3 天从入门到可视化监控:Elasticsearch 新手实战指南
新手痛点:面对命令行的恐惧、数据可视化需求、集群状态监控难题
阅读时长 :约 15 分钟 | 难度系数 :⭐⭐⭐ | 实操性:100%

文章目录
- [3 天从入门到可视化监控:Elasticsearch 新手实战指南](#3 天从入门到可视化监控:Elasticsearch 新手实战指南)
-
- 一、开篇:三个真实场景痛点
-
- [场景 1:面对命令行的恐惧](#场景 1:面对命令行的恐惧)
- [场景 2:数据可视化需求](#场景 2:数据可视化需求)
- [场景 3:集群状态监控难题](#场景 3:集群状态监控难题)
- 二、零基础入门模块
-
- [2.1 ES 核心概念:用生活化类比理解](#2.1 ES 核心概念:用生活化类比理解)
-
- [2.1.1 索引(Index) = 智能文件夹](#2.1.1 索引(Index) = 智能文件夹)
- [2.1.2 文档(Document) = 一张信息卡片](#2.1.2 文档(Document) = 一张信息卡片)
- [2.1.3 字段(Field) = 信息标签](#2.1.3 字段(Field) = 信息标签)
- [2.2 环境部署:Docker 一键启动](#2.2 环境部署:Docker 一键启动)
-
- [方式 1:命令行部署](#方式 1:命令行部署)
- [方式 2:Docker Compose(推荐新手)](#方式 2:Docker Compose(推荐新手))
- [2.3 数据操作:双路径教学](#2.3 数据操作:双路径教学)
-
- [2.3.1 创建索引](#2.3.1 创建索引)
- [2.3.2 添加数据](#2.3.2 添加数据)
- [2.3.3 查询数据](#2.3.3 查询数据)
- [2.4 核心操作速查表](#2.4 核心操作速查表)
- 三、可视化管理模块
-
- [3.1 数据索引流程](#3.1 数据索引流程)
- [3.2 查询执行路径](#3.2 查询执行路径)
- [3.3 集群部署架构](#3.3 集群部署架构)
- [3.4 Kibana 界面操作详解](#3.4 Kibana 界面操作详解)
-
- [3.4.1 Index Pattern 配置](#3.4.1 Index Pattern 配置)
- [3.4.2 Discover 数据探索](#3.4.2 Discover 数据探索)
- [3.4.3 Visualize 可视化图表](#3.4.3 Visualize 可视化图表)
- [3.5 Elasticsearch-Head 插件](#3.5 Elasticsearch-Head 插件)
-
- [3.5.1 插件安装](#3.5.1 插件安装)
- [3.5.2 界面功能](#3.5.2 界面功能)
- [3.6 动态词云:ES 高频操作命令](#3.6 动态词云:ES 高频操作命令)
- 四、集群状态监控
-
- [4.1 集群健康指标](#4.1 集群健康指标)
- [4.2 关键性能指标](#4.2 关键性能指标)
- 五、避坑指南
-
- [⚠️ 避坑 1:字段类型选择错误](#⚠️ 避坑 1:字段类型选择错误)
- [⚠️ 避坑 2:分片数设置不当](#⚠️ 避坑 2:分片数设置不当)
- [⚠️ 避坑 3:查询性能优化不足](#⚠️ 避坑 3:查询性能优化不足)
- 六、学习资源包
-
- [6.1 Docker 快速部署脚本](#6.1 Docker 快速部署脚本)
- [6.2 常用命令速查表](#6.2 常用命令速查表)
- 文档操作
- 查询操作
- 聚合操作
- 批量操作
- 集群管理
-
-
- [6.3 推荐学习资源](#6.3 推荐学习资源)
- 七、问题解决路径
-
- [7.1 常见问题排查](#7.1 常见问题排查)
- [7.2 社区支持](#7.2 社区支持)
一、开篇:三个真实场景痛点
场景 1:面对命令行的恐惧
小王刚入职某互联网公司,项目经理说"把用户行为数据存到 ES 里,方便后续查询"。面对黑乎乎的终端界面,输入 curl -XGET 'localhost:9200' 就报错,瞬间崩溃------ES 命令行操作对新手来说就像天书。
场景 2:数据可视化需求
运营团队想要实时监控用户注册趋势,要求"做一个好看的数据大屏"。技术负责人说"用 Kibana 吧",但打开 Kibana 界面后,复杂的 Index Pattern 配置、各种图表选项,让人眼花缭乱。想做出美观的可视化,却不知道从何入手。
场景 3:集群状态监控难题
系统上线后,ES 集群偶尔会变慢,需要排查原因。打开 Elasticsearch-head 插件,看到一堆绿色的方块和红色的警告,却不知道这些指标代表什么,更不知道如何优化。集群健康监控对新手来说完全是个黑盒。
二、零基础入门模块
2.1 ES 核心概念:用生活化类比理解
2.1.1 索引(Index) = 智能文件夹
想象你有一个巨大的文件柜,里面装满了文件:
传统文件系统:
文件夹1: 2024年用户数据
├── user_001.txt
├── user_002.txt
└── ...
Elasticsearch索引:
用户索引 (user_index)
├── 文档1: { "name": "张三", "age": 25 }
├── 文档2: { "name": "李四", "age": 30 }
└── ...关键区别:ES 的索引是"智能文件夹",不是简单的存储容器,它能:
- 全文搜索:像 Google 一样快速找到内容
- 智能分析:自动提取关键词、统计词频
- 实时更新:数据秒级可查
2.1.2 文档(Document) = 一张信息卡片
每条数据就是一个文档,像一张名片:
{
"user_id": "1001",
"name": "张三",
"age": 25,
"tags": ["程序员", "Java", "ES新手"],
"create_time": "2024-01-15T10:30:00"
}重要提示:文档必须包含:
- 唯一标识符(_id)
- 字段(Field):各种数据类型
- 元数据(Meta):索引类型、版本号等
2.1.3 字段(Field) = 信息标签
字段类型决定了如何处理数据:
| 类型 | 示例 | 说明 |
|---|---|---|
| text | "Hello World" | 全文搜索,分词索引 |
| keyword | "产品经理" | 精确匹配,不分词 |
| integer | 100 | 整数 |
| date | "2024-01-15" | 日期时间 |
避坑指南:不要把所有字段都设为 text 类型!精确匹配用 keyword,全文搜索才用 text。
2.2 环境部署:Docker 一键启动
方式 1:命令行部署
# 新手必知:基础参数说明
- -p 9200:9200: 端口映射(宿主机:容器)
- -e "discovery.type=single-node": 单节点模式
- -e "ES_JAVA_OPTS=-Xms512m -Xmx512m": 内存限制
# 创建Docker网络
docker network create es-net
# 启动ES容器
docker run -d \
--name elasticsearch \
--net es-net \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
elasticsearch:8.11.0
# 启动Kibana容器
docker run -d \
--name kibana \
--net es-net \
-p 5601:5601 \
-e "ELASTICSEARCH_HOSTS=http://elasticsearch:9200" \
kibana:8.11.0验证是否启动成功:
# 检查ES状态
curl -XGET 'localhost:9200/_cluster/health?pretty'
# 期望输出
{
"cluster_name" : "docker-cluster",
"status" : "green", # green=健康, yellow=警告, red=异常
"number_of_nodes" : 1,
"active_shards" : 1
}方式 2:Docker Compose(推荐新手)
创建 docker-compose.yml:
version: '3.8'
services:
elasticsearch:
image: elasticsearch:8.11.0
container_name: elasticsearch
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms512m -Xmx512m
- xpack.security.enabled=false # 关闭安全认证(仅测试环境)
ports:
- "9200:9200"
- "9300:9300"
kibana:
image: kibana:8.11.0
container_name: kibana
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
ports:
- "5601:5601"
depends_on:
- elasticsearch启动服务:
docker-compose up -d避坑指南 :首次启动 ES 可能较慢(1-2 分钟),请耐心等待。访问 http://localhost:5601 前确认 ES 已启动。
2.3 数据操作:双路径教学
2.3.1 创建索引
命令行方式:
# 新手必知:基础索引配置
PUT /user_index
{
"settings": {
"number_of_shards": 1, # 分片数(新手保持默认1)
"number_of_replicas": 1 # 副本数(新手保持默认1)
},
"mappings": {
"properties": {
"name": { "type": "text" },
"age": { "type": "integer" },
"email": { "type": "keyword" }
}
}
}可视化工具方式(Kibana Dev Tools):
PUT /user_index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": { "type": "text" },
"age": { "type": "integer" },
"email": { "type": "keyword" }
}
}
}2.3.2 添加数据
命令行方式:
# 方式1:指定ID
POST /user_index/_doc/1
{
"name": "张三",
"age": 25,
"email": "zhangsan@example.com"
}
# 方式2:自动生成ID
POST /user_index/_doc
{
"name": "李四",
"age": 30,
"email": "lisi@example.com"
}可视化工具方式:
POST /user_index/_doc/1
{
"name": "张三",
"age": 25,
"email": "zhangsan@example.com"
}2.3.3 查询数据
命令行方式:
# 查询所有文档
GET /user_index/_search
# 精确查询
GET /user_index/_search?q=name:张三
# 条件查询
GET /user_index/_search
{
"query": {
"match": {
"name": "张三"
}
}
}可视化工具方式:
GET /user_index/_search
{
"query": {
"match": {
"name": "张三"
}
}
}避坑指南 :查询 text 类型字段用
match,查询 keyword 类型字段用term。类型不匹配会导致查询结果为空!
2.4 核心操作速查表
// 索引操作
PUT /index_name // 创建索引
GET /index_name // 查看索引信息
DELETE /index_name // 删除索引
GET /_cat/indices?v // 查看所有索引
// 文档操作
POST /index/_doc/1 // 创建/更新文档(指定ID)
POST /index/_doc // 创建文档(自动生成ID)
GET /index/_doc/1 // 查询文档
DELETE /index/_doc/1 // 删除文档
// 批量操作
POST /_bulk // 批量操作(增删改)
GET /index/_search // 查询文档三、可视化管理模块
3.1 数据索引流程
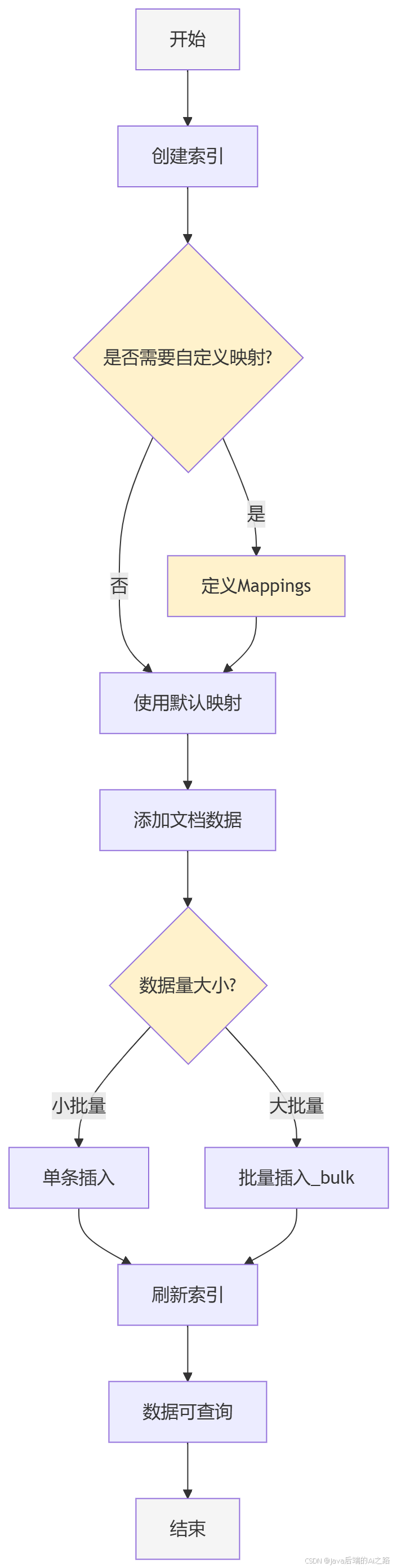
关键节点说明:
- 创建索引:定义索引名称和基本配置
- 定义 Mappings:指定字段类型和索引方式
- 批量插入 :使用
_bulkAPI 提升写入性能 - 刷新索引:使新数据可查询
新手必知 :ES 默认 1 秒刷新一次索引。如需立即查询,可在批量操作后调用
POST /index/_refresh
3.2 查询执行路径
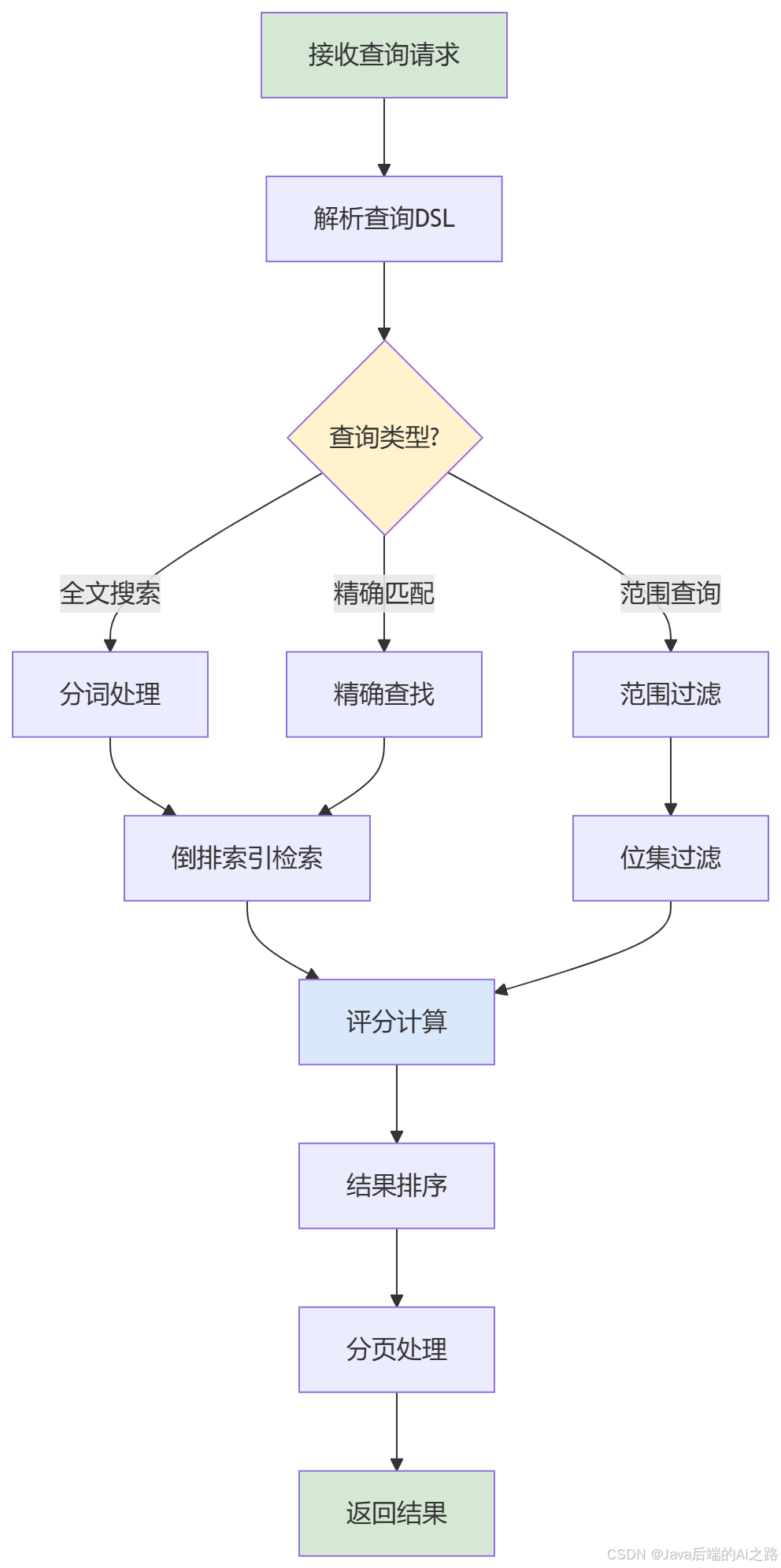
核心概念解析:
- 倒排索引:像书的索引页,快速定位关键词位置
- 评分计算:根据相关度排序结果
- 分页处理 :使用
from和size控制返回数量
高级选项 :复杂查询可使用 bool 查询组合多个条件。
3.3 集群部署架构
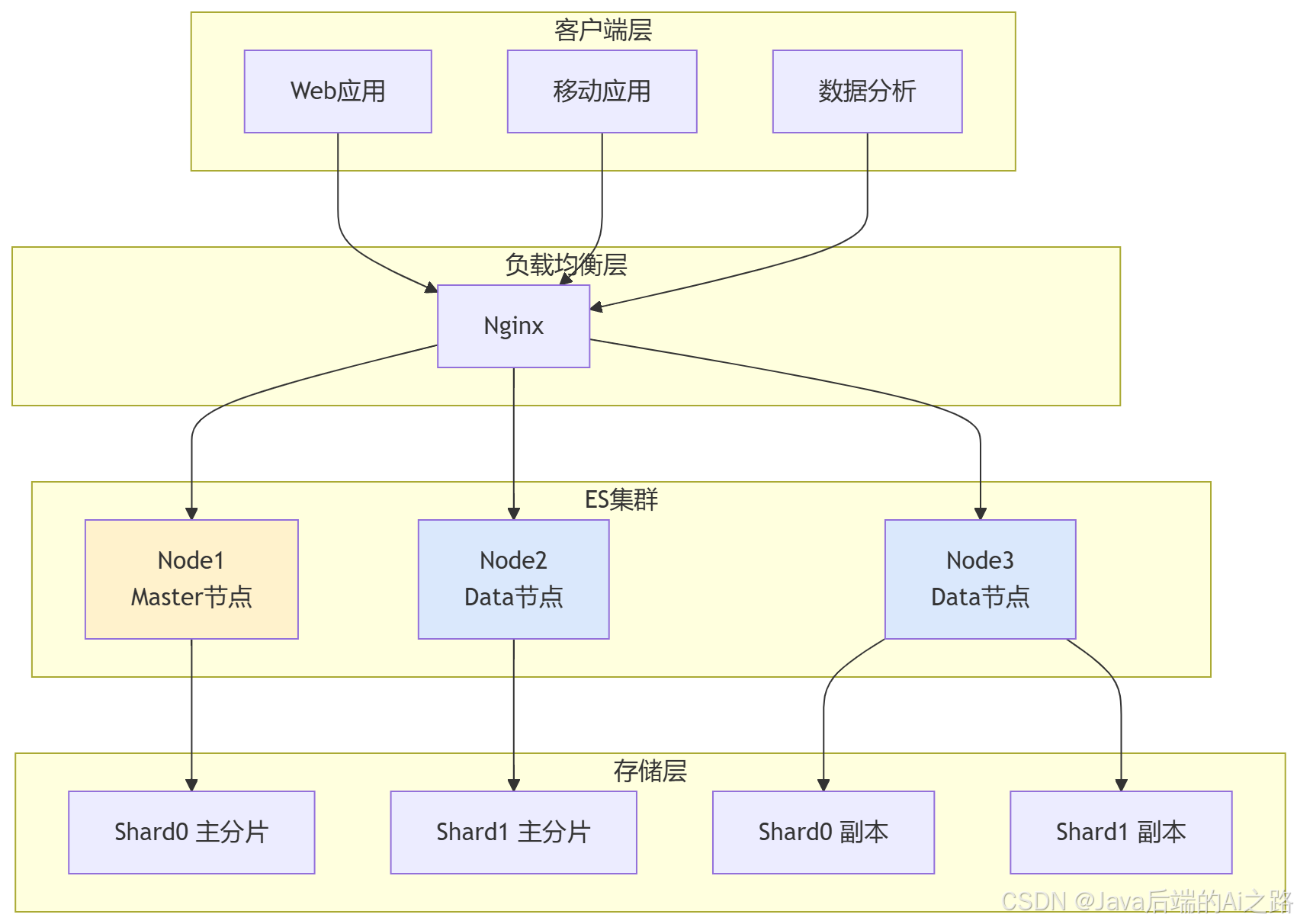
节点角色说明:
| 节点类型 | 职责 | 内存要求 |
|---|---|---|
| Master | 集群管理、元数据维护 | 低(4GB+) |
| Data | 数据存储、查询处理 | 高(16GB+) |
| Coordinating | 请求分发、结果聚合 | 中(8GB+) |
新手必知:单节点环境适合学习,生产环境至少 3 节点保证高可用。
3.4 Kibana 界面操作详解
3.4.1 Index Pattern 配置
步骤 1: 打开 Kibana → Management → Stack Management → Index Patterns
步骤 2: 点击"Create index pattern"
步骤 3 : 输入索引名称(如 user_index*,支持通配符)
步骤 4: 选择时间字段(可选,用于时间序列数据)
关键操作截图:
┌────────────────────────────────────────────┐
│ Index pattern name: user_index* │
│ │
│ Next step │
├────────────────────────────────────────────┤
│ Time field: create_time ▼ │
│ │
│ [I don't want to use a time field] │
│ │
│ Create index pattern │
└────────────────────────────────────────────┘功能区标注:
- Index pattern name:索引名称(支持通配符)
- Time field:时间字段(用于时序分析)
- Create index pattern:创建按钮
3.4.2 Discover 数据探索
主要功能:
- 实时数据浏览
- 字段过滤
- 条件查询
- 结果导出
操作截图:
┌────────────────────────────────────────────────────────┐
│ Query bar: name:张三 ▼ [Refresh] [Add filter] │
├────────────────────────────────────────────────────────┤
│ Available Fields (20) Documents (156) │
│ ☑ _id ┌──────────────────┐ │
│ ☑ _source │ Doc 1 │ │
│ ☑ name │ _id: 1 │ │
│ ☑ age │ name: 张三 │ │
│ ☑ email │ age: 25 │ │
│ ☑ create_time │ email: xxx │ │
│ └──────────────────┘ │
│ [Document table] │
└────────────────────────────────────────────────────────┘关键操作:
- 在 Query bar 输入查询条件
- 勾选字段显示
- 点击 Refresh 刷新数据
- 使用 Add filter 添加过滤条件
3.4.3 Visualize 可视化图表
创建步骤:
- 点击左侧菜单"Visualize"
- 点击"Create visualization"
- 选择图表类型(折线图、饼图、柱状图等)
- 配置数据源和聚合方式
示例:用户年龄分布饼图
{
"index_pattern": "user_index",
"chart_type": "pie",
"metric": "count",
"bucket": "terms",
"field": "age",
"size": 10
}效果图示:
用户年龄分布
┌─────────────────┐
│ │
│ ●● 25岁 │
│ ●●●● 30岁 │
│ ●●●●● 35岁 │
│ ●●● 40岁 │
│ │
└─────────────────┘3.5 Elasticsearch-Head 插件
3.5.1 插件安装
# 方式1:Chrome扩展(推荐)
# 搜索"Elasticsearch Head"安装
# 方式2:独立运行
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
# 默认地址: http://localhost:91003.5.2 界面功能
主要功能:
- 集群状态监控
- 索引管理
- 数据浏览
- 查询执行
界面布局:
┌─────────────────────────────────────────────────────┐
│ 集群健康: 🟢 green 节点数: 1 数据: 9200 │
├─────────────────────────────────────────────────────┤
│ 索引列表 数据浏览 │
│ ┌────────────┐ ┌──────────────────────┐ │
│ │user_index │ │查询框: │ │
│ │ docs: 100 │ │GET /user_index/_search│ │
│ │ size: 1MB │ │ │ │
│ └────────────┘ │[执行查询] │ │
│ └──────────────────────┘ │
│ 结果展示区域 │
└─────────────────────────────────────────────────────┘关键功能标注:
- 集群健康:绿色=健康,黄色=警告,红色=异常
- 索引列表:显示所有索引及其状态
- 查询框:执行查询语句
- 结果展示:显示查询结果
3.6 动态词云:ES 高频操作命令
{
"title": {
"text": "ES高频操作命令",
"left": "center",
"textStyle": {
"fontSize": 18,
"fontWeight": "bold"
}
},
"tooltip": {
"show": true
},
"series": [
{
"type": "wordCloud",
"width": "100%",
"height": "100%",
"gridSize": 5,
"sizeRange": [60, 80],
"rotationRange": [0, 0],
"drawOutOfBound": false,
"data": [
{
"name": "_search",
"value": 100,
"textStyle": {
"color": "#d97757"
}
},
{
"name": "_doc",
"value": 90,
"textStyle": {
"color": "#6a9bcc"
}
},
{
"name": "_index",
"value": 85,
"textStyle": {
"color": "#788c5d"
}
},
{
"name": "_mapping",
"value": 75,
"textStyle": {
"color": "#c4a35a"
}
},
{
"name": "_bulk",
"value": 70,
"textStyle": {
"color": "#8b7cb6"
}
},
{
"name": "_refresh",
"value": 65,
"textStyle": {
"color": "#c97b84"
}
},
{
"name": "_cluster",
"value": 60,
"textStyle": {
"color": "#5d8c8c"
}
},
{
"name": "_settings",
"value": 55,
"textStyle": {
"color": "#a67c52"
}
},
{
"name": "match",
"value": 50,
"textStyle": {
"color": "#b0aea5"
}
},
{
"name": "term",
"value": 45,
"textStyle": {
"color": "#d97757"
}
},
{
"name": "bool",
"value": 40,
"textStyle": {
"color": "#6a9bcc"
}
},
{
"name": "filter",
"value": 35,
"textStyle": {
"color": "#788c5d"
}
},
{
"name": "range",
"value": 30,
"textStyle": {
"color": "#c4a35a"
}
},
{
"name": "aggs",
"value": 25,
"textStyle": {
"color": "#8b7cb6"
}
},
{
"name": "scroll",
"value": 20,
"textStyle": {
"color": "#c97b84"
}
}
]
}
]
}命令解析:
| 命令 | 使用频率 | 用途 |
|---|---|---|
| _search | ★★★★★ | 数据查询 |
| _doc | ★★★★★ | 文档操作 |
| _index | ★★★★☆ | 索引管理 |
| _mapping | ★★★★☆ | 字段映射 |
| _bulk | ★★★★☆ | 批量操作 |
| _refresh | ★★★☆☆ | 索引刷新 |
四、集群状态监控
4.1 集群健康指标
健康等级:
| 状态 | 颜色 | 说明 | 处理建议 |
|---|---|---|---|
| Green | 🟢 | 所有主分片和副本都正常 | 无需处理 |
| Yellow | 🟡 | 主分片正常,部分副本未分配 | 检查节点数,增加节点 |
| Red | 🔴 | 主分片未分配 | 紧急处理,检查数据 |
查询命令:
# 查看集群健康
GET /_cluster/health?pretty
# 详细健康信息
GET /_cluster/health?pretty&level=shards可视化监控(Kibana Stack Monitoring):
集群健康度趋势
┌────────────────────────────────────────┐
│ 100% │██████████████████████████ │
│ 80% │████████████████████████████ │
│ 60% │████████████████████████████ │
│ 40% │████████████████████████████ │
│ 20% │████████████████████████████ │
│ 0% └─────────────────────────────── │
│ 10:00 12:00 14:00 16:00 18:00│
└────────────────────────────────────────┘4.2 关键性能指标
指标说明:
- CPU 使用率:建议 <80%
- 内存使用率:建议 <85%
- 磁盘使用率:建议 <70%
- JVM 堆内存:建议 <75%
监控命令:
# 节点统计信息
GET /_nodes/stats?pretty
# 索引统计信息
GET /_index/user_index/_stats?pretty
# 集群状态
GET /_cluster/state?pretty避坑指南:JVM 堆内存设置不要超过物理内存的 50%,避免频繁 GC 导致性能下降。
五、避坑指南
⚠️ 避坑 1:字段类型选择错误
问题描述:
// 错误示例:手机号用text类型
{
"phone": {
"type": "text"
}
}
// 查询:无法精确匹配
GET /user/_search
{
"query": {
"term": {
"phone": "13800138000"
}
}
// 结果:查询为空!
}正确做法:
{
"phone": {
"type": "keyword" // 精确匹配用keyword
}
}经验总结:
- 精确匹配 → keyword
- 全文搜索 → text
- 手机号/身份证 → keyword
⚠️ 避坑 2:分片数设置不当
问题描述:
# 错误示例:单节点设置过多分片
PUT /user_index
{
"settings": {
"number_of_shards": 10 // 单节点10个分片!
}
}
// 结果:性能下降,资源浪费正确做法:
// 新手建议:单节点1个分片
PUT /user_index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
// 生产环境:根据节点数调整
// 分片数 = 节点数 × (1-2)经验总结:
- 小数据量(<10GB):1-2 分片
- 中数据量(10-100GB):3-5 分片
- 大数据量(>100GB):根据节点数调整
⚠️ 避坑 3:查询性能优化不足
问题描述:
// 错误示例:查询所有文档然后过滤
GET /user_index/_search
{
"query": {
"match_all": {}
},
"size": 10000 // 一次性取1万条!
// 结果:性能极差,超时
}正确做法:
// 使用scroll分批查询
GET /user_index/_search
{
"query": {
"match": {
"name": "张三"
}
},
"size": 100, // 每次取100条
"scroll": "1m" // 游标保持1分钟
}优化建议:
- 避免深分页(from + size > 10000)
- 使用 scroll 或 search_after
- 合理使用 filter 缓存
- 避免通配符查询
六、学习资源包
6.1 Docker 快速部署脚本
文件名 : es-deploy.sh
#!/bin/bash
# Elasticsearch快速部署脚本
# 使用方法: bash es-deploy.sh
echo "=== Elasticsearch部署脚本 ==="
# 创建网络
echo "创建Docker网络..."
docker network create es-net 2>/dev/null || echo "网络已存在"
# 启动ES
echo "启动Elasticsearch..."
docker run -d \
--name elasticsearch \
--net es-net \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "xpack.security.enabled=false" \
elasticsearch:8.11.0
# 启动Kibana
echo "启动Kibana..."
docker run -d \
--name kibana \
--net es-net \
-p 5601:5601 \
-e "ELASTICSEARCH_HOSTS=http://elasticsearch:9200" \
kibana:8.11.0
echo "=== 部署完成 ==="
echo "ES访问地址: http://localhost:9200"
echo "Kibana访问地址: http://localhost:5601"
echo "查看ES状态: curl http://localhost:9200/_cluster/health?pretty"使用方法:
# 保存脚本
chmod +x es-deploy.sh
# 执行部署
bash es-deploy.sh6.2 常用命令速查表
文件名 : es-cheatsheet.md
# Elasticsearch命令速查表
## 索引管理
```bash
# 创建索引
PUT /index_name
# 查看索引信息
GET /index_name
# 删除索引
DELETE /index_name
# 查看所有索引
GET /_cat/indices?v文档操作
# 创建文档(指定ID)
POST /index/_doc/1
{
"field": "value"
}
# 创建文档(自动生成ID)
POST /index/_doc
{
"field": "value"
}
# 查询文档
GET /index/_doc/1
# 更新文档
POST /index/_update/1
{
"doc": {
"field": "new_value"
}
}
# 删除文档
DELETE /index/_doc/1查询操作
# 查询所有文档
GET /index/_search
# 精确查询(keyword字段)
GET /index/_search
{
"query": {
"term": {
"field": "value"
}
}
}
# 全文搜索(text字段)
GET /index/_search
{
"query": {
"match": {
"field": "value"
}
}
}
# 多条件查询
GET /index/_search
{
"query": {
"bool": {
"must": [
{ "match": { "field1": "value1" } }
],
"filter": [
{ "term": { "field2": "value2" } }
]
}
}
}
# 范围查询
GET /index/_search
{
"query": {
"range": {
"age": {
"gte": 18,
"lte": 30
}
}
}
}聚合操作
# 统计总数
GET /index/_search
{
"size": 0,
"aggs": {
"total_count": {
"value_count": {
"field": "_id"
}
}
}
}
# 分组统计
GET /index/_search
{
"size": 0,
"aggs": {
"group_by_field": {
"terms": {
"field": "field_name"
}
}
}
}批量操作
# 批量插入
POST /_bulk
{ "index": { "_index": "index_name", "_id": "1" } }
{ "field": "value1" }
{ "index": { "_index": "index_name", "_id": "2" } }
{ "field": "value2" }
# 批量删除
POST /_bulk
{ "delete": { "_index": "index_name", "_id": "1" } }
{ "delete": { "_index": "index_name", "_id": "2" } }集群管理
# 查看集群健康
GET /_cluster/health?pretty
# 查看节点信息
GET /_nodes?pretty
# 查看集群状态
GET /_cluster/state?pretty
# 查看分片信息
GET /_cat/shards?v
6.3 推荐学习资源
官方文档:
-
Elasticsearch官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
-
Kibana官方文档: https://www.elastic.co/guide/en/kibana/current/index.html
学习路径:
-
第1天:环境搭建 + 基础操作
-
第2天:数据查询 + 聚合分析
-
第3天 :可视化 + 性能优化
进阶学习:
- 深入理解倒排索引原理
- 掌握复杂查询DSL
- 学习集群架构设计
- 了解性能调优技巧
七、问题解决路径
7.1 常见问题排查
问题1:ES无法启动
检查清单:□ 端口是否被占用(9200/9300)□ 内存是否足够(JVM 堆内存设置)□ 磁盘空间是否充足□ 配置文件是否正确(elasticsearch.yml)
解决方法:docker logs elasticsearchnetstat -tulpn | grep 9200
问题2:查询结果为空
检查清单:□ 索引是否存在□ 字段类型是否正确□ 查询语法是否正确□ 是否需要 refresh 索引
解决方法:GET /*cat/indices?vGET /index/*mappingPOST /index/_refresh
问题3:性能缓慢
检查清单:□ 分片数是否合理□ 查询是否使用了 filter□ 索引是否需要 refresh□ JVM 内存是否溢出
解决方法:GET /*cat/shards?vGET /*nodes/stats?pretty调整分片数和副本数
7.2 社区支持
官方论坛:
-
Elastic Discuss: https://discuss.elastic.co/
中文社区:
-
Elastic中文社区: https://elasticsearch.cn/
转载声明:本文原创,转载请注明出处。