渲染管线基础:光照计算在哪发生?
在实时渲染中,计算物体表面在光线照射下呈现的颜色,本质上是对 光照方程(Lighting Equation) 的求解。这个方程需要三类信息:光源方向与强度、表面法线方向、以及材质属性(漫反射、高光、粗糙度等)。关键的问题不是"算什么",而是**"在哪个阶段算,算多少次"**。
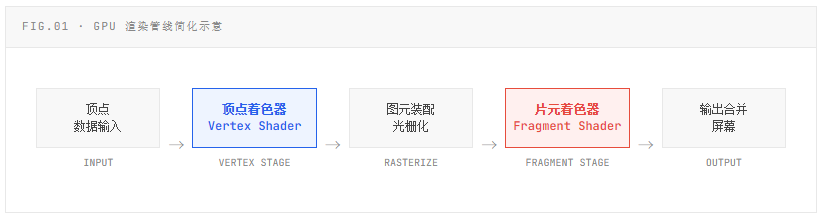
逐顶点光照 在 Vertex Shader 阶段完成光照计算,每个顶点算一次,然后在光栅化时通过插值传递给像素。逐像素光照则将计算推迟到 Fragment Shader,每个屏幕像素独立计算一次。两者之间的选择,直接决定了计算量的数量级差异。
💡 关键洞察一个 1080p 的屏幕有约 200 万个像素,而一个中等复杂度的 3D 网格可能只有几千个顶点。这意味着逐像素光照的计算量可能是逐顶点的数百倍。
逐顶点光照:速度优先的古典方案
逐顶点光照(Per-Vertex Lighting,也称 Gouraud Shading)是渲染史上最经典的光照方案之一。其核心思路是:在顶点着色器中完成完整的光照计算,得到每个顶点的最终颜色,再由 GPU 自动在三角形内部进行线性插值。
核心实现原理
cs
// 逐顶点光照 Vertex Shader (URP)
Varyings vert(Attributes input)
{
Varyings output;
// 将法线变换到世界空间
float3 worldNormal = TransformObjectToWorldNormal(input.normalOS);
float3 worldPos = TransformObjectToWorld(input.positionOS.xyz);
// 在顶点阶段完成光照计算
Light mainLight = GetMainLight();
float NdotL = saturate(dot(worldNormal, mainLight.direction));
// Blinn-Phong 高光(顶点级)
float3 viewDir = normalize(_WorldSpaceCameraPos - worldPos);
float3 halfVec = normalize(mainLight.direction + viewDir);
float NdotH = saturate(dot(worldNormal, halfVec));
float specular = pow(NdotH, 32.0); // 高光在顶点计算
// 最终颜色写入 varying,由光栅化器插值
output.color = NdotL * mainLight.color + specular;
output.positionCS = TransformWorldToHClip(worldPos);
return output;
}
half4 frag(Varyings input) : SV_Target
{
// Fragment 只做颜色乘法,无光照计算
return half4(input.color * _BaseColor.rgb, 1.0);
}优势与局限
顶点着色器的执行次数等于网格的顶点数,对于低多边形模型(数百到数千个顶点)而言计算量极小。然而,线性插值天然无法重现高光(Specular)在像素级的尖锐变化:当高光的最亮点恰好落在三角形内部而非顶点上时,逐顶点方案会完全丢失它。
⚠ 经典缺陷Gouraud Shading 的"阿喀琉斯之踵":高频高光(如 Blinn-Phong 的 Shininess > 32)几乎必定产生严重失真。即便顶点密度足够高,在 Specular 强烈区域仍可能出现马赫带(Mach Band)现象。
逐像素光照:精度至上的现代方案
逐像素光照(Per-Pixel Lighting,也称 Phong Shading)将光照计算从顶点着色器移至片元着色器。每个屏幕像素拥有独立的法线(从顶点插值而来,或从法线贴图采样),独立计算完整光照方程。这是现代游戏渲染管线的基础。
URP Lit Shader 核心片段
cs
// 逐像素光照 Fragment Shader (URP)
half4 frag(Varyings input) : SV_Target
{
// 从法线贴图重建像素法线(TBN 空间→世界空间)
half3 normalTS = UnpackNormal(SAMPLE_TEXTURE2D(_NormalMap, sampler_NormalMap, input.uv));
half3 worldNormal = TransformTangentToWorld(normalTS,
half3x3(input.tangent, input.bitangent, input.normal));
worldNormal = normalize(worldNormal);
// 主光源(每像素重新计算)
Light mainLight = GetMainLight(input.shadowCoord);
half NdotL = saturate(dot(worldNormal, mainLight.direction));
// 精确的像素级 Blinn-Phong 高光
half3 viewDir = normalize(_WorldSpaceCameraPos - input.worldPos);
half3 halfVec = normalize(mainLight.direction + viewDir);
half NdotH = saturate(dot(worldNormal, halfVec));
half spec = pow(NdotH, _Shininess) * _SpecularStrength;
// 附加光源循环(逐像素多光源)
half3 additionalLight = 0;
int count = GetAdditionalLightsCount();
LIGHT_LOOP_BEGIN(count)
Light light = GetAdditionalLight(lightIndex, input.worldPos);
additionalLight += LightingLambert(light.color, light.direction, worldNormal)
* light.distanceAttenuation;
LIGHT_LOOP_END
half3 albedo = SAMPLE_TEXTURE2D(_BaseMap, sampler_BaseMap, input.uv).rgb;
half3 diffuse = NdotL * mainLight.color * mainLight.shadowAttenuation;
return half4((diffuse + additionalLight + spec) * albedo, 1.0);
}法线贴图:逐像素的真正威力
单纯将光照计算移到片元着色器只是逐像素光照的第一步。配合**法线贴图(Normal Map)**后,每个像素可以拥有与几何体网格完全不同的法线方向,从而在低多边形模型上模拟出高多边形的表面细节。这是逐顶点光照在结构上无法实现的能力。
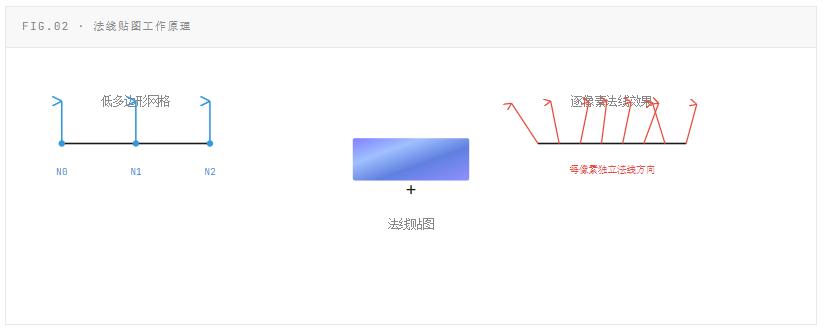
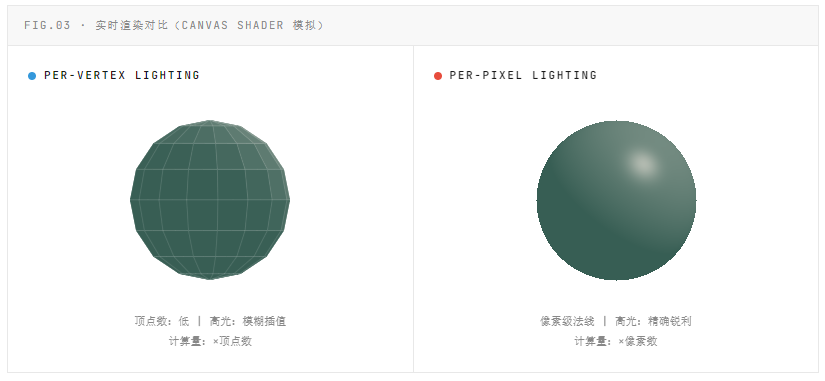
画质差异的直观对比
下图通过 Canvas 实时渲染,展示同一球体在逐顶点光照与逐像素光照下的视觉差异。注意高光区域的锐利程度与边缘过渡。
量化画质对比
| 维度 | 逐顶点光照 | 逐像素光照 |
|---|---|---|
| 高光质量 | 插值模糊,低顶点密度下严重失真 差 | 精确锐利,可支持任意 Shininess 优 |
| 法线贴图 | 不支持(顶点无像素级细节) 不支持 | 完整支持,表面细节丰富 支持 |
| 低多边形模型 | 三角形面感明显,色带现象 差 | 即使低模也能呈现平滑光照 优 |
| 阴影边缘 | 粗糙,受顶点分布影响 一般 | 像素精度,边缘平滑 优 |
| 远处物体 | 视觉差异不明显 可接受 | 效果相同但消耗更多 浪费 |
性能分析:GPU 侧的真实代价
性能差异并非简单的"顶点数 vs 像素数",还涉及着色器复杂度、带宽占用、GPU 架构特性等多个维度。以下是在典型移动端 GPU(Adreno 650)上的实测对比数据(相同场景,1080p):
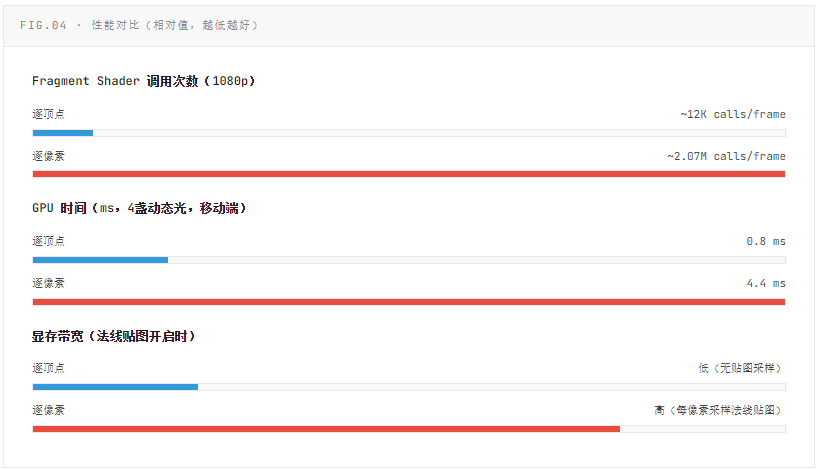
URP 中的光源数量影响
在 URP 的 Forward Rendering 路径下,每增加一盏动态附加光(Additional Light),逐像素方案的 Fragment Shader 复杂度呈线性增长。而逐顶点方案的增长幅度则取决于顶点密度,往往远低于像素密度。
// URP Asset 关键设置(ProjectSettings/URPAsset.asset) 2m_MainLightRenderingMode: 1 // 1=逐像素, 0=逐顶点 3m_AdditionalLightsRenderingMode: 1 // 1=逐像素, 0=逐顶点 4m_AdditionalLightsPerObjectLimit: 4 // 每物体最多4盏附加光 5m_SupportsVertexLight: 1 // 启用顶点光照支持 6m_SupportsMixedLighting: 1 // 混合光照模式 7m_RenderingMode: 0 // 0=Forward, 1=Deferred🔴 移动端陷阱在 Mali / Adreno 等移动端 GPU 上,Fragment Shader 的 ALU 并行度较低。当多盏逐像素附加光同时影响一个像素时,分支发散(Shader Branching)会导致 GPU 的 SIMD 效率骤降,实际耗时可能远超线性增长的预期。
URP 中的实战配置
Unity URP 通过 Material 的 Shader 属性和 Render Pipeline Asset 共同控制光照模式。理解配置层级对优化至关重要。
Material 层级:Shader 中的光照模式声明
cs
Shader "Custom/PerPixelLit"
{
Properties { /* ... */ }
SubShader
{
// URP 通用标签
Tags {
"RenderType" = "Opaque"
"RenderPipeline" = "UniversalPipeline"
"UniversalMaterialType" = "Lit"
}
Pass
{
Name "ForwardLit"
Tags { "LightMode" = "UniversalForward" }
#pragma vertex vert
#pragma fragment frag
// 关键 multi_compile:控制附加光照模式
#pragma multi_compile _ _ADDITIONAL_LIGHTS_VERTEX _ADDITIONAL_LIGHTS
// ↑顶点光照变体 ↑像素光照变体
#pragma multi_compile _ _MAIN_LIGHT_SHADOWS
#pragma multi_compile _ _SHADOWS_SOFT
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Lighting.hlsl"
// HLSL 实现见上方示例...
}
}
}运行时动态切换(LOD 联动)
对于大场景中的远景物体,可以通过脚本将其材质切换为逐顶点光照变体,结合 LOD Group 实现性能自适应:
cs
using UnityEngine;
using UnityEngine.Rendering;
using UnityEngine.Rendering.Universal;
/// <summary>
/// 根据相机距离动态切换光照模式变体
/// </summary>
public class LightingLODController : MonoBehaviour
{
public Material[] materials;
public float pixelLightMaxDist = 30f;
public float vertexLightDist = 60f;
private static readonly int kAdditionalLights =
Shader.PropertyToID("_ADDITIONAL_LIGHTS");
void Update()
{
float dist = Vector3.Distance(
transform.position, Camera.main.transform.position);
foreach (var mat in materials)
{
if (dist < pixelLightMaxDist)
{
// 近景:逐像素附加光
mat.EnableKeyword("_ADDITIONAL_LIGHTS");
mat.DisableKeyword("_ADDITIONAL_LIGHTS_VERTEX");
}
else if (dist < vertexLightDist)
{
// 中景:逐顶点附加光
mat.DisableKeyword("_ADDITIONAL_LIGHTS");
mat.EnableKeyword("_ADDITIONAL_LIGHTS_VERTEX");
}
else
{
// 远景:禁用附加光,仅保留主光源
mat.DisableKeyword("_ADDITIONAL_LIGHTS");
mat.DisableKeyword("_ADDITIONAL_LIGHTS_VERTEX");
}
}
}
}权衡策略:如何做出正确选择
没有绝对的"最优解",只有最适合当前约束条件的方案。以下是针对不同场景的策略矩阵:
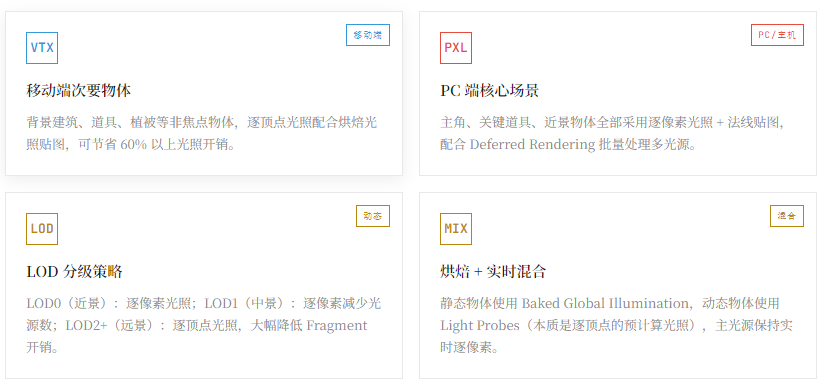
决策流程图

总结:选择的本质是什么?
逐像素光照 是现代渲染管线的基石,它以更高的 Fragment 开销换取像素级精度,支撑起法线贴图、精确高光、物理正确光照等一切现代视觉特性。逐顶点光照则是一种有意识的性能妥协,在顶点密度远低于像素密度的场景下,用可接受的视觉代价换取显著的性能收益。
真正的优化不是非此即彼,而是在正确的位置、正确的时机,使用正确的精度。将 LOD 系统、烘焙光照、材质变体和运行时动态切换结合起来,才是 Unity URP 下光照优化的最终形态。
🎯 最终建议使用 Unity 的 GPU Profiler 和 Frame Debugger 定期采样,找到真正的瓶颈。不要凭直觉优化------在实测数据出现之前,一切判断都只是假设。