目录
[四、上下文窗口(Context Window)](#四、上下文窗口(Context Window))
前言
今天在用使用大模型的时候,提问了AI一个问题:"请根据我们第一次讨论的那个例子继续改进",因此脑子里突然蹦出来一个疑问,**大模型是如何记住之前的对话的,也就是上下文的?**只听说过Attention注意力机制,但是并没有很体系地去深入探讨这个问题。
一、分词机制(Tokenization)
要理解大模型的上下文机制,我们首先需要了解一个基础概念 :Tokenization(分词)。
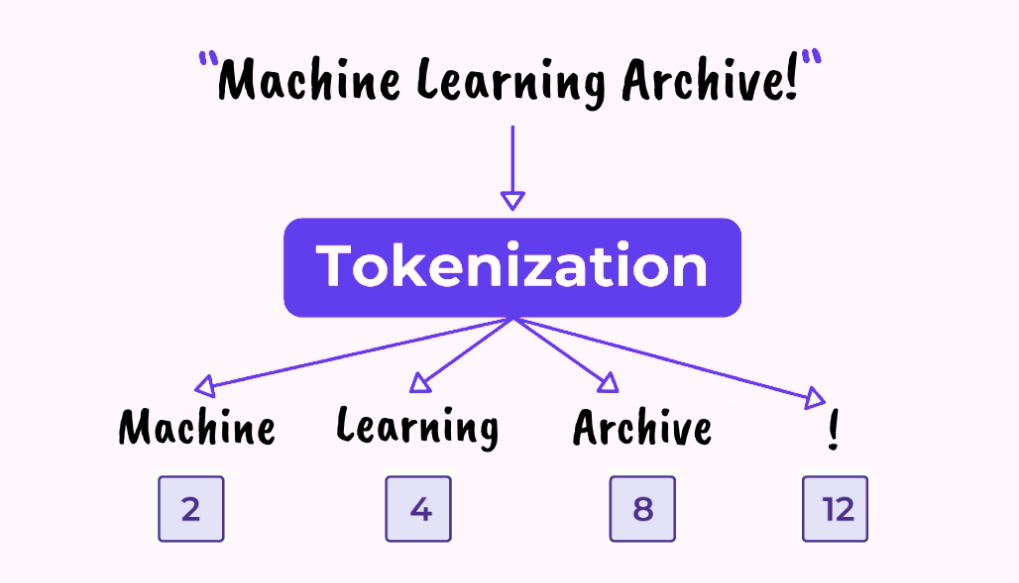
大模型本质上是一个数学函数,它的输入和输出都是数字。要让模型处理人类的语言,第一步就是将文字转换为数字。这个过程就是 Tokenization。
简单来说,Tokenization 就是把一段文本切分成一个个"小砖块"。英文中,一个 token 可能是一个单词,也可能是一个词根,比如 "running" 可能被切分成 "run" 和 "##ning"。中文则通常以字符或词组为单位进行切分。例如,"今天天气真好" 可能被切分为 "今天", "天气", "真", "好" 这样的 token。
每个 token 都会被分配一个唯一的数字 ID。比如 "今天" 可能对应数字 256,"天气" 对应 1024,以此类推。这样一来,一段文字就变成了一串数字序列------这正是神经网络能够处理的格式。
二、嵌入向量(Embedding)
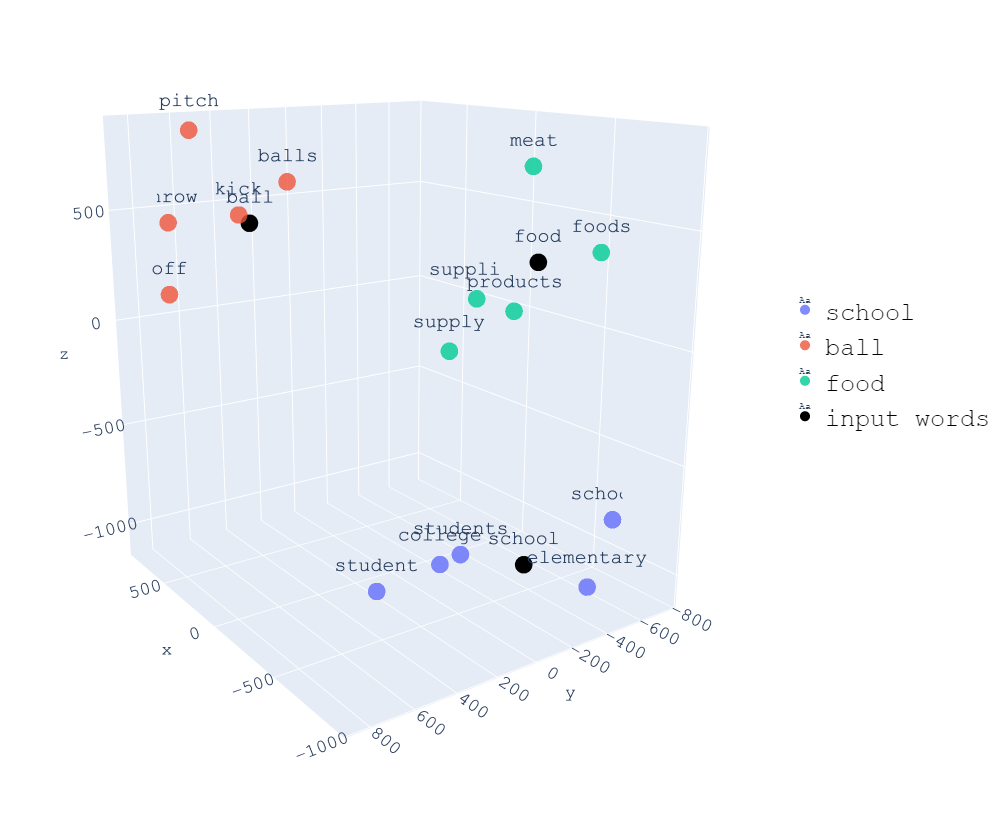
将文本进行分词之后,仅仅将每个词转换成了数字ID,而数字ID本身是不包含语义的,"狗"和"猫"的 ID 可能分别是 256 和 1024,但这并不意味着它们有任何联系。
嵌入的核心思想是:为每个 token 学习一个向量,这个向量不是随机分配的,而是通过大量的文本训练,让具有相似语义或用法的词语拥有相似的向量表示。
想象一个三维空间:如果我们把"狗"定位在 (1.2, 0.8, -0.3) 这个坐标点,那么"猫"可能就在附近的 (1.1, 0.9, -0.2),因为它们都是动物,都是宠物。而"汽车"的位置可能就在远离它们的地方,比如 (0.1, -0.5, 0.9)。
总之只要记住一句话:语义相近的词,在向量空间中距离更近。
三、注意力机制(Attention)
现在我们有了数字化的文本表示,接下来就是最关键的部分:大模型是如何理解上下文关系的?
答案是 Attention 机制(注意力机制),这是 Transformer 架构的核心创新。
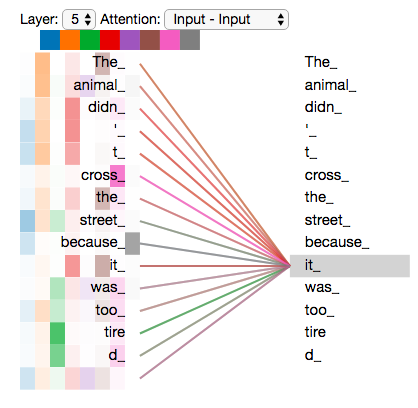
让我们用一个直观的例子来说明。考虑这句话:"他的新书销量很好,因为内容很精彩。"
假设我们想要理解"精彩"这个词的意思。人类会自然而然地注意到"新书"、"销量"、"内容"这些相关词汇,从而理解"精彩"是指书的内容质量高。但对于传统的序列模型(如 RNN)来说,它必须按照顺序从左到右处理每个词,很难有效地捕捉这种跨越距离的依赖关系。
注意力机制则完全不同。它允许模型在处理任何一个词时,同时关注句子中的所有其他词,并根据它们的相关性动态调整权重。
举例来说,注意力机制会计算每对词之间的相关性分数。对于"精彩"这个词,它与"新书"和"内容"的相关性很高(因为它们描述的是同一本书),而与"他的"或"销量"的相关性较低。
正是这种机制,让大模型能够在处理长文本时,记住并利用之前的上下文信息。无论是你开头提到的一个例子,还是几段对话前的某个细节,只要它们与当前任务相关,注意力机制就能让模型看到它们。
四、上下文窗口(Context Window)
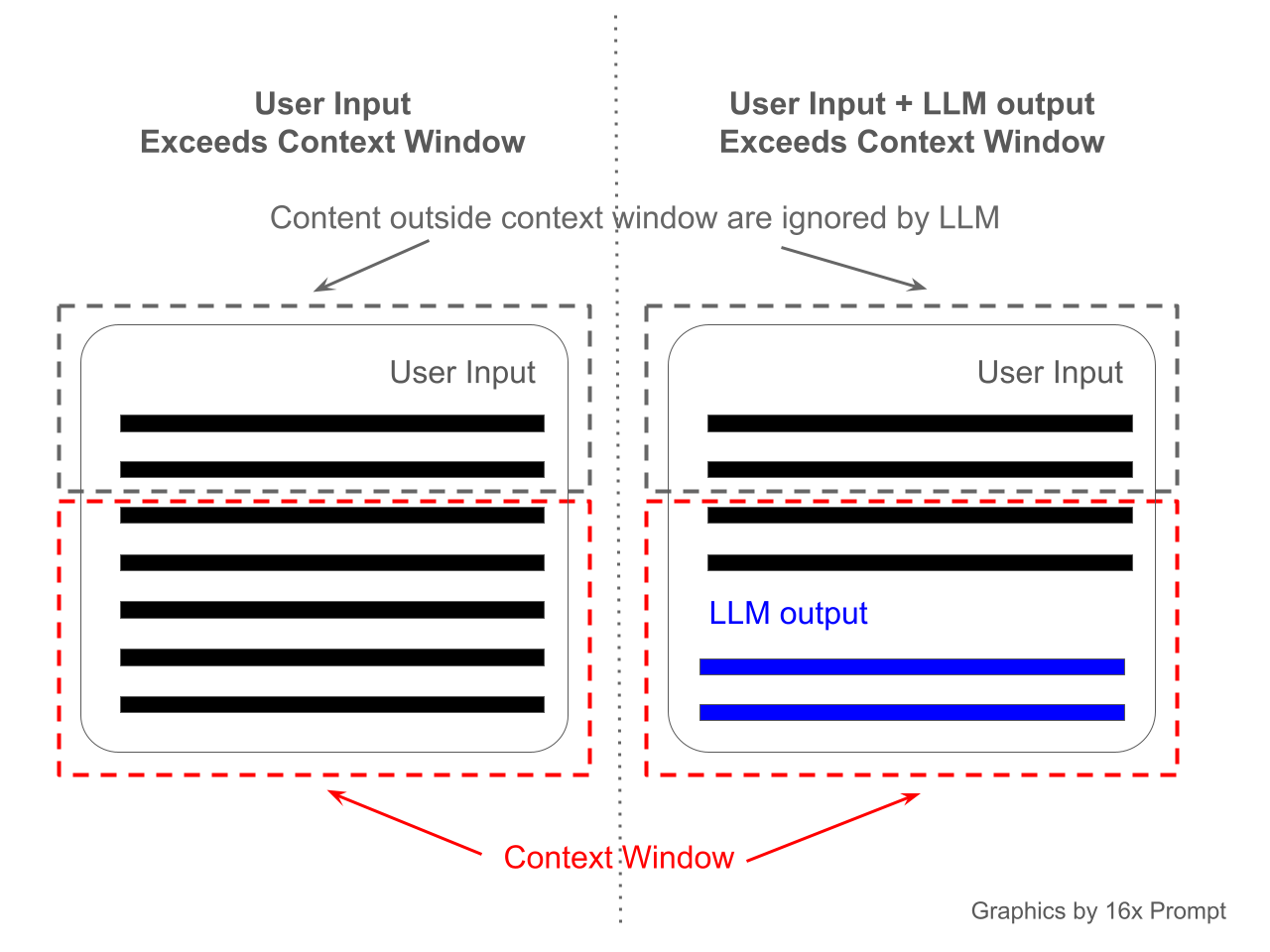
理解了注意力机制的工作原理后,你可能会觉得大模型的记忆能力应该是无限的。但事实并非如此,这里就引出了另一个关键概念:上下文窗口(Context Window)。
上下文窗口指的是模型在单次推理时能够处理的最大 token 数量。这个数字因模型而异:从最早的 GPT-2 的 1024 个 token(约 750 个英文单词),到 GPT-4 的 128k tokens,再到一些最新模型的百万级 token,差距巨大。
但无论多大,上下文窗口终究是有限的 。这意味着模型无法记住超出窗口范围的内容。当对话长度超过窗口限制时,早期的内容就会被挤出记忆空间。
常用的三种对话历史管理技术
- 第一种是截断策略:直接丢弃最早的部分对话,只保留最近的内容。这种方法简单直接,但可能导致重要信息的丢失。
- 第二种是摘要策略:使用额外的 AI 模型对历史对话进行摘要压缩,保留关键信息的同时减少 token 数量。
- 第三种是滑动窗口:始终保持最近的 N 个 token 作为上下文,随着对话进行,不断滑动丢弃最早的内容。
五、对话场景
让我们更具体地看看在对话场景中,大模型是如何利用上下文的。
当你发送一条新消息时,系统通常会将以下内容组合成一个输入:系统提示、完整的对话历史、以及你的新问题。
这个组合会被转换为 token 序列,通过嵌入层转换为向量,然后由 Transformer 模型处理。模型利用注意力机制,同时考虑对话历史和当前问题,生成合适的回复。
值得注意的是,模型并没有一个专门的记忆模块存储对话内容。对上下文的记忆完全来自于输入序列本身------它只是在当前处理过程中,暂时性地看到了这些历史信息。
这与人类记忆有着本质区别。人类会将信息存储在神经元之间的连接中,形成长期记忆;而大模型并没有持久存储对话内容的能力,它的记忆是瞬时的、基于当前上下文的。