作者:来自 Elastic Miguel Luna

用于构建 OpenTelemetry Collection 架构的概念框架 ------ 包括 edge、processing 和 resilience 层,将它们组合成适合你环境的正确 pipeline。
大多数 OpenTelemetry 教程都会在同一个地方结束:应用通过 SDK 完成 instrumentation,将 traces 导出到单个 collector,再转发到后端。这可以工作。然后生产环境出现了。
流量增长。团队希望从 traces 派生 metrics。后端因维护宕机,你丢失了一小时的 telemetry。合规要求规定在数据离开集群之前必须去除 PII。突然之间,单个 collector 已经不够用了 ------ 问题变成:架构实际上应该是什么样?
OpenTelemetry Collector 被设计为可组合的。它可以以多种部署模式运行,被串联成 pipelines,并且可以在每个阶段独立扩展。但文档描述的是各个独立组件,而不是如何思考将它们组装在一起。本文正是关于这种思考方式。
接下来介绍的是一个用于理解 collector 架构的概念框架 ------ 而不是一组固定模板。这里描述的构建块是参考点。在实际中,它们会组合、重叠,并根据你的约束进行调整。例如,一个 tail sampling 层可能还需要基于 Kafka 的 resilience。一个 gateway 在低流量时可能会承担 sampling 层的角色。目标是充分理解这些概念,从而为你的场景组合出合适的架构,而不是从现成方案中直接选择。
三个概念层
将 collector 架构分为三个层次来理解会很有帮助:edge 、processing 和 resilience。这些并不是必须作为独立部署存在的物理层 ------ 它们是关注点的分类。一个 collector 可以覆盖多个层。一个复杂部署在同一层中也可能包含多个组件。这些层是思考工具,而不是部署图。

边缘层:telemetry 如何进入 pipeline
边缘层关注的是第一跳 ------ telemetry 如何从你的应用和基础设施进入 pipeline。在这个阶段,collector 以两种根本不同的方式收集数据。像 filelog 和 hostmetrics 这样的 pull 型 receivers 会主动获取数据 ------ 从磁盘 tail 日志文件或从主机抓取系统级 metrics。像 otlp 这样的 push 型 receivers 会监听发送给它们的数据 ------ 通过 OpenTelemetry SDK 完成 instrumentation 的应用会将 traces、metrics 和 logs 直接导出到 collector 的 OTLP endpoint。一个典型的边缘 collector 通常同时运行两者:pull receivers 用于收集应用本身不了解的基础设施 telemetry,push receivers 用于接收 SDK 生成的应用 telemetry。常见的部署模式有多种,具体选择取决于你的环境以及需要收集的数据。
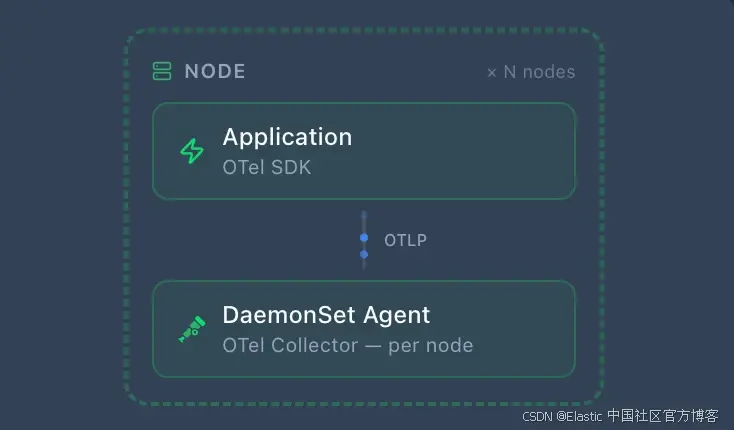
DaemonSet Agent ------ 每个 Kubernetes 节点运行一个 OpenTelemetry Collector,以 DaemonSet 方式部署。应用将数据导出到同一节点上的 agent(通常通过 Kubernetes Downward API 使用 status.hostIP:4317)。该 agent 还会通过 filelog receiver 从磁盘 tail 容器日志文件,并通过 hostmetrics receiver 抓取主机级 metrics。这是最常见的 Kubernetes 模式,因为它通过一次部署同时处理应用和基础设施 telemetry,并且应用只需要知道 localhost。
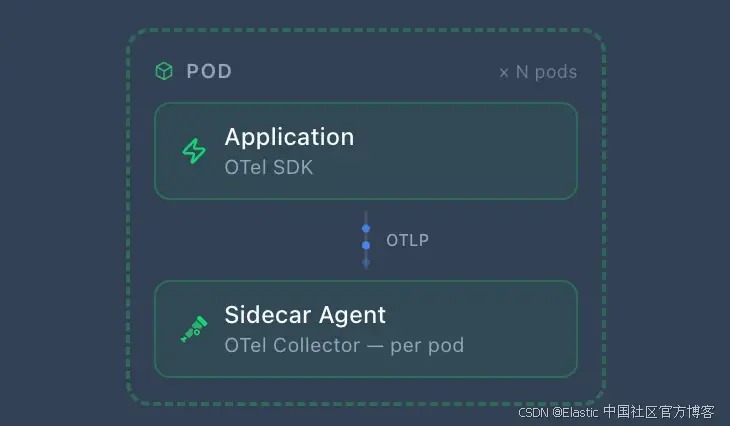
Sidecar Agent ------ 每个 pod 运行一个 OpenTelemetry Collector,作为 sidecar 容器部署。每个服务都有自己的 collector,并使用自定义配置。在像 AWS Fargate 或 Azure Container Apps 这样的托管容器平台上(这些平台不支持 DaemonSets),这是必需的;当不同服务有不同处理需求时,这种方式也很有用。当与 DaemonSet 一起运行时,sidecar 负责处理应用 telemetry,而 DaemonSet 独立收集节点级 telemetry ------ 应用不会同时向两者发送数据。
Host Agent------ 在裸机或 VM 主机上以 systemd 服务运行的独立 OpenTelemetry Collector。它与 DaemonSet agent 的作用相同,但在 Kubernetes 之外:收集主机 metrics、tail 日志文件,并接收来自本地应用的 OTLP 数据。
Direct SDK Export------ 应用直接将数据导出到下一阶段(gateway 或后端),不经过本地 collector。这是最简单的方式,但仅在不需要收集基础设施数据时适用。对于日志收集,推荐模式仍然是写入 stdout 并使用带有 filelog receiver 的 collector ------ 即使 SDK 已直接导出 traces 和 metrics。
这些模式并不是互斥的。一个 Kubernetes 集群可能同时运行 DaemonSet agents 来收集基础设施数据,并为需要自定义处理的服务运行 sidecars。一个 VM 环境可能对部分服务使用 host agents,对其他服务使用 direct SDK export。边缘层的关键在于根据工作负载匹配合适的采集方式,而不是为所有场景选择单一模式。
处理层:集中策略、采样和转换
并非所有架构都需要处理层。如果你的边缘 collectors 可以直接导出到后端,并且你不需要集中策略,可以跳过该层以保持简单性。但有些场景会推动你采用集中处理 ------ 实现方式可以从单个 gateway 到多阶段 pipeline。
集中策略(Gateway)------ 一组位于边缘 collectors 与后端之间的 OpenTelemetry Collectors。在这里你可以为所有服务统一执行过滤、转换和 PII 脱敏。同时,这里也是管理后端凭证的地方 ------ 边缘 collectors 通过 OTLP 将数据发送到 gateway,只有 gateway 持有 API keys。凭证隔离通常是团队引入 gateway 的主要原因。
副本数量根据数据量进行扩展。在低流量(低于 1K events/sec)时,2 个副本并与工作负载共置即可。在中等流量时,使用 3--5 个副本并部署在专用节点池。在高流量时,使用 5--20+ 个副本,甚至可能部署在单独的集群中。这是一个通用经验法则,你应根据具体需求进行调整,因为不同负载类型之间的流量差异可能很大。

基于尾部的采样 ------ 需要考虑完整 trace 的采样决策(例如"保留所有包含错误的 traces,对成功的 traces 采样 10%")要求同一 trace 的所有 spans 都到达同一个 collector 实例。这可以通过使用 loadbalancingexporter 并设置 routing_key: traceID 来实现,从而将同一 trace 的 spans 一致地路由到同一个下游 collector。

这里有一个关键的细微点:如果你使用 spanmetrics connector 从 traces 派生 span metrics(RED metrics),派生必须在采样之前完成。否则,你的 metrics 只反映被采样的子集,而不是实际流量。正确的模式是在采样阶段使用两步 pipeline:
- 接收 traces,从 100% 流量中派生 spanmetrics,并通过 forward connector 转发。
- 对转发后的 traces 应用 tail_sampling,仅导出被保留的 traces。
- 一个独立的 metrics pipeline 用于导出派生的 RED metrics。
这样可以确保无论采样率如何,metrics 都是准确的。
关于 processing 的关键点是,这些能力 ------ gateway 策略、尾部采样、span metrics 派生 ------ 并不是独立的产品或固定模块。它们都是同一个 OpenTelemetry Collector 的不同配置。在低流量情况下,一个 gateway 部署可以同时处理策略执行、采样和 metrics 派生。在高流量情况下,你可能会将它们拆分为独立阶段以实现独立扩展。架构应适应你的规模,而不是反过来。
韧性层:当后端不可用时会发生什么
韧性层决定了在后端故障或 collector 重启期间你可以接受多少数据丢失。这不是一个单独附加的层 ------ 而是可以应用于 pipeline 任意阶段的一种属性。
内存队列 ------ 默认方式。collector 的 sending_queue 会使用指数退避重试失败的导出。如果 collector 进程崩溃或重启,队列中的数据会丢失。这适用于开发环境或可以容忍部分数据丢失的工作负载。
持久化队列(WAL) ------ file_storage 扩展会在导出前将排队数据写入磁盘。如果 collector 崩溃,重启后会从中断处继续。在 Kubernetes 中,这需要 PersistentVolumeClaim。这是大多数生产工作负载的合适选择 ------ 在不引入外部消息总线复杂性的情况下,可以应对 collector 重启和短暂的后端故障。
Kafka 缓冲 ------ 在 collectors 和后端之间引入外部 Kafka 集群。生产者 collector 写入 Kafka topics;消费者 collector 从 Kafka 读取并导出到后端。这提供了最强的数据持久性保障 ------ Kafka 可以在长时间故障期间缓冲数小时的 telemetry,并支持重放。但这也带来了显著的运维复杂性。

需要理解的关键点是,resilience 与其他层是正交的。你可以在 edge agent、gateway 或 sampling 层中添加持久化队列。你可以在 gateway 前、sampling 层前或后端前引入 Kafka。一个需要在长时间故障中保持可用的 tail sampling 部署,可能会使用基于 Kafka 的摄取 ------ 将看似两个独立"模块"的能力组合到同一个阶段中。这些构建块可以根据你需要防护的场景自由组合。
从哪里开始构建你的架构
Agent + Gateway 的两层模式是事实上的生产标准,被绝大多数在规模化运行 OpenTelemetry 的组织采用。每个节点上的 DaemonSet agents 负责本地采集 ------ 通过 filelog 和 hostmetrics 拉取基础设施 telemetry,通过 OTLP 接收应用 telemetry ------ 而集中式 gateway 集群负责执行策略、管理凭证并将数据导出到后端。在 gateway 上使用持久化队列(WAL)可以在不依赖外部系统的情况下防护后端故障。
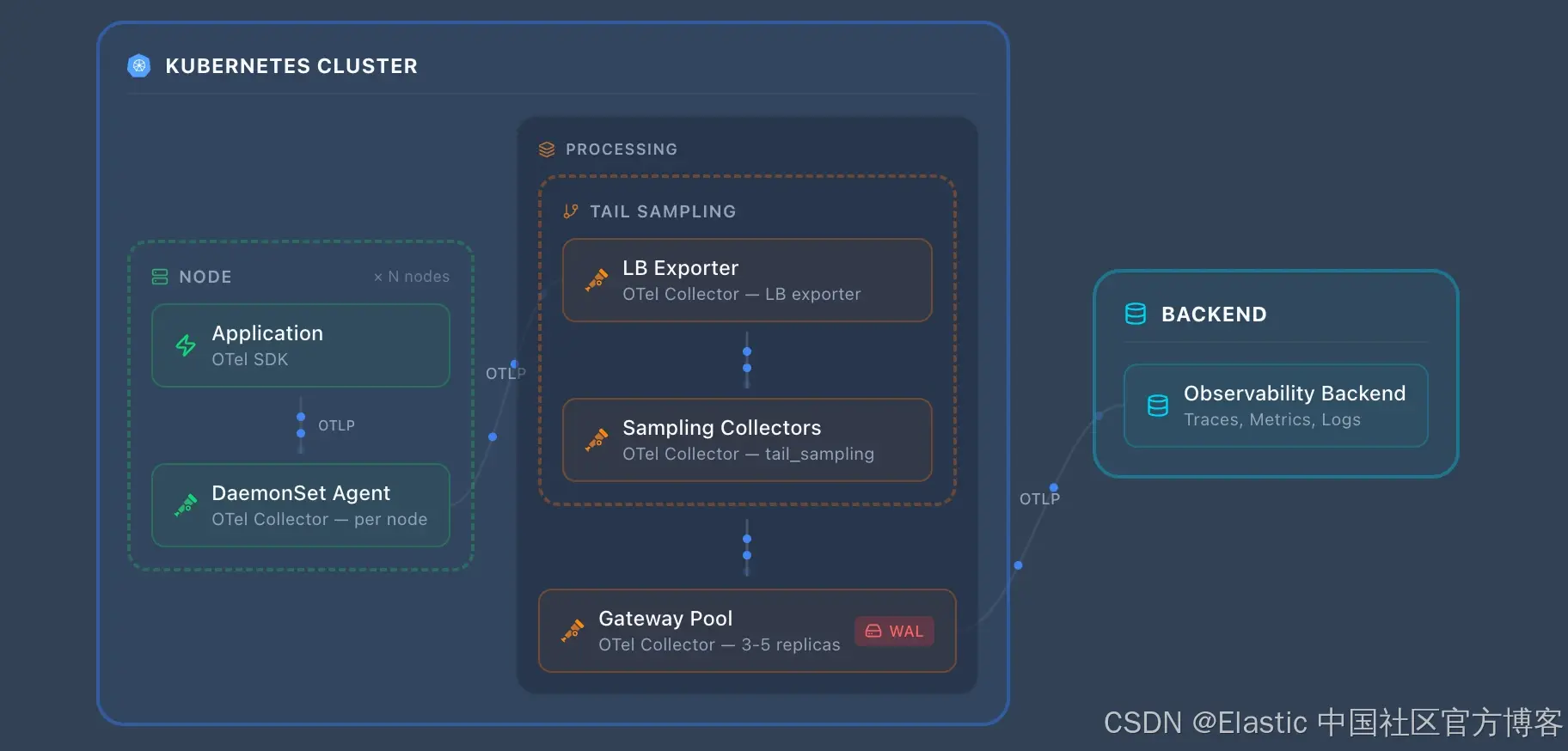
其他所有配置要么是对这种模式的简化,要么是在其基础上的扩展。较小的环境可能会去掉 gateway,直接从 agents 导出。较大的环境可能会增加一个带有基于 traceID 负载均衡的 tail sampling 层、用于增强韧性的 Kafka 缓冲,或者在采样前进行 span metrics 派生。前面章节中描述的构建块 ------ edge、processing、resilience ------ 就是你在这个基础上添加或移除的模块。
关键是从两层模式开始,并逐步演进:
- 需要凭证隔离或集中式 PII 脱敏?你已经有 gateway。
- 需要基于尾部的采样?在 agents 和 gateway 之间添加 load-balancing exporter 和 sampling 层。
- 需要在长时间故障期间提供数小时缓冲?在 agents 和 processing 层之间插入 Kafka。
- 运行在 Fargate 或 Azure Container Apps 上?将 DaemonSet agents 替换为 sidecars ------ pipeline 的其余部分保持不变。
从这里开始。随着需求增长逐步添加模块。架构应适应你的规模,而不是反过来。
决定架构走向的关键问题
在设计 collector 架构时,以下问题决定了你需要哪些模式:
| 问题 | 影响 |
|---|---|
| 我需要基础设施 telemetry(主机指标、磁盘日志)吗? | 决定你是否需要本地 collector 或可以使用直接 SDK 导出 |
| 我运行在托管容器平台上吗(Fargate、ACA)? | 必须使用 sidecar 模式,而不是 DaemonSet |
| 我需要集中式过滤、PII 脱敏或凭证隔离吗? | 增加一个 gateway 阶段 |
| 我需要基于尾部的采样吗? | 增加一个带 load-balancing exporter 和 traceID 路由的采样阶段 |
| 我想要 span 派生的 metrics(RED metrics)吗? | 在两步 pipeline 中采样前需要 spanmetrics |
| 在故障期间可接受多少数据丢失? | 决定使用内存队列、持久化队列还是 Kafka ------ 应用于需要保护的阶段 |
| 我预计的数据量是多少? | 决定功能能否共置于单个部署,还是需要独立阶段 |
这些问题的答案并不对应单一的"正确"架构。它们只是约束了设计空间,在这些约束内,你需要在简化和功能之间进行权衡。
交互式探索这些模式
如果你希望探索这些构建块如何组合,而不是手动组装它们,OpenTelemetry Blueprints 是一个开源工具,可以根据你的需求生成参考架构。
切换你的环境、信号类型、数据量、韧性和处理需求 ------ 即可获得一个组合好的图表,包含动画数据流、交互式提示,以及可以直接在 OTelBin 中打开验证的参考 collector 配置。
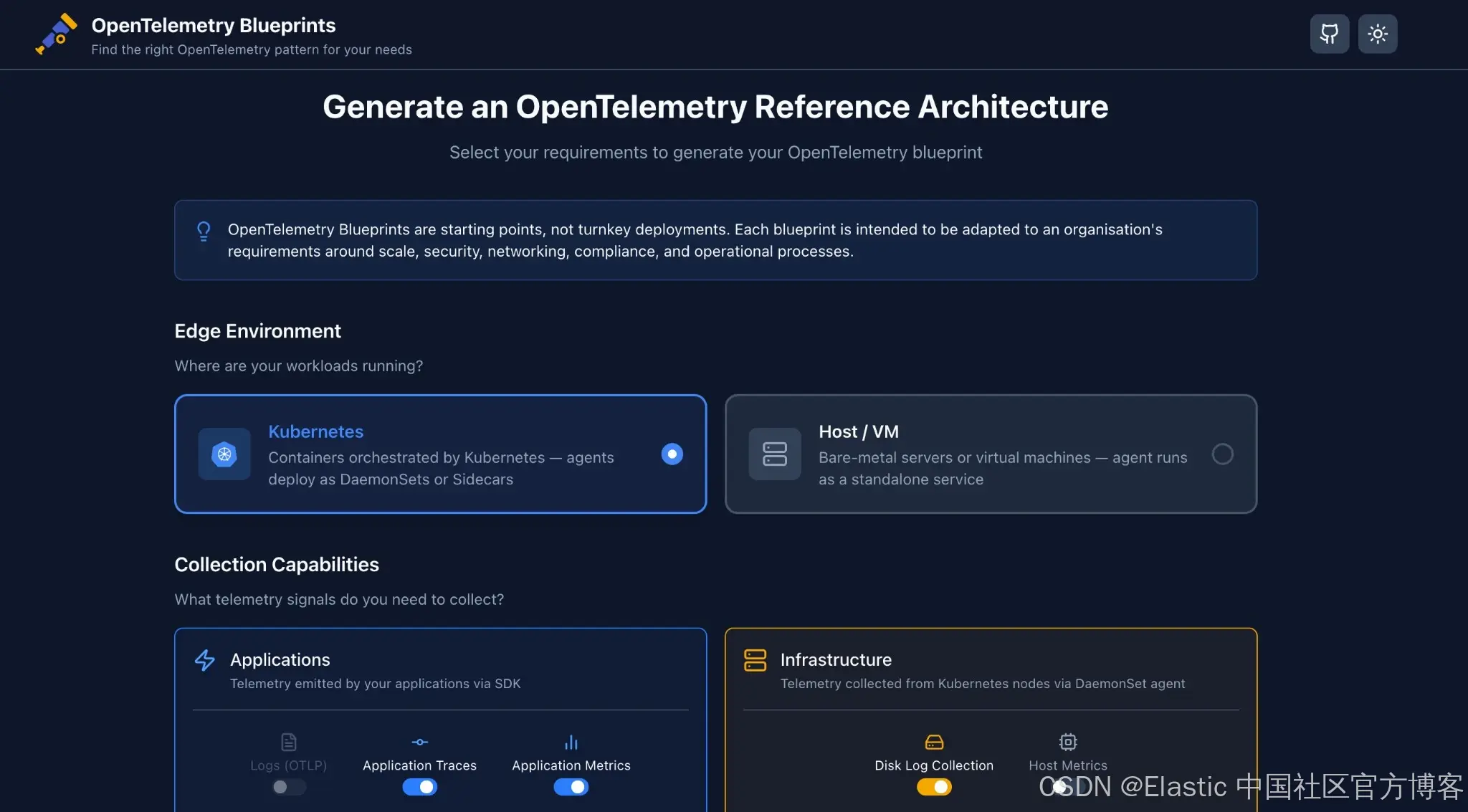
生成的配置通过 OTLP 导出,因此它们可与任何 OTLP 兼容的后端一起使用 ------ 包括 Elastic Observability,它原生接收并存储 OTLP traces、metrics 和 logs。
Blueprints 生成的架构是参考组合 ------ 用于理解构建块如何配合,而不是现成可用的部署。每个架构都应根据你组织的规模、安全、网络和合规要求进行调整。在你的环境中,这些模式可能组合或重叠的方式与其他人的不同,这正是重点所在。
开始使用
这里描述的架构通过 OTLP 导出,因此可与任何兼容后端一起使用。如果你还没有后端,最快看到 telemetry 全流程的方法是使用 Elastic Observability ------ 它原生接收 OTLP traces、metrics 和 logs,无需额外配置。
-
在 Elastic Cloud Serverless 上开始免费试用 ------ 无需信用卡。
-
将你的 collector 的 OTLP exporter 指向托管 OTLP endpoint。
-
在几分钟内在 Kibana 中探索你的 traces、metrics 和 logs。
深入学习资源:
原文:https://www.elastic.co/observability-labs/blog/opentelemetry-collector-reference-architectures