引言:为什么需要消息防重?
在网络通信、分布式系统以及物联网设备中,消息重复是一个常见且棘手的问题。想象一下这样的场景:
一个支付请求因网络抖动被客户端发送了两次
传感器数据在传输过程中因确认超时被重传
设备控制指令因响应延迟被重复执行
如果不加以处理,这些重复消息可能导致重复扣款、数据统计错误或设备状态异常。今天,我们将深入解析一个名为 oam_msgid 的轻量级C语言防重模块,探讨其设计原理、实现优化,并提供可直接使用的生产级代码。
一、模块核心用途解析
oam_msgid模块本质上实现了一个带自动过期机制的消息ID缓存池,主要用于:
1.1 核心功能
短期消息去重:在设定的时间窗口内(如15秒),对同一消息ID的重复请求进行识别和过滤
请求幂等性保证:确保同一操作即使被多次请求,也只会被执行一次
资源泄漏防护:通过自动过期机制,避免内存无限增长
1.2 适用场景
嵌入式设备的通信协议层
物联网设备数据上报
低并发服务端的API请求去重
需要轻量级幂等性校验的中间件
二、原始设计分析
2.1 数据结构设计
// 原始数据结构
struct {
int64_t time; // 存储消息ID
u32_t cnt; // 状态与超时计数器
} msg_id_queue[MSG_ID_MAX_NUB];这是一个典型的环形缓冲区设计:
- time字段存储消息的唯一标识符(通常是时间戳或序列号)
- cnt字段作为多状态标志:
cnt == 0:槽位空闲
cnt > 0:槽位占用,值表示剩余生存时间
2.2 工作流程
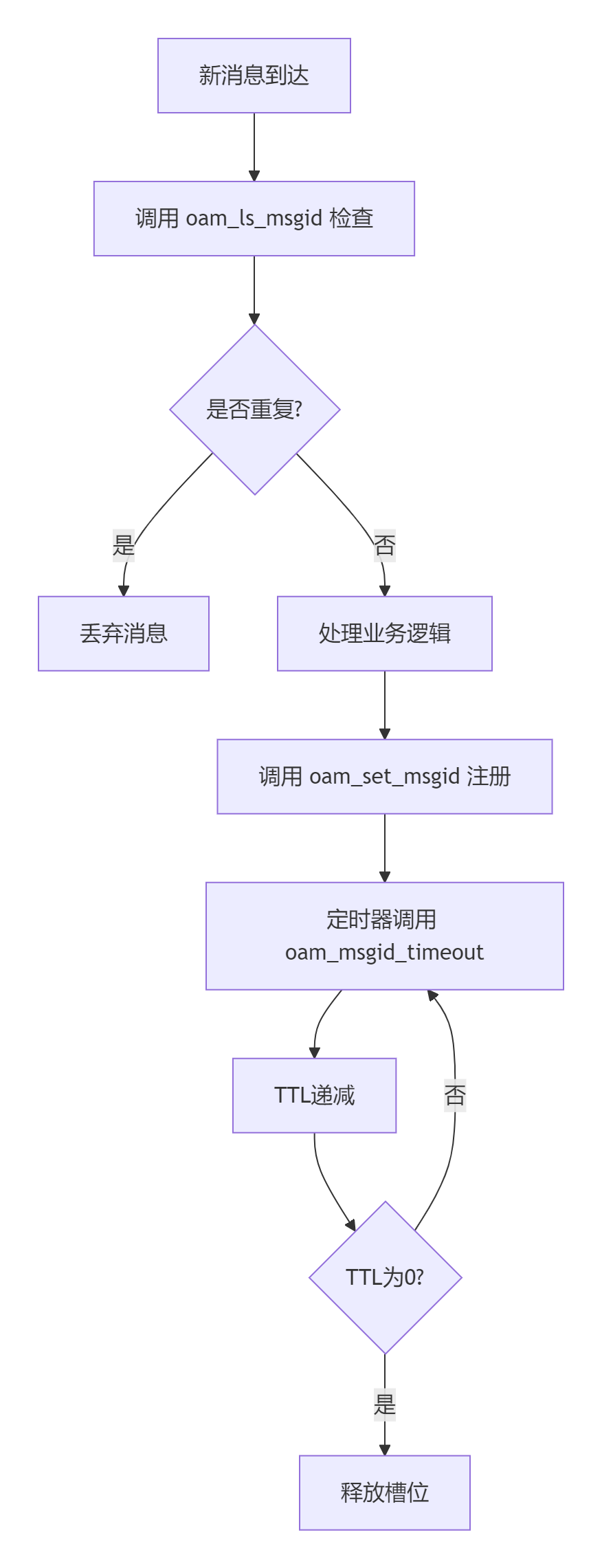
2.3 设计的优缺点
优点:
-
内存占用固定,无动态分配
-
实现简单,代码量小
-
自动过期,无需手动清理
三、优化版本实现
3.1 版本一:推荐直接使用
此版本修复了原始代码的所有问题,同时保持API兼容,可直接替换原文件。
#ifndef __OAM_MSGID_H_
#define __OAM_MSGID_H_
#ifdef __cplusplus
extern "C" {
#endif
/* 消息防重模块 - 优化版 */
#define MSG_ID_MAX_NUM 100 /* 缓存池容量 */
#define MSG_ID_TIMEOUT 15 /* ID存活时间单位 */
/**
* @brief 初始化消息ID缓存池
*/
void oam_msgid_init(void);
/**
* @brief 检查消息ID是否已存在(防重检查)
* @param id 消息唯一标识
* @return 1: ID已存在(重复) 0: ID不存在(新消息)
*/
int oam_msgid_check(int64_t id);
/**
* @brief 注册新消息ID
* @param id 消息唯一标识
* @return 1: 注册成功 0: 注册失败(缓存池已满)
*/
int oam_msgid_register(int64_t id);
/**
* @brief 超时处理函数(需定期调用)
*/
void oam_msgid_timeout(void);
/**
* @brief 获取当前已使用的缓存槽位数
*/
int oam_msgid_used_count(void);
#ifdef __cplusplus
}
#endif
#endif /* __OAM_MSGID_H_ */oam_msgid.c
#include "oam_msgid.h"
#include <string.h>
#include <stdint.h>
/* 缓存条目结构 */
typedef struct {
int64_t id; /* 消息唯一标识 */
uint32_t ttl; /* 生存时间计数器 */
} msg_entry_t;
/* 全局缓存池 */
static msg_entry_t msg_cache[MSG_ID_MAX_NUM];
void oam_msgid_init(void) {
memset(msg_cache, 0, sizeof(msg_cache));
}
int oam_msgid_check(int64_t id) {
for (int i = 0; i < MSG_ID_MAX_NUM; i++) {
if (msg_cache[i].ttl > 0 && msg_cache[i].id == id) {
return 1; /* 找到重复ID */
}
}
return 0; /* 新ID */
}
int oam_msgid_register(int64_t id) {
/* 查找空闲槽位 */
for (int i = 0; i < MSG_ID_MAX_NUM; i++) {
if (msg_cache[i].ttl == 0) {
msg_cache[i].id = id;
msg_cache[i].ttl = MSG_ID_TIMEOUT;
return 1; /* 注册成功 */
}
}
return 0; /* 缓存池已满 */
}
void oam_msgid_timeout(void) {
for (int i = 0; i < MSG_ID_MAX_NUM; i++) {
if (msg_cache[i].ttl > 0) {
msg_cache[i].ttl--;
/* ttl为0的条目在下次查找时被视为空闲 */
}
}
}
int oam_msgid_used_count(void) {
int count = 0;
for (int i = 0; i < MSG_ID_MAX_NUM; i++) {
if (msg_cache[i].ttl > 0) {
count++;
}
}
return count;
}3.2 版本二:哈希表高性能版
对于高并发场景,我们提供了哈希表优化版本,将平均查找时间复杂度从O(n)降至O(1)。
3.1.1 设计思路
-
使用简单哈希函数分散数据
-
采用链地址法解决哈希冲突
-
预分配固定内存池,避免动态分配开销
oam_msgid_hash.c(核心部分)
#define HASH_TABLE_SIZE 101 /* 质数大小减少哈希冲突 */
#define DEFAULT_TTL 15
#define MAX_NODES 100 /* 最大节点数 */
/* 哈希节点结构 */
typedef struct hash_node {
int64_t id;
uint32_t ttl;
struct hash_node *next;
} hash_node_t;
/* 哈希表 + 内存池 */
static hash_node_t *hash_table[HASH_TABLE_SIZE];
static hash_node_t node_pool[MAX_NODES];
static int pool_index = 0;
/* 简单哈希函数 */
static inline uint32_t hash_func(int64_t id) {
return (uint32_t)(id % HASH_TABLE_SIZE);
}
int oam_msgid_check(int64_t id) {
uint32_t idx = hash_func(id);
hash_node_t *node = hash_table[idx];
while (node != NULL) {
if (node->ttl > 0 && node->id == id) {
return 1; /* 找到重复 */
}
node = node->next;
}
return 0; /* 未找到 */
}
int oam_msgid_register(int64_t id) {
/* 先检查是否已存在 */
if (oam_msgid_check(id)) {
return 1; /* 已存在,避免重复注册 */
}
/* 从内存池分配节点 */
if (pool_index >= MAX_NODES) {
/* 内存池满,尝试清理过期节点 */
oam_msgid_timeout();
/* 这里可添加更主动的清理策略 */
if (pool_index >= MAX_NODES) {
return 0; /* 资源不足 */
}
}
hash_node_t *new_node = &node_pool[pool_index++];
new_node->id = id;
new_node->ttl = DEFAULT_TTL;
/* 插入哈希表(头插法) */
uint32_t idx = hash_func(id);
new_node->next = hash_table[idx];
hash_table[idx] = new_node;
return 1;
}四、性能对比与选型建议
4.1 性能对比表
|-------|------|------------|
| 特性 | 版本一 | 优化版本二(哈希表) |
| 时间复杂度 | O(n) | 平均O(1) |
| 内存占用 | 固定 | 固定+指针开销 |
| 代码复杂度 | 简单 | 中等 |
| 并发安全 | 非安全 | 非安全 |
| 适用场景 | 低频场景 | 中高频场景 |
4.2 选型指南
选择版本一如果:
- 消息频率较低(< 100条/秒)
- 希望最小化改动,直接替换原文件
- 资源极度受限,追求极简实现
- 系统对哈希表的内存开销敏感
选择版本二如果:
- 消息频率较高(> 100条/秒)
- 缓存容量需要更大(> 1000条目)
- 可以接受稍高的内存开销
- 未来可能扩展更多功能
五、集成与使用示例
5.1 集成步骤
将选定的 .h和 .c文件添加到项目中
在系统初始化时调用 oam_msgid_init()
设置定时器,定期调用 oam_msgid_timeout()(建议每秒一次)
5.2 使用示例代码
#include "oam_msgid.h"
#include <stdio.h>
/* 模拟系统定时器,每秒调用一次 */
void system_timer_1s_callback(void) {
oam_msgid_timeout();
}
/* 处理接收到的消息 */
void process_message(int64_t msg_id, const char* payload) {
/* 步骤1:检查是否重复消息 */
if (oam_msgid_check(msg_id)) {
printf("消息 %lld 为重复消息,已丢弃\n", msg_id);
return;
}
/* 步骤2:处理业务逻辑 */
printf("处理新消息: %lld, 内容: %s\n", msg_id, payload);
/* 步骤3:注册消息ID,防止后续重复 */
if (!oam_msgid_register(msg_id)) {
printf("警告: 消息防重缓存池已满,消息 %lld 可能无法防重\n", msg_id);
}
/* 可选:监控缓存使用情况 */
int used = oam_msgid_used_count();
if (used > MSG_ID_MAX_NUM * 0.8) {
printf("警告: 防重缓存使用率超过80%% (%d/%d)\n",
used, MSG_ID_MAX_NUM);
}
}
int main() {
/* 初始化 */
oam_msgid_init();
/* 模拟消息处理 */
process_message(1001, "温度数据: 25.5℃");
process_message(1002, "湿度数据: 60%");
process_message(1001, "温度数据: 25.5℃"); // 这将是重复消息
return 0;
}六、生产环境注意事项
6.1 线程安全性
当前实现非线程安全。如果在多线程环境中使用,需要添加锁机制:
/* 简单示例:添加互斥锁保护 */
static pthread_mutex_t cache_mutex = PTHREAD_MUTEX_INITIALIZER;
int oam_msgid_check_safe(int64_t id)
{
pthread_mutex_lock(&cache_mutex);
int result = oam_msgid_check(id);
pthread_mutex_unlock(&cache_mutex);
return result;
}6.2 参数调优建议
-
MSG_ID_TIMEOUT:根据实际业务设置。网络延迟大则设置较长,实时性要求高则设置较短 -
MSG_ID_MAX_NUM:根据系统峰值消息量设置,建议为预估每秒最大消息数的2-3倍 -
哈希表版本 :
HASH_TABLE_SIZE建议使用质数,减少哈希冲突
6.3 监控与调试
建议在生产环境中添加以下监控点:
-
缓存使用率监控(通过
oam_msgid_used_count()) -
注册失败率统计(
oam_msgid_register返回0的频率) -
定期日志输出缓存状态,便于问题排查
七、总结
oam_msgid模块展示了一个经典的空间换时间防重设计方案。通过本文的分析与优化,我们:
-
优化了代码可读性:通过更清晰的命名和注释
-
提供了性能优化方案:哈希表版本满足更高性能需求
-
增强了健壮性:添加了错误处理和状态监控
无论选择哪个版本,核心思想不变:在有限的时间窗口内,通过记录已处理的消息ID来识别和过滤重复请求。这种模式在分布式系统的幂等性保证、消息队列的去重等场景中有着广泛的应用。
最佳实践建议:对于大多数嵌入式或IoT场景,优化版本一已完全够用且稳定;对于服务端高并发场景,建议采用优化版本二,并根据实际负载调整哈希表参数。