目录
一、如何理解用户态&&内核态
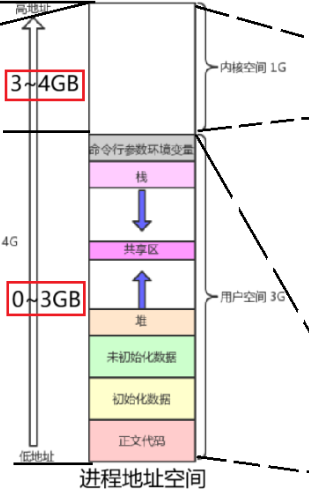
对于任何一个进程来说,都有一块专属的虚拟地址空间。我们以 32 位 x86 Linux系统举例(最经典的划分),整个虚拟地址空间一共有 4 GB,其中0 ~ 3GB是用户空间(User Space),这是进程自己私有的地盘,放进程的代码、数据、栈、堆 ,只能被【用户态】访问。而剩余的3 ~ 4GB是内核空间(Kernel Space),这是全局共享的地盘(有进程共用),放内核代码、内核数据、内核页表、系统调用表 ,只能被【内核态】访问,所有进程(不管是我们自己的程序还是系统程序),地址空间布局都是一样的:前 3G 私有,后 1G 共享。
误区 : 用户态有用户态页表,内核也有内核级页表 ❌
不存在「用户态页表」和「内核级页表」两套独立的页表,每个进程都有自己的一套完整页表,这套页表同时映射了用户空间 (0~3GB)和内核空间 (3~4GB)。内核空间的页表项,所有进程都是完全相同的(因为内核是全局的),而用户空间的页表项,每个进程都不一样(进程隔离)。内核自己运行时,用的也是这套进程页表,只是内核态可以访问所有页表项,用户态只能访问自己的 0~3GB 页表项(页表项里有权限位,限制用户态访问内核空间)。
进程地址空间的分层(32 位 Linux):
| 虚拟地址范围 | 区域 | 权限 | 说明 |
|---|---|---|---|
| 0 ~ 3GB | 用户空间 | 用户态可访问 | 包含:代码段、数据段、BSS 段(未初始化数据)、堆、共享区、栈、命令行参数 / 环境变量 |
| 3 ~ 4GB | 内核空间 | 仅内核态可访问 | 内核代码、内核数据、内核栈、页表本身、硬件资源等,用户态绝对不能直接访问 |
既然都是内存,为什么不直接都给进程用,非要分为 "用户态" 和 "内核态"?
-
【安全隔离】:防止进程搞坏系统,如果一个进程随便写 3~4GB 的内存(比如修改内核页表、篡改系统调用),会导致整个系统都会崩溃,所以操作系统做了两层隔离,用户态(0~3GB)进程只能玩自己的地盘,不能碰系统核心。内核态(3~4GB)只有操作系统能操作,进程想操作必须 "请求" 操作系统。
-
【资源隔离】:防止进程互相破坏,每个进程的 0~3GB 都是私有的(每个进程有自己的页表),3~4GB 是所有进程共享的(系统调用、内核代码、全局资源)。
-
【权限控制】:用户态进程只能读、写自己的内存,内核态能读、写整个系统的内存(包括所有进程的空间)。
下面我们总结几个细节:
细节1 : 进程中所有函数的调用,都是在自己的虚拟地址空间内完成的
整个 4GB 是同一个进程的虚拟地址空间,所有函数调用(不管是用户态还是内核态),都发生在这个 4GB 空间里。这个 4GB 被严格分成两部分:
- 0~3GB:用户虚拟空间(用户态专属)
- 3~4GB:内核虚拟空间(内核态专属)
0~3GB 用户虚拟空间跑的是用户态函数,包括普通函数,C 标准库封装函数,动态链接库函数,特点就是只能在用户态执行,绝对不能直接访问 3~4GB 内核空间,每个进程的 0~3GB 是完全私有的,其他进程无法访问。举个例子 : printf() 本身是用户态函数,跑在 0~3GB;但它内部最终会调用系统调用 write(),触发软中断进入内核态,去 3~4GB 执行内核代码。
3~4GB 内核虚拟空间:跑的是内核态函数,包括系统调用,内核核心函数(中断处理函数、信号处理函数(do_signal),进程调度函数、内存管理函数),和内核驱动函数等,特点就是只能在内核态执行,用户态绝对不能直接调用。通过系统调用(syscall/int 0x80 软中断),硬件中断(时钟中断、键盘中断),CPU 异常(缺页、除零)触发,所有进程的 3~4GB 内核空间,完全映射到同一块物理内核内存,全局共享。
细节二 : 每个进程有一套完整页表,用户空间页表项私有隔离,内核空间页表项全局共享、唯一不变。
细节三 : 进程切换时只换用户空间映射,内核空间映射永远不变,所以 OS 永远可访问,绝不会找不到。
因为所有进程的 3~4GB 内核空间,都映射到同一块物理内核内存,页表项完全一致。进程切换的本质只是切换了当前进程的页表,但新进程的页表中,3~4GB 内核空间的映射和旧进程完全一样,内核代码、数据、系统调用表的虚拟地址永远不变。无论切换到哪个进程,内核的虚拟地址都是固定的,所以系统调用、中断、异常处理永远能正常执行,不会出现找不到 OS的情况。
用户态和内核态的转换
如果进程可以直接访问所有内存、硬件资源,一旦出现 bug 或恶意代码,会直接破坏整个操作系统,导致系统崩溃。因此操作系统通过权限分级实现隔离:
- 用户态(低权限):进程只能访问自己的 0~3GB 虚拟地址空间,不能直接操作硬件、修改系统资源。
- 内核态(高权限):操作系统运行的状态,可访问整个 4GB 虚拟地址空间、所有硬件资源,执行特权指令。
核心结论:CPU 的状态 = 进程的状态,CPU 运行在哪个权限,进程就处于哪个态。如果CPU 是低权限,那进程现在就处于用户态。
CPL
在x86架构下的 CPU 中,有一个叫 CS 的寄存器,CS 全称 Code Segment Register(代码段寄存器),是 CPU 中硬件级的寄存器,和我们熟悉的 rax、rbx、rsp 是同一类东西。
这个CS寄存器中有一个字段,这个字段是两个比特位,这两个比特位要么是全0,要么全1,当全为 0 时用二进制表示就是数字 0,全为 1 时是数字 3,这两个比特位的值,就直接、实时地标识当前 CPU 的运行权限状态,我们把这个值叫做 CPL (Request Privilege Level,请求特权级)。
所以说 CPL 就是 CS 寄存器里那 2 个比特位的实时值,没有任何中间层:
- 当这 2 位是 00(数值 0):CPL=0 → CPU 运行在内核态,拥有最高权限,可执行所有特权指令、访问所有内存。
- 当这 2 位是 11(数值 3):CPL=3 → CPU 运行在用户态,权限最低,只能访问用户空间,不能执行特权指令。
补充 :
- CPU 每执行一条指令,都会检查 CPL 的值,权限检查是硬件级、实时的,完全由 CS 寄存器的这 2 位决定。
- CPU 的权限状态,就是当前进程的权限状态,二者完全等价。
DPL
DPL 和 CPL 一样,也是用两个比特位分别表示 0 和 3,DPL 是代码段、数据段、系统调用入口、中断入口的访问权限标记:
- 当 DPL = 0 时,只有内核态CPL=0时才有权限访问/执行该段,用户态CPL=3无权访问;
- 当 DPL = 3 时,用户态CPL=3和内核态CPL=0都有权限访问/执行该段。
访问前硬件会自动检查:只有满足 CPL ≤ DPL(数值越小权限越高),才允许访问 / 执行,否则触发异常。
每执行一条代码,CPU 都要检查权限,不是我们想的 "偶尔检查一下",是CPU 硬件级,每条指令都自动检查。只要我们执行一条指令,CPU 立刻做三件事:
- 看CPU自己当前所处的运行状态:CPL(0 或 3)
- 看要执行的这段代码的DPL:DPL(0 或 3)
- 然后判断:CPL ≤ DPL 才能执行,否则直接报错(段错误)
我们直观的举个例子 :
- 场景 1:当我们在用户态(CPL=3)执行用户代码(DPL=3),CPL=3 ≤ DPL=3 ✅,允许执行
- 场景 2:你在用户态(CPL=3)想去执行内核代码(DPL=0),CPL=3 ≤ DPL=0❌,不允许执行,CPU 直接拒绝,触发异常并引起程序崩溃
- 场景 3:你在内核态(CPL=0)执行任何代码,0 ≤ 任何 DPL(0 或 3)都成立✅,所以内核能执行所有代码
所以每一条指令执行前,CPU 都会自动检查 CPL 和 DPL。这就是硬件级的保护机制,保证用户态永远不能乱碰内核。
陷入内核
陷入内核是什么意思?
陷入内核(Trap into Kernel) 本质就是CPU 从用户态(CPL=3)切换到内核态(CPL=0)的过程,**是操作系统实现系统调用、中断、异常处理的核心机制。**它不是 "跳进内核代码里" 这么简单,而是一次完整的硬件级权限切换:
- 保存用户态的寄存器、栈指针等上下文到内核栈
- 硬件自动将 CPL 从 3 修改为 0,获得内核态最高权限
- 跳转到内核对应的处理函数(系统调用服务例程、中断处理函数等)执行
- 执行完成后,恢复用户态上下文,将 CPL 改回 3,切回用户态继续执行
陷入内核过程中,当我们执行 syscall 或 int 0x80 时,CPU 会去查对应的 DPL。当 DPL = 3 并且CPU的 CPL = 3 时,3 ≤ 3 ✅,通过!允许触发内核态切换。如果 DPL=0,CPL=3 ≤ DPL=0 ❌ ,直接拒绝,无法陷入。当跳进内核后,我们要执行的内核函数(如 sys_read)所在的代码段 DPL=0。此时CPU的 CPL 已经被硬件自动改为 0(内核态),0 ≤ 0 ✅,允许执行内核函数。
DPL 保证了CPU自己不可能把自己的 CPL 改成 0,必须走合法的 DPL,这就是系统真正的安全保护。
我们可不可以拿着syscall / int修改CPU权限级别使其陷入内核?
结论:不可以,不是 "我们修改",是硬件自动完成。syscall(x86-64)、int 0x80(32 位 x86)本身就是触发陷入内核的指令,它们的作用是触发软中断,让 CPU 进入内核态。权限修改(CPL 从 3→0)不是软件做的,是 CPU 硬件在响应中断时自动完成的,用户程序、内核程序都没有权限手动修改 CPL,这是硬件强制保护的。
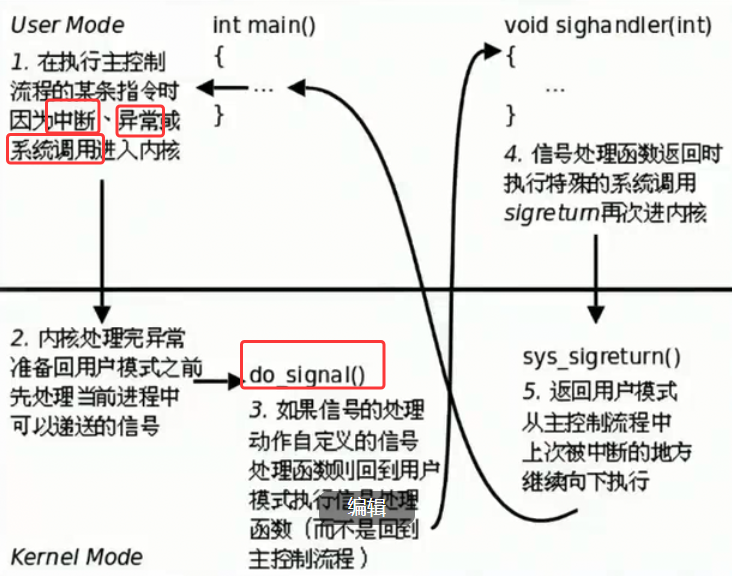
此时我们再回过头来看这幅图,这张图就是用户态/内核态切换、陷入内核、权限检查、信号处理的完整流程。我们再来逐一讲解一下流程 :
步骤 1:中断 / 异常 / 系统调用 → 进入内核(第一次陷入内核)
- 这是用户态 (CPL=3) 陷入内核,是从低权限切到高权限的唯一合法方式。不管是系统调用、中断还是异常,本质都是触发一次硬件级的权限切换:CPU 会先做权限检查(CPL ≤ DPL),确认用户态(CPL=3)有权限触发这次切换,然后硬件自动把 CPL 从 3 改成 0,CPU 就从用户态切到了内核态,进入 3~4GB 的内核空间执行代码。
步骤 2:内核处理完异常 → 执行do_signal()
- 此时 CPU 已经是内核态(CPL=0),拥有系统最高权限。do_signal()是内核函数,它所在的内核代码段 DPL=0,CPL=0 满足0 ≤ 0,正常执行。它的作用就是检查当前进程有没有未处理的信号,决定信号是默认处理、忽略,还是执行用户自定义的处理函数,是内核态内部的操作。
步骤 3:有自定义信号处理函数 → 切回用户态执行sighandler
- 这是内核态(CPL=0)切回用户态(CPL=3),高权限切低权限,没有安全风险,不需要额外检查。内核会修改用户栈的上下文,把返回地址改成用户自定义的sighandler函数入口,然后硬件自动把 CPL 从 0 改回 3,CPU 切回用户态,执行用户态的信号处理函数。sighandler是用户态函数,所在的用户代码段 DPL=3,CPL=3 满足3 ≤ 3,可以正常执行。
步骤 4:信号处理函数返回 → 执行sigreturn → 再次进入内核(第二次陷入内核)
- 这是第二次用户态(CPL=3)陷入内核,和第一次逻辑完全一致。sigreturn是系统调用,用户态执行它时,CPU 再次做权限检查,确认用户态有权限触发,然后硬件自动把 CPL 从 3 改成 0,切回内核态,执行内核函数sys_sigreturn()。作用是恢复用户态被中断的上下文,为切回main函数做准备。
步骤 5:sys_sigreturn执行完 → 切回用户态,回到main继续执行
- 这是第二次内核态(CPL=0)切回用户态(CPL=3),硬件自动把 CPL 从 0 改回 3,恢复用户态的寄存器、栈等上下文,回到main函数中被中断的指令,继续往下执行。整个流程闭环,完全符合我们讲的「用户态↔内核态切换」的完整逻辑。
时钟中断与陷入内核
其实在操作系统内核,几乎一直靠时钟中断 + 各种硬件中断,反复把 CPU 拉进内核态。 操作系统会因为时钟中断持续不断地触发陷入内核的动作,CPU 平时大部分时间都在运行普通用户进程、处于用户态低权限状态,而硬件自带的时钟定时器每隔几毫秒就会自动发出时钟中断,一旦中断产生,CPU 就会立刻做硬件层面的权限校验,完成权限相关检查后自动把当前特权级 CPL 从代表用户态的 3 改成代表内核态的 0,强行让 CPU 陷入内核;进入内核态之后,操作系统会趁机完成进程调度切换 CPU 占用权、检测当前进程有没有待处理的信号、更新系统时间、维护系统后台数据这些核心工作,对应之前信号流程图里进入内核后执行 do_signal 检测信号的逻辑,处理完所有内核需要完成的任务后,又会通过硬件自动把 CPL 从 0 改回 3,退回用户态继续运行原本的用户程序,整个过程会一秒钟重复几十甚至上百次,速率非常快,也就意味着内核不是一直主动霸占 CPU 运行,而是靠着频繁的时钟中断反复被拉入内核态做短暂的系统维护工作,保障整个系统的调度、信号处理和基础运转始终正常,这也是系统能实时管控所有进程、响应各类信号和调度需求的根本原因。
下面我们可以用一段代码说明这个现象 :
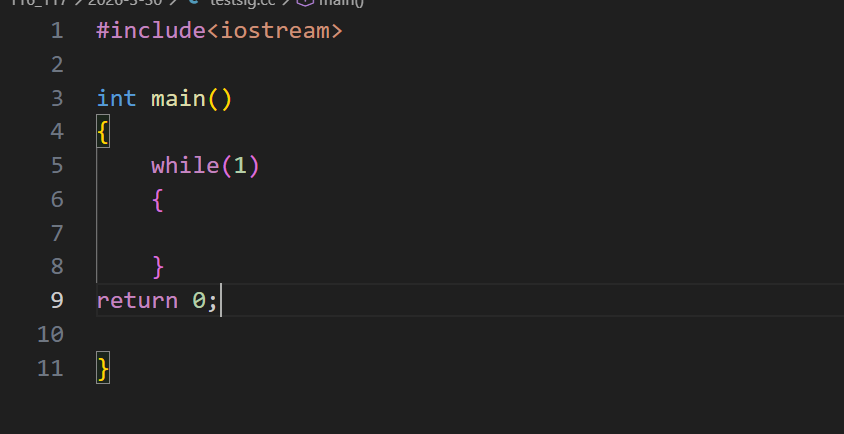

上图是一段 C++ 死循环代码,运行后用 Ctrl+C(终端显示^C)终止程序,这个现象完美对应了我们前面聊的中断、信号、用户态 / 内核态切换的完整逻辑。
不管我们的代码是死循环还是正常运行,硬件定时器都会每隔几毫秒自动触发一次时钟中断,强行把 CPU 从用户态拉进内核态。每次陷入内核,都会做 "信号检查",进入内核后,内核会在do_signal() 函数里第一时间检查当前进程有没有未处理的信号。我们按下 Ctrl+C 的瞬间,键盘中断触发,内核把SIGINT信号(2 号信号)挂到你的进程信号队列里。下一次时钟中断陷入时,才会真正处理信号,内核不会立刻处理信号,而是等到下一次时钟中断触发,CPU 再次陷入内核时,在 do_signal() 里检测到信号队列里有SIGINT,如果我们自定义了处理函数,就切回用户态执行你的sighandler。如果没自定义就执行系统默认动作(直接终止进程)。
状态切换 CPL 变化 DPL 作用 用户态 → 内核态(中断 / 系统调用) 3 → 0 入口 DPL=3,校验 3 ≤ 3,允许切换内核态执行内核函数 保持 0 内核段 DPL=0,校验 0 ≤ 0,允许执行内核态 → 用户态(返回 / 切 handler) 0 → 3 用户段 DPL=3,校验 3 ≤ 3,允许执行用户态执行用户函数 保持 3 用户段 DPL=3,校验 3 ≤ 3,允许执行对应这幅图就是 : CPU 在用户态执行main主控制流程时,始终处于 CPL=3 的低权限状态,硬件定时器会周期性触发时钟中断,对应图中步骤 1,中断入口的 DPL=3,CPU 完成CPL=3 ≤ DPL=3的权限校验后,硬件自动将 CPL 从 3 修改为 0,使 CPU 切换为内核态高权限状态,完成陷入内核;内核处理完时钟中断、准备返回用户态前,会执行do_signal()函数,对应图中步骤 2,该函数属于内核代码段,DPL=0,CPL=0 满足0 ≤ 0的权限要求,内核在此检查当前进程的未决信号,若检测到SIGINT(2 号信号),则分两种分支处理:若信号无自定义处理函数,内核直接执行默认终止操作,在 CPL=0 的内核态销毁进程,不会切回用户态,流程终止;若信号注册了自定义sighandler,则对应图中步骤 3,内核修改用户栈上下文后,硬件自动将 CPL 从 0 改回 3,切回用户态,sighandler所在用户代码段 DPL=3,CPL=3 ≤ DPL=3校验通过,CPU 执行自定义信号处理函数而非回到main的断点;当信号处理函数返回时,对应图中步骤 4,执行sigreturn系统调用,系统调用入口 DPL=3,CPL=3 ≤ DPL=3校验通过,硬件再次将 CPL 从 3 改为 0,进入内核态执行sys_sigreturn(),恢复main的断点上下文;最后对应图中步骤 5,硬件将 CPL 从 0 改回 3,切回用户态,main所在用户代码段 DPL=3,CPL=3 ≤ DPL=3校验通过,CPU 回到main中上次被中断的位置继续向下执行,整个流程全程由 CPL 标识当前权限状态、DPL 标识资源访问门槛,通过硬件自动的权限检查保障用户态与内核态的安全隔离。
但是我还有个问题,就是第一个步骤中说因为中断,异常或者系统调用进入内核,这个中断,是不是就是硬件中断、软中断、时钟中断这些吗?
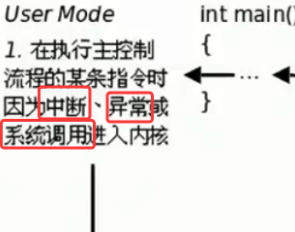
图里步骤 1 说的中断、异常、系统调用,是进程进入内核态的三类入口:
- 中断:包含硬件中断(键盘、磁盘、网卡中断)、时钟中断(属于硬件定时中断)、软中断(内核态的异步任务)都算,只要触发就会强制切内核态。
- 异常:比如缺页、除零、非法指令这类 CPU 执行时的错误,会主动陷入内核。
- 系统调用:用户态主动调用write/read/sigreturn这类函数,主动切内核态。
还有个问题就是这个时钟中断的是不是几毫秒一次几毫秒一次,速率很快? 每次是不是都要进入内核之后检查是否有信号吗?
时钟中断的频率是系统级配置,Linux 默认一般是10ms(100Hz)左右(不同版本配置会有差异,比如 100Hz、250Hz、1000Hz,对应 10ms、4ms、1ms)。每次时钟中断一定会进入内核态:时钟中断是硬件触发的,CPU 会暂停当前用户态代码,跳转到内核的时钟中断处理函数执行。
但是我感觉这个速率好快呀,每隔几毫秒就切换切换切换,这个 CPU 效率来得及吗?
几毫秒的时钟中断,CPU 完全 "来得及",我们先算一笔账:假设时钟中断周期是10ms(100Hz),也就是每秒触发 100 次。现代 CPU 的主频是GHz 级(比如 3GHz = 每秒 30 亿个时钟周期),10ms 的时间里,CPU 能执行约 3000 万个指令。而一次时钟中断 +do_signal() 检查的总耗时,通常只有几微秒(μs)级别(1μs = 0.001ms),相当于在 10ms 的周期里,只花了不到 0.1% 的时间做内核态切换和信号检查,对 CPU 效率的影响微乎其微。几毫秒一次的时钟中断切换,对现代 CPU 来说完全没有效率压力,开销占比极低,而且内核做了大量优化来降低成本,是操作系统正常运行的必要开销。
所以陷入内核就是中断、异常和系统调用这三种情况吗?中断就包括硬件中断、软件中断以及时钟中断吗?还有其他的吗?系统调用就是当我们的代码中如果碰到系统调用的话,也会直接进入内核是吧?然后异常也是同样的情况吗?
- 陷入内核只有三种方式 : 1.中断(硬件)2.异常(CPU 自己发现错了)3.系统调用(程序主动进内核),没有第四种。中断包含硬件发来的信号,时钟中断,键盘中断,磁盘中断,网卡中断,鼠标中断......全部都是硬件中断。但是软中断(softirq)是内核内部的东西,不算 "陷入内核" 的入口。
- 系统调用怎么回事? 比如我们的代码里写了printf,,open,read,write,只要执行系统调用指令(syscall / int 0x80)立刻从用户态切换为内核态。
sigaction
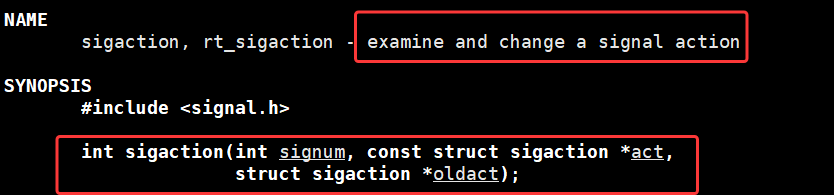
sigaction 系统调用是 Linux 系统中用于检查和修改信号处理动作的标准系统调用,通过 signum 指定目标信号、act 设置新的处理规则、oldact 保存旧规则,核心是为信号注册自定义处理函数,它的作用 signal() 一摸一样,并且可以看成是 signal() 函数的增强版。
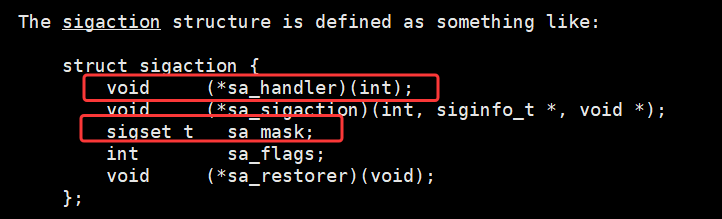
第二个和第三个参数的类型是什么结构体?
这个结构体是用来打包 "信号怎么处理" 的所有配置的结构体,一次性传给内核。一个信号需要设置的东西有好几个:1.用哪个函数处理?(sa_handler)2.处理时要屏蔽哪些信号?(sa_mask)3.要不要自动重启系统调用?(sa_flags)... 等等,这些东西不能零散传给内核,内核规定必须打包成一个结构体,一起传过去,这也是优于 signal() 的原因之一。第二个参数 act 是我们要传给内核的新配置好的结构体变量。第三个参数 oldact 是内核返回给我们的旧的原来的结构体变量。
下面我们来看一下这个结构体里的成员变量都代表着什么? 我们着重看第一个和第三个成员变量
第一个成员 void (*sa_handler)(int) ,本质是一个函数指针,指向我们写的自定义信号处理函数 (就是 sighandler(int) )。作用就是告诉内核,当对应信号触发时,跳转到这个函数去执行。
第三个成员 sigset_t sa_mask,本质是一个信号掩码(信号集合),是一个位掩码类型,用来标记在执行当前信号处理函数时,需要临时阻塞的信号。**作用是解决信号重入问题 ------ 当我们正在处理 A 信号时,默认会阻塞 A 信号本身,我们可以通过 sa_mask 额外添加其他要阻塞的信号,避免多个信号打断当前处理逻辑。**比如我们在 SIGINT 处理函数里,不想被 SIGALRM 打断,就把 SIGALRM 加入 sa_mask,内核在执行 sighandler 期间,会临时阻塞这些信号,等处理完再投递。
其余的变量以表格的形式进行补充:
| 成员 | 作用 |
|---|---|
void (*sa_sigaction)(int, siginfo_t *, void *); |
带额外信息的信号处理函数,需要配合 SA_SIGINFO 标志使用,能获取信号发送者的 PID、UID 等详细信息,比 sa_handler 更强大 |
int sa_flags; |
行为标志位,比如 SA_RESTART 让被信号中断的系统调用自动重启,SA_NODEFER 不阻塞当前信号等,控制信号的处理行为 |
void (*sa_restorer)(void); |
历史遗留字段,用于信号处理完后的栈恢复,由系统自动设置,用户无需手动赋值 |
这个结构体是在内核中已经存在了吗 我们直接生成变量就行了吗
这个结构体的定义在头文件里,不是内核里,struct sigaction 是 POSIX 标准定义的 C 语言结构体类型,它的定义在 <signal.h> 头文件里。我们可以直接在用户态生成变量,然后传给内核,我们在用户态代码里,直接声明 struct sigaction act; 就创建了一个这个类型的变量,完全在用户态栈 / 堆上分配内存,和内核无关。
信号阻塞、未决与信号递送的关系
- 信号阻塞(Block):给信号挂一个「暂停处理」的牌子。内核收到这个信号后,不会立刻递送,先把它存起来。就像快递到了,但你设置了「暂时不要敲门」,快递员先放驿站。
- 信号未决(Pending):已经被内核收到、但还没被进程处理的信号,处于「待处理」状态。就是驿站里还没送到你手上的那堆快递。
- 信号递送(Delivery):内核把信号交给进程,进程去执行信号处理函数(或默认动作)。就是快递员终于把包裹送到你手上,你拆开处理。
三者的完整流转逻辑 :
内核收到信号检查是否阻塞,如果这个信号没被阻塞:立刻执行递送 → 进程去跑信号处理函数。
如果这个信号被阻塞:内核把它标记为「未决」,先存起来,不递送。解除阻塞后,当我们把这个信号的阻塞状态取消时,内核会立刻把之前「未决」的信号递送给进程,进程开始处理。
1. 阻塞 → 未决的关系
开始阻塞时:信号还没来 → 自然不是未决状态,只是给这个信号挂了「暂时别递送」的牌子。
信号来了之后:内核发现它被阻塞 → 立刻把它标记为未决(Pending),先存起来,不递送。
取消阻塞后:内核检查到有未决信号 → 立刻尝试递送(Delivery)。
所以顺序是: 设置阻塞 → 信号到达 → 变为未决 → 取消阻塞 → 递送
2. 未决之后会立马递送吗?
是的,只要满足两个条件:
-
信号的阻塞状态被解除
-
进程当前处于「可被中断」的状态(比如在用户态、或即将从内核态返回用户态)
内核会在下一次进程从内核态返回用户态时,把未决信号递送给进程。
3. 递送之后会立马执行吗?
是的,几乎是立刻执行!
递送的本质就是:内核把进程的执行上下文切到信号处理函数,进程会暂停当前代码,先去跑你注册的处理函数,等处理函数跑完,再回到原来被打断的位置继续执行。
二、可重入函数
在学习可重入函数之前,我们先复习一下单链表的头插
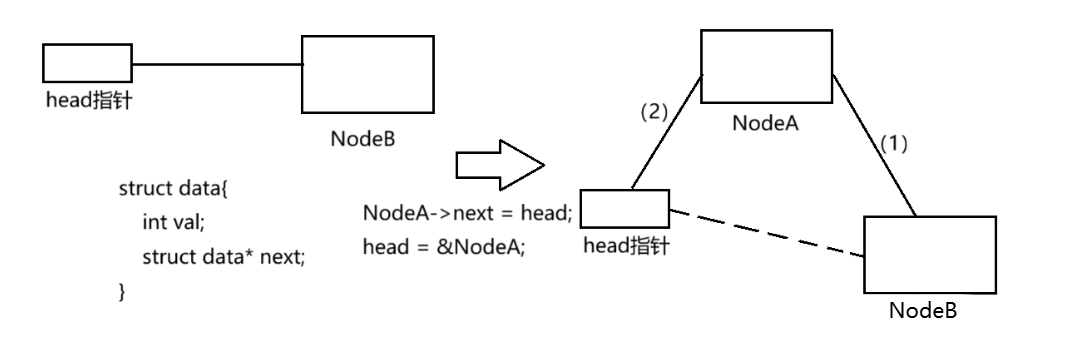
单链表头插的核心是两步:① 新节点的next指向当前头节点head;② 更新head为新节点。
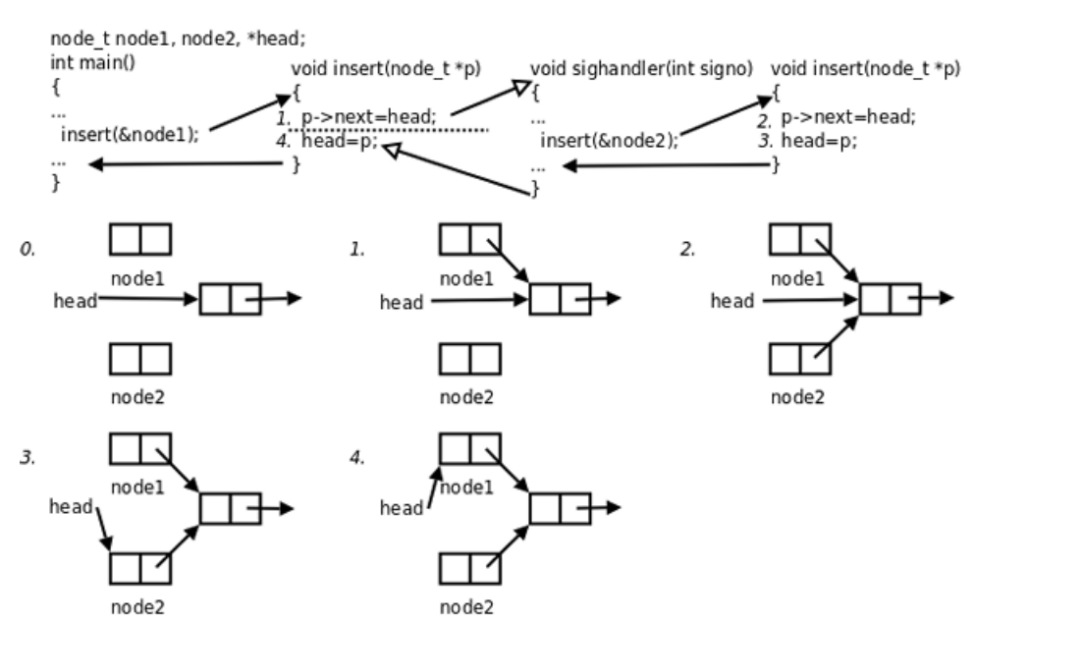
当main函数执行头插操作时,刚执行完第一步(p->next = head,新节点node1已经指向原头节点),还没来得及执行第二步(head = p,更新头指针),就被时钟中断 / 信号打断:进程从用户态陷入内核态,内核检测到未决信号(比如SIGINT),准备返回用户态时执行自定义的handler信号处理函数;handler函数也对同一个全局单链表执行头插操作,插入新节点node2,此时head还没被main更新,所以handler的头插会正常完成,head被更新为node2;handler执行完毕,通过sigreturn切回内核态,再切回用户态,main函数从断点继续执行,也就是执行第二步head = p,把head重新指回node1。
此时head最终指向了node1,而node2的地址彻底丢失,再也无法通过链表访问,造成内存泄漏,链表结构完全损坏。造成整个问题的根源就是insert函数操作了全局变量head,被main和handler两个独立执行流重复进入,打断了原本完整的两步操作,导致数据不一致。
所以就引入了可重入函数和不可重入函数 :
不可重入函数:如果一个函数被重复进入时,会出错,就称为不可重入函数。我们日常写的大部分函数(操作全局变量、静态变量、malloc/free、标准 IO 等)都是不可重入的。这些函数被重复进入时就会出错。
可重入函数:如果一个函数被重复进入时,永远不会出错,就称为可重入函数。核心要求:不访问任何全局 / 静态变量、不修改全局资源、只使用栈上的局部变量。
三、volatile
我们可以设置全局变量标志位flag = 0,当main函数中使用标志位while(!flag)执行死循环的时候,可以使用signal自定义捕捉信号,当捕捉到对应的信号的时候,例如:2号信号,那么此时就执行handler方法,handler方法中有将标志位设置为1,那么此时main函数中的死循环while(!flag)就会退出,所以main函数就会正常向后执行,进程正常退出。
所以类似的,我们就可以使用ctrl+c以发送2号信号形式退出main函数中的死循环,进而就可以结束进程。
此时进程已经使用signal函数对2号信号进行了设置,并且此时进程正在执行while(!flag)死循环
那么我们使用ctrl+c给进程发送了2号信号之后,此时执行handler方法,flag设置为1,那么main函数中的while(!flag)就会结束死循环,进而进程就会正常退出


CPU优化
下面是g++中的几个优化选项,其中-03的优化程度已经够高了,我们下面使用g++的-03选项去优化编译源文件
这些是 g++(GCC C++ 编译器)的核心编译优化选项,这些优化选项,核心是在「性能、编译时间、代码体积、可调试性、标准兼容性」之间做权衡:
- -O0:完全不优化,默认选项,编译最快、好调试,但运行最慢,只适合开发调试;
- -O/-O1:基础优化,平衡编译速度和性能,适合快速编译的工具;
- -O2:生产环境首选,开启几乎所有安全优化,性能大幅提升,体积可控,可调试性好,绝大多数软件都用它;
- -O3:最高安全优化,在-O2基础上做更激进的优化,压榨硬件性能,适合计算密集型场景,但编译慢、体积可能变大;
- -Os:体积优化,在-O2基础上缩小二进制大小,适合嵌入式、存储受限场景;
- -Ofast:极限性能,在-O3基础上放宽标准、牺牲精度,性能拉满但兼容性差,仅适合特定场景;
- -Og:调试专用优化,兼顾性能和调试信息,解决-O0慢、-O2难调试的问题,是调试阶段的推荐选项。
g++ 的 - O0/O1/O2/O3 这些选项,不是给编译器自己提速,而是让编译器把我们的 C++ 代码,重写成更贴合 CPU 硬件特性、执行效率更高的机器指令,最终让程序在 CPU 上跑得更快、占资源更少。
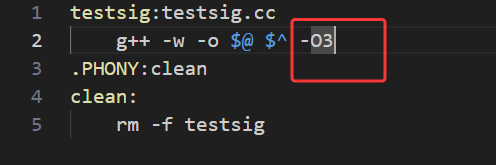

我们现在用 g++ -O3 编译运行,程序打印出 process use signal set 2 in handler 后就直接退出了,这其实是 -O3 编译器优化过度,改变了信号处理流程导致的,并不是代码逻辑错了,而是编译器在 -O3 级别下做了激进优化,导致程序收到信号后没有按照预期执行,而是直接正常退出,这也就是为什么 -O0 能正常运行,-O3 却会直接退出的核心原因 ------编译器的激进优化破坏了信号处理的原本流程。
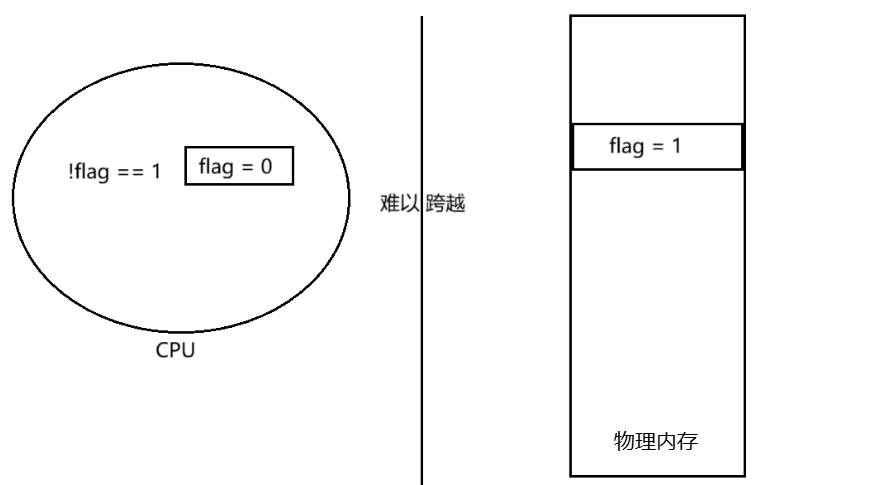
上述代码,本质上我们没有进行修改flag,仅仅只是将flag进行逻辑判断,所以在我们给g++添加-O3优化选项之后,那么此时编译器就会告诉CPU,这个flag在main函数没有进行修改,仅仅是进行了逻辑判断,而一般CPU拿数据都是从物理内存中拿数据,但是访问内存也是需要消耗时间的,所以进行了优化之后,CPU为了提高访问内存效率,针对这个flag会将flag的值0拷贝到CPU的寄存器中,那么此时CPU每次想要拿flag,那么就不再需要从内存中取了,而是直接从寄存器中拿数据,那么此时CPU每次拿flag的数据都是0。
所以此时小编给进程发送2号信号,那么就会执行自定义捕捉方法,将物理内存中的flag修改为1,那么此时CPU执行while(!flag)再进行判断,但是由于进行了优化,CPU想要拿数据不会从物理内存中拿flag的值了,而是从自己的寄存器中拿flag的值0,这就造成了无论你物理内存中的flag的值变成什么,我CPU的从自己寄存器中拿到的flag永远是0,所以这也就造成了!flag == 1永远成立,所以while(!flag)也永远成立,while循环永远退不出去,所以进程也就无法通过2号信号的方式正常退出了,所以因为编译器的优化,让CPU和物理内存形成了一个屏障,最终造成了内存的不可见。
那么该如何解决呢?此时关键字volatile就可以闪亮登场了,被volatile修饰的变量,可以防止变量被编译器过度优化,保持内存的可见性,即让CPU取被volatile修饰的变量的值的时候,每次都访问物理内存,从物理内存中取被volatile修饰的变量的值,所以这样就打破了CPU和物理内存的屏障,所以我们现在使用volatile修饰全局变量flag观察现象。
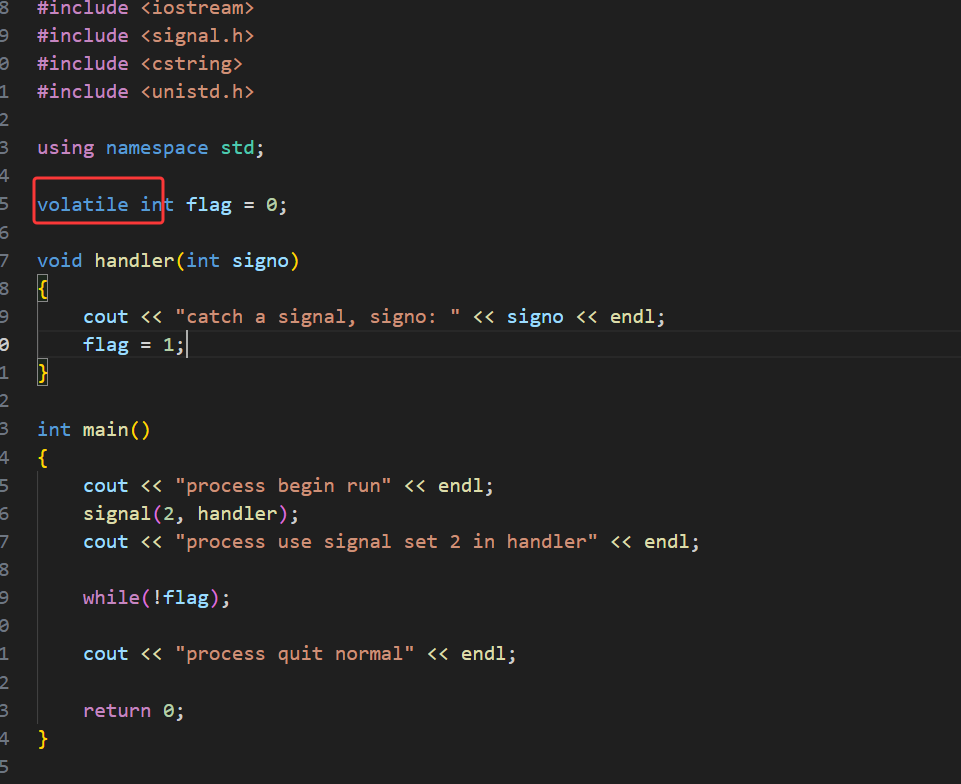
加入 volatile 关键字之后,尽管此时使用了g++加上-O3的优化选项编译形成可执行程序
我们使用ctrl+c仍然可以正常退出程序


四、SIGCHLD信号
回忆起我们之前学习进程等待的时候,讲到当子进程退出的时候,父进程需要阻塞式等待或者非阻塞式轮询等待子进程的退出,否则子进程就会变成僵尸进程,造成资源泄漏。
那么子进程退出的时候,是静悄悄的退出吗?不是,相反子进程在退出的时候要给父进程发送17号信号,即SIGCHLD,如何证明呢?

 那么我们就使用handler对17号信号捕捉一下,捕捉方法是handler方法,即打印收到的信号编号,子进程打印信息,5秒时候子进程退出,当子进程退出的时候,看是否父进程对17号信号进行打印
那么我们就使用handler对17号信号捕捉一下,捕捉方法是handler方法,即打印收到的信号编号,子进程打印信息,5秒时候子进程退出,当子进程退出的时候,看是否父进程对17号信号进行打印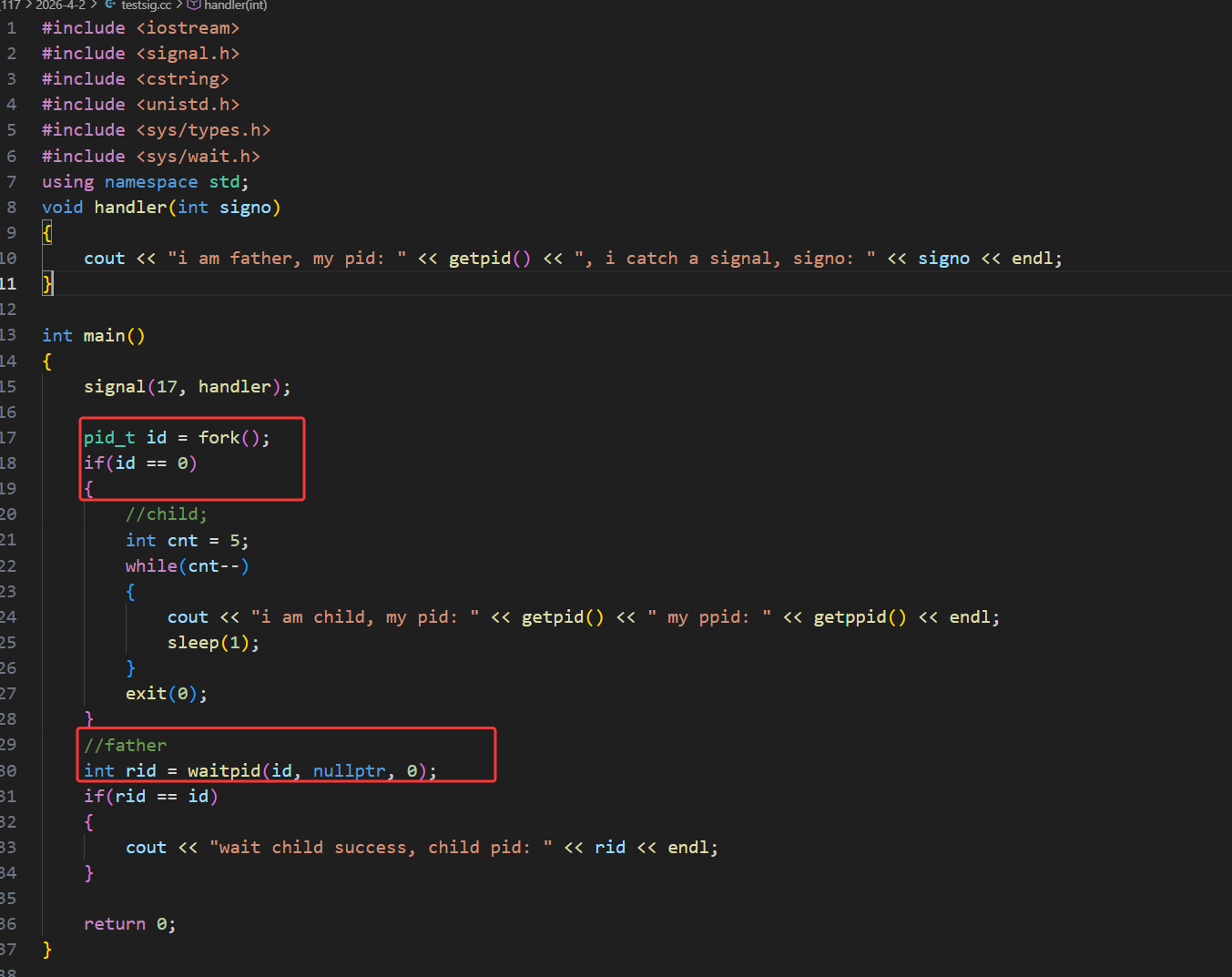
此时父进程确实是执行的handler方法,打印了收到的信号编号17号,代表着子进程退出的时候确实是给父进程发送了17号信号
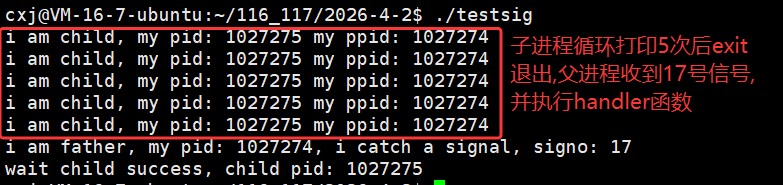
那么我们不妨摒弃之前的等待子进程的方法,让父进程做自己的事情,既然子进程退出的时候是会给父进程发送17号信号,那么我父进程完全可以提前捕捉17号信号,收到17号信号的时候,在handler方法内对子进程进行回收即可,但是这个过程必须保证父进程的运行时间比子进程的时间长,即父进程要晚于子进程退出,如果父进程早于子进程退出,那儿可怜的子进程不就成了孤儿进程了,所以父进程必须晚于子进程退出,那么子进程打印信息,运行5秒之后退出即可,由于父进程必须晚于子进程退出,所以我们让父进程死循环睡眠即可
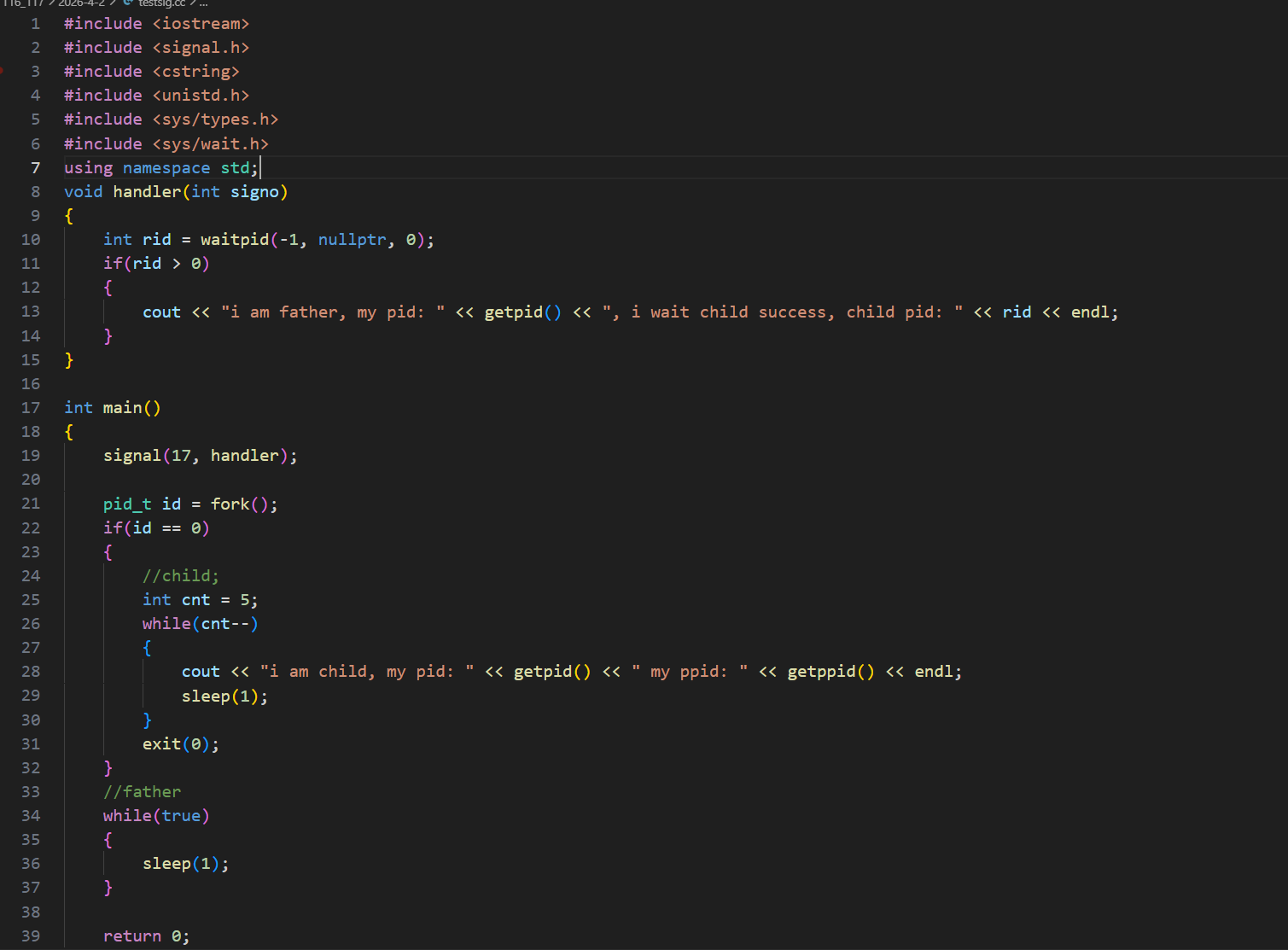
此时父进程就可以做自己的事情,基于子进程发送17号信号,父进程捕获17号信号,handler方法再对子进程进行回收
五、总结
本文深入解析了Linux系统中用户态与内核态的进程地址空间管理机制。32位x86 Linux系统中,每个进程拥有4GB虚拟地址空间,其中0-3GB为用户空间(私有),3-4GB为内核空间(共享)。文章详细阐述了权限控制原理(CPL/DPL)、状态切换机制(中断/异常/系统调用)以及信号处理流程,重点分析了时钟中断如何周期性触发内核态切换(约10ms一次)。通过实际代码示例,展示了信号处理、可重入函数、volatile关键字应用等核心概念,并解释了子进程退出时发送SIGCHLD信号的工作机制。这些机制共同保障了系统的安全隔离、资源管理和高效运行。
谢谢大家的观看!