本章我们将循序渐进,先梳理AI的发展脉络,再拆解大模型应用开发的核心技术,帮大家从基础到实战,全面掌握大模型相关知识,轻松入门大模型应用开发。
1. 人工智能的发展
AI,即人工智能(Artificial Intelligence),是一门致力于让机器模拟人类思维、学习能力与问题解决能力的前沿技术,核心是让非生命载体拥有"类人智能"。
自人类文明萌芽以来,"造物赋智"就一直是人类的美好愿景------渴望赋予非生命物体思考、判断的能力。尽管AI在近几年才成为全球关注的焦点,成为科技领域的"流量密码",但其思想的种子,早在20世纪50年代就已正式埋下,开启了长达数十年的探索之路。
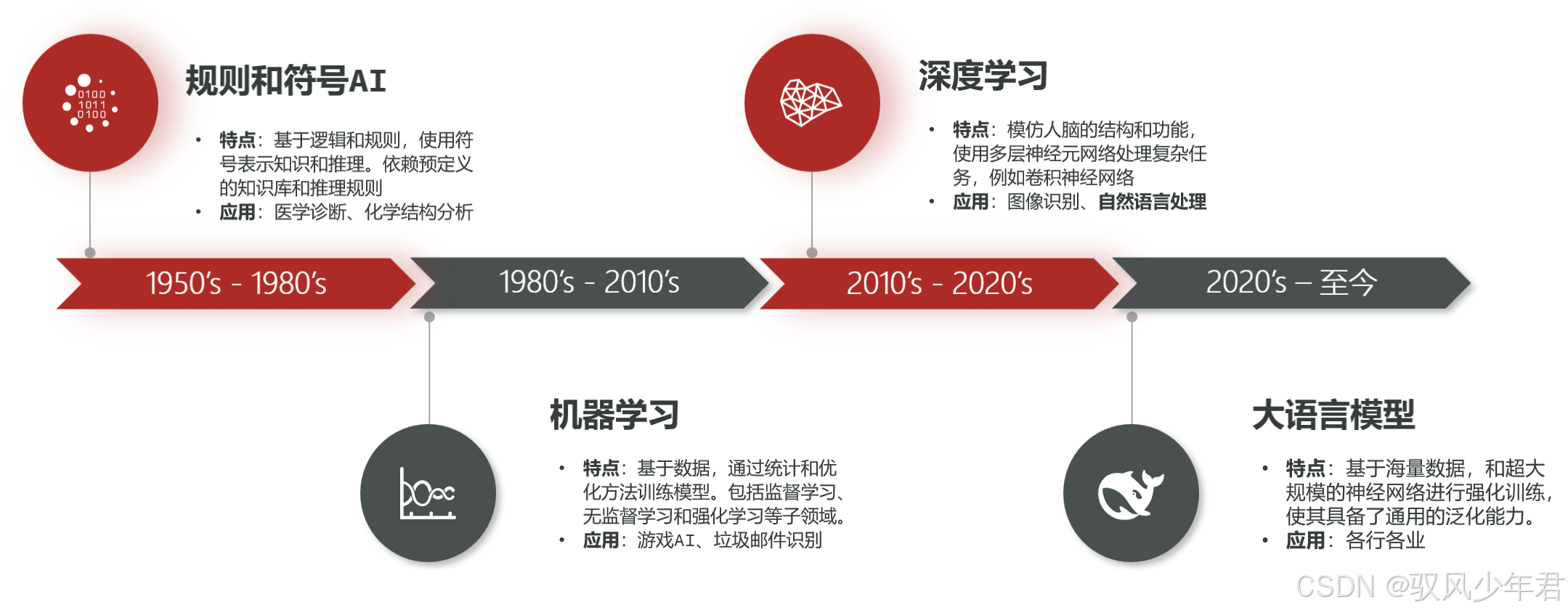
回顾AI的发展历程,可清晰划分为四大浪潮,每一次浪潮都伴随着技术的突破与范式的革新:
-
第一浪潮:规则与符号的探索(20世纪50-70年代)
AI的诞生始于"符号主义"学派,这一阶段的研究者坚信,智能可以通过预设的逻辑规则和符号体系来复刻。他们用形式化的符号表示知识,再通过严密的推理规则进行推导,让机器完成特定任务。但现实世界的模糊性、复杂性,远超人工预设规则的覆盖范围,这类AI最终只能局限在象棋对弈、定理证明等封闭的专业领域,无法走进真实的生活场景,逐渐陷入发展瓶颈。
-
第二浪潮:统计与学习的兴起(20世纪80年代)
随着符号主义的局限日益凸显,AI发展迎来关键转折------从"符号主义"正式迈入"联结主义",机器学习成为推动AI发展的新引擎。这一阶段的核心变化的是:研究者不再费力编写所有规则,而是让机器从海量数据中自主发现规律、总结模式。这种范式转换,让AI从封闭的规则库走向开放的真实数据,奠定了现代AI的基础,也让AI在垃圾邮件过滤、简单推荐系统等场景中初露锋芒,逐渐摆脱"实验室产物"的标签。
-
第三浪潮:深度神经网络的突破(21世纪初)
进入21世纪,海量数据的爆发、GPU等高性能计算硬件的普及,为AI发展注入了新的动力。深度学习------这一基于深层神经网络的机器学习分支,将AI推向了新的高潮。深度网络能够自动提取数据的多层次抽象特征,在图像识别、语音理解、自然语言处理等领域,精度远超传统方法。它的成功,标志着AI在感知类任务上的能力首次接近乃至超越人类水平,也催生了人脸识别、智能语音助手、自动驾驶辅助等我们如今习以为常的应用。
-
第四浪潮:大模型与生成式AI的革命(2020年代至今)
真正让AI走进大众生活、引发全民普及风暴的,是2020年代大语言模型(简称"大模型")的崛起。这一次,技术变革的焦点从"专用型"感知智能,转向了"通用型"认知智能。借助简单的自然语言对话,任何人都能指挥AI完成写作、编程、数据分析、创意生成等复杂任务,彻底降低了AI的使用门槛。大模型不再是实验室的成果、新闻中的概念,而是成为普通人日常工作、生活中触手可及的智能伙伴,从根本上重塑了生产力与创造力模式,标志着AI真正融入人类社会结构的核心。
看到这里,很多人都会有一个疑问:这个看似无所不能的大模型,它的"大脑"里究竟在发生什么?它的"智能"到底从何而来?接下来,我们就拆解大模型智能产生的核心要素。
2. 智能产生的要素
2022年,GPT-3刚发布时,其智商水平大约相当于7岁儿童;而短短几年时间,如今最先进的大模型,智商已接近20岁成年人,甚至在部分专业领域(如代码编写、数据分析)的表现超过人类。
大模型的"智能"之所以能实现爆发式增长,核心离不开三大要素,这也是大模型具备智能的三大支柱,更是长期制约AI发展的"三座大山"------直到近十多年,这三者同时跨过技术临界点,AI的能力才真正得以显现。
影响大模型智能的核心三要素:
-
模型算法(AI的"大脑架构")
-
海量数据(AI的"学习素材")
-
超级算力(AI的"运行动力")
2.1 模型算法
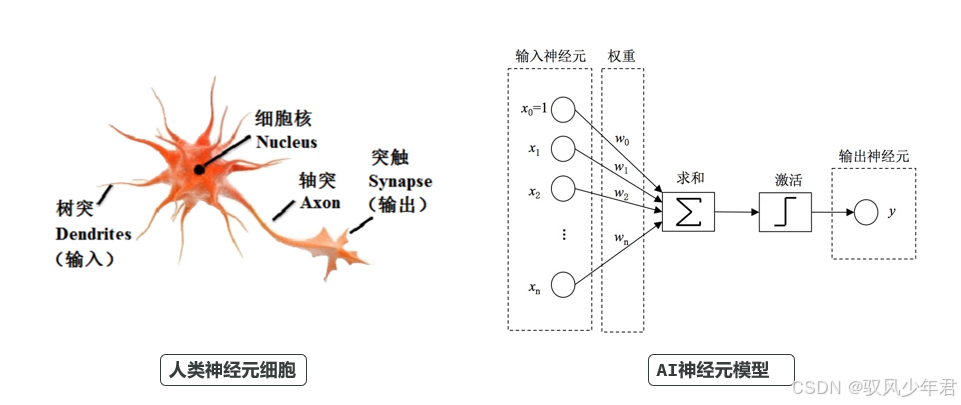
模型算法是大模型的"大脑架构",决定了AI的"聪明程度",也是大模型实现智能的基础。如今所有主流AI,都采用神经网络架构,而这一架构的核心,就是模拟人类大脑的神经元工作模式。
人类的大脑由数十亿个神经元细胞构成,神经元之间通过突触连接,传递信号、处理信息;AI神经网络的本质,就是对人类大脑神经元的模拟:
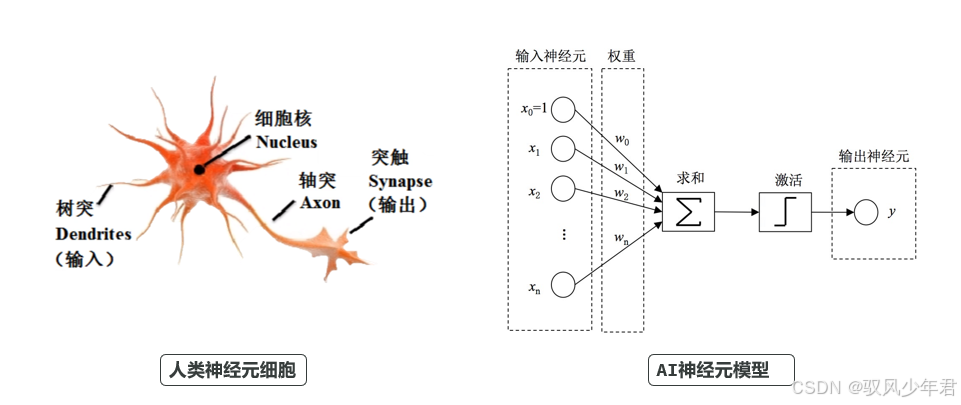
AI的神经元与人类神经元类似,会接收多个不同的输入信号(用x表示),经过加权求和得到初步结果,再通过激活函数处理,最终生成输出结果。但在早期,激活函数较为简单,AI只能完成简单的二分类任务,比如根据照片判断性别、根据输入判断真假,能力非常有限。
最早的神经网络可追溯到1958年,弗兰克·罗森布拉特(Frank Rosenblatt)发明了人类历史上第一个神经网络机器------感知机(Perceptrons)。

不过,早期的感知机结构极其简单,只有一个神经元,只能实现简单的二分类判断(例如根据照片区分性别),无法处理复杂的任务,这也导致神经网络的发展在随后一段时间陷入停滞。
近20年来,神经网络算法不断迭代、优化、升级:最初的神经网络多采用前馈神经网络,受限于算法设计,其理解人类语言时的上下文窗口非常有限,通常只能处理5~10个词,无法理解长文本的逻辑关系;而如今主流的Transformer神经网络模型,凭借优良的算法设计,能够并行处理大量数据,上下文窗口可达到100K级别,这也是大模型能精准理解人类语言、段落逻辑的核心原因。
当然,算法只是大模型智能的"基础",再完善的算法,没有足够的学习素材和运行动力,也无法产生真正的智能。接下来,我们看看另外两大核心要素------数据和算力。
2.2 海量数据
如果说模型算法是AI的"大脑",那么海量数据就是AI的"学习素材"。就像再聪明的人,不学习任何知识、不接触任何信息,也无法产生智慧;AI要实现智能,同样需要通过海量数据的训练,积累足够的"知识"。
上个世纪,互联网尚未普及,数据的产生、存储、传播都非常有限,能够用于AI训练的数据更是稀缺,这也直接限制了AI的发展------没有足够的学习素材,再完善的算法也无法发挥作用。
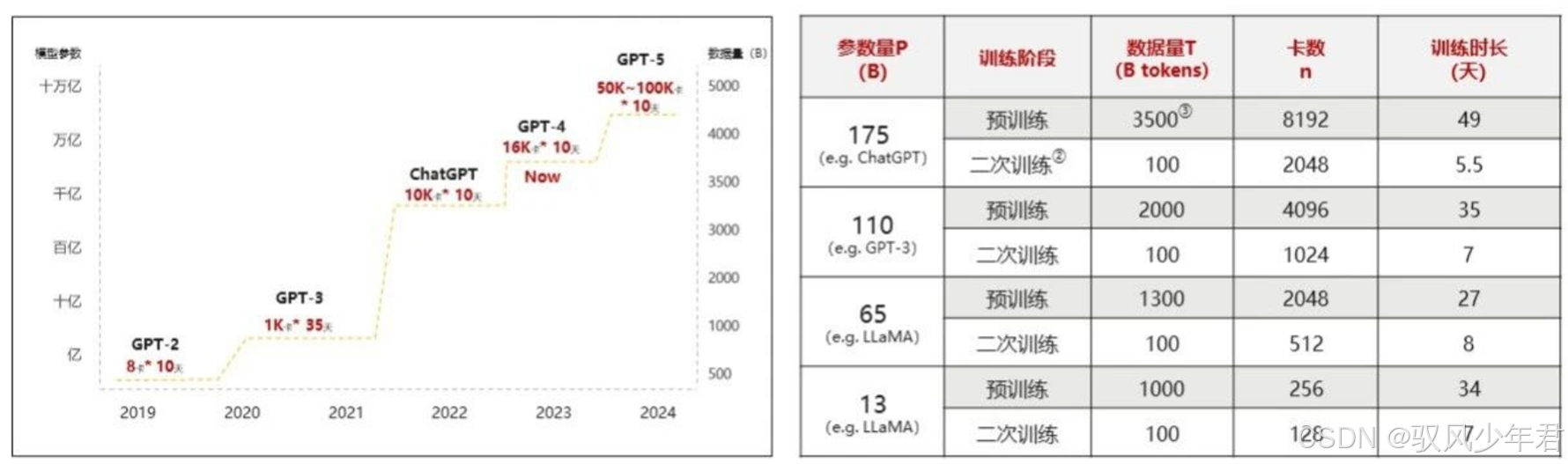
而进入现代,随着互联网、移动互联网的蓬勃发展,数据呈井喷式增长:文字、图片、视频、代码等各类数据无处不在,AI可以学习整个互联网的精华------所有的维基百科词条、无数的新闻文章、海量的书籍文献、庞大的代码仓库......这些训练数据的规模,是以万亿级词汇来计算的,为大模型的训练提供了坚实的"知识基础"。
如图所示,随着AI大模型规模的扩大,其训练所需的时长和数据量也呈指数级增长:
2.3 超级算力
超级算力是大模型的"运行动力",也是支撑大模型训练的核心保障。大模型的训练,需要处理海量数据、运行复杂的神经网络算法,其计算量堪称天文数字------通常需要成千上万的顶级GPU协同工作,不间断运行数周甚至数月,这背后不仅需要庞大的硬件投入,还需要巨大的电力消耗。
如图所示,模型训练所需的算力,已经完全超出了摩尔定律的预估,几乎每隔几个月就会翻倍增长:
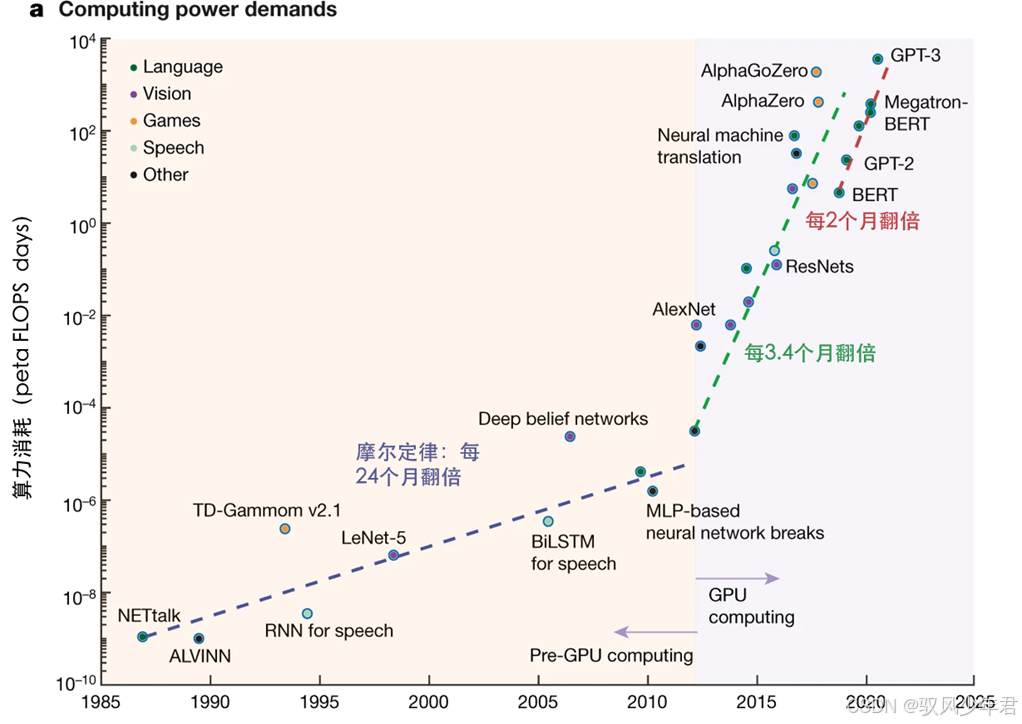
这样规模的算力消耗,在上个世纪甚至本世纪初期,都是难以想象的。直到近几年,随着GPU技术的不断突破,算力规模才勉强满足大模型的训练需求,也为大模型的爆发式发展提供了可能。
总结来说,模型算法、海量数据、超级算力,三者缺一不可,共同构成了大模型智能的核心支柱。只有当这三者同时达到一定水平,大模型才能真正产生"类人智能"。
3. 大模型原理
通过前面的分析,我们已经知道,大模型产生智能的三要素是算法、数据、算力。但很多人可能会好奇:本质上来说,AI的智能都是基于各种数学计算产生的,那么大模型究竟是如何通过训练,理解人类语言、完成复杂任务的?人类的语言,又是如何转化为数学计算的?
3.1 模型的训练
前面我们提到,AI的神经网络模型,本质是对人类神经元的模拟:
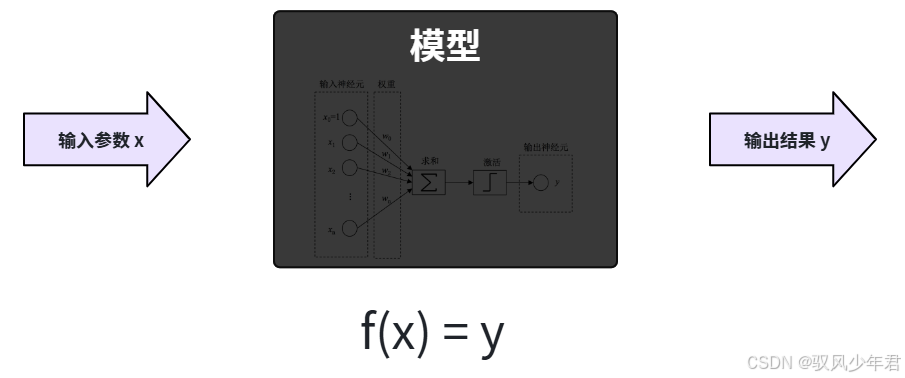
你给它输入一些参数,它经过一系列数学计算,最终返回一个结果。因此,从某种意义上来说,你可以把大模型看作是一个极其复杂的"函数"。
这就像我们初中学习的一次函数:y = ax + b,这个函数有两个参数(a和b),当a和b的数值确定时,这个函数就能表示一条固定的直线;输入一个x的值,就能得到一个对应的y值。
当然,大模型这个"函数",要比一次函数复杂得多------它的参数不是2个,而是千亿甚至万亿规模:
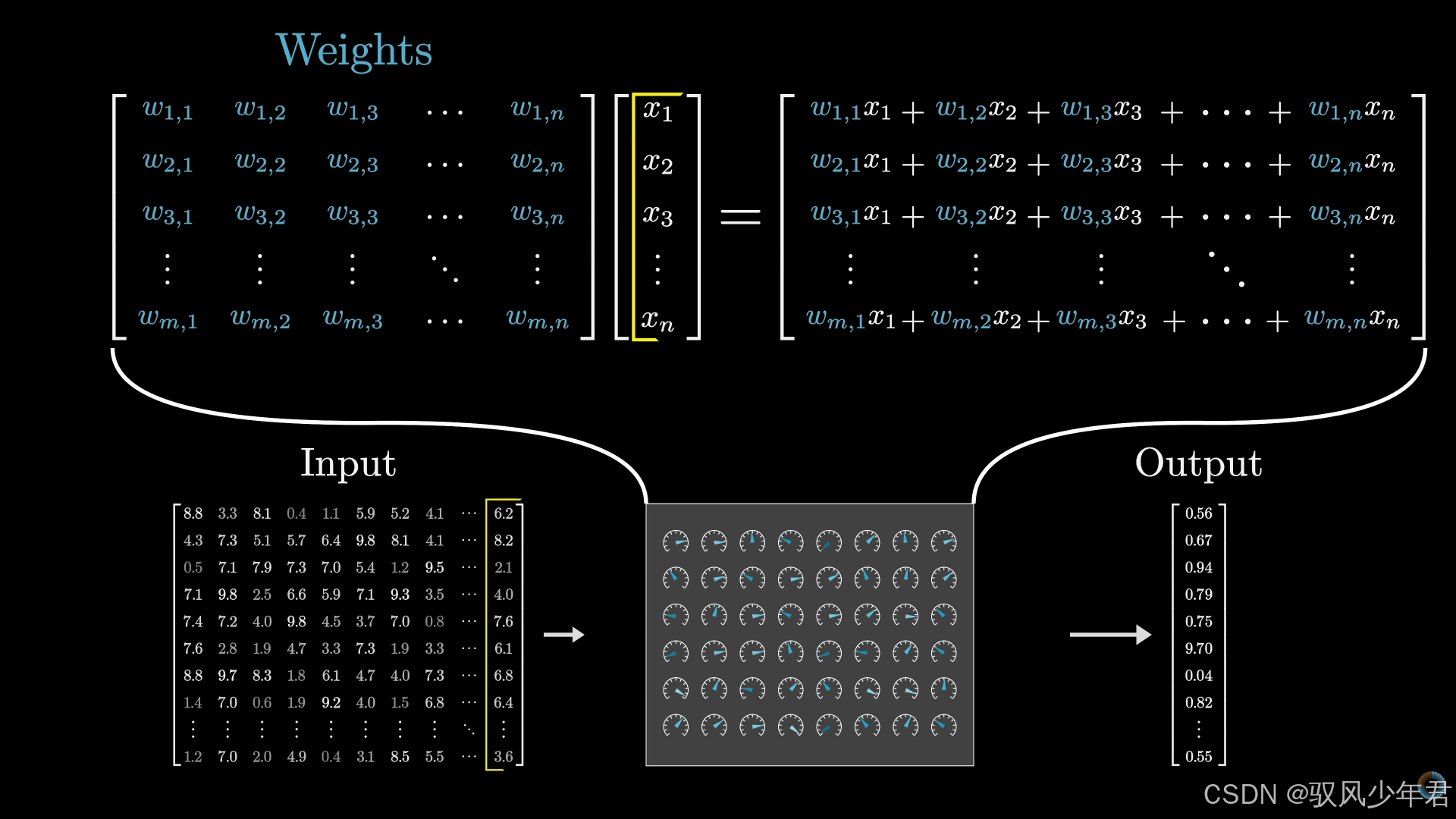
因此,它表示的不是一条简单的直线,而是人类复杂的语言系统、知识体系,能够处理各种复杂的输入(文字、图片等),输出符合逻辑、贴合需求的结果。
模型训练的过程,本质上就是"求解模型参数"的过程,和我们求解一次函数参数的逻辑类似:已知直线上两个点的坐标,就能求出a和b的值;而大模型的训练,就是通过海量训练数据,求出模型中千亿级参数的最优值。
不过,大模型的"函数"太过复杂,参数规模高达数千亿,模拟的也不是简单的直线,它需要的"训练数据(相当于直线上的点)"也是天文数字,因此根本不可能精确计算出每一个参数的值。
所以,大模型的训练,更像是一个"不断试错、不断调整"的猜答案过程,具体步骤如下:
-
第一步:给模型的所有参数设定一个随机值,相当于"先猜一个答案";
-
第二步:输入一组训练数据(相当于"已知条件"),让模型进行计算,得到一个输出结果;
-
第三步:将模型的计算结果,与预期的正确结果进行对比,判断误差大小;
-
第四步:如果误差较大,就根据误差情况,调整模型的参数;重复第二步到第四步,直到模型的计算结果,能够与大多数训练数据吻合,此时模型的训练就完成了。
这里的输入参数和预期结果,就是我们所说的"训练数据"(相当于直线上的"点")。大语言模型的训练,就是拿海量的人类语言文字作为训练数据,不断调整模型参数,让模型的输出能够贴合人类的语言习惯、逻辑规则,实现对人类语言的理解和生成。
但新的问题又来了:人类的语言文字是抽象的,它如何转化为可计算的数学数据,参与模型的训练呢?这就需要用到"词向量"技术。
3.2 大语言模型
2003年,图灵奖得主约书亚·本吉奥(Yoshua Bengio)发表了一篇名为《A neural probabilistic language model》的论文,这篇论文开创了神经网络语言模型(Neural Network Language Model,NNLM)的先河,也首次提出了"词向量(Word Embedding)"的概念雏形------这一概念,为神经网络训练、学习自然语言,打下了坚实的基础。
词向量的核心逻辑,就是将抽象的语言文字,转化为可计算的多维向量(也就是一个浮点数数组),具体来说:
-
每个词语,都可以通过模型运算,转化为一个多维向量(例如GPT-3采用的是12288维向量);
-
通过训练,让模型计算出的多维向量,与文字的语义产生关联------多维空间中的不同方向、不同距离,对应不同的语义,语义越相近的词语,它们的向量距离就越近。
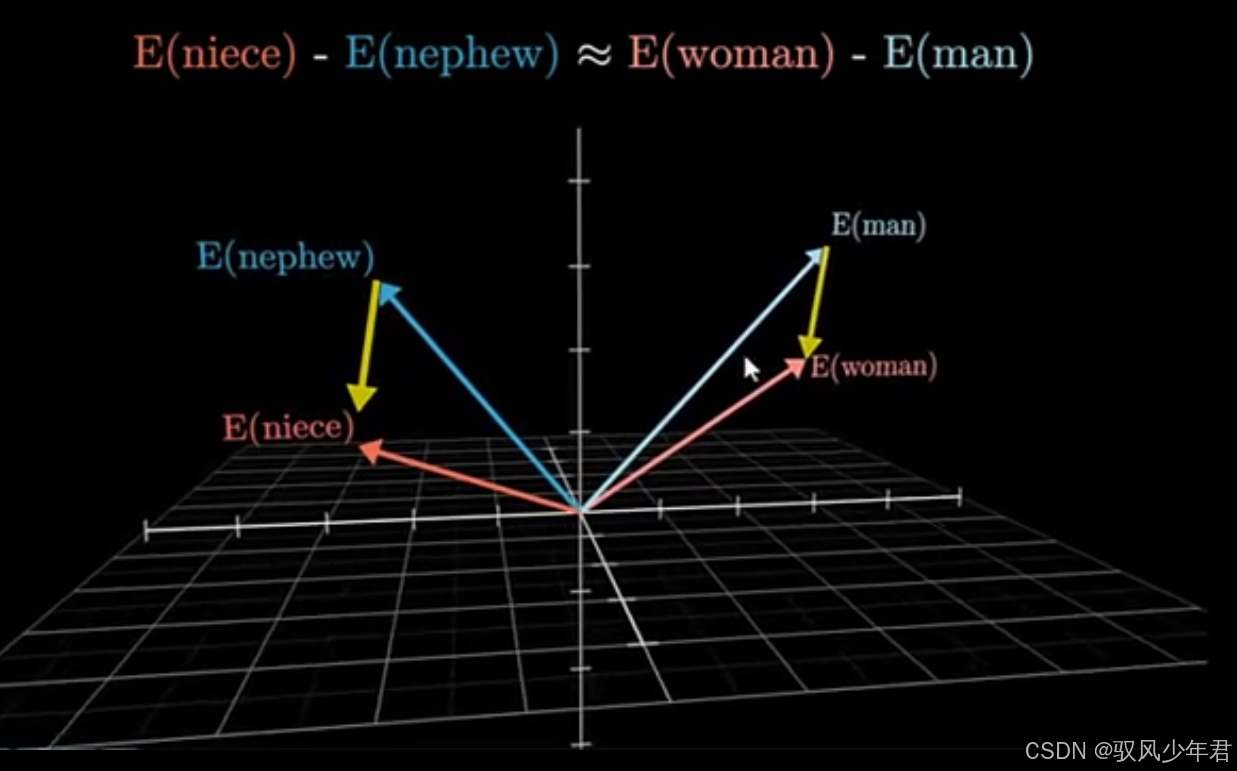
举个简单的例子,在经过训练后的向量空间中,"中国"和"美国"这两个词语,会对应两个不同的向量(用E(中国)、E(美国)表示):
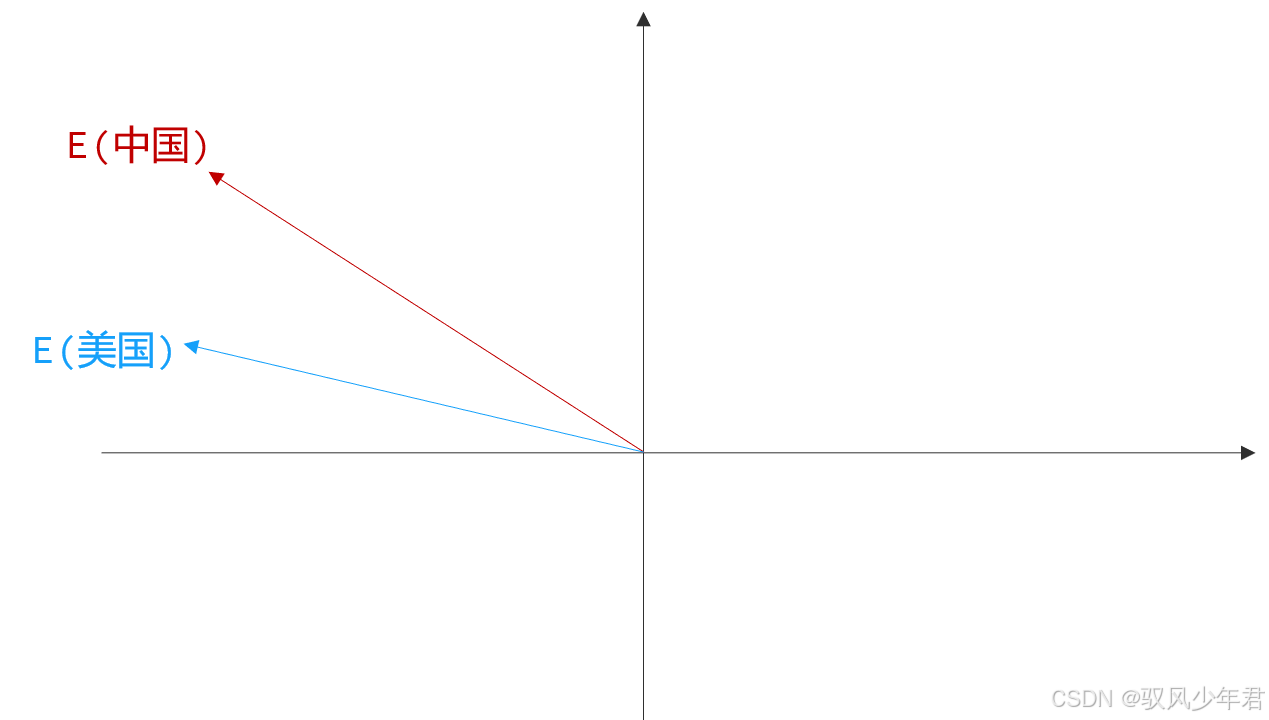
此时,我们用E(美国) - E(中国) 得到的新向量,就可以表示"美国与中国的差异"(比如地域、文化、语言等方面的差异)。
如果我们询问大模型:"中国有什么食物与美国的汉堡类似?",大模型的计算逻辑就可以简化为:
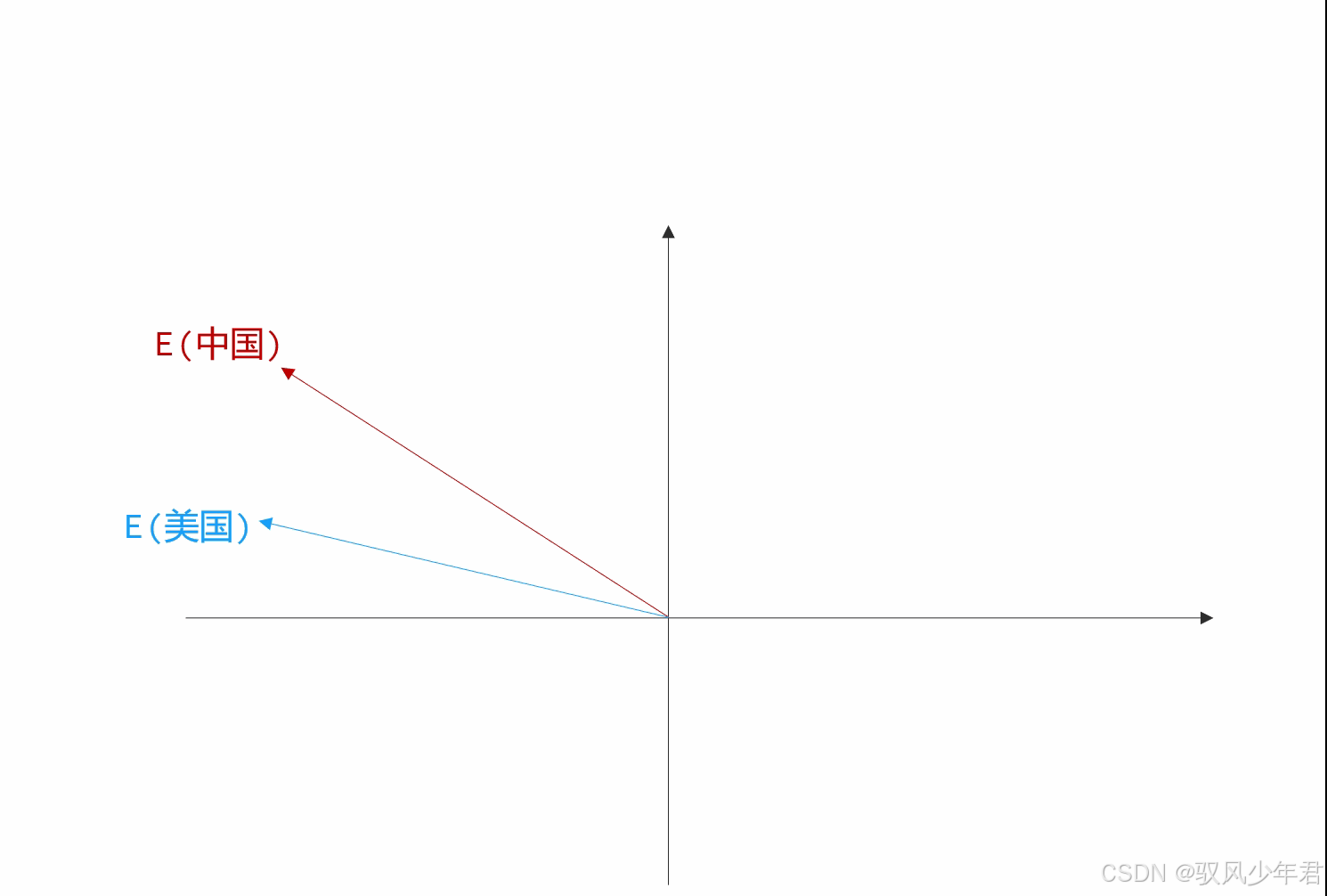
-
第一步:找到表示"汉堡"的向量:E(汉堡);
-
第二步:加上表示"美国与中国差异"的向量:E(美国) - E(中国);
-
第三步:计算得到新向量:E(汉堡) + E(美国) - E(中国);
-
第四步:将得到的新向量反向量化(unembedding),转化为人类能理解的文字,大概率就是我们想要的答案(比如"肉夹馍")。
当然,真实情况会比这个例子复杂得多:大模型的计算会受到语句上下文、多义词、语义歧义等因素的影响,运算后可能会得到多个结果,并且会根据每个结果的可能性,形成概率分布,再通过特定的函数算法,选择一个最优结果输出。
综上,大语言模型的核心逻辑,就是将人类语言转化为可计算的多维向量坐标,然后根据上文的向量计算,推测下文的内容,实现对语言的理解和生成:
更神奇的是,人类最初训练语言模型,只是为了让它理解人类语言、完成翻译等简单任务。但当模型规模和训练数据量足够大时,它不仅能够理解和生成自然语言,还能实现推理、分析、创作等复杂能力,成为可应用于各个领域的通用人工智能(AGI)。
这种"随着数据和模型规模扩大,而涌现出各类新能力"的现象,我们称之为"泛化";而具备这种泛化能力的大规模语言模型,就是我们常说的大语言模型(Large Language Model),简称LLM。
如果大家想要进一步搞清楚大模型的原理,可以参考以下两个视频,讲解更直观、更细致:
【90分钟!清华博士带你一口气搞懂人工智能和神经网络】 https://www.bilibili.com/video/BV1atCRYsE7x/?share_source=copy_web\&vd_source=6cbf1743620562cda2be61462432b8f3
https://youtu.be/wjZofJX0v4M?si=KdMSidvs1UjY6-xW
4. 大模型应用
了解了大模型的原理和核心要素后,我们再来聊聊大家最关心的"大模型应用"------什么是大模型应用?它和大模型本身有什么区别?我们日常使用的AI产品,哪些属于大模型应用?
4.1 什么是大模型应用
要理解大模型应用,我们可以先对比"传统应用"与"大模型"的能力边界,看看两者的优劣势分别是什么:
-
传统应用:由程序员编写固定规则(编程),计算机严格按照规则执行任务。
-
擅长:规则清晰、流程固定的事情(如转账、下单);能够确保100%准确;行为可控、可追溯,安全性高。
-
不擅长:没有明确规则的事情;自然语言的理解(如"给我推荐清淡的菜");模糊的判断和表达(如"帮我写一段有温度的文案")。
-
大模型:通过海量数据训练,自主学会规律和知识,无需程序员编写所有规则。
-
擅长:理解和生成自然语言;处理模糊问题的合理回答;总结、改写、对话、创意生成等需要"思考"的任务。
-
不擅长:精确的计算(如复杂数学题);固定的流程和规则(如转账操作);稳定可预测的结果(如财务记账)。
而大模型应用,核心就是"扬长避短"------把传统应用和大模型的能力结合起来,让大模型负责"思考"(理解用户意图、处理模糊需求),让传统程序负责"行动"(执行固定流程、保障准确安全),两者强强联合,实现更优质的产品体验。
举个大家熟悉的"点外卖"例子,我们可以清晰地看到两者的结合:
-
菜价展示、优惠计算、支付操作 → 传统程序(规则固定、要求精准);
-
"给我推荐点清淡的""想吃不辣的家常菜" → 大模型(理解模糊需求、匹配合适菜品);
-
最终下单、扣钱、生成订单 → 传统程序(流程固定、保障安全)。
简单来说,大模型应用开发的真谛,就是在传统应用开发中融入AI大模型,充分利用两者的优势:既能通过AI实现更便捷的人机交互,更好地理解用户的模糊意图;又能通过传统编程,保障应用的安全性、准确性和稳定性。
我们日常接触的很多AI产品,其实都是大模型应用,而非大模型本身------比如通义千问、豆包这样的APP或聊天机器人,其背后的逻辑的也是"大模型+传统程序"的结合:
-
收集用户输入的文本、上传的文件/图片 → 传统程序(数据采集、存储);
-
分析和理解用户输入的问题 → 大模型(思考、推理);
-
联网搜索与问题相关的资料 → 传统程序(接口调用、数据抓取);
-
根据资料生成答案 → 大模型(内容生成)。
这里需要特别区分一点:大模型本身,只具备理解、推理、生成回复的核心能力;而我们平常使用的AI对话产品,除了这些核心能力,还有会话记忆、联网、文件上传、历史记录保存等功能------这些功能都不是大模型本身具备的,而是需要通过额外的传统程序开发实现的,这就是"基于大模型开发应用"的核心意义。
4.2 常见的大模型
为了让大家更清晰地区分"大模型"与"大模型应用",下面我将常见的大模型、对应的对话产品、所属公司及官方地址,整理成表格,方便大家查阅:
| 大模型 | 对话产品 | 公司 | 地址 |
|---|---|---|---|
| GPT-3.5、GPT-4o | ChatGPT | OpenAI | https://chatgpt.com/ |
| Claude 3.5 | Claude AI | Anthropic | https://claude.ai/chats |
| DeepSeek-R1 | DeepSeek | 深度求索 | https://www.deepseek.com/ |
| 文心大模型3.5 | 文心一言 | 百度 | https://yiyan.baidu.com/ |
| 星火3.5 | 讯飞星火 | 科大讯飞 | https://xinghuo.xfyun.cn/desk |
| Qwen-Max | 通义千问 | 阿里巴巴 | https://tongyi.aliyun.com/qianwen/ |
| Moonshoot | Kimi | 月之暗面 | https://kimi.moonshot.cn/ |
| Yi-Large | 零一万物 | 零一万物 | https://platform.lingyiwanwu.com/ |
4.3 与大模型的交互
既然大模型应用是"传统程序+大模型"的结合,那么传统程序该如何与大模型进行交互,让大模型完成"思考"任务呢?
答案很简单:调用大模型的API接口。
大模型在部署时,通常都会对外暴露基于HTTP协议的API接口------这个接口就相当于"桥梁",传统程序通过调用这个接口,向大模型发送请求(比如用户的问题),大模型处理后,通过接口返回结果(比如问题的答案),从而实现两者的交互:
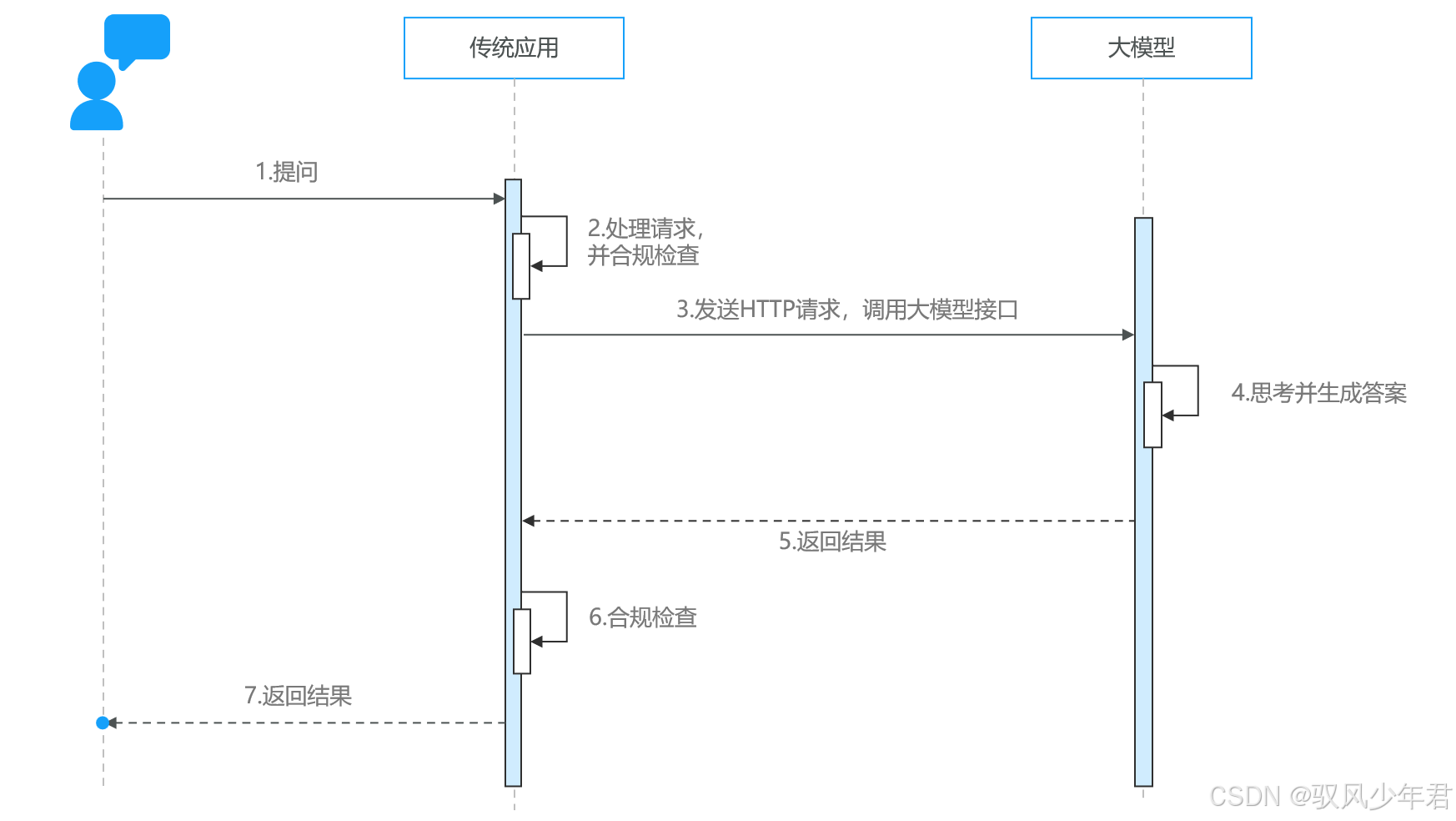
当然,要实现这种交互,首先需要有一个可调用的大模型服务------要么使用第三方开放的大模型服务,要么自己部署私有大模型。接下来,我们就详细讲解大模型服务的相关知识。
5. 大模型服务
再次强调:大模型应用开发,并不是在浏览器中跟AI聊天,而是通过访问大模型对外暴露的API接口,实现传统程序与大模型的交互。因此,企业或开发者要开发大模型应用,首先需要拥有一个可访问的大模型服务,通常有两种选择:使用开放大模型服务,或部署私有大模型。
我们先对比一下两种方式的优缺点,方便大家根据自身需求选择:
-
使用开放大模型API
-
优点:无需自己部署和维护模型,按调用次数收费,初期投入低;上手快,无需具备专业的运维能力。
-
缺点:依赖第三方平台,服务稳定性受平台影响;长期大量调用的话,成本较高;训练数据、用户数据存储在第三方平台,存在隐私和安全风险。
-
部署私有大模型
-
优点:数据完全自主掌控,隐私和安全性高;不依赖外部平台,服务稳定性可控;短期投入大,但长期大量使用的话,成本更低。
-
缺点:初期部署成本高(需要采购高性能硬件、投入人力);后续需要专业人员维护,运维难度大。
接下来,我们分别演示两种部署方式的具体操作:一种是使用公共开放大模型服务(以DeepSeek和阿里云百炼为例),另一种是本地部署私有大模型(以Ollama工具为例)。
通常,发布大模型的官方平台、大多数云平台,都会提供开放的公共大模型服务。前面我们已经介绍过常见的大模型官方平台,这里不再赘述,重点介绍国内几个主流的云平台大模型服务:
| 云平台 | 公司 | 地址 |
|---|---|---|
| DeepSeek | DeepSeek | https://www.deepseek.com |
| 阿里百炼 | 阿里巴巴 | https://bailian.console.aliyun.com |
| 腾讯TI平台 | 腾讯 | https://cloud.tencent.com/product/ti |
| 千帆平台 | 百度 | https://console.bce.baidu.com/qianfan/overview |
| SiliconCloud | 硅基流动 | https://siliconflow.cn/zh-cn/siliconcloud |
| 火山方舟-火山引擎 | 字节跳动 | https://www.volcengine.com/product/ark |
需要注意的是,这些开放平台并不是免费的,而是按照调用时消耗的"token"来付费------token可以简单理解为"你与大模型交互时,发送和接收的文字总量",通常一个汉字约等于2个token,每百万token的费用大概在几毛到几元不等。另外,大多数平台都会给新用户赠送百万级token的免费使用权,足够大家入门学习和测试。
下面,我们分别详细讲解DeepSeek和阿里云百炼平台的使用方法,帮大家快速上手开放大模型服务。
5.1 DeepSeek模型服务
DeepSeek是深度求索公司推出的大模型,其官方平台提供了开放的API服务,操作简单,适合新手入门。
官方平台地址:https://platform.deepseek.com/
5.1.1 注册
首次访问DeepSeek平台,必须先完成注册(支持手机号、邮箱等方式注册),注册流程简单,按照页面提示操作即可:

5.1.2 充值
DeepSeek官方提供的大模型API服务是收费的,因此注册成功后,需要充值少量金额(最低1元即可),用于调用API。
注册成功后,进入平台管理页面,找到"充值"选项,点击进入充值页面:
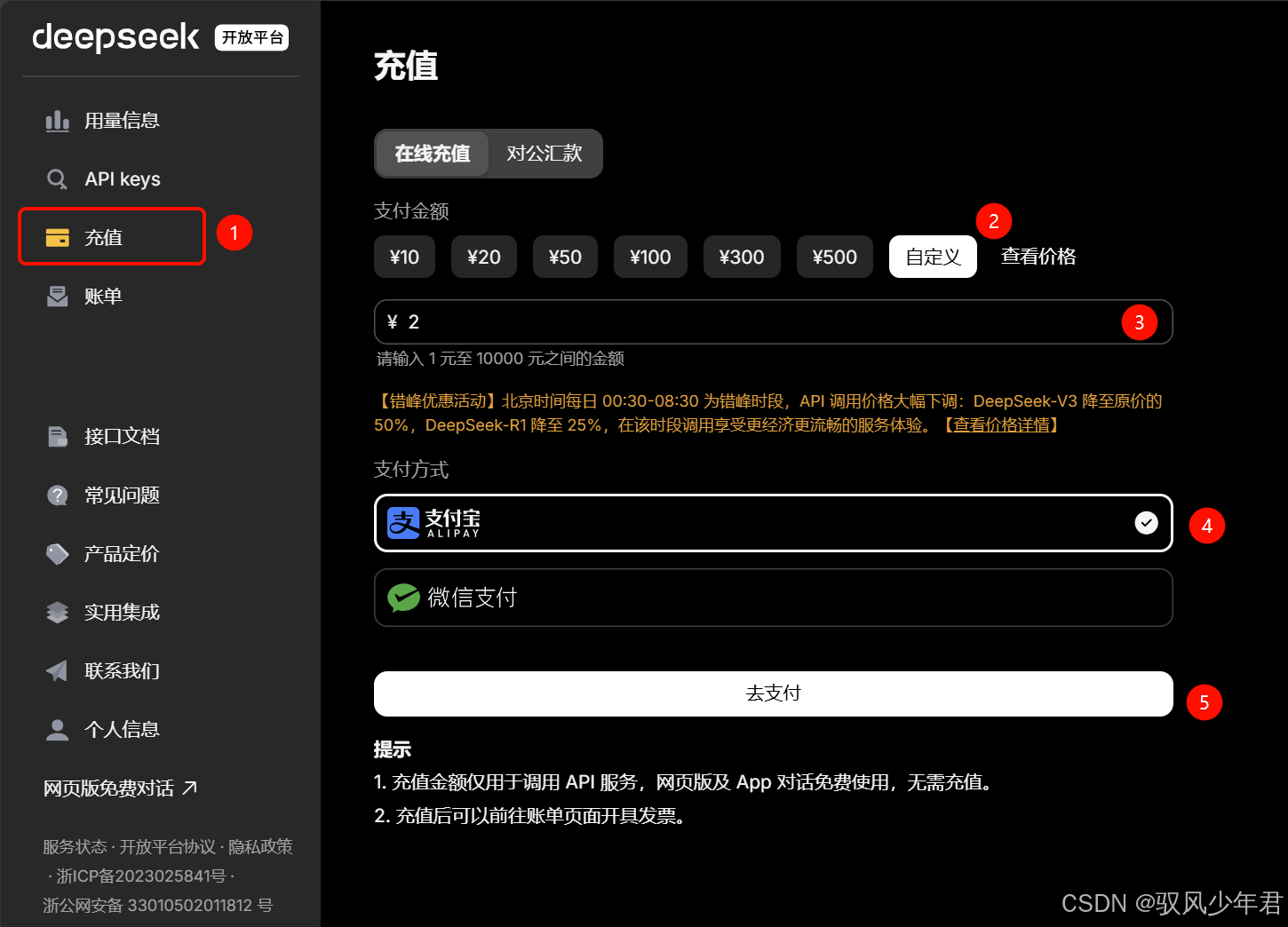
选择合适的充值金额(新手建议先充1~10元,足够测试使用),完成支付后,即可使用DeepSeek的官方API服务。
5.1.3 创建API_KEY
由于是收费服务,为了防止账号被盗用、API被恶意调用,DeepSeek的所有API都有权限校验功能------我们需要创建一个鉴权用的API_KEY,后续调用API时,需要使用这个API_KEY进行身份验证。
操作步骤:点击平台左侧的"API Keys"选项卡,进入API_KEY管理页面。第一次进入时,页面没有API_KEY,点击"创建API key"按钮,即可生成一个新的API_KEY:
重要提醒:API_KEY只有在创建时可以查看,后续无法再次查看,因此创建时一定要妥善保管(比如复制保存到记事本),不要泄露给他人,否则可能会产生不必要的费用。
到这里,使用DeepSeek API服务的准备工作就完成了。
5.1.4 API文档
访问公共大模型,都是通过API的形式,不同平台的API规范略有差异,但基本都兼容OpenAI的规范。学习DeepSeek的官方API文档,了解如何调用其API。
在文档中,有一段调用对话API的示例代码(curl命令),我们可以通过这段代码,快速了解DeepSeek API的调用要求:
python
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'这段代码包含了调用DeepSeek大模型API的核心信息,我们拆解一下:
-
请求URL:https://api.deepseek.com/chat/completions(DeepSeek对话API的接口地址);
-
请求头(Header):
- Content-Type: application/json:表示请求参数的格式是JSON;
- Authorization: Bearer :身份验证信息,将替换成我们刚才创建的API_KEY即可。
-
请求体(Body):JSON格式,包含调用模型的核心参数:
- model:模型名称,DeepSeek支持deepseek-reasoner(推理模型)和deepseek-chat(对话模型)两种;
- messages:发送给大模型的消息数组,里面可以包含多条消息,每条消息包含"role"(角色)和"content"(内容)两个属性;
-
stream:是否流式返回结果,false表示一次性返回完整结果,true表示分批次返回(适合聊天界面实时显示)。
-
请求方式:虽然代码中没有明确说明,但由于包含请求体(Body),因此使用POST方式。
5.1.5 测试
我们可以使用任意HTTP客户端(比如Postman、Apifox,或简单的curl命令),来测试DeepSeek的API是否能正常调用。
操作要点:在HTTP请求的请求头中,添加我们创建的API_KEY,确保身份验证通过;请求体按照文档要求,填写正确的JSON参数:
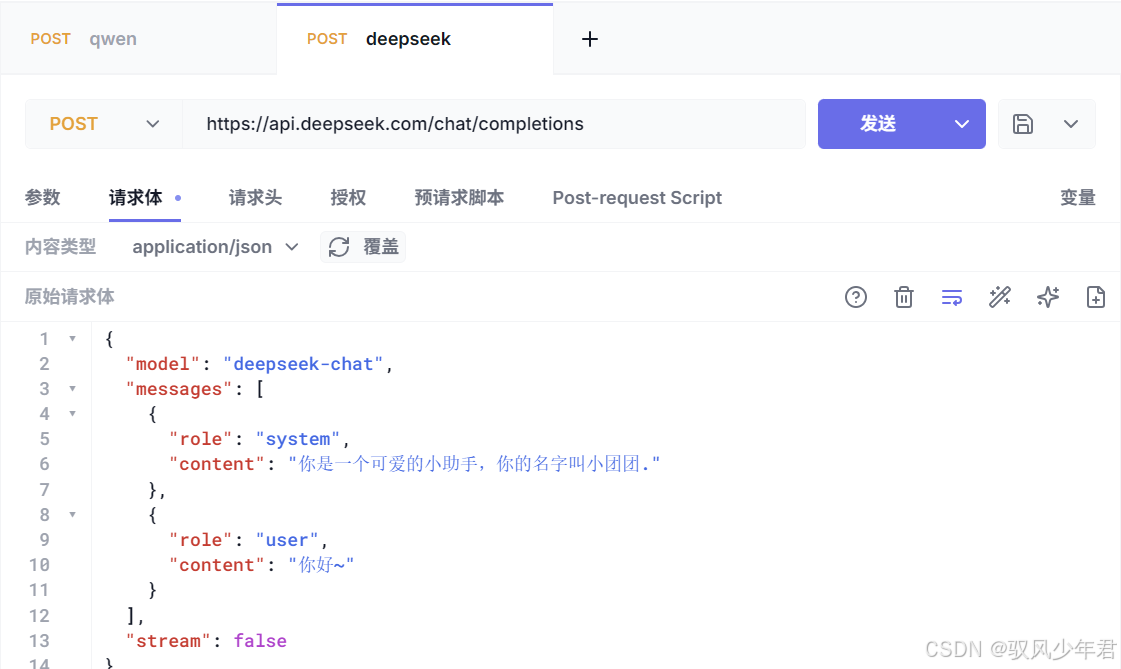
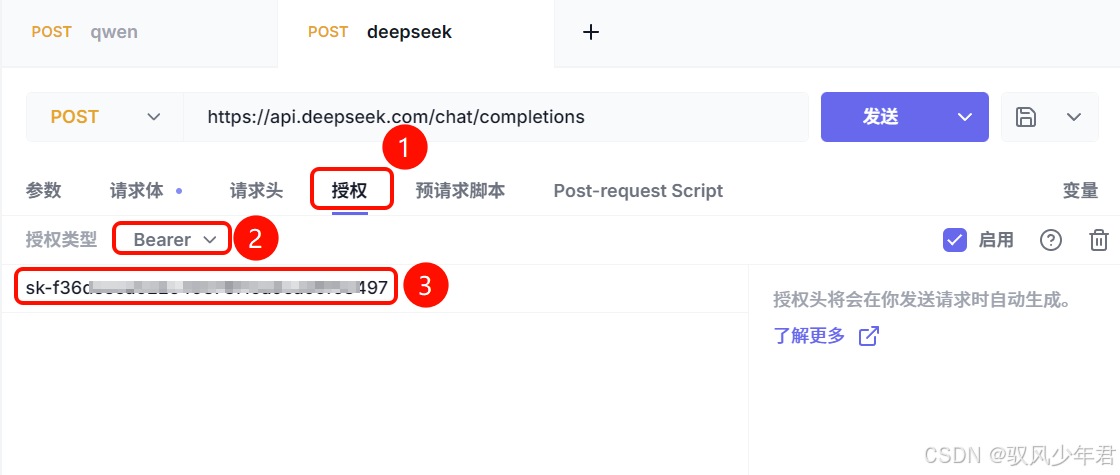
发送请求后,如果能收到大模型返回的JSON格式结果,说明API调用成功。
5.2 阿里巴巴百炼模型服务
阿里云百炼是阿里巴巴推出的大模型服务平台,支持多种主流大模型(如Qwen、DeepSeek-R1等),而且新用户会赠送免费token,适合新手测试使用。
5.2.1 注册账号
第一步:注册阿里云账号,地址:https://account.aliyun.com/(支持手机号、支付宝等方式注册)。
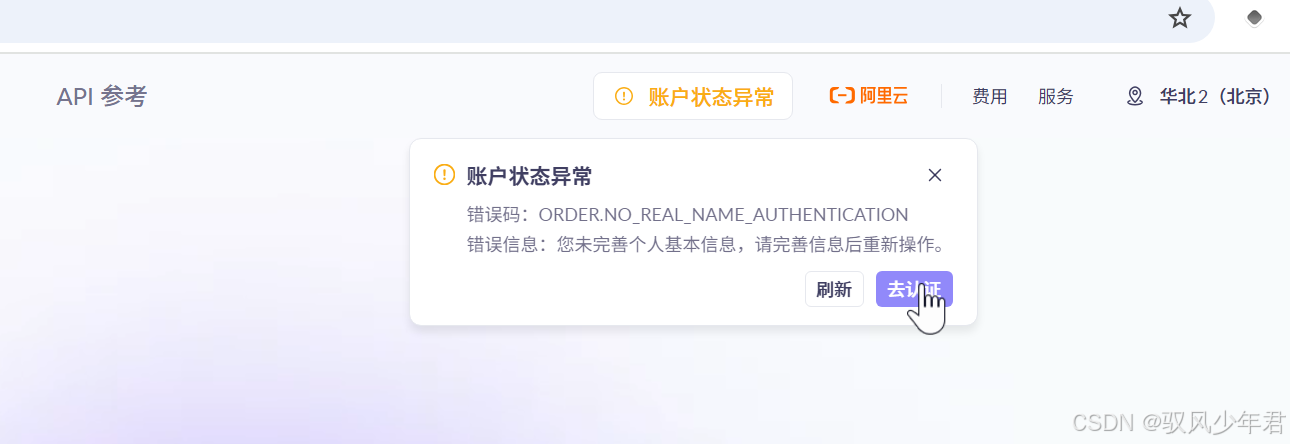
注意:阿里云账号需要完成个人实名认证,否则后续使用百炼服务时会出现警告,无法正常调用API。
第二步:访问阿里云百炼平台,地址:https://bailian.console.aliyun.com/
首次访问时,会弹出窗口,询问是否同意开通百炼服务,点击"确认开通"即可:
如果未完成实名认证,会弹出"账户异常"提示,点击"去认证",按照页面提示完成个人实名认证即可(此处略过详细步骤)。
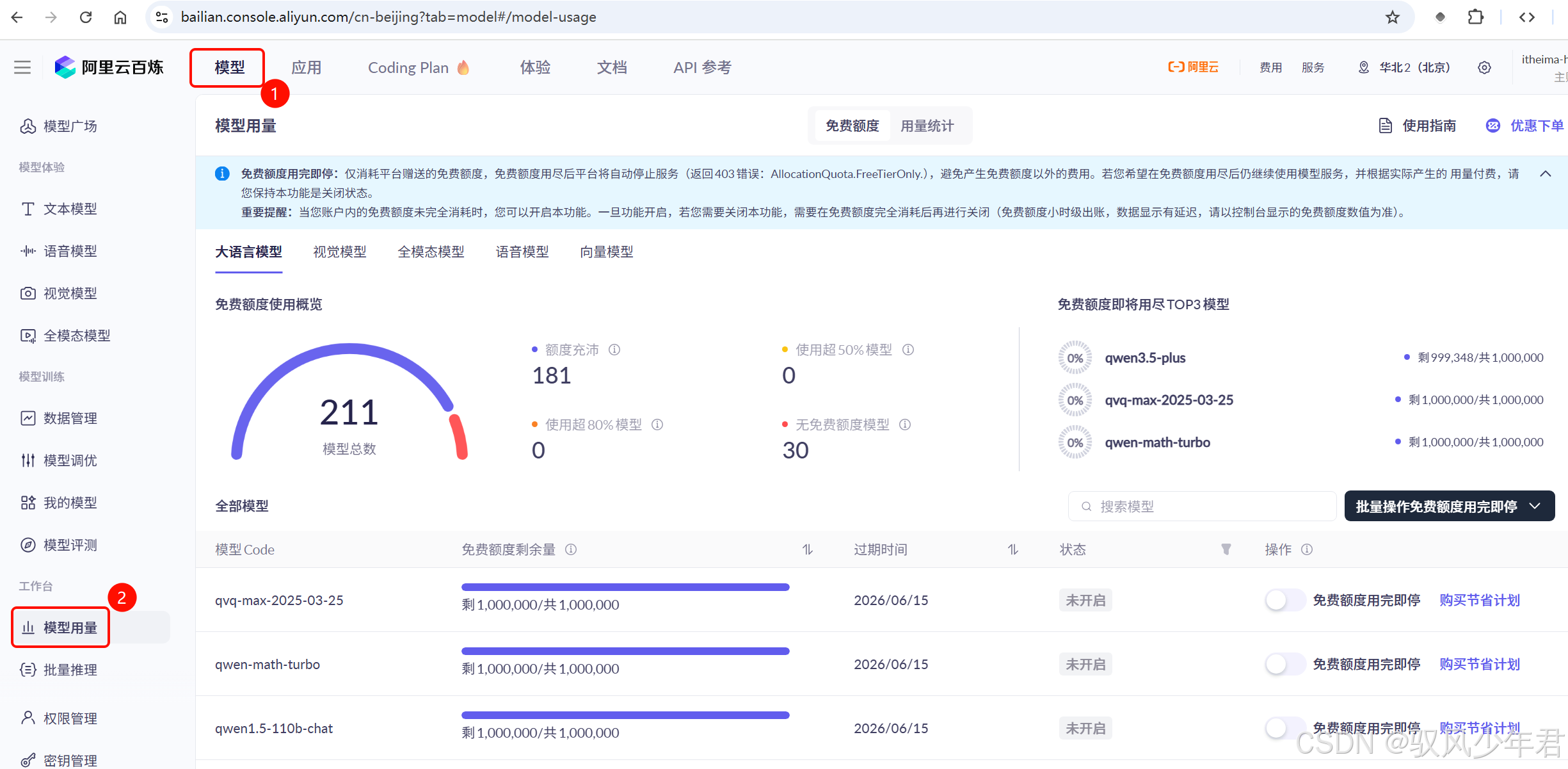
首次开通百炼服务,平台会赠送百万级token的免费使用权(包含多种模型),有效期3~9个月不等。大家可以在"模型控制台"→"模型用量"中,查看自己的免费额度使用情况:
由于有免费额度,我们可以跳过充值步骤,直接使用API服务。
5.2.2 申请API_KEY
和DeepSeek一样,调用阿里云百炼的API,也需要创建API_KEY进行身份验证。
操作步骤:
-
注册并登录阿里云百炼平台后,点击左侧菜单的"模型"选项;
-
在左侧菜单最下方,找到"密钥管理"选项,点击进入;
-
点击"创建API-KEY"按钮,弹出表单,勾选相关协议后,点击"确定";
-
即可生成一个新的API_KEY,后续开发中需要用到这个API_KEY,务必妥善保管,不要泄露。

5.2.3 体验模型
如果想先体验一下大模型的效果,不需要调用API,直接在百炼平台上即可操作:
点击平台左侧的"模型"选项,进入模型广场,选择任意模型,即可直接与大模型对话,体验其功能:
5.2.4 API文档
点击平台顶部的"API参考"选项,即可进入API文档页面,查看各种模型的API调用规范(兼容OpenAI规范):
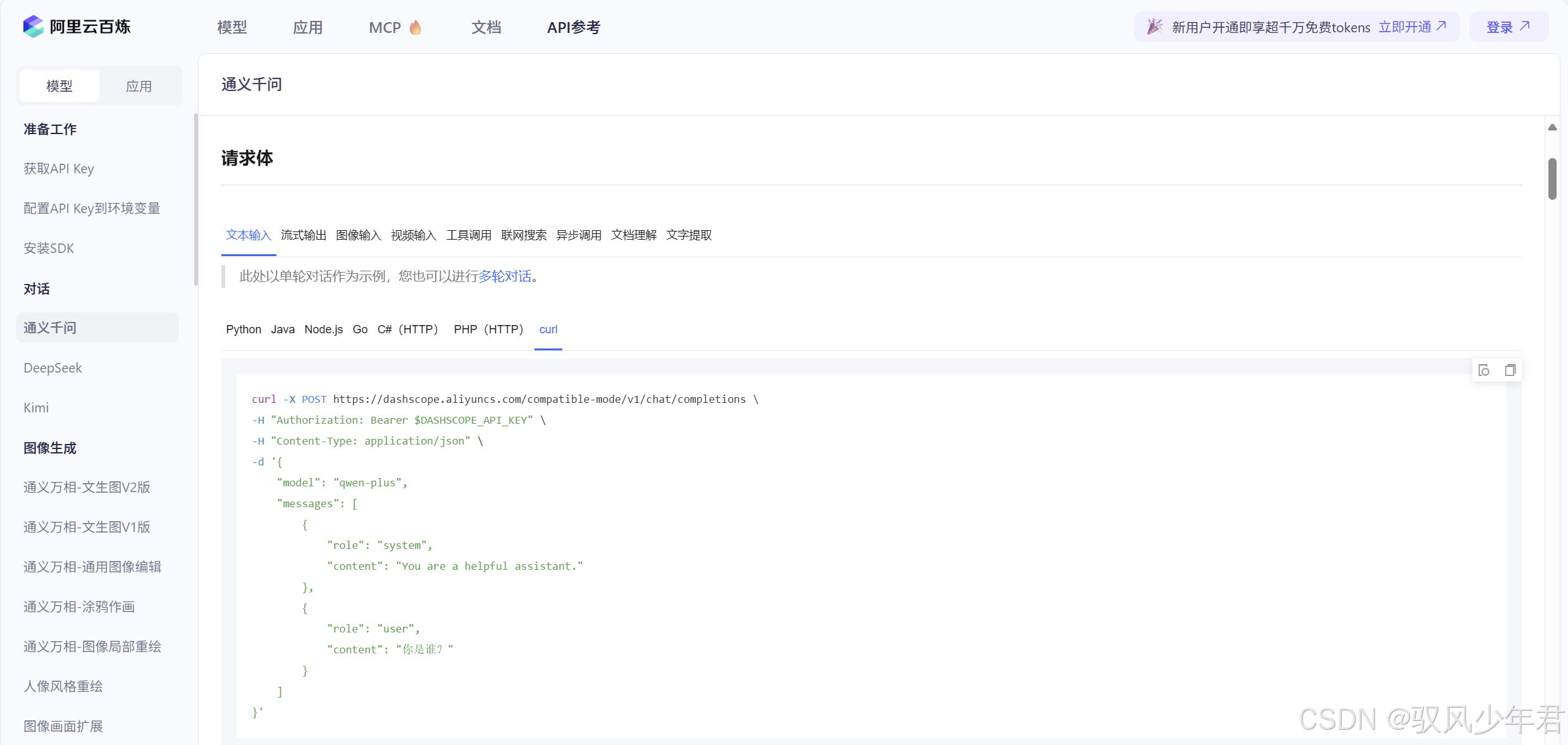
5.2.5 测试
使用HTTP客户端(如Postman、Apifox),调试阿里云百炼的API,注意在请求头中添加我们创建的API_KEY,确保身份验证通过:
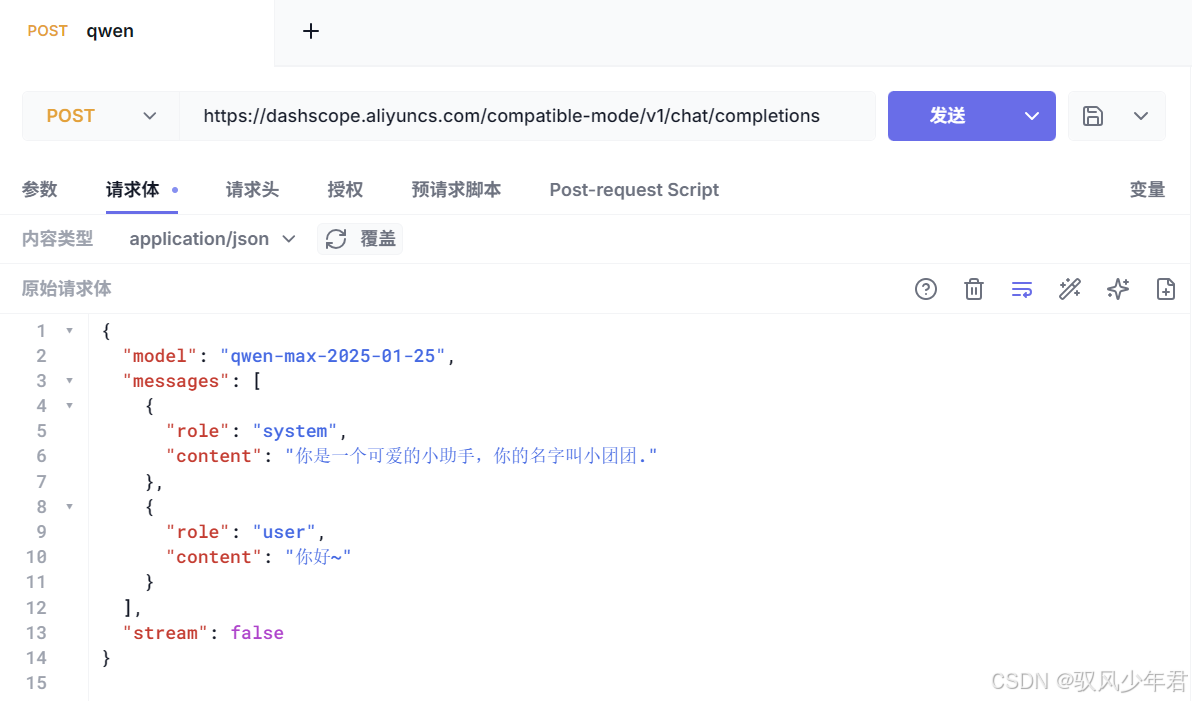
5.3 本地部署
很多云平台都提供了大模型一键部署功能,操作简单,此处不再赘述。我们重点讲解如何手动部署大模型------最简单的方式,就是使用Ollama工具,这是一个专门用于部署和运行大模型的工具,支持Windows、Mac、Linux等多种系统,上手难度低,适合新手。
Ollama官网地址:https://ollama.com/
5.3.1 下载安装ollama
第一步:访问Ollama官网,根据自己的操作系统(Windows、Mac、Linux),下载对应的Ollama客户端:
第二步:安装Ollama。
默认情况下,Ollama会安装在C盘的用户目录下;如果不希望安装在C盘(比如C盘空间不足),可以通过命令行方式安装,具体步骤如下:
-
将下载的OllamaSetup.exe文件,放在自己想要的文件夹中(比如D盘Ollama目录);
-
在该文件夹中,按住Shift键+鼠标右键,选择"在此处打开命令窗口"(或"在此处打开PowerShell窗口");
-
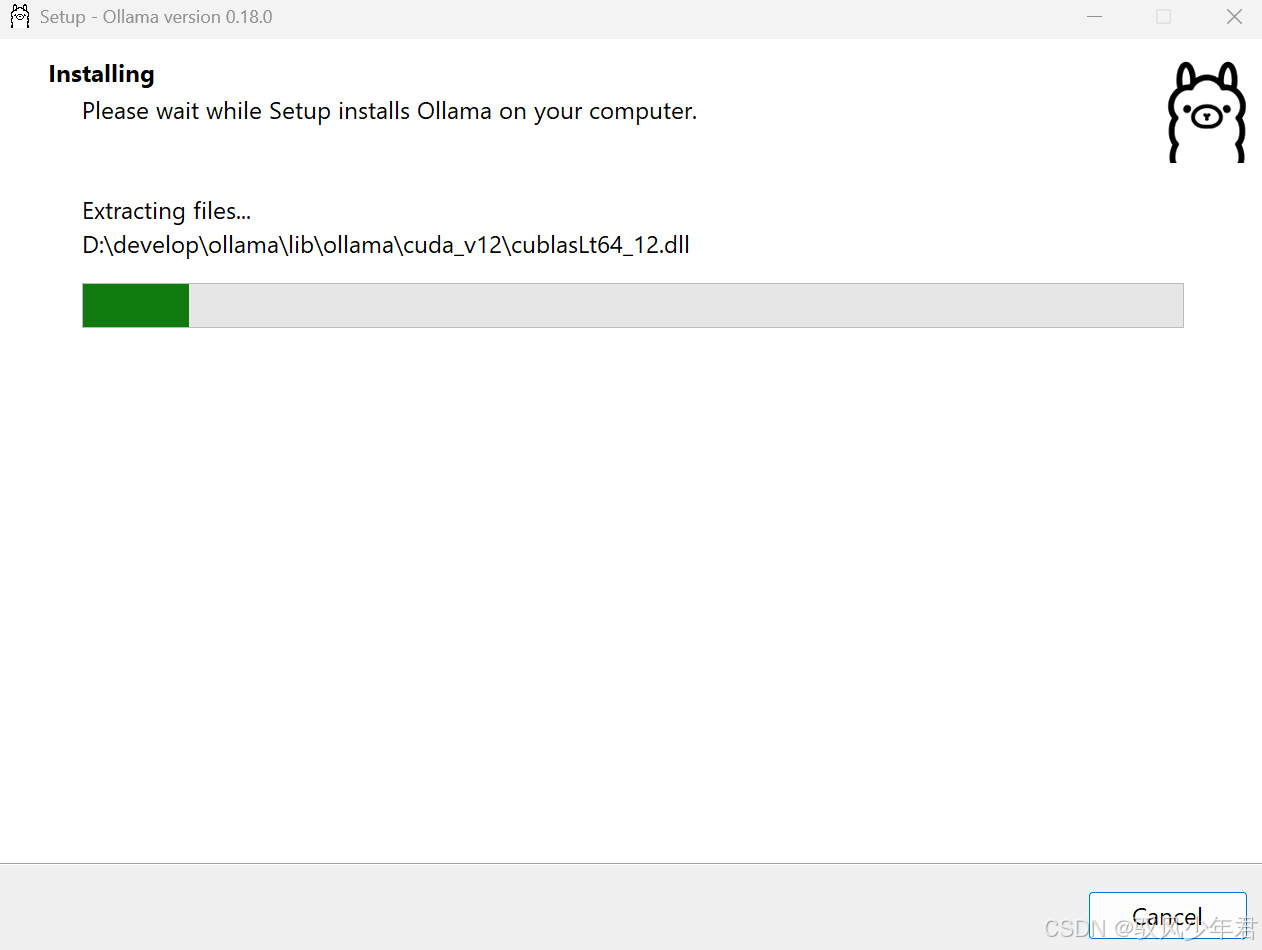
输入命令:OllamaSetup.exe /DIR=你要安装的目录位置(比如OllamaSetup.exe /DIR=D:\Ollama);
-
运行命令后,会弹出安装窗口,此时安装位置就是你设定的目录(如D:\Ollama),点击"Install"即可完成安装。
第三步:配置环境变量(可选,但推荐)。
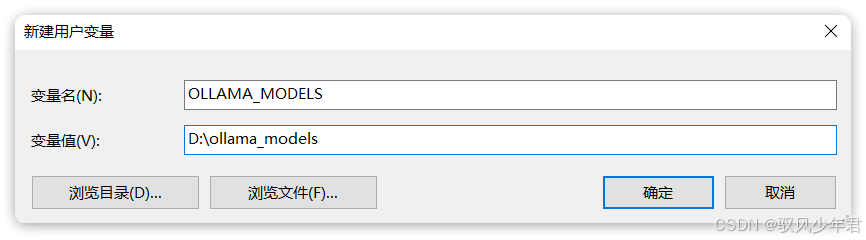
安装完成后,建议配置一个环境变量,更改Ollama下载和部署模型的位置(默认会存在C盘,占用C盘空间)。
环境变量配置:新建系统环境变量,变量名:OLLAMA_MODELS,变量值:你想要保存模型的目录(比如D:\Ollama\Models)。
环境变量配置方式,相信学过Java的同学都很熟悉,这里不再赘述,配置完成后如图所示:
5.3.2 搜索模型
Ollama不仅是部署工具,还是一个模型管理平台,提供了很多国内外常见的大模型(如DeepSeek-R1、Qwen、Llama等),我们可以在其官网上搜索自己需要的模型。
模型搜索地址:https://ollama.com/search
举例:搜索"deepseek",可以看到排在第一位的是deepseek-r1模型:
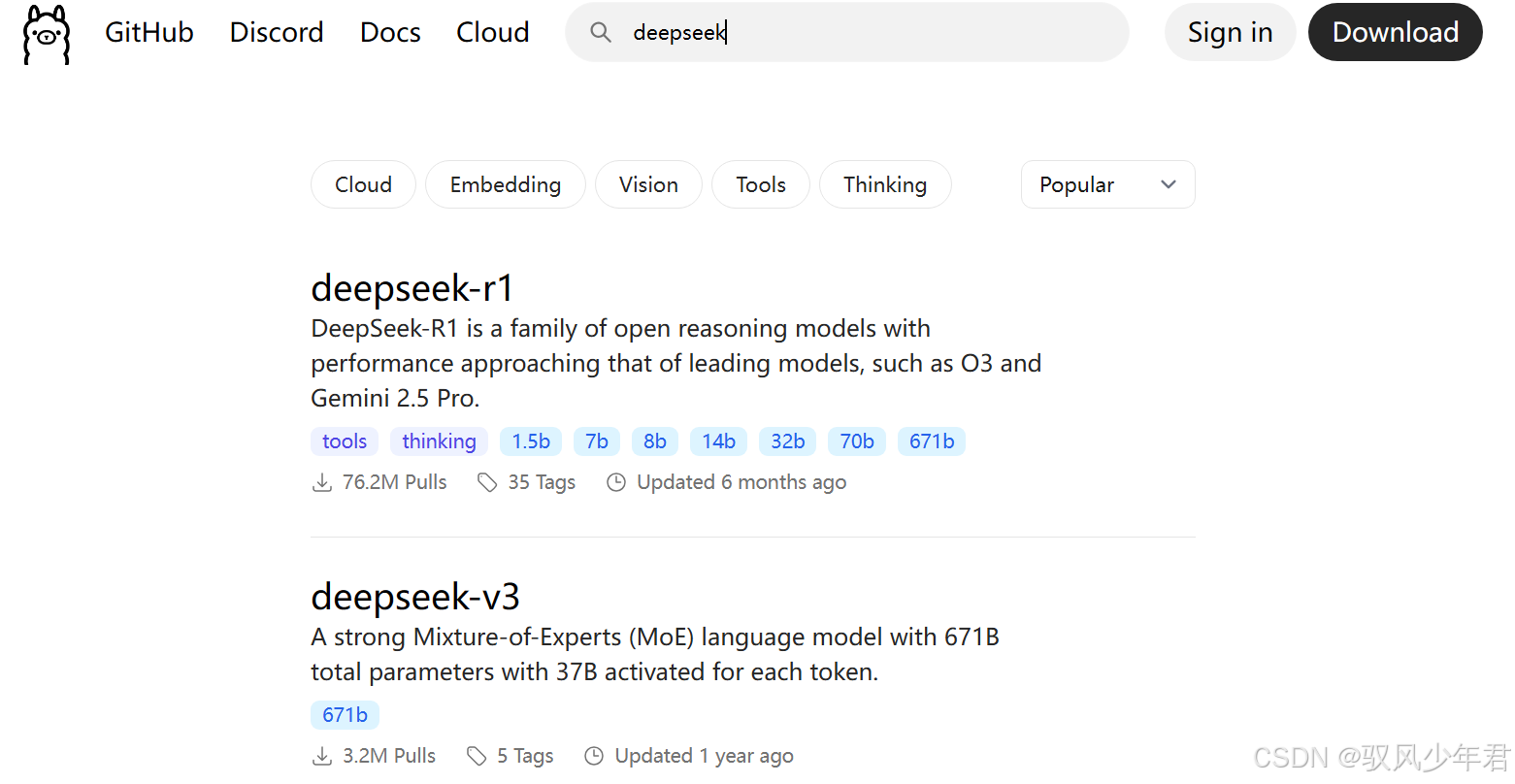
点击进入deepseek-r1页面,会发现该模型有多个版本(不同参数规模):
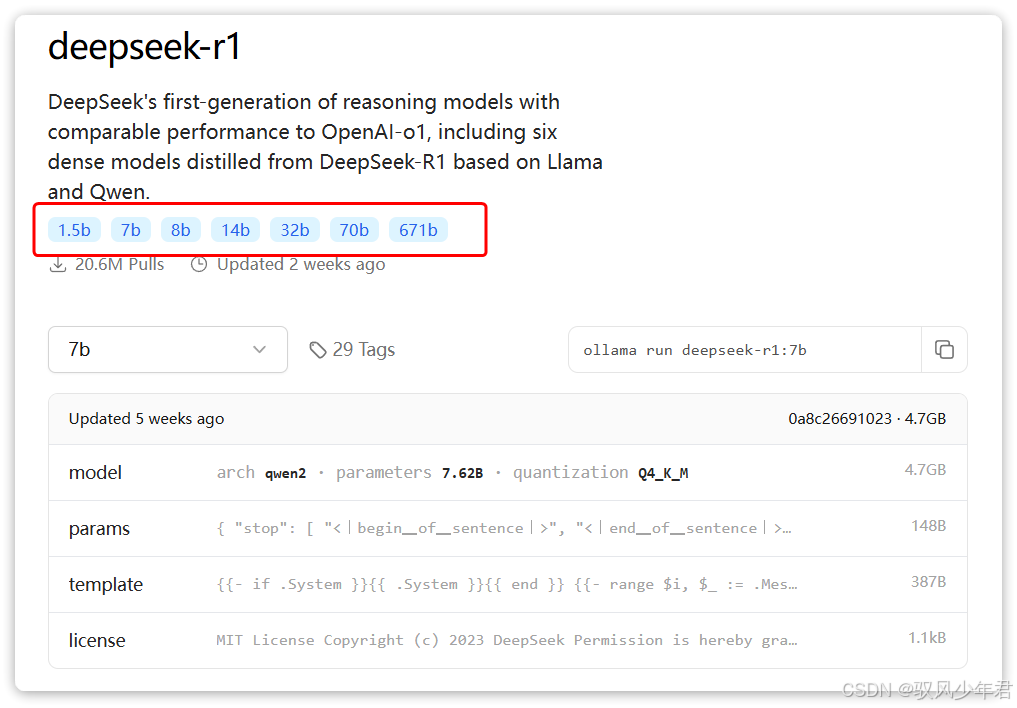
这些版本的区别在于参数大小:参数越大,模型的推理能力越强,但需要的算力(CPU、GPU)也越高。其中,671b版本是最强的满血版deepseek-r1,对硬件要求极高;而7b、8b版本,对硬件要求较低,适合普通电脑部署。
需要注意的是,Ollama提供的大模型,都是量化压缩版本,相比官网的蒸馏版,体积更小,对显卡的要求更低,具体对比如图:
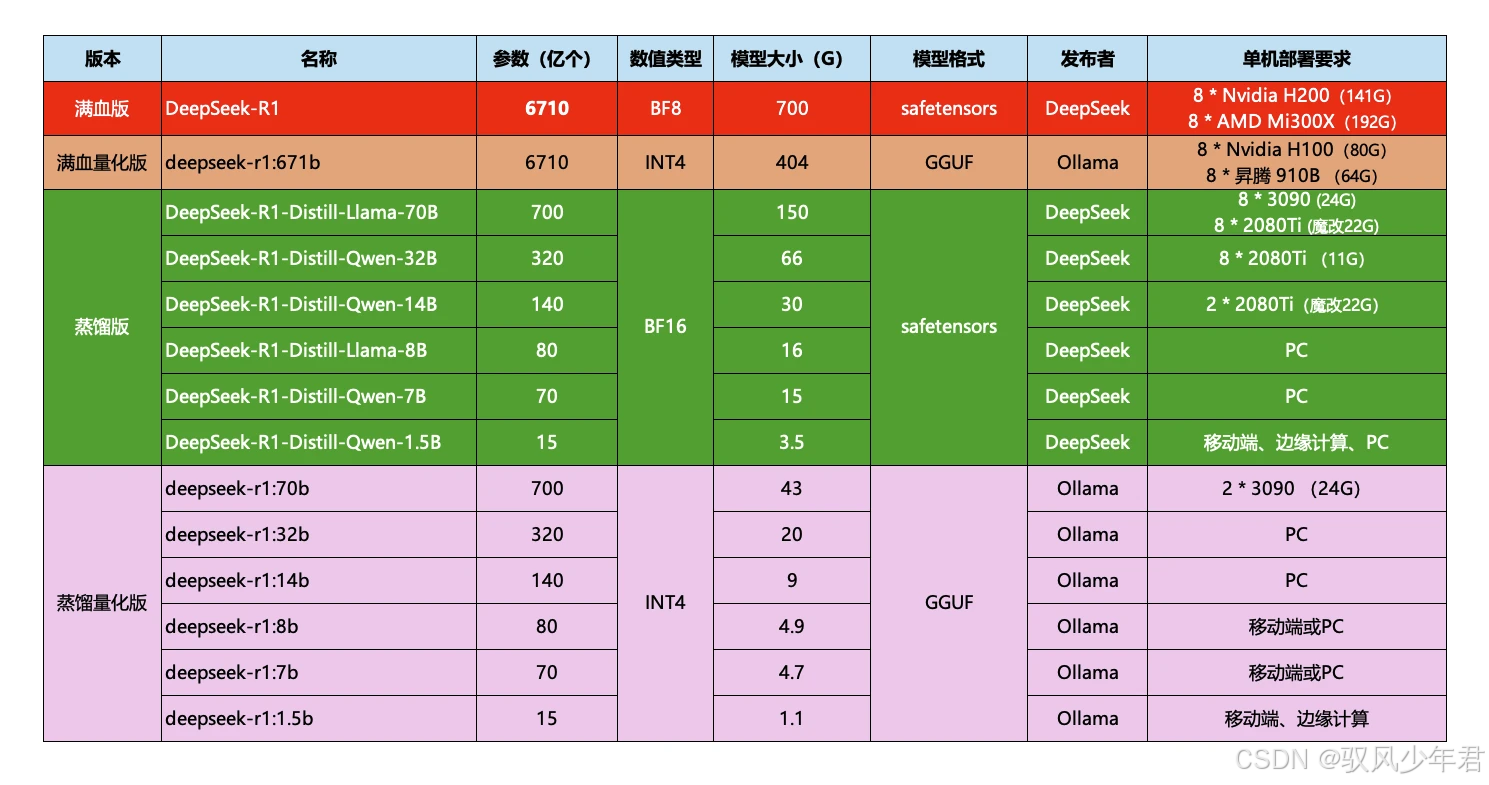
举例:我的电脑内存32G,显存6G,选择部署7b版本的deepseek-r1,完全可以流畅运行;8b版本也可以尝试,两者性能差别不大。
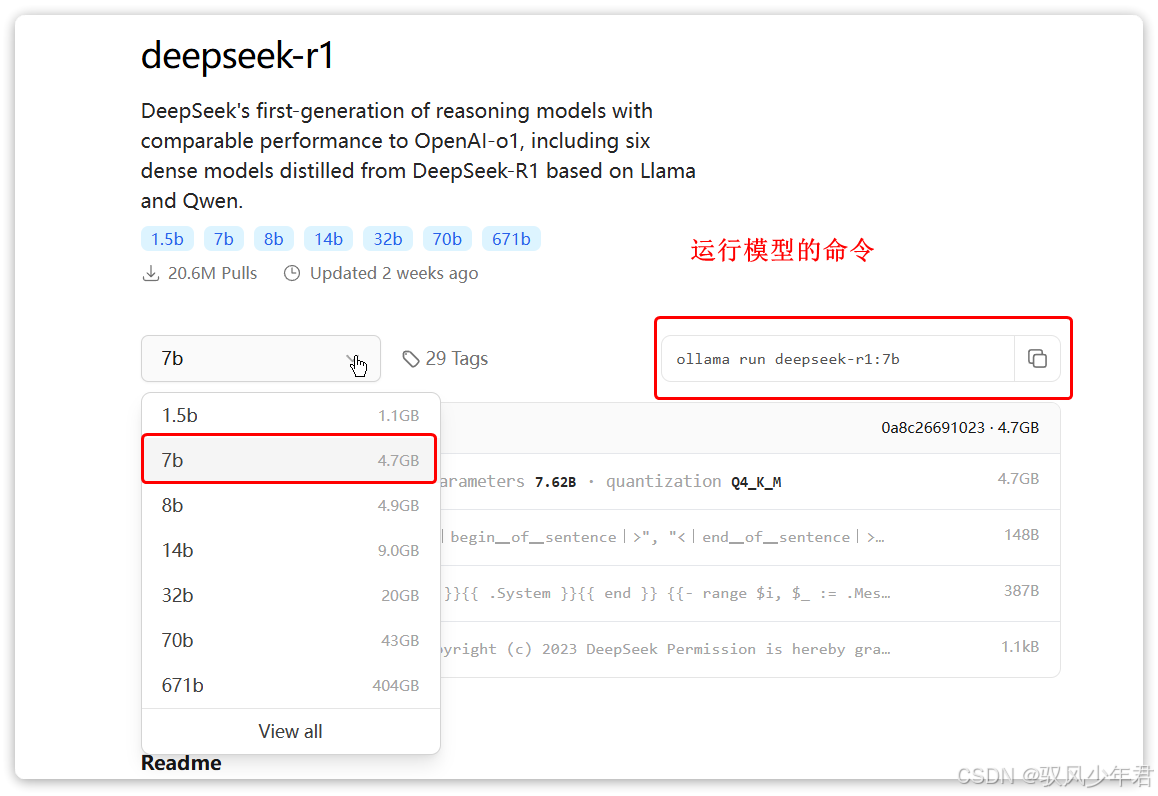
5.3.3 运行模型
选择合适的模型版本后,Ollama会给出对应的运行命令,我们只需复制命令,在命令行中运行,即可启动模型,开始与本地模型对话。
操作步骤:
-
复制Ollama官网中该模型的运行命令(比如deepseek-r1 7b版本的命令:ollama run deepseek-r1:7b);
-
打开CMD命令行(或PowerShell),粘贴命令并运行;
-
首次运行命令时,会自动下载模型文件,下载时长根据模型大小和网络速度而定,大概在5分钟~1小时不等,请耐心等待;
-
下载完成后,会自动启动模型,此时就可以在命令行中,直接与本地模型聊天了。
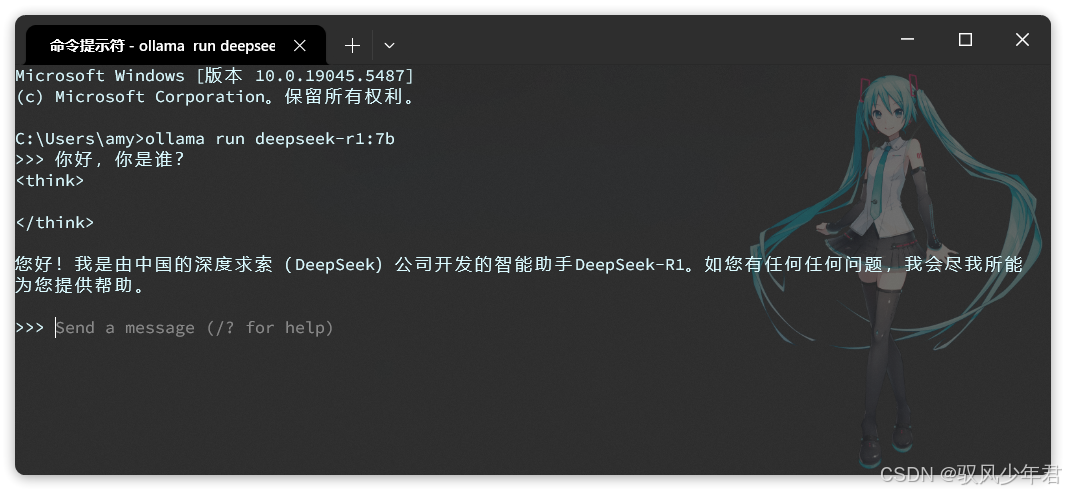
注意事项:
-
首次运行需下载模型,网络速度会影响下载时长;
-
Ollama控制台是一个封装好的AI对话界面,和ChatGPT类似,具备会话记忆功能,能够记住上下文;
-
Ollama会自动提供HTTP接口,供传统程序调用,默认接口地址是:http://127.0.0.1:11434/api/chat。
另外,Ollama的命令和Docker类似,常用命令如下(方便大家管理模型):
ollama serve # 启动Ollama服务
ollama create # 从Modelfile创建模型
ollama show # 查看模型信息
ollama run # 运行模型
ollama stop # 停止运行中的模型
ollama pull # 从仓库拉取模型
ollama push # 将模型推送到仓库
ollama list # 查看本地所有模型
ollama ps # 查看正在运行的模型
ollama cp # 复制模型
ollama rm # 删除模型
ollama help # 查看帮助信息
5.3.4 测试API
Ollama在本地部署模型后,会自动开启HTTP接口,我们可以使用HTTP客户端(如Postman),测试该接口是否能正常调用,接口地址默认是:http://localhost:11434/api/chat
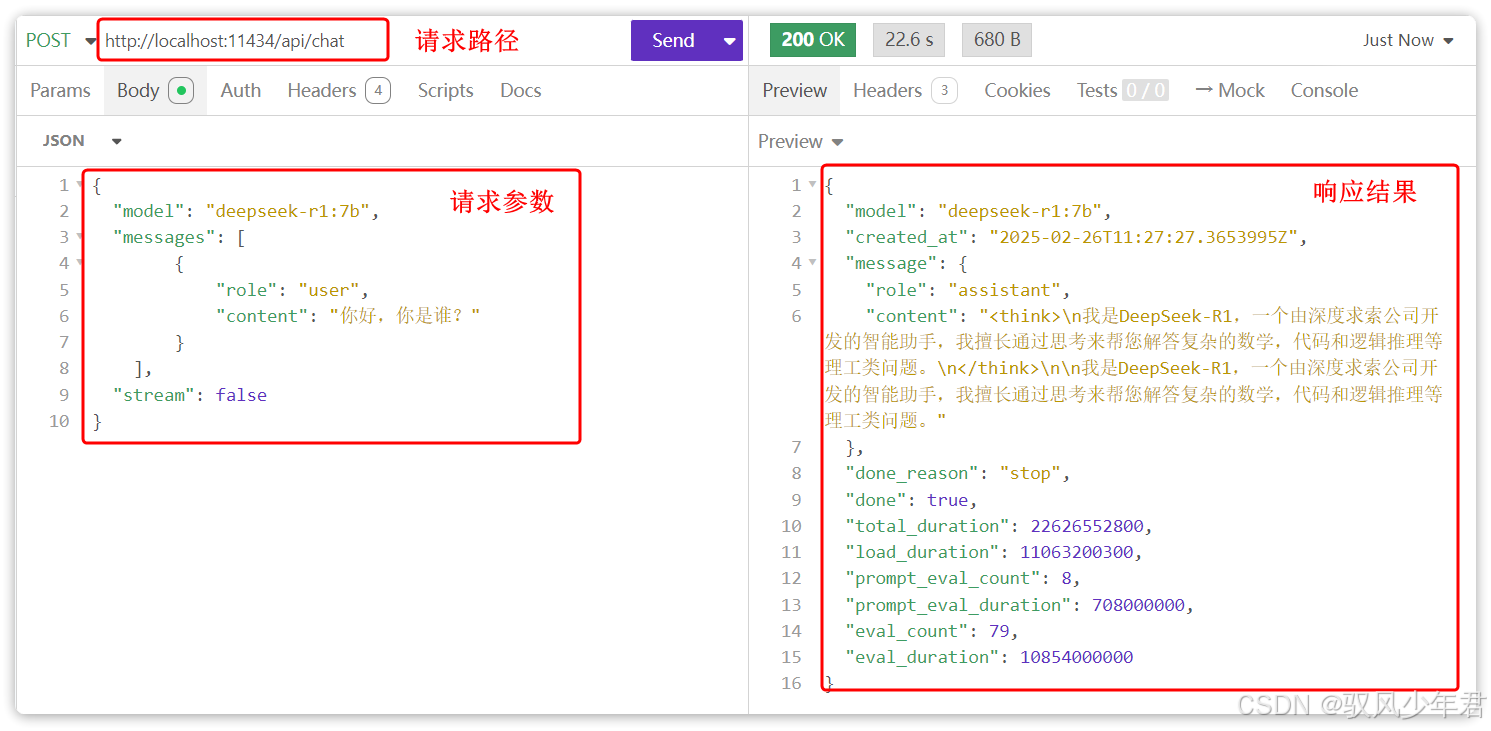
6. 大模型API
再次强调:大模型应用开发,核心是通过调用大模型的API接口,实现传统程序与大模型的交互,而不是在浏览器中与AI聊天。因此,要学习大模型应用开发,必须掌握大模型的API接口规范。
目前,大多数大模型的API都遵循OpenAI的接口规范------基于HTTP协议,请求路径、参数、返回值的格式基本一致,只有少量细节差异。具体的调用细节,需要查看对应大模型的官方API文档。
6.1 大模型接口规范
我们以DeepSeek官方给出的API示例为例,详细拆解大模型API的核心规范,帮大家快速掌握调用方法:
python
curl -X POST https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <DeepSeek API Key>" \
-d '{
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
],
"stream": false
}'6.1.1 接口说明
6.1.1 接口说明
- 请求方式:通常是POST,因为要传递JSON风格的参数
- 请求URL:与平台有关
- DeepSeek官方平台:https://api.deepseek.com/chat/completions
- 阿里云百炼平台:https://dashscope.aliyuncs.com/compatible-mode/v1
- 本地ollama部署的模型:http://localhost:11434
- 请求头:开放平台都需要提供API_KEY来校验权限,本地ollama则不需要
- Content-Type: application/json,请求参数的格式,必须是application/json,稍后解释
- Authorization: Bearer ,上一节创建的API_KEY
- 请求参数:JSON格式:
python
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}- model:模型名称,DeepSeek支持deepseek-reasoner和deepseek-chat两者模型
- messages:发送给大模型的消息,\[\]是数组的意思,里面可以有多条消息。消息结构:
- content:是消息的内容
- role:消息的角色,有system、user、assisant三种角色
- system:是给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉
- user:就是用户提问的问题
- assisant:是大模型的回答
- stream:true,代表响应结果流式返回;false,代表响应结果一次性返回,但需要等待
注意,这里请求参数中的messages是一个消息数组,而且其中的消息要包含两个属性:
- role:消息对应的角色
- content:消息内容
其中System和User消息的内容,也被称为提示词(Prompt),也就是用户发送给大模型的指令。
- System提示词,是系统指令,给大模型设定一个角色,比如你让她扮演你的奶奶,让她哄你睡觉
- User提示词,是用户指令,也就是用户向大模型的提问或命令
6.1.2 提示词角色
通常消息的角色有三种:
| 角色 | 描述 | 示例 |
|---|---|---|
| system | 优先于user指令之前的指令,也就是给大模型设定角色和任务背景的系统指令 | 你是一个乐于助人的编程助手,你以小团团的风格来回答用户的问题。 |
| user | 终端用户输入的指令(类似于你在ChatGPT聊天框输入的内容) | 写一首关于Java编程的诗 |
| assistant | 由大模型生成的消息,可能是上一轮对话生成的结果 注意,用户可能与模型产生多轮对话,每轮对话模型都会生成不同结果 |
其中System类型的消息非常重要!影响了后续AI会话的行为模式。
比如,我们会发现,当我们询问这些AI对话产品"你是谁"这个问题的时候,每一个AI的回答都不一样,这是怎么回事呢?
这其实是因为AI对话产品并不是直接把用户的提问发送给LLM,通常都会在user提问的前面通过System消息给模型设定好背景:
所以,当你问问题时,AI就会遵循System的设定来回答了。因此,不同的大模型由于System设定不同,回答的答案也不一样。
示例:
python
## Role
System: 你是一家名为《黑马程序员》的职业教育培训公司的智能客服,你的名字叫小黑。请以友好、热情的方式回答用户问题。
## Example
User: 你好
Assisant: 你好,我是小黑,很高兴认识你!😊 你是想了解我们的课程信息,还是有其他关于职业培训的问题需要咨询呢?无论什么问题,我都会尽力帮你解答哦!6.2 会话记忆问题
这里还有一个问题:
我们为什么要把历史消息都放入Messages中,形成一个数组呢?
大模型的API接口是"无状态"的,服务端不会记录用户请求的上下文。因此我们调用API接口与大模型对话时,每一次对话信息都不会保留,多次对话之间都是独立的,没有关联的。
因此大模型并不知道之前的聊天历史,也就是说大模型是没有记忆的。
测试,我询问AI一个问题:12个苹果分给3个人,每人能分几个?
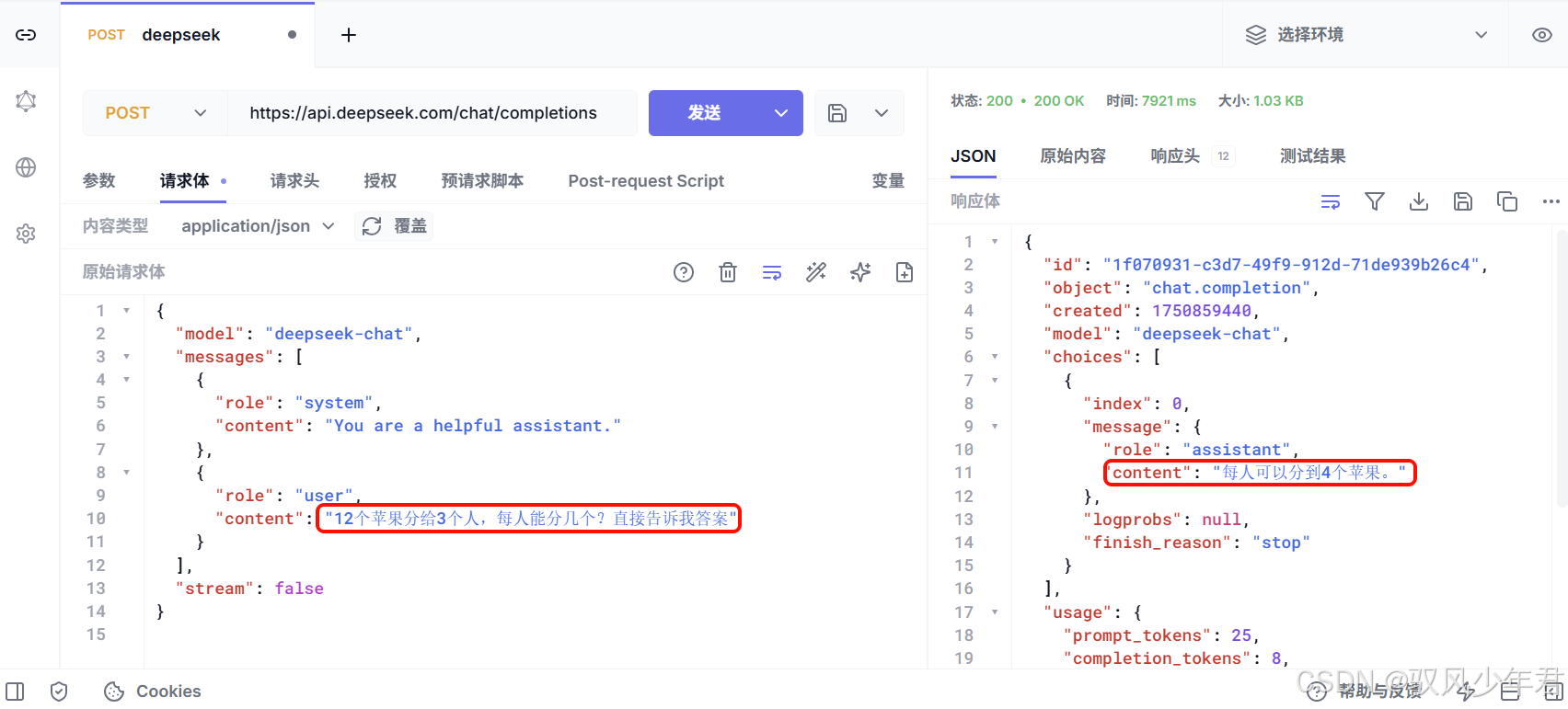
AI的答案是:每人可以分到4个苹果。
我们接着问:如果是分给4个人呢?,由于AI没有记忆,它不知道我是接着上一题问的,因此不知道要分的是12个苹果,答案就有问题:
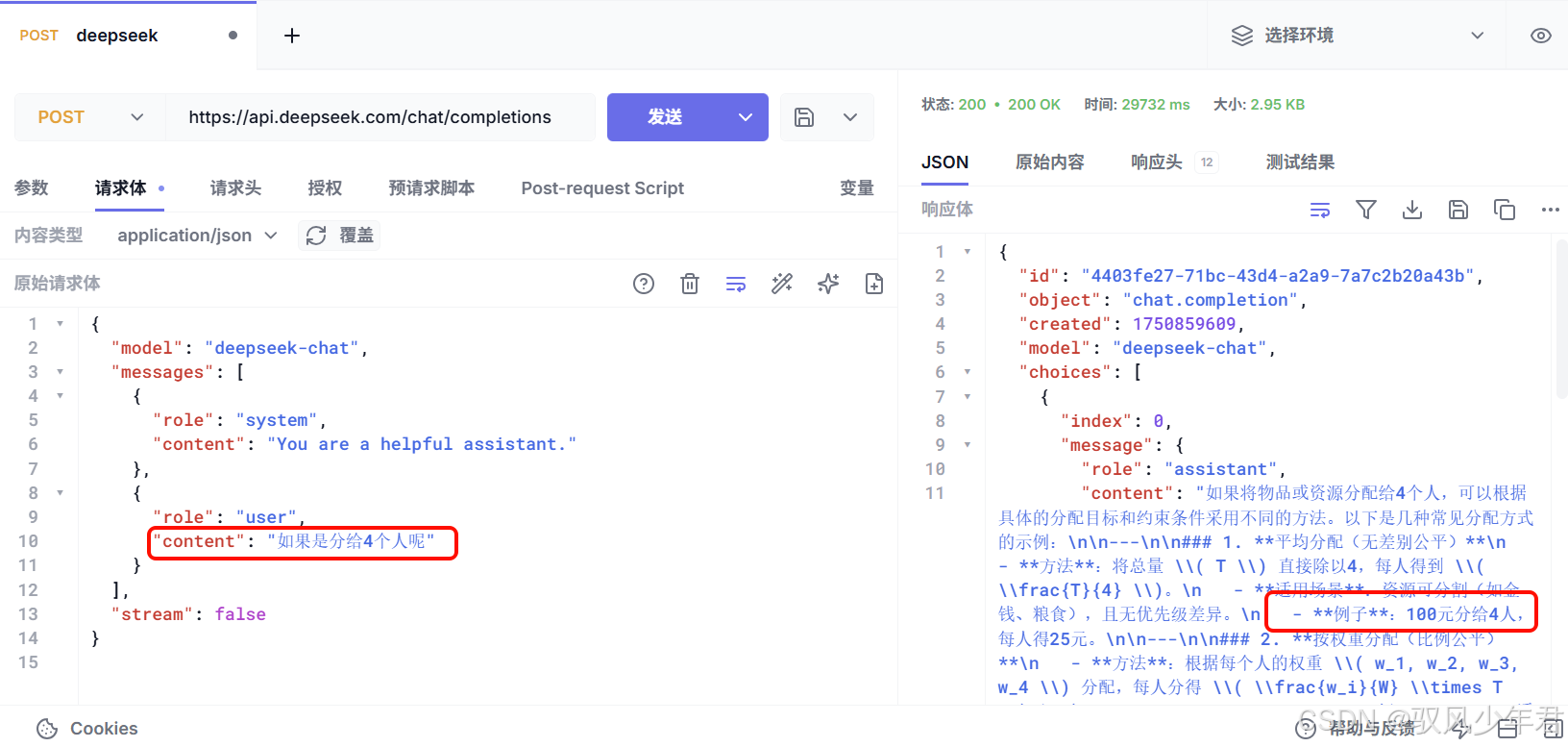
可以看到,AI完全不知道我们聊天的背景是上一次的分12个苹果。
那么,如何才能让AI具备记忆呢?
要想让大模型有记忆,必须在每次请求时,将之前所有对话的历史拼接好,传递给对话API接口。
官方文档说明:
暂时无法在飞书文档外展示此内容
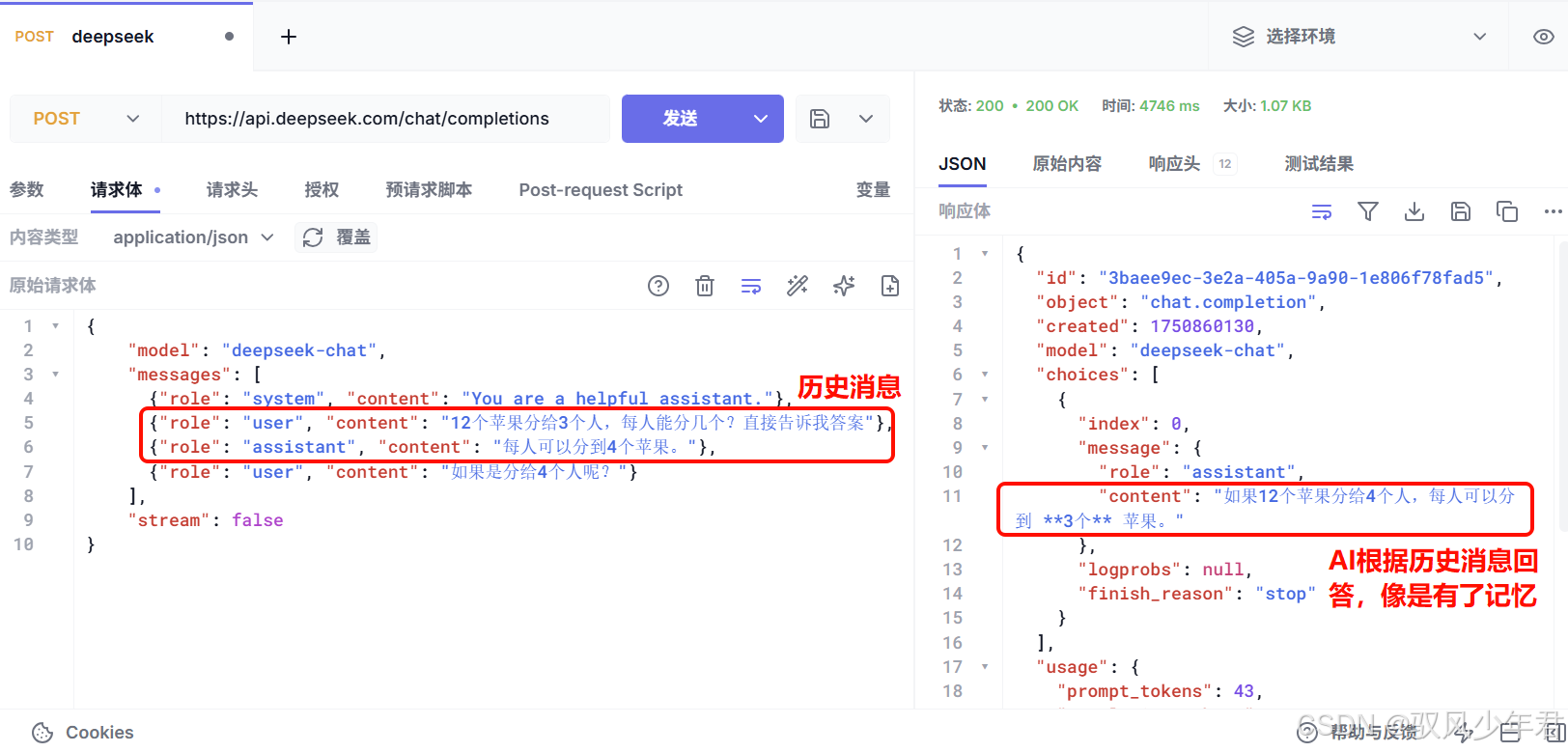
要想让AI具备记忆,就必须把对话历史都添加到请求体中的messages数组中,像这样:
python
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "12个苹果分给3个人,每人能分几个?直接告诉我答案"},
{"role": "assistant", "content": "每人可以分到4个苹果。"},
{"role": "user", "content": "如果是分给4个人呢?"}
],
"stream": false
}测试结果:
好了,现在我们能用图形界面的Http客户端发送http请求,调用大模型了。
但是这样还不够,如果要开发AI应用,肯定是要通过编程的方式发送Http请求,调用大模型。
6.3 开发环境准备
现在,我们已经掌握了大模型提供的API接口规范了,不过,最终我们还是要用编程的方式来访问大模型。
所以,接下来就让我们准备好开发的 环境吧。
6.3.1 安装UV
Python的环境管理方案有很多种,例如:
- pip
- uv
- conda
- ...
在后面的课程中我们会选择uv作为项目管理工具,其官网如下:
还有个第三方写的中文文档:
它有非常多的优点:

具体的安装方式大家可以参考官方文档:
https://uv.doczh.com/getting-started/installation/
最简单的安装方案就是使用pip:
pip install uv
详细教程可以参考视频:
https://www.bilibili.com/video/BV1Stwfe1E7s/?spm_id_from=333.1387.search.video_card.click
6.3.2 添加镜像源
默认情况下,uv下载依赖是到国外站点:https://test.pypi.org/simple,速度很慢。推荐大家将下载的镜像源改为国内站点。
uv支持项目级配置和系统级配置两种方案,项目级优先级高,但是需要每个项目都配置,比较麻烦。推荐采用系统级配置。
系统配置方式如下:
- Windows系统,在CMD运行如下命令:
python
setx UV_DEFAULT_INDEX "https://pypi.tuna.tsinghua.edu.cn/simple"- MacOS或Linux系统:
python
echo 'export UV_DEFAULT_INDEX=https://pypi.tuna.tsinghua.edu.cn/simple' >> ~/.zshrc && source ~/.zshrc常见的国内镜像站点有:
阿里云
https://mirrors.aliyun.com/pypi/simple/
腾讯云
https://mirrors.cloud.tencent.com/pypi/simple/
火山引擎
https://mirrors.volces.com/pypi/simple/
华为云
https://mirrors.huaweicloud.com/repository/pypi/simple/
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学
https://pypi.mirrors.ustc.edu.cn/simple/
6.3.3 创建项目
接下来我们就创建一个项目,我们会使用PyCharm作为开发工具,以uv作为项目管理工具。
第一步,打开PyCharm,创建Project:
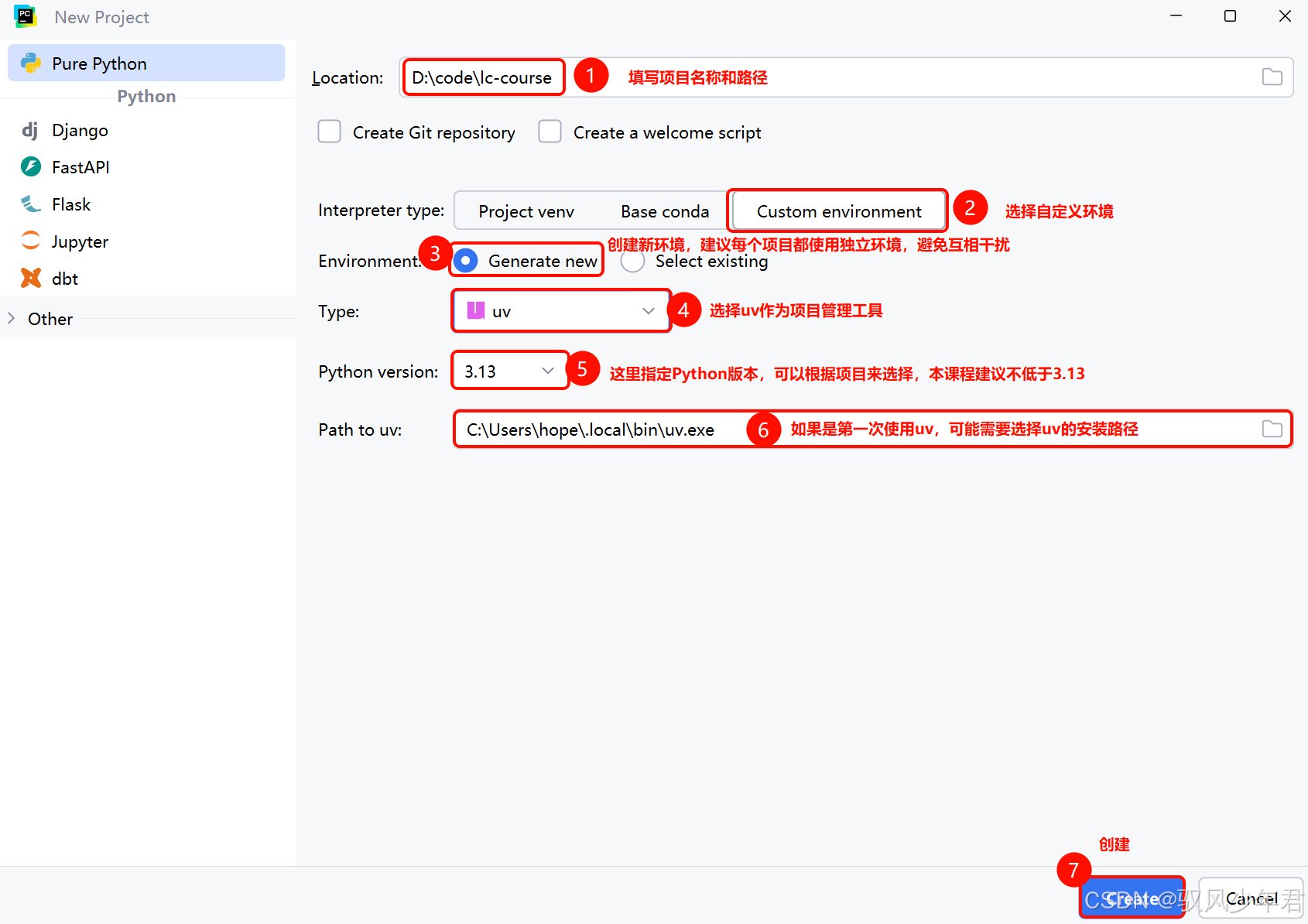
为了方便大家学习,我们会使用jupyter,所以需要在项目中引入notebook依赖。
在PyCharm中,左侧有一个Terminal按钮,点击即可打开终端:
如图:
在终端中输入命令:
uv add notebook
6.3.4 测试
为了测试环境,我们创建一个notebook试试:
起名为hello:
如图:
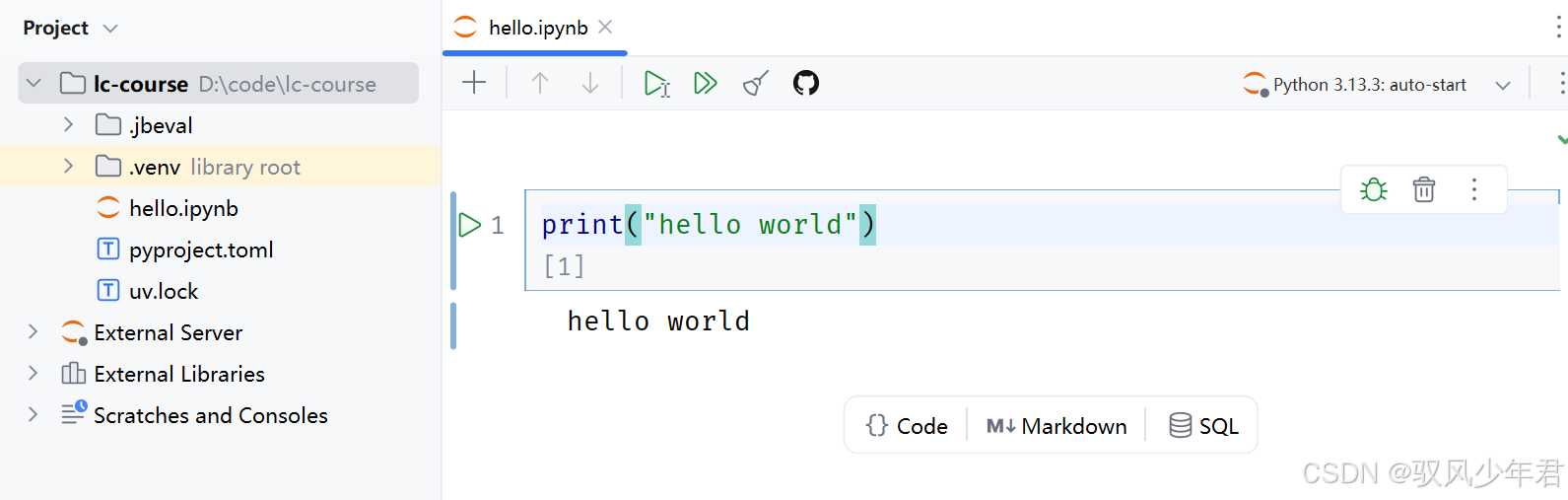
然后在代码框中编写打印HelloWorld的代码,快捷键SHIFT + ENTER即可运行::
图片
6.4 OpenAI
OpenAI作为全球最早,也是最火的大模型公司之一,占据了先发优势。因此其制定的API规范几乎成为了大模型API的默认规范,几乎所有的大模型API都兼容OpenAI的规范。
在任何模型的官方文档中都能看到基于OpenAI提供的SDK的代码示例,例如DeepSeek:
https://api-docs.deepseek.com/zh-cn/
本节我们来学习如何使用OpenAI提供的SDK工具来访问大模型。
6.4.1 基本使用
首先,我们需要安装OpenAI的SDK,以python为例:
- 使用pip安装:
pip install openai - 使用uv安装:
uv add openai
接下来,就可以使用SDK调用任何兼容OpenAI规范的模型了,只要将base_url和api_key设定为对应的模型提供者的url和api_key即可:
python
from openai import OpenAI
client = OpenAI(
api_key="sfxxxxx",
base_url="https://api.deepseek.com"
)
print("🚀 正在调用大模型...")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一名友好的AI助教。"},
{"role": "user", "content": "你好,你是谁?"}
],
stream=False
)
print(response)6.4.2 环境变量
将api_key直接写在代码中非常危险,所以通常我们都将其写入环境变量,程序运行时加载。
第一步,配置环境变量。
在项目根目录创建一个.env文件:
在其中配置自己的API_KEY,我们以Deepseek为例:
deepseek
DEEPSEEK_API_KEY=sk-1234567890
阿里云
DASHSCOPE_API_KEY=sk-1234567890
第二步,安装python-dotenv。
在项目中,我们通过python-dotenv库来读取环境变量,所以要先安装依赖。
uv add python-dotenv安装成功后,会在pyproject.toml中看到新添加的依赖:
python
[project]
name = "lc-course"
version = "0.1.0"
description = "Add your description here"
requires-python = ">=3.13"
dependencies = [
"notebook>=7.5.5",
"openai>=2.28.0",
"python-dotenv>=1.2.2",
]第三步,读取环境变量。
最后,我们就可以在代码中读取环境变量了:
python
from openai import OpenAI
from dotenv import load_dotenv
import os
# 加载环境变量
load_dotenv()
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
print("🚀 正在调用大模型...")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一名友好的AI助教。"},
{"role": "user", "content": "你好,你是谁?"}
],
stream=False
)
print(response)