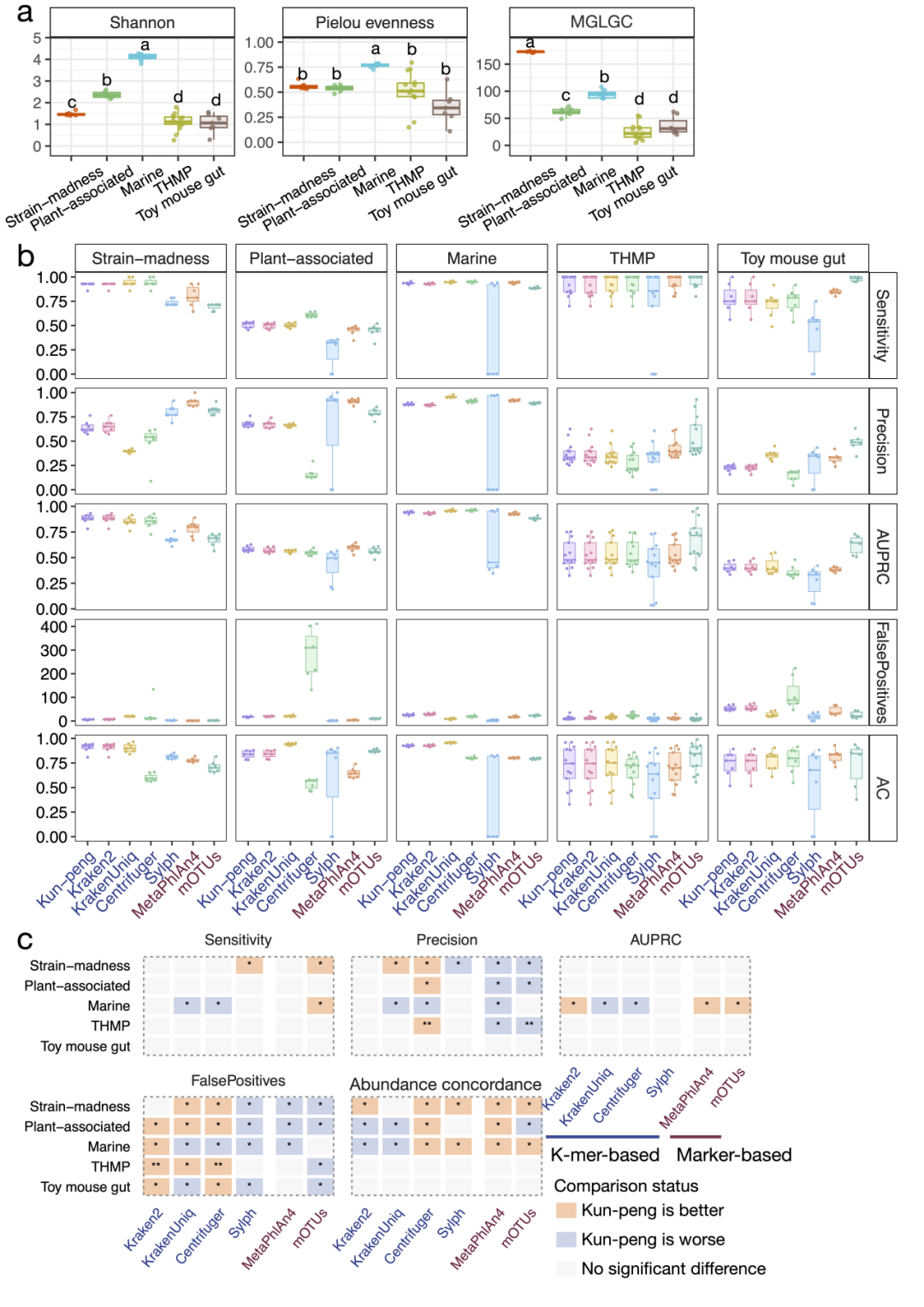
图2 | Kun-peng(鲲鹏)与多种先进宏基因组分类工具在 CAMI II 模拟群落中的性能对比
在计算效率方面,Kun-peng(鲲鹏)同样表现突出。使用相同参考序列构建数据库时,Kun-peng(鲲鹏)将峰值内存从 Kraken2 的 100.2 GB 降至 4.1 GB,降幅约 96%;构建时间则从 20.6 小时缩短至 4.6 小时,缩短约 78%。KrakenUniq 在构建阶段需要最高内存,而 Centrifuger 的构建时间最长(图3a)。
在分类阶段(图3b-c),若采用热启动(索引只加载一次),Kun-peng-M 在峰值内存仅为 9.1 GB 的情况下,速度比 Kraken2 快约 17%;而 Kun-peng-F 在内存占用接近 Kraken2 的前提下,速度达到 4.73 倍提升(1.5 分钟 vs 7.1 分钟)。尤其值得注意的是,在相近峰值内存下,Kun-peng-M 比 KrakenUniq 的低内存分块模式快 227 倍。这是因为 KrakenUniq 在无法整体载入数据库时,需要对每个数据块反复扫描整个 read 集,而 Kun-peng(鲲鹏)可根据 minimizer 实现真正的按需块查询,避免了重复全量扫描。冷启动(每个样本都重新加载索引)条件下,各工具的相对排序基本不变,但大型索引带来的装载开销更加明显。总体上,Kun-peng(鲲鹏)在保持具有竞争性的准确度的同时,大幅降低了计算成本,并且在普通个人电脑甚至外接 SSD 的条件下也可稳定运行。
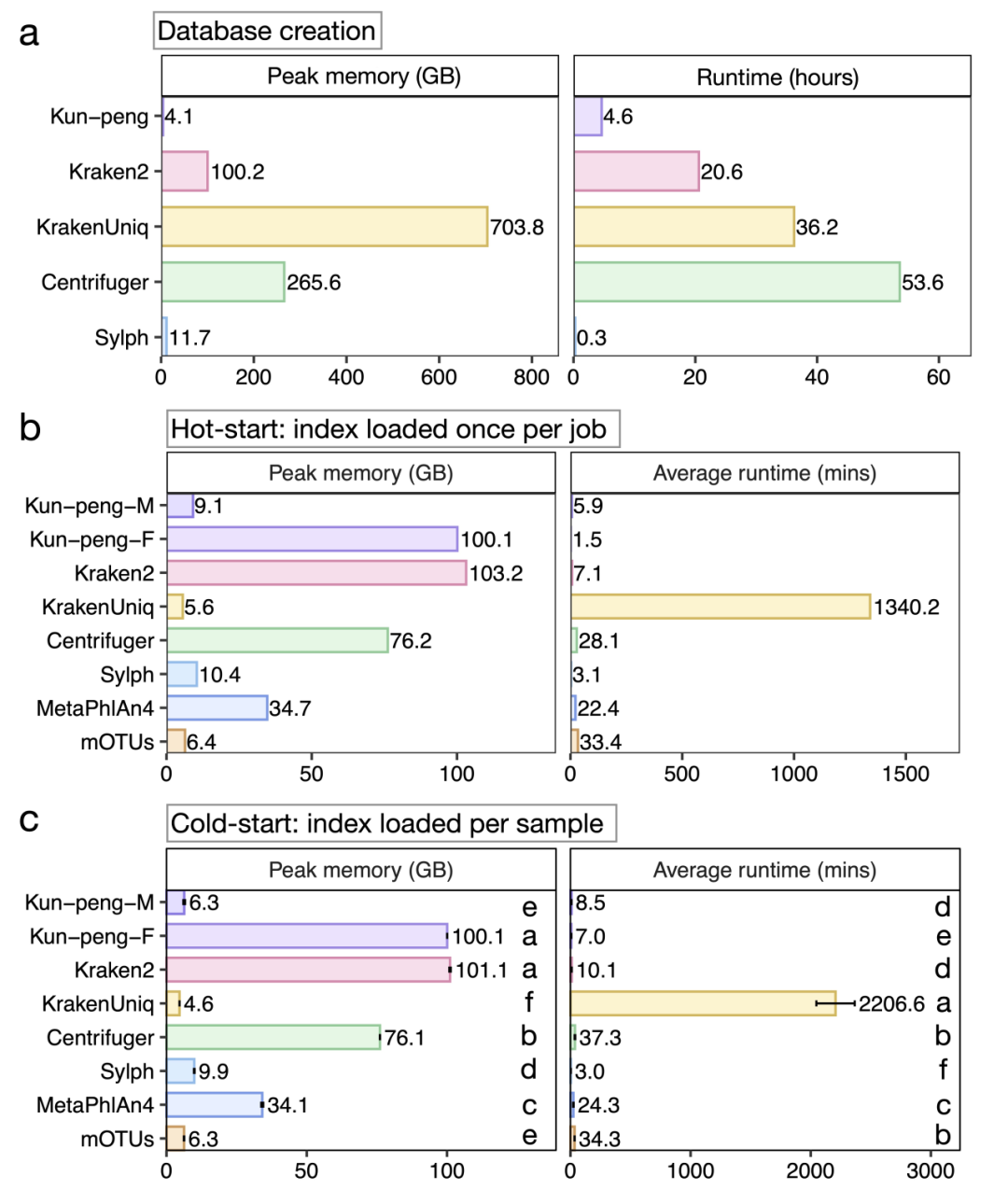
图3 | Kun-peng(鲲鹏)数据库构建与分类过程中的峰值内存和运行时间对比
Kun-peng(鲲鹏)支持复杂真实样本的泛域分类
环境样本、动物样本和植物样本的宏基因组数据通常比标准微生物组样本更复杂,使用更广泛的泛域参考数据库有助于提高注释覆盖率,但这类数据库往往超出传统工具的内存承载范围。Kun-peng(鲲鹏)借助 IBPDS 成功突破了这一瓶颈:作者收集了 4.3 TB 的 GenBank / RefSeq 完整基因组与染色体序列,构建得到 1.85 TB 的 Kun-peng(鲲鹏)泛域索引数据库,而构建时峰值内存仍只有 4.1 GB。
在 586 个真实样本中,Kun-peng-epdb 在空气、水体、土壤和人体样本上都表现出稳健的分类能力,reads 注释率大约比标准 Kraken2 数据库高出 20%--60%(图4)。作者指出,这一提升主要来自参考数据库覆盖面的扩展,即更多跨域参考基因组被纳入数据库后,原本无法归类的大量 reads 获得了潜在注释,从而为后续验证提供更丰富的生物学假设。
与之形成鲜明对比的是,Sylph 在这些复杂样本上的分类能力明显不足(图4):无论使用默认数据库还是作者构建的泛域数据库,大部分样本中仍有超过 90% 的 reads 未被分类;在 301 个空气样本中,Sylph-epdb 甚至没有成功分类任何 reads。作者认为,这反映了 Sylph 的统计模型更适合 CAMI II 那样相对简化的群落,而其 1/200 的激进子采样在低丰度、多域混合场景中会进一步削弱灵敏度。MetaPhlAn4 作为标记基因方法,在这些复杂环境样本中通常只能分类不到 2% 的 reads,而且绝大多数仍限于细菌信号,这也进一步说明基于全基因组的泛域框架在复杂样本中更具优势。
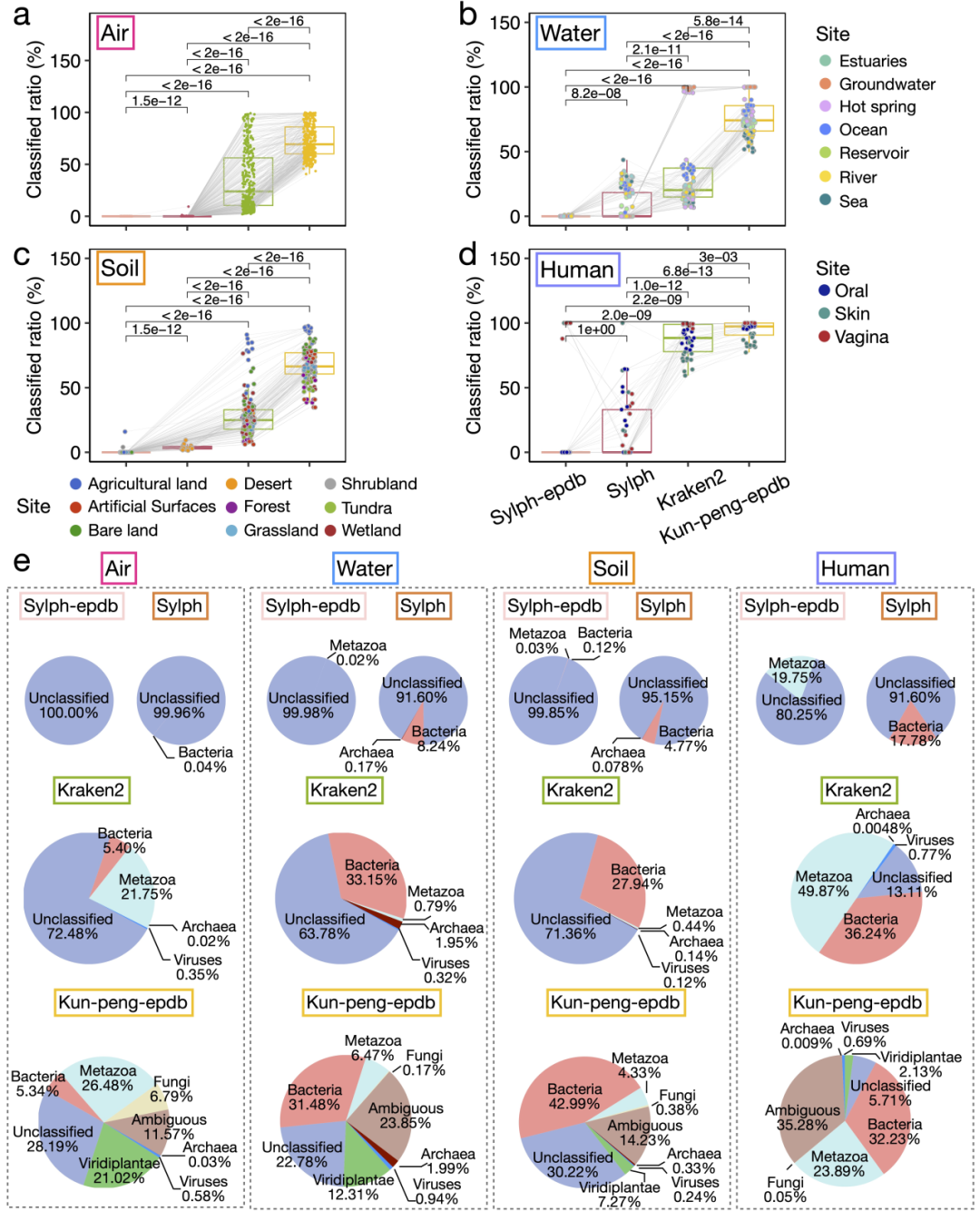
图4 | 不同工具在真实环境宏基因组样本中的 reads 分类率比较
在运行效率上(图5a),Kun-peng-epdb 同样保持了较高水准。尽管其数据库规模比标准 Kraken2 数据库大约 23 倍,但平均单样本分析时间仍保持在较合理水平:空气样本约 11 分钟,水体样本约 0.2 分钟,土壤样本约 4 分钟,人体样本约 3 分钟,整体与 Kraken2 标准数据库相当。
在峰值内存方面(图5b),Kun-peng-epdb 在空气、水体、土壤和人体样本上分别约需 25 GB、4 GB、35 GB 和 10 GB,显著低于 Sylph-epdb 的 83--88 GB,也远低于 Kraken2 在使用同等规模数据库时理论上需要的约 1.85 TB 内存。以实测最高值 35 GB 计算,也比 Kraken2 的理论需求低约 53.5 倍;若按最低值 4 GB 计算,则可低至约 473 倍。这种优势来自其 4 GB 分块数据库设计:程序只需在分类过程中按需装入必要数据块,而临时内存虽会随 read 长度、read 数量和分类吞吐波动,但相对于整个数据库规模依然较小。作者据此认为,Kun-peng(鲲鹏)不仅适合大规模真实数据分析,还能够通过减轻内存限制和缩短集群排队时间,显著改善整体分析周转效率。
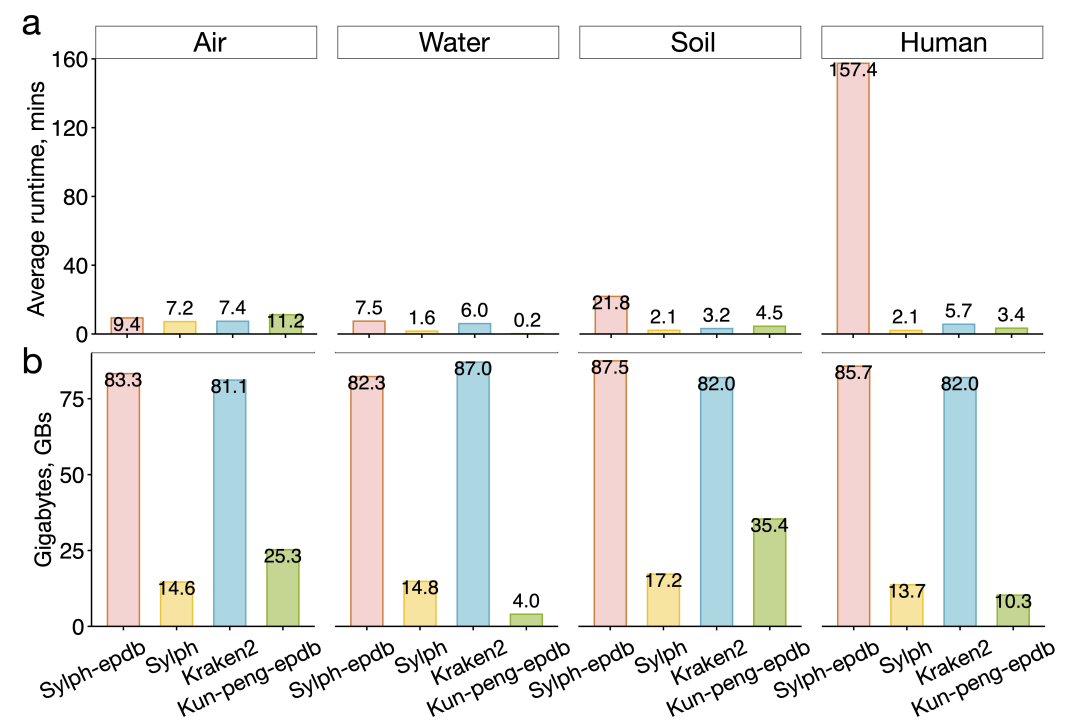
图5 | 不同工具在真实样本类别上的平均运行时间与峰值内存对比
总结
总而言之,Kun-peng(鲲鹏)通过降低内存占用、加快分类速度并支持超大参考数据库的实际使用,显著提升了泛域宏基因组分类的可行性。与多种 k-mer 和标记基因工具相比,它在 CAMI II 基准上实现了有竞争力的分类准确度,同时拥有更少的假阳性,并持续维持较高灵敏度与良好的丰度估计一致性。
其双模式设计使得 Kun-peng(鲲鹏)既能在高性能计算集群上高速运行,也能在标准个人电脑上以内存友好的方式部署。更重要的是,借助前所未有的泛域参考覆盖范围,Kun-peng(鲲鹏)在复杂环境样本与暴露组样本中展现出更高的分类敏感性。因此Kun-peng(鲲鹏)为生态学、非人体样本研究以及暴露组研究中的大规模泛域宏基因组分析,提供了一个高效、可扩展且更易普及的框架。
参考文献
Q. Chen, B. Zhang, C. Peng, J. Huang, Z. Liu, X. Shen, C. Jiang. Kun-peng enables scalable and accurate pan-domain metagenomic classification. Briefings in Bioinformatics (2026). DOI: 10.1093/bib/bbag119
作者简介
陈琼(第一作者)

陈琼,博士后,2019年博士毕业于浙江大学,研究方向为沙漠生态修复、微塑料暴露以及生信软件开发等。已在国际知名期刊Cell Discovery、Journal of Hazardous Materials、Briefings in Bioinformatics、Nutrients、The Journal of Nutrition、Journal of Agricultural and Food Chemistry等杂志发表多篇研究论文。长期担任Environmental Health Perspective、Current Microbiology、Journal of Food Science、Journal of Health and Pollution等杂志审稿人。
蒋超(通讯作者)

蒋超博士,现任浙江大学生命科学研究院研究员、博导,兼聘于浙江大学附属第一医院。长期致力于环境空气暴露组、微生物组、微生物进化、精准医学研究以及相关的分子实验和生信分析方法开发及应用。以通讯或一作在国际知名期刊Cell, Nature, Nature Communications, Nature Protocols, Advanced Science, Cell Reports, Environmental Science & Technology, iMeta, Briefings in Bioinformatics, Journal of Hazardous Materials, eBioMedicine, Cell Discovery, Critical Care, Journal of Infection, mSystems等杂志发表多篇研究论文,获得国内外专利若干。主持国家级及省部级科研项目,包括国自然科学基金病毒组学专项、科技部重大专项子课题、国自然集成项目子课题、面上项目及省杰青等。拥有多个国内外专利。目前担任iMeta、iMetaOmics副主编、Phenomics、Scientific Reports执行编委和The Innovation Life编委。蒋超实验室主要围绕暴露组和微生物组在各类自然和人体环境的多样性、功能、进化动态、环境互作展开多学科交叉的前沿研究。暴露组学是一门新兴学科,主旨在同一健康的大框架下,解析联系环境、动植物及人类健康的全景环境暴露动态及其效应机制。实验室集干湿实验、宏观微观、环境人类健康研究为一体。
宏基因组推荐
本公众号现全面开放投稿,希望文章作者讲出自己的科研故事,分享论文的精华与亮点。投稿请联系小编(微信号:yongxinliu 或 meta-genomics)
iMeta高引 fastp PhyloSuite ImageGP2iNAP2 ggClusterNet2
iMeta工具 SangerBox2 美吉2026 OmicStudioWekemo OmicShare
iMeta综述 高脂饮食菌群 发酵中药 口腔菌群 微塑料 癌症 宿主代谢
10000+:扩增子EasyAmplicon 比较基因组JCVI 序列分析SeqKit2 维恩图EVenn
iMetaOmics高引 猪微生物组 16S扩增子综述 易扩增子(EasyAmplicon)
点击阅读原文