Transformer实战------视觉提示模型
-
- [0. 前言](#0. 前言)
- [1. CLIPSeg](#1. CLIPSeg)
- [2. 实现 CLIPSeg](#2. 实现 CLIPSeg)
- 相关链接
0. 前言
提示模型 (Prompt-based models) 在人工智能的许多领域中备受关注。这类模型能够以某种模式作为指导,并通过理解该模式生成相应的输出。提示可以是多种形式或数据格式,包括文本提示和视觉提示。文本提示是一段自由文本,用于指示模型应执行的任务或输出的内容;而视觉提示则是一种视觉引导,帮助模型理解任务或指令本身。
1. CLIPSeg
例如,CLIP 等模型能够同时理解图像和文本,并将它们映射到同一个向量空间中。在这个向量空间中,语义相近的文本和图像(即文本描述的场景或物体与图像内容一致)在向量空间中的距离更近。为了更好地利用模型的能力,可以通过引入外部数据来增强模型的性能。例如,假设不仅要搜索图像,还要在图像中搜索特定物体。虽然这可以通过语义分割或目标检测实现,但在我们的场景中,文本是自由格式的,这意味着用户可以自由输入任何内容,而不受模型已知或训练过的物体类别的限制。在这种情况下,视觉提示或文本提示的方法非常有用。
CLIPSeg 是一种结合文本和视觉提示的方法,下图展示了该模型的工作原理:
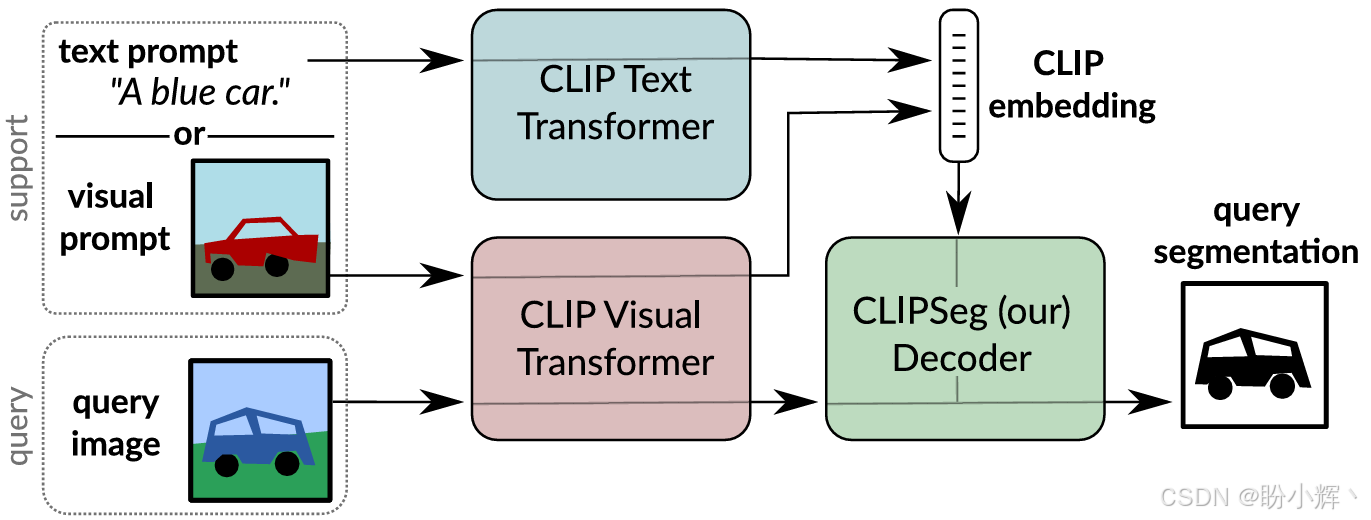
如图所示,CLIPSeg 是一个基于 CLIP 视觉和文本 Transformer 训练的解码器。这个解码器接收两种不同的输入:一种是原始图像,另一种是支持信息(可以是文本或另一张图像)。
2. 实现 CLIPSeg
(1) 首先,下载并加载样本图像:
python
from PIL import Image
import requests
url = "https://farm4.staticflickr.com/3487/3925656789_1b64654c91_z.jpg"
image = Image.open(requests.get(url, stream=True).raw)(2) 获取图像后,加载 CLIPSeg 模型:
python
from transformers import CLIPSegProcessor, CLIPSegForImageSegmentation
processor = CLIPSegProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")(3) 对于文本提示,我们可以使用一组描述目标物体的文本来帮助模型定位我们要找的物体:
python
prompts = ["hat", "ball", "player", "red shirt"]
inputs = processor(
text=prompts,
images=[image] * len(prompts),
padding="max_length",
return_tensors="pt",
)(4) 准备好模型所需的提示和相应的输入后,生成模型的输出:
python
outputs = model(**inputs)
preds = outputs.logits.unsqueeze(1)
展示每个输出的预测分割结果:
import matplotlib.pyplot as plt
import torch
_, ax = plt.subplots(1, 5, figsize=(15, 4))
[a.axis("off") for a in ax.flatten()]
ax[0].imshow(image)
[ax[i + 1].imshow(torch.sigmoid(preds.detach()[i][0])) for i in range(4)]
[ax[i + 1].text(0, -15, prompts[i]) for i in range(4)]输出结果如下所示:

除了利用文本提示使用此模型外,我们也可以使用视觉提示作为输入。
(5) 假设我们有一张棒球的图像,并且希望搜索这颗球的位置:
python
url = "Baseball_(crop).jpg"
prompt = Image.open(url)(6) 获取棒球图像后,对图像和提示进行编码,并根据提示调整模型:
python
encoded_image = processor(images=[image], return_tensors="pt")
encoded_prompt = processor(images=[prompt], return_tensors="pt")
outputs = model(**encoded_image, conditional_pixel_values = encoded_prompt.pixel_values)(7) 得到输出后,将其可视化:
python
preds = outputs.logits.unsqueeze(1)
preds = torch.transpose(preds, 0, 1)
_, ax = plt.subplots(1, 2, figsize=(6, 4))
[a.axis('off') for a in ax.flatten()]
ax[0].imshow(image)
ax[1].imshow(torch.sigmoid(preds.detach()[0][0]))结果如下图所示:
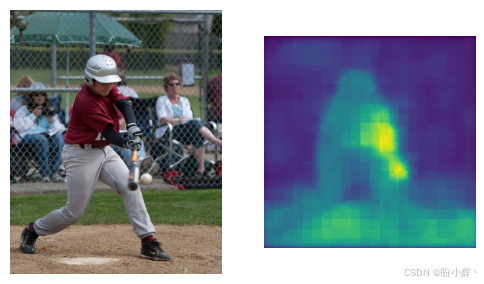
如分割图像所示,球以及一些相关部分(如球棒)被高亮显示。
相关链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类
Transformer实战(18)------微调Transformer语言模型进行回归分析
Transformer实战(19)------微调Transformer语言模型进行词元分类
Transformer实战(20)------微调Transformer语言模型进行问答任务
Transformer实战(21)------文本表示(Text Representation)
Transformer实战(22)------使用FLAIR进行语义相似性评估
Transformer实战(23)------使用SBERT进行文本聚类与语义搜索
Transformer实战(24)------通过数据增强提升Transformer模型性能
Transformer实战(25)------自动超参数优化提升Transformer模型性能
Transformer实战(26)------通过领域适应提升Transformer模型性能
Transformer实战(27)------参数高效微调(Parameter Efficient Fine-Tuning,PEFT)
Transformer实战(28)------使用 LoRA 高效微调 FLAN-T5
Transformer实战(29)------大语言模型(Large Language Model,LLM)
Transformer实战(30)------Transformer注意力机制可视化
Transformer实战(31)------解释Transformer模型决策
Transformer实战(32)------Transformer模型压缩
Transformer实战(33)------高效自注意力机制
Transformer实战(34)------多语言和跨语言Transformer模型
Transformer实战(35)------跨语言相似性任务
Transformer实战(36)------Transformer模型部署
Transformer实战(37)------Transformer模型训练追踪与监测
Transformer实战(38)------视觉Transformer