目录
[方式1:使用 with_structured_output() 的 tools 参数](#方式1:使用 with_structured_output() 的 tools 参数)
[OpenAI返回的块是什么格式,如何转换成 AIMessageChunk ?](#OpenAI返回的块是什么格式,如何转换成 AIMessageChunk ?)
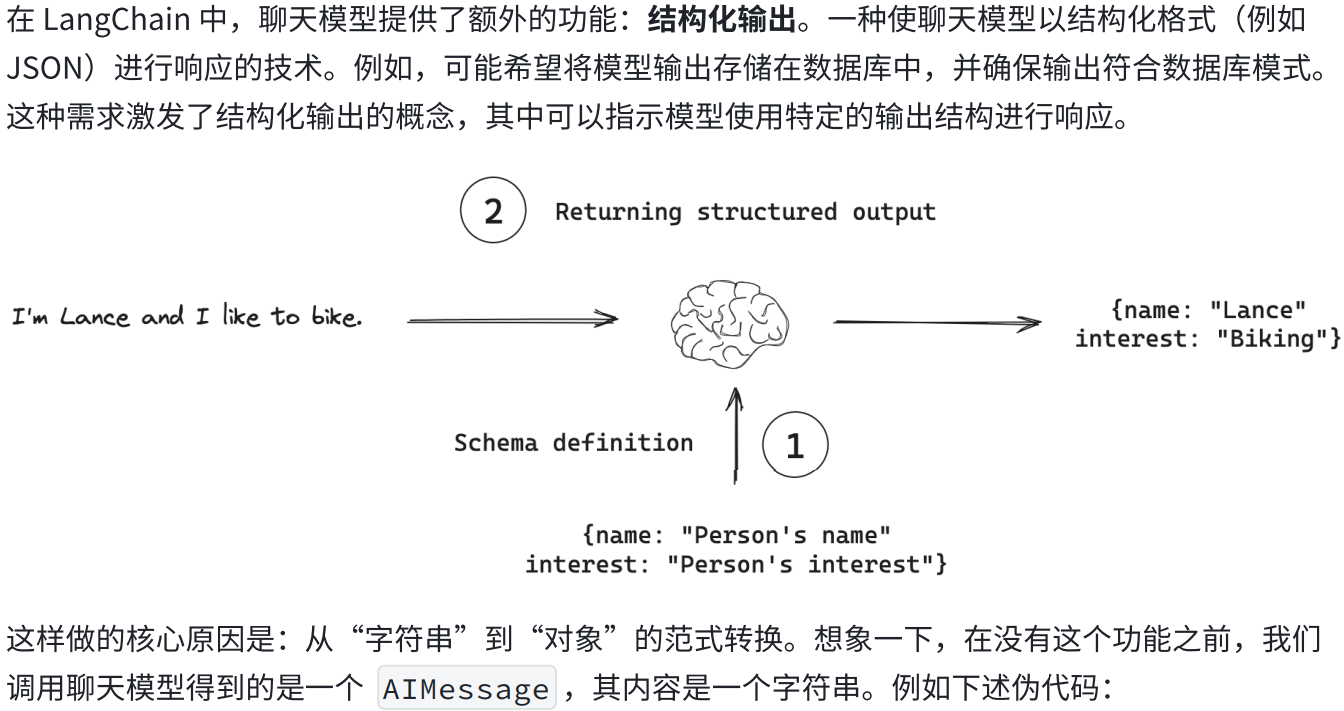
一.聊天模型--结构化输出
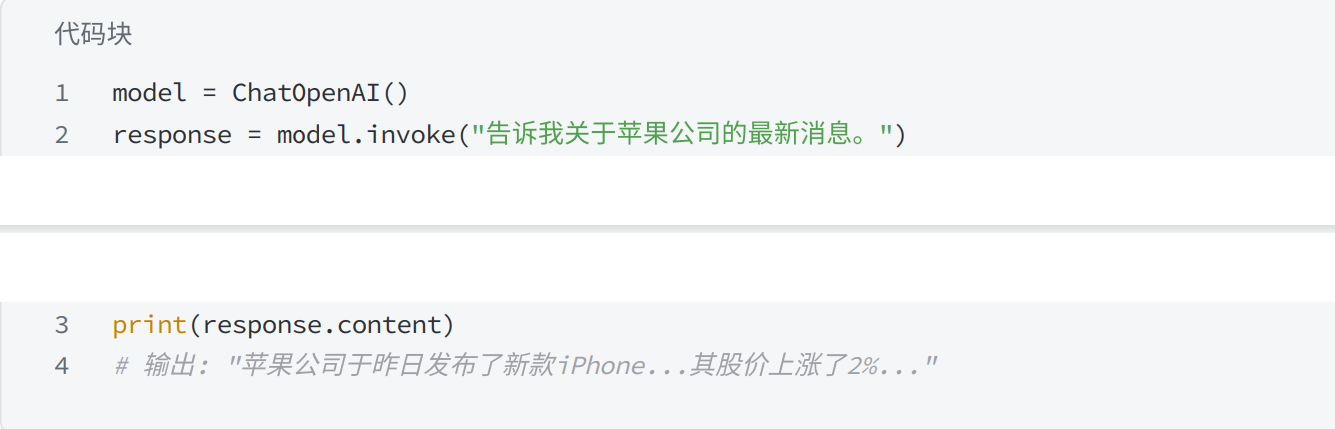
python
model = ChatOpenAI()
response = model.invoke("告诉我关于苹果公司的最新消息。")
print(response.content)
# 输出: "苹果公司于昨⽇发布了新款iPhone...其股价上涨了2%..." 
python
from langchain_openai import ChatOpenAI
import os
from pydantic import BaseModel,Field
from typing import Optional
api_key = os.getenv("ZHIPU_API_KEY")
model = ChatOpenAI(
model="glm-5",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
print(model.invoke("将一个关于唱歌笑话,10个字").content)
1.with_structured_output()
a.返回Pydantic对象
python
from langchain_openai import ChatOpenAI
import os
from pydantic import BaseModel, Field
from typing import Optional
api_key = os.getenv("ZHIPU_API_KEY")
model = ChatOpenAI(
model="glm-5",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key,
temperature=0.7
)
# 你的模型完全正确 ✅
class Joke(BaseModel):
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(default=None, description="1-10分,这个笑话几分?")
model_with_structured = model.with_structured_output(Joke)
# 关键:必须让 AI 返回你模型里的三个字段!!!
result = model_with_structured.invoke("""
请讲一个关于唱歌的笑话。
必须严格返回JSON,只包含以下三个字段:
1. setup:笑话开头
2. punchline:笑话笑点
3. rating:1-10分评分
不要任何多余文字、解释、标点、符号,只返回纯JSON!
""")
print(result)
python
from langchain_openai import ChatOpenAI
import os
from pydantic import BaseModel, Field
from typing import Optional, List
api_key = os.getenv("ZHIPU_API_KEY")
model = ChatOpenAI(
model="glm-5",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key,
temperature=0.7
)
# 笑话模型
class Joke(BaseModel):
"""给用户讲的一个笑话"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(default=None, description="1-10分,这个笑话几分?")
# 数据模型(包含笑话列表)
class Date(BaseModel):
"""获取关于笑话的数据列表"""
jokes: List[Joke]
model_with_structured = model.with_structured_output(Date)
# ✅ 关键修复:告诉AI返回 { "jokes": [ {...} ] } 格式!
result = model_with_structured.invoke("""
请生成1个关于唱歌和跳舞的笑话。
必须返回严格的JSON格式,结构如下:
{
"jokes": [
{
"setup": "笑话开头",
"punchline": "笑话笑点",
"rating": 评分(1-10)
}
]
}
只返回纯JSON,不要任何多余文字、解释、标点!
""")
print(result)
国内AI,可能对于我们with_structured_output(),支持性没有那么好,所以很多内容我们要写在提示词里面(我们可以尝试换国外的大模型,入OpenAI就可以不用写提示词,直接使用)

b.返回TypedDict(返回字典的写法)

python
from typing import TypedDict
class User(TypedDict):
name: str
age: int
email: str
is_active: bool = True # 默认值 


python
from langchain_openai import ChatOpenAI
import os
from pydantic import BaseModel, Field
from typing import Optional, List, TypedDict
from typing import Annotated # 必须是这个!
api_key = os.getenv("ZHIPU_API_KEY")
model = ChatOpenAI(
model="glm-5",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key,
temperature=0.7
)
class Joke(TypedDict):
"""给用户讲的一个笑话"""
setup: Annotated[str,...,"这个笑话的开头"]
punchline: Annotated[str,...,"这个笑话的妙语"]
rating: Annotated[Optional[int], None, "从1-10分,给这个笑话评分"]
model_with_structured = model.with_structured_output(Joke)
result = model_with_structured.invoke("""
讲一个关于跳舞的笑话,
必须返回JSON格式,包含三个字段:setup、punchline、rating
不要任何多余文字,只返回JSON!
""")
print(result)
python
from langchain_openai import ChatOpenAI
import os
from pydantic import BaseModel, Field
from typing import Optional, List, TypedDict
from typing import Annotated # 必须是这个!
api_key = os.getenv("ZHIPU_API_KEY")
model = ChatOpenAI(
model="glm-5",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key,
temperature=0.7
)
class Joke(TypedDict):
"""给用户讲的一个笑话"""
setup: Annotated[str,...,"这个笑话的开头"]
punchline: Annotated[str,...,"这个笑话的妙语"]
rating: Annotated[Optional[int], None, "从1-10分,给这个笑话评分"]
model_with_structured = model.with_structured_output(Joke,include_raw=True)
result = model_with_structured.invoke("""
讲一个关于跳舞的笑话,
必须返回JSON格式,包含三个字段:setup、punchline、rating
不要任何多余文字,只返回JSON!
""")
print(result)

这样就将完整的AI大模型调用的结果全部展现出来
c.返回JSON

python
from langchain_openai import ChatOpenAI
import os
from pydantic import BaseModel, Field
from typing import Optional, List, TypedDict
from typing import Annotated
api_key = os.getenv("ZHIPU_API_KEY")
model = ChatOpenAI(
model="glm-5",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key,
temperature=0.7
)
json_schema = {
"title": "joke",
"description": "给⽤⼾讲⼀个笑话。",
"type": "object",
"properties": {
"setup": {
"type": "string",
"description": "这个笑话的开头",
},
"punchline": {
"type": "string",
"description": "这个笑话的妙语",
},
"rating": {
"type": "integer",
"description": "从1到10分,给这个笑话评分",
"default": None,
},
},
"required": ["setup", "punchline"],
}
model_with_structured = model.with_structured_output(json_schema, include_raw=True)
# 👇 提示词我帮你写好了,强制按 JSON 格式输出
result = model_with_structured.invoke("""
讲一个关于唱歌、跳舞的笑话。
必须严格按照 JSON 格式返回,只包含 setup、punchline、rating 三个字段。
不要加任何多余文字、解释、标点符号,只返回纯 JSON。
""")
print(result)

d.选择输出格式

python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import Optional, Union
import os
# 你的 GLM-5 配置
api_key = os.getenv("ZHIPU_API_KEY")
model = ChatOpenAI(
model="glm-5",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key,
temperature=0.1
)
# 结构定义
class Joke(BaseModel):
"""给⽤⼾讲⼀个笑话。"""
setup: str = Field(description="笑话开头")
punchline: str = Field(description="笑话妙语")
rating: Optional[int] = Field(default=None, description="1-10分")
class ConversationalResponse(BaseModel):
"""友善对话回应"""
response: str = Field(description="对话回复")
class FinalResponse(BaseModel):
final_output: Union[Joke, ConversationalResponse]
# 绑定结构化输出
structured_model = model.with_structured_output(FinalResponse)
# ==============================
# 🔥🔥🔥 强制 GLM 必须套 final_output!(这次绝对听话)
# ==============================
prompt1 = """
【严格格式命令,必须遵守】
你必须返回 JSON,且最外层必须有一个字段叫:final_output
根据用户输入选择内容:
- 要讲笑话 → final_output 填写 Joke 结构(setup、punchline、rating)
- 正常聊天 → final_output 填写 ConversationalResponse 结构(response)
只返回纯 JSON,绝对不要加```json,不要加任何文字、解释、标点!
用户输入:给我讲一个关于唱歌的笑话
"""
prompt2 = """
【严格格式命令,必须遵守】
你必须返回 JSON,且最外层必须有一个字段叫:final_output
根据用户输入选择内容:
- 要讲笑话 → final_output 填写 Joke 结构(setup、punchline、rating)
- 正常聊天 → final_output 填写 ConversationalResponse 结构(response)
只返回纯 JSON,绝对不要加```json,不要加任何文字、解释、标点!
用户输入:你好
"""
# 执行
result = structured_model.invoke(prompt1)
print(result)
print("-" * 50)
result = structured_model.invoke(prompt2)
print(result)这里glm-5对于我们的Union支持也不是很好,所以我们要在提示词里面写上要的内容

但是对于OpenAI,我们只要写如下即可:
python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import Optional, Union
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
class Joke(BaseModel):
"""给⽤⼾讲⼀个笑话。"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
class ConversationalResponse(BaseModel):
"""以对话的⽅式回应。待⼈友善,乐于助⼈。"""
response: str = Field(description="对⽤⼾查询的会话响应")
class FinalResponse(BaseModel):
final_output: Union[Joke, ConversationalResponse]
structured_model = model.with_structured_output(FinalResponse)
result = structured_model.invoke("给我讲⼀个关于唱歌的笑话")
print(result)
result = structured_model.invoke("你好")
print(result)不需要额外写提示词
2.实用场景
a.场景1:作为信息提取器
python
from langchain_openai import ChatOpenAI
from typing import Optional
from pydantic import BaseModel, Field
from langchain_core.messages import HumanMessage, SystemMessage
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
class Person(BaseModel):
"""⼀个⼈的信息。"""
# 注意:
# 1. 每个字段都是 Optional "可选的" ------ 允许 LLM 在不知道答案时输出 None。
# 2. 每个字段都有⼀个 description "描述" ------ LLM使⽤这个描述。
# 有⼀个好的描述可以帮助提⾼提取结果。
name: Optional[str] = Field(default=None, description="这个⼈的名字")
hair_color: Optional[str] = Field(default=None, description="如果知道这个⼈头发的颜⾊")
skin_color: Optional[str] = Field(default=None, description="如果知道这个⼈的肤⾊")
height_in_meters: Optional[str] = Field(default=None, description="以⽶为单位的⾼度")
structured_model = model.with_structured_output(schema=Person)
messages = [
SystemMessage(content="你是⼀个提取信息的专家,只从⽂本中提取相关信息。如果您不知道要提取的属性的值,属性值返回null"),
HumanMessage(content="史密斯⾝⾼6英尺,⾦发。")
]
result = structured_model.invoke(messages)
print(result)
b.场景2:使用"少样本提示"来增强信息提取能力
后面再进行讲解,类似于如下:


代码后续再写
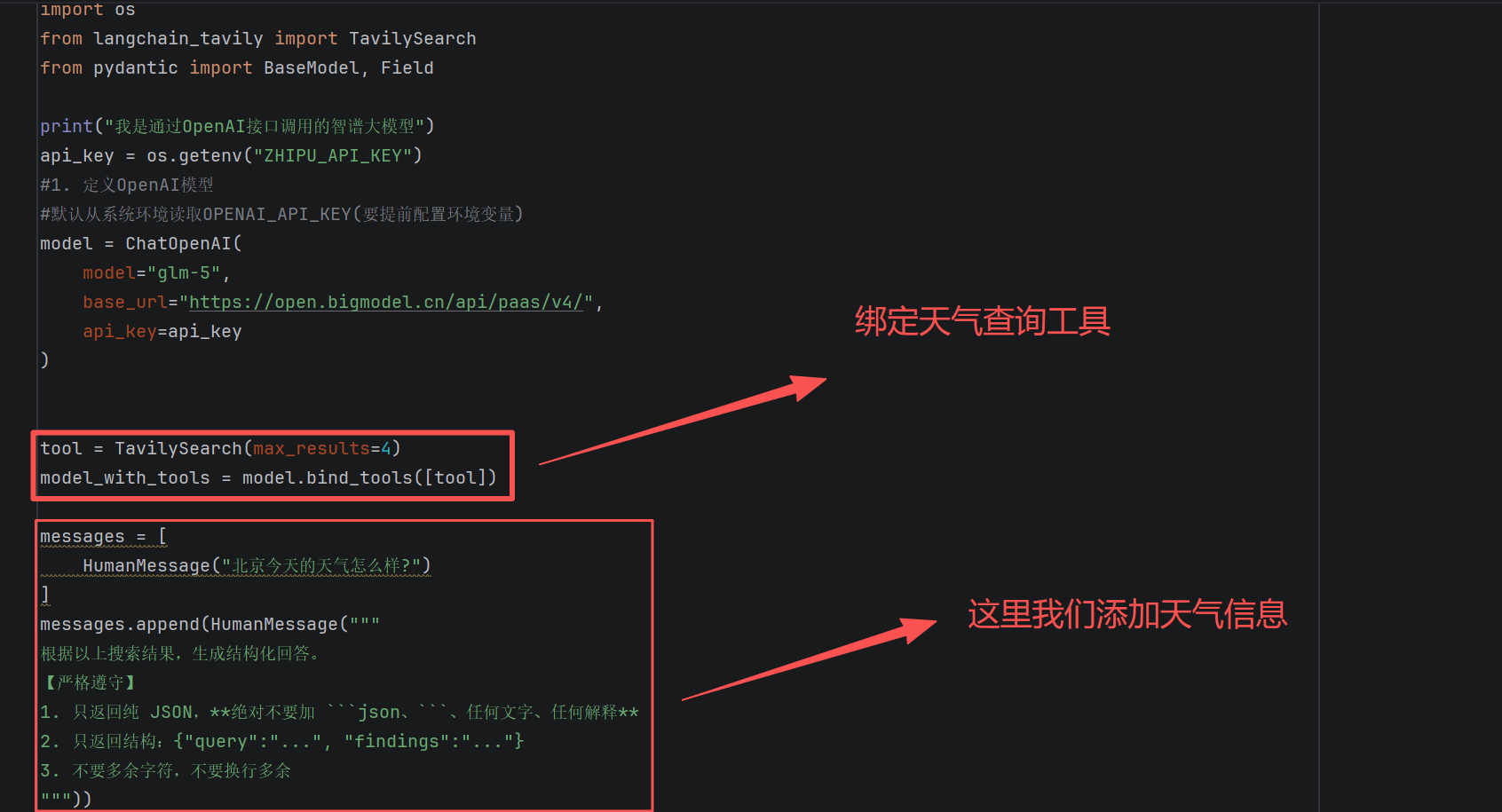
c.场景3:与工具结合使用

方式1:使用 with_structured_output() 的 tools 参数
python
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
import os
from langchain_tavily import TavilySearch
from pydantic import BaseModel, Field
print("我是通过OpenAI接口调用的智谱大模型")
api_key = os.getenv("ZHIPU_API_KEY")
#1. 定义OpenAI模型
#默认从系统环境读取OPENAI_API_KEY(要提前配置环境变量)
model = ChatOpenAI(
model="glm-5",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
tool = TavilySearch(max_results=4)
model_with_tools = model.bind_tools([tool])
messages = [
HumanMessage("北京今天的天气怎么样?")
]
messages.append(HumanMessage("""
根据以上搜索结果,生成结构化回答。
【严格遵守】
1. 只返回纯 JSON,**绝对不要加 ```json、```、任何文字、任何解释**
2. 只返回结构:{"query":"...", "findings":"..."}
3. 不要多余字符,不要换行多余
"""))
ai_message = model_with_tools.invoke(messages)
messages.append(ai_message)
for tool_call in ai_message.tool_calls:
tool_message = tool.invoke(tool_call)
messages.append(tool_message)
class SearchResult(BaseModel):
"""结构化搜索对象"""
query: str = Field(description="搜索查询")
findings: str = Field(description="查询结果摘要")
model_with_structured = model_with_tools.with_structured_output(SearchResult)
print(model_with_structured.invoke(messages))


二.聊天模型--流式传输

python
model = ChatOpenAI()
model.invoke("讲⼀个1000字的笑话")
python
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
import os
print("我是通过OpenAI接口调用的智谱大模型")
api_key = os.getenv("ZHIPU_API_KEY")
#1. 定义OpenAI模型
#默认从系统环境读取OPENAI_API_KEY(要提前配置环境变量)
model = ChatOpenAI(
model="glm-4",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
print(model.invoke("写一段关于春天的作文,1000个字左右").content)这样的话,等待的时间就非常的长了

我们能采用流式传输进行操作

1.stream()同步传输
代码实现流式传输:
python
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
import os
print("我是通过OpenAI接口调用的智谱大模型")
api_key = os.getenv("ZHIPU_API_KEY")
#1. 定义OpenAI模型
#默认从系统环境读取OPENAI_API_KEY(要提前配置环境变量)
model = ChatOpenAI(
model="glm-4",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
#返回迭代器
for chunk in model.stream("写一段关于春天的作文,1000个字左右"):
print(chunk.content,end="|")
# print(model.invoke("写一段关于春天的作文,1000个字左右").content)这样就是流式输出的
python
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
import os
print("我是通过OpenAI接口调用的智谱大模型")
api_key = os.getenv("ZHIPU_API_KEY")
#1. 定义OpenAI模型
#默认从系统环境读取OPENAI_API_KEY(要提前配置环境变量)
model = ChatOpenAI(
model="glm-4",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
#返回迭代器
chunks = []
for chunk in model.stream("写一段关于春天的作文,1000个字左右"):
chunks.append(chunk)
# print(chunk.content,end="|",flush=True)
tmp_chunks = chunks[0] + chunks[1] + chunks[2]
print(tmp_chunks)
# print(model.invoke("写一段关于春天的作文,1000个字左右").content)
2.astream()异步传输

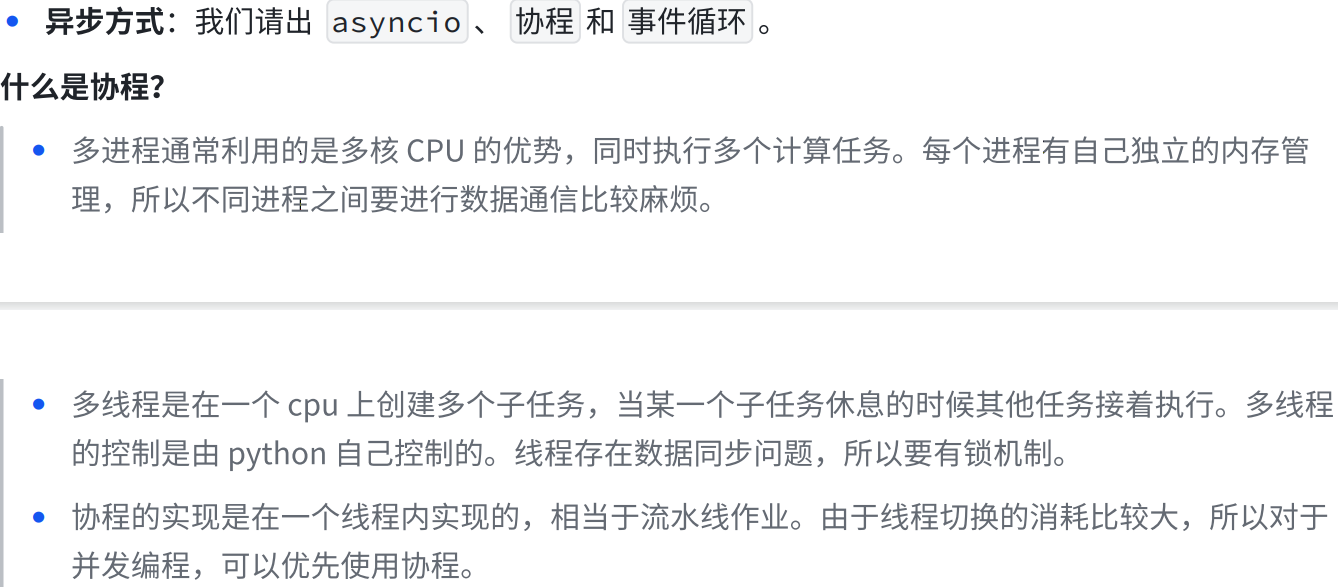
a.异步相关概念

python
import time
def boil_water():
print("开始煮⽔...")
time.sleep(5) # 模拟阻塞等待5秒
print("⽔开了!")
def send_message():
print("开始发短信...")
time.sleep(2) # 模拟阻塞等待2秒
print("短信发送成功!")
# 主程序
def main():
boil_water() # 先花5秒煮⽔,期间什么也不能做
send_message() # ⽔开后再花2秒发短信
main()
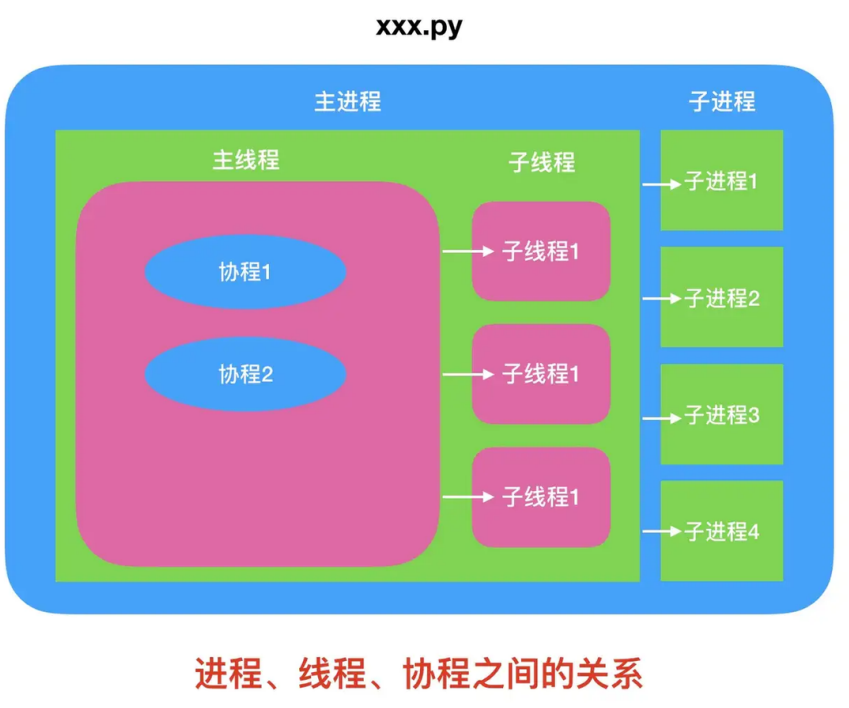

协程就是一个线程里面的执行分支

python
import asyncio
# 定义协程
async def boil_water_async():
print("开始煮水...")
await asyncio.sleep(5) # 关键! await 表示"等待这个操作完成,但期间让事件循环去做别的事"
print("水开了!")
async def send_message_async():
print("开始发短信...")
await asyncio.sleep(2) # 同样,等待2秒,但让出控制权
print("短信发送成功!")
# 主协程,并发运行两个任务
async def main():
# 并发执行煮水和发短信
task1 = asyncio.create_task(boil_water_async())
task2 = asyncio.create_task(send_message_async())
await task1
await task2
# 启动事件循环
asyncio.run(main())
python
# 主程序(也是⼀个协程)
async def main():
# 创建两个任务,并交给事件循环去调度
task1 = asyncio.create_task(boil_water_async())
task2 = asyncio.create_task(send_message_async())
# 等待两个任务都完成
await task1
await task2
# 它负责创建事件循环,并将第⼀个协程(主程序)放⼊其中运⾏。
asyncio.run(main())

b.使用

python
from langchain_openai import ChatOpenAI
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
# 异步调⽤
async def async_stream():
print("=== 异步调⽤ ===")
async for chunk in model.astream("讲⼀个50字的笑话"):
print(chunk.content, end="|", flush=True)
import asyncio
asyncio.run(async_stream())
python
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
import os
import asyncio
api_key = os.getenv("ZHIPU_API_KEY")
model = ChatOpenAI(
model="glm-4",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
async def async_stream():
print("===异步调用===")
async for chunk in model.astream("写一段关于春天的作文,1000字"):
print(chunk.content,end="|",flush=True)
asyncio.run(async_stream())3.使用StrOutputParser解析模型的输出


python
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 定义⼤模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出解析器
parser = StrOutputParser()
# 定义链
chain = model | parser
for chunk in chain.stream("写⼀段关于爱情的歌词,需要5句话"):
print(chunk, end="|", flush=True)
python
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
import os
api_key = os.getenv("ZHIPU_API_KEY")
#组件1:聊天模型
model = ChatOpenAI(
model="glm-4",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
#组件2:输出解析器
parser = StrOutputParser()
#定义链
chain = model | parser
for chunk in chain.stream("写一段关于爱情的歌词,5句话左右"):
# 使用parser,结果就是str
print(chunk,end="|",flush=True)4.自定义流式输出解析器
python
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from typing import Iterator, List
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出解析器
parser = StrOutputParser()
# 定义生成器
def split_into_list(input: Iterator[str]) -> Iterator[List[str]]:
buffer = ""
for chunk in input:
buffer += chunk
while "。" in buffer:
# 只要缓冲区中包含句号,就找到第一个句号的位置
stop_index = buffer.index("。")
# 将句号之前的内容(去除首尾空格)作为一个句子放入列表中并产出
yield [buffer[:stop_index].strip()]
# 更新缓冲区,保留句号之后的内容
buffer = buffer[stop_index + 1 :]
yield [buffer.strip()]
# 定义链
chain = model | parser | split_into_list
for chunk in chain.stream("写一份关于爱情的歌词,需要5句话,每句话用句号分割"):
print(chunk, end="|", flush=True)
python
from typing import List, Iterator
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
import os
api_key = os.getenv("ZHIPU_API_KEY")
#组件1:聊天模型
model = ChatOpenAI(
model="glm-4",
base_url="https://open.bigmodel.cn/api/paas/v4/",
api_key=api_key
)
#组件2:输出解析器
parser = StrOutputParser()
#自定义生成器
def split_into_list(input: Iterator[str]) -> Iterator[List[str]]:
buffer = ""
for chunk in input:
buffer += chunk
#遇到句号,就刷新
while "。" in buffer:
#找到。的位置
stop_index = buffer.index("。")
#yield用于创造生成器
yield [buffer[:stop_index].strip()]
buffer = buffer[stop_index + 1:]
yield [buffer.strip()]
#定义链
chain = model | parser | split_into_list
for chunk in chain.stream("写一段关于爱情的歌词,5句话左右,每句话用中文,句号隔开"):
# 使用parser,结果就是str
print(chunk,end="|",flush=True)
5.深度探索流式传输
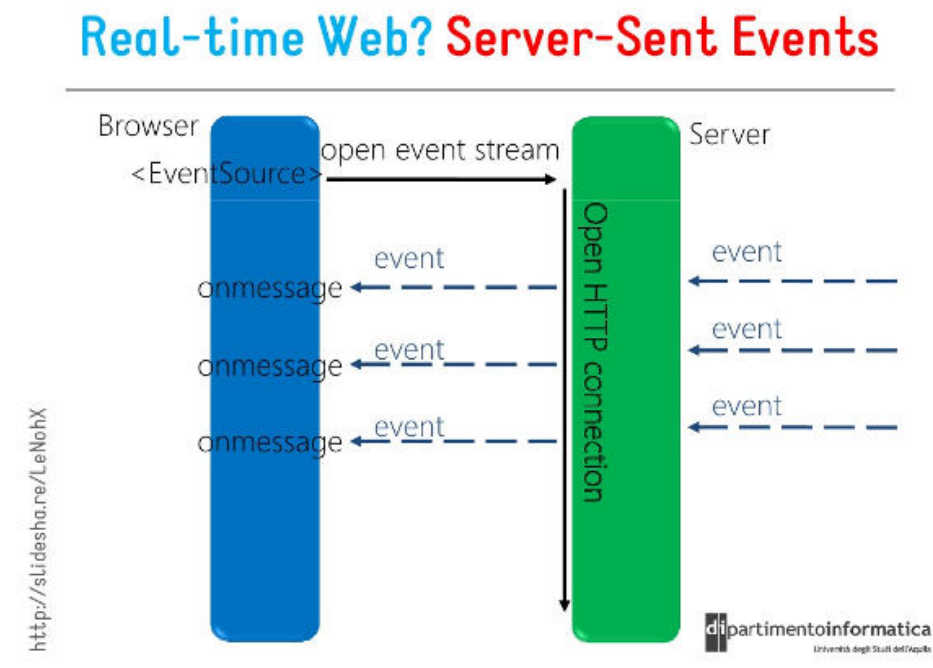
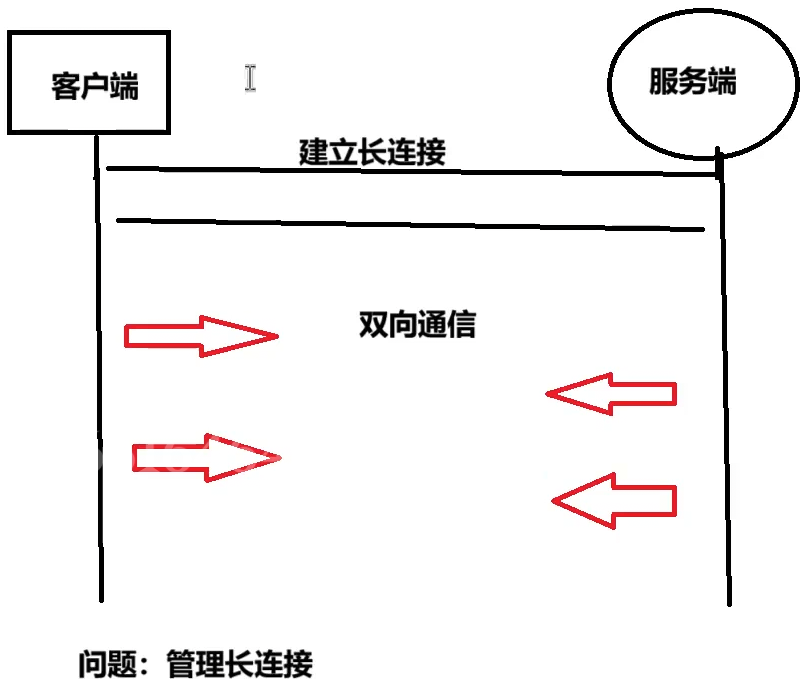
a.SSE协议介绍

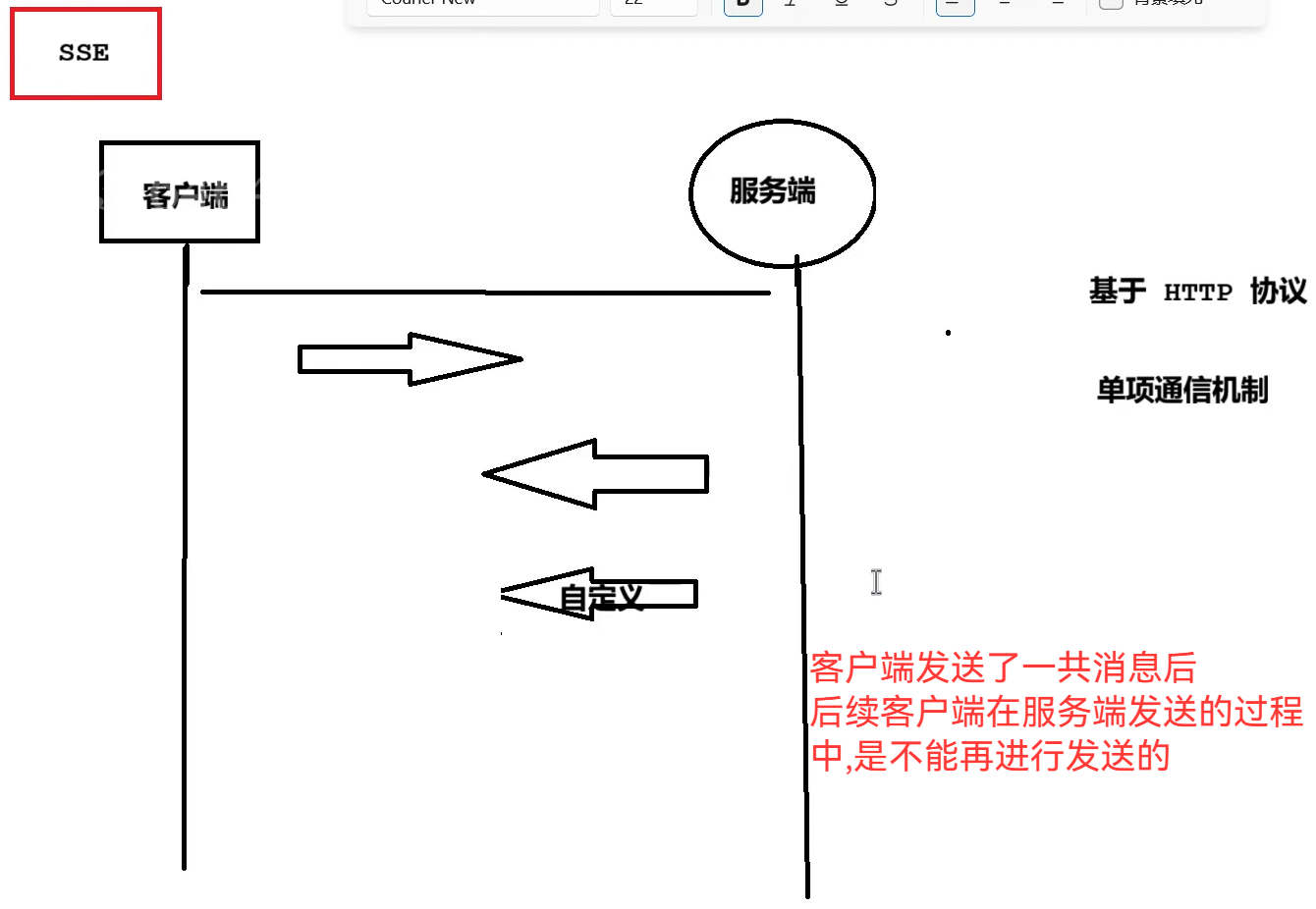


python
Content-Type: text/event-stream;charset=utf-8
Connection: keep-alive


b.LangChain流式传输流程分析


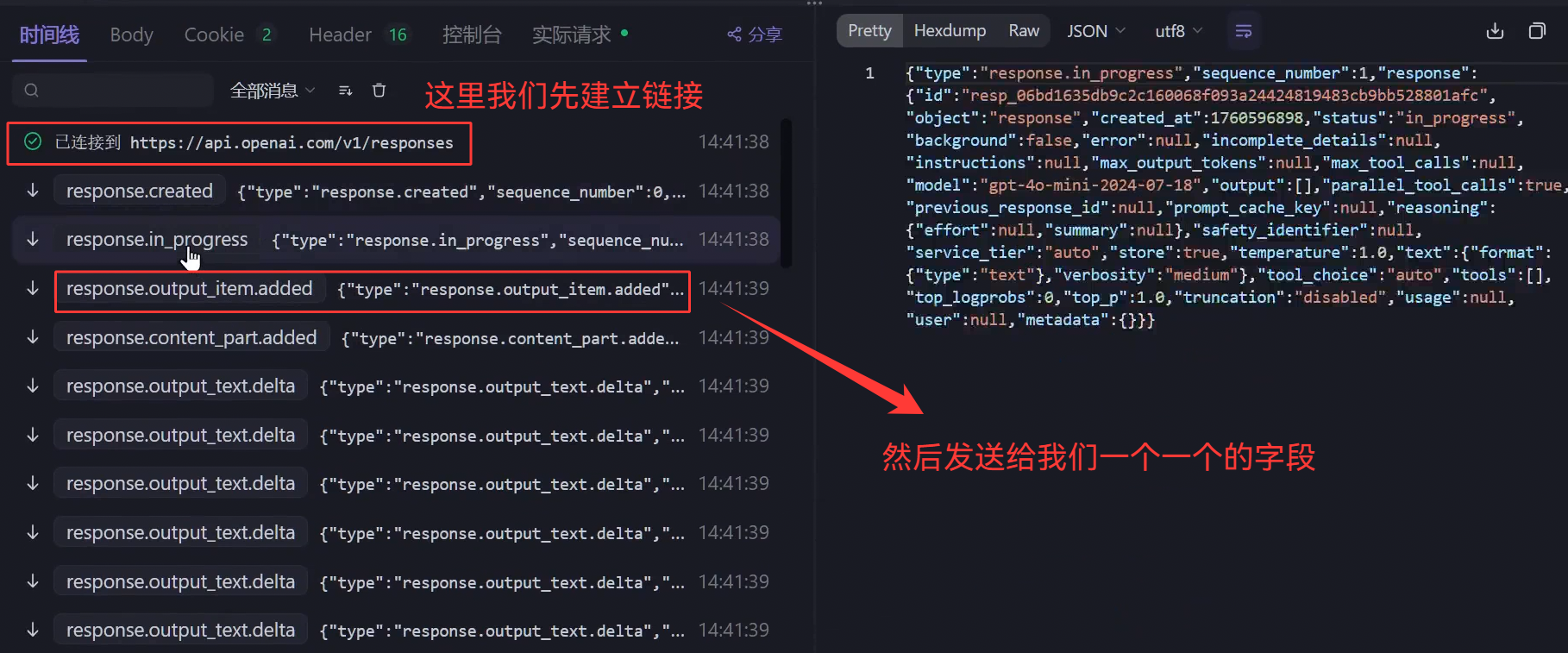

通过源码分析流程

python
# ===================== 导入依赖 =====================
from typing import Iterator, List, Optional, Any
from langchain_core.callbacks import CallbackManagerForLLMRun
from langchain_core.outputs import ChatGenerationChunk
from langchain_core.messages import BaseMessage
# ===================== 核心流式方法 =====================
def _stream(
self,
messages: List[BaseMessage], # 传入的对话消息
stop: Optional[List[str]] = None, # 停止词
run_manager: Optional[CallbackManagerForLLMRun] = None, # 回调管理器
**kwargs: Any # 其他参数
) -> Iterator[ChatGenerationChunk]: # 返回:流式迭代器(一块一块输出)
# 强制开启流式输出(关键:告诉模型要边生成边返回)
kwargs["stream"] = True
# 是否开启流式token统计(默认开启)
stream_usage = self._should_stream_usage(**kwargs)
# 构建请求参数(把消息、停止词等拼成API需要的格式)
payload = self._get_request_payload(messages, stop=stop, **kwargs)
try:
# 如果需要指定返回格式(如JSON),用专用流式接口
if "response_format" in payload:
# 请求流式接口
response_stream = self.root_client.beta.chat.completions.stream(**payload)
context_manager = response_stream
else:
# 普通流式请求
response = self.client.create(**payload)
context_manager = response
# 进入流式响应上下文
with context_manager as response:
# 标记是否是第一个数据块(用于处理元信息)
is_first_chunk = True
# 遍历模型返回的每一块数据(核心:一块一块来)
for chunk in response:
# 把模型返回的原始块 → 转换成 LangChain 标准块
generation_chunk = self._convert_chunk_to_generation_chunk(
chunk,
self.default_chunk_class,
self.base_generation_info if is_first_chunk else {},
)
# 如果块为空,跳过
if generation_chunk is None:
continue
# 回调:告诉外部有新的token生成了
if run_manager is not None:
run_manager.on_llm_new_token(
generation_chunk.text, chunk=generation_chunk
)
# ===================== 核心 =====================
# 输出这一块数据!!!
# 外面的 for chunk in chain.stream() 就是接收这里 yield 的内容
yield generation_chunk
# 第一个块处理完,标记为False
is_first_chunk = False
# 捕获API请求错误
except Exception as e:
self._handle_openai_bad_request(e)
raise e
LangChain请求OpenAI使用什么协议?

python
# 导入 openai 库,用于继承其默认 HTTP 客户端类
import openai
# 导入 os 库,用于读取环境变量(代码中隐含使用,需补充导入)
import os
from typing import Optional, Any
# 定义一个同步 HTTP 客户端包装类,继承自 openai 的 DefaultHttpClient
# 作用:在 openai 原生客户端基础上,增加安全的资源回收逻辑
class _SyncHttpxClientWrapper(openai.DefaultHttpClient):
"""Borrowed from openai._base_client"""
# 析构方法:对象被销毁时自动调用,用于资源清理
def __del__(self) -> None:
# 如果客户端已经关闭,直接返回,无需重复操作
if self.is_closed:
return
try:
# 主动调用 close() 方法,关闭 HTTP 连接,释放资源
# 避免连接泄漏,提升程序稳定性
self.close()
except Exception: # noqa: S110
# 捕获所有异常,即使关闭失败也不影响程序运行
# noqa: S110 是代码检查工具的忽略标记,避免"捕获泛型异常"的警告
pass
# 定义构建同步 HTTP 客户端的工厂函数
# 作用:统一创建符合配置的 _SyncHttpxClientWrapper 实例
def _build_sync_httpx_client(
base_url: Optional[str], timeout: Any
) -> _SyncHttpxClientWrapper:
# 按优先级确定 base_url:
# 1. 优先使用传入的 base_url 参数
# 2. 若参数为空,读取环境变量 OPENAI_BASE_URL
# 3. 若环境变量也为空,使用默认的 OpenAI 官方 API 地址
return _SyncHttpxClientWrapper(
base_url=base_url
or os.environ.get("OPENAI_BASE_URL")
or "https://api.openai.com/v1",
timeout=timeout,
)
LangChain如何支持流式传输?




OpenAI返回的块是什么格式,如何转换成 AIMessageChunk ?
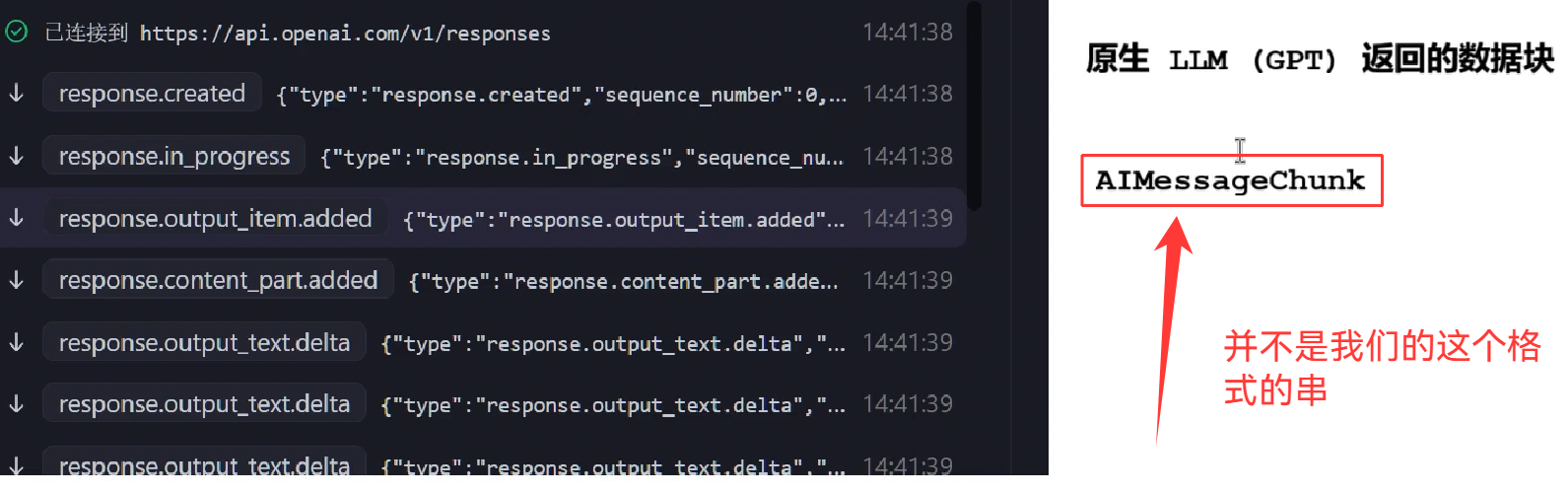

python
# 将模型返回的chunk 转换为 LangChain 标准的 ChatGenerationChunk
def _convert_chunk_to_generation_chunk(
self,
chunk: dict,
default_chunk_class: type[BaseMessageChunk],
base_generation_info: Optional[dict]
) -> Optional[ChatGenerationChunk]:
# 获取choices字段,兼容普通流式与beta流式两种格式
choices = (
chunk.get("choices", [])
or chunk.get("chunk", {}).get("choices", [])
)
# 取第一个结果
choice = choices[0]
# 如果delta为空,直接返回None
if choice["delta"] is None:
return None
# 把delta转换为消息块
message_chunk = _convert_delta_to_message_chunk(
choice["delta"], default_chunk_class
)
# 构建生成信息
generation_info = {**base_generation_info} if base_generation_info else {}
# 封装并返回标准的 ChatGenerationChunk
generation_chunk = ChatGenerationChunk(
message=message_chunk, generation_info=generation_info or None
)
return generation_chunk
# 将OpenAI格式的delta 转换为 LangChain 消息块
def _convert_delta_to_message_chunk(
_dict: Mapping[str, Any], default_class: type[BaseMessageChunk]
) -> BaseMessageChunk:
id_ = _dict.get("id")
role = cast(str, _dict.get("role"))
content = cast(str, _dict.get("content")) or ""
additional_kwargs: dict = {}
# 处理旧版 function_call
if _dict.get("function_call"):
function_call = dict(_dict["function_call"])
if "name" in function_call and function_call["name"] is None:
function_call["name"] = ""
additional_kwargs["function_call"] = function_call
# 处理新版 tool_calls
tool_call_chunks = []
if raw_tool_calls := _dict.get("tool_calls"):
additional_kwargs["tool_calls"] = raw_tool_calls
try:
tool_call_chunks = [
tool_call_chunk(
name=rtc["function"].get("name"),
args=rtc["function"].get("arguments"),
id=rtc.get("id"),
index=rtc["index"],
)
for rtc in raw_tool_calls
]
except KeyError:
pass
# 根据角色返回对应消息块
if role == "user" or default_class == HumanMessageChunk:
return HumanMessageChunk(content=content, id=id_)
elif role == "assistant" or default_class == AIMessageChunk:
return AIMessageChunk(
content=content,
additional_kwargs=additional_kwargs,
id=id_,
tool_call_chunks=tool_call_chunks,
)
elif role in ("system", "developer") or default_class == SystemMessageChunk:
if role == "developer":
additional_kwargs = {"__openai_role__": "developer"}
else:
additional_kwargs = {}
return SystemMessageChunk(
content=content, id=id_, additional_kwargs=additional_kwargs
)
elif role == "function" or default_class == FunctionMessageChunk:
return FunctionMessageChunk(content=content, name=_dict["name"], id=id_)
elif role == "tool" or default_class == ToolMessageChunk:
return ToolMessageChunk(
content=content, tool_call_id=_dict["tool_call_id"], id=id_
)
elif role or default_class == ChatMessageChunk:
return ChatMessageChunk(content=content, role=role, id=id_)
else:
return default_class(content=content, id=id_)

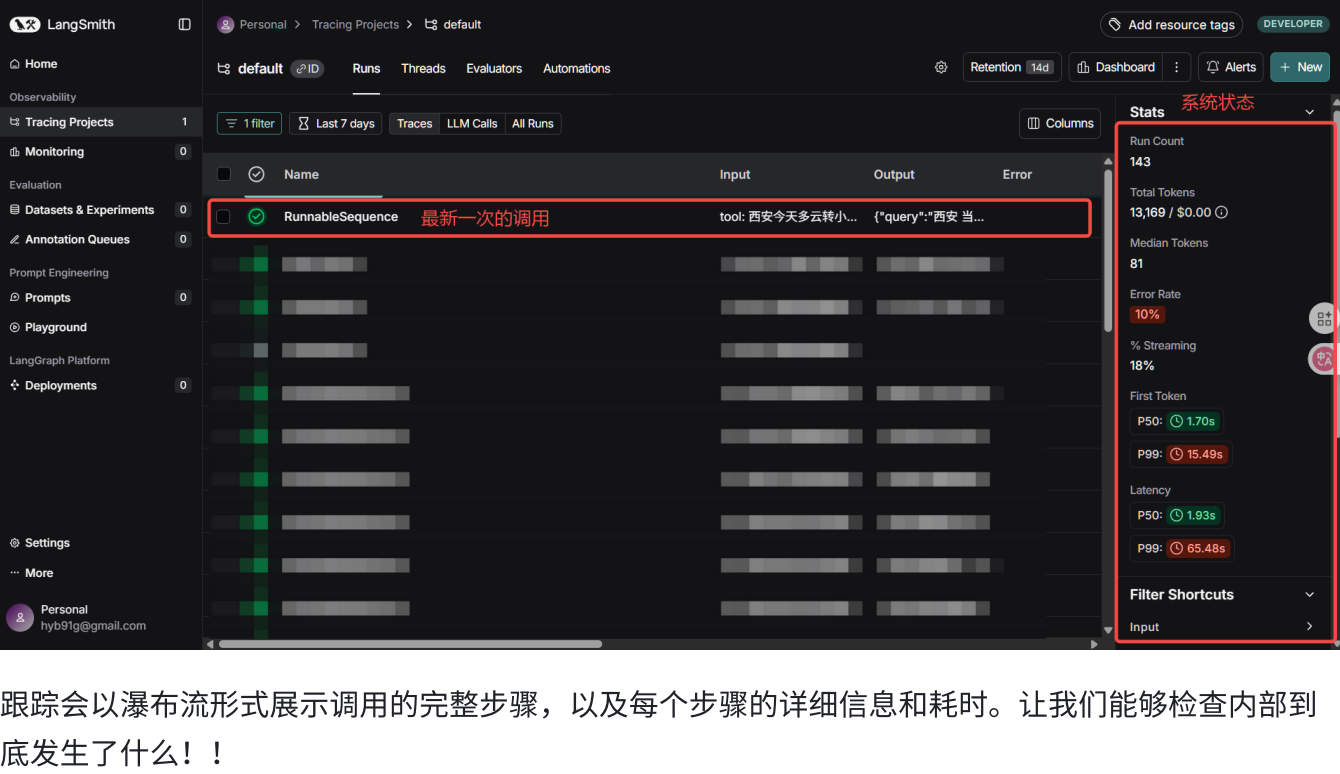
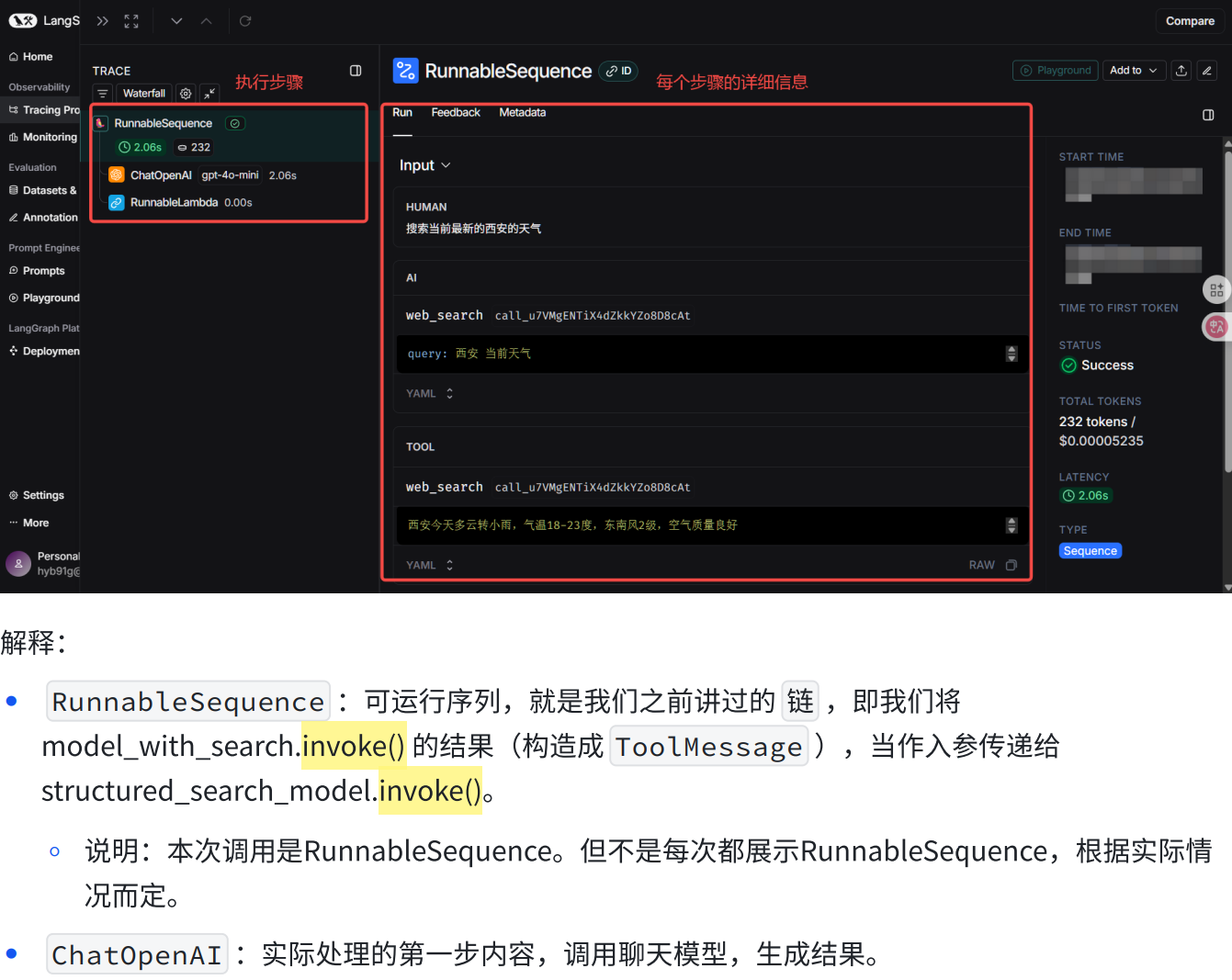
三.使用LangSmith跟踪LLM应用

LangSmith链接:https://smith.langchain.com/
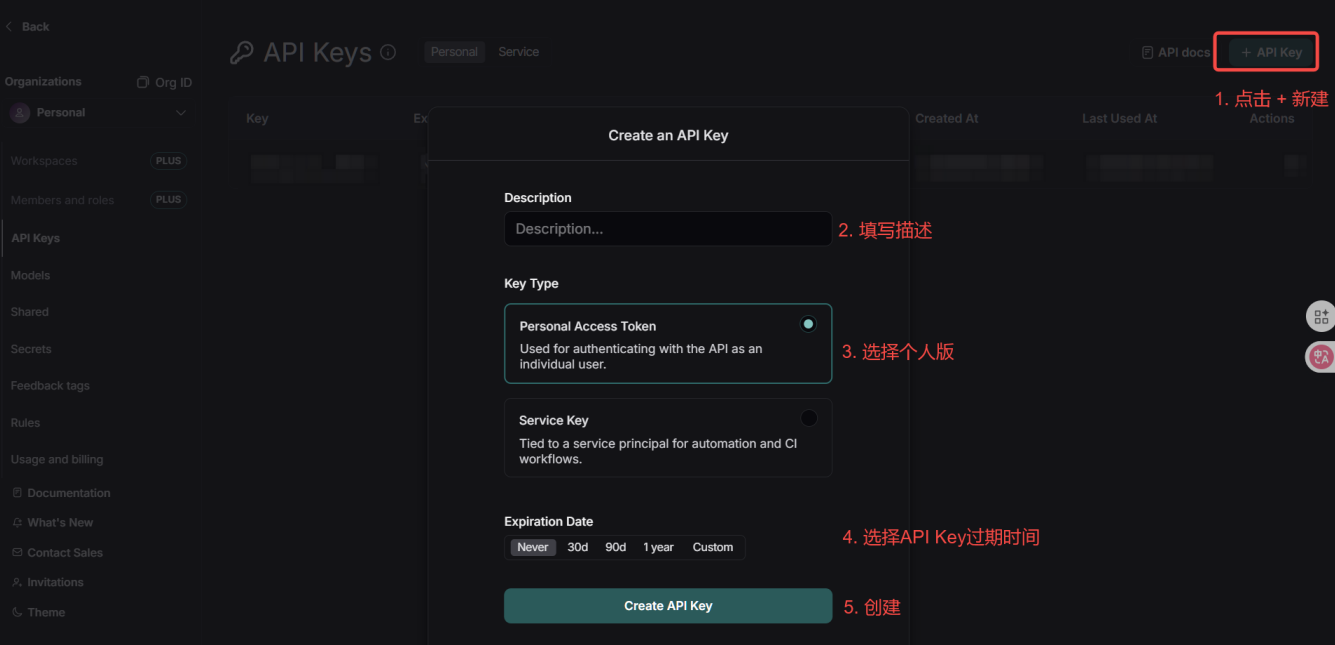
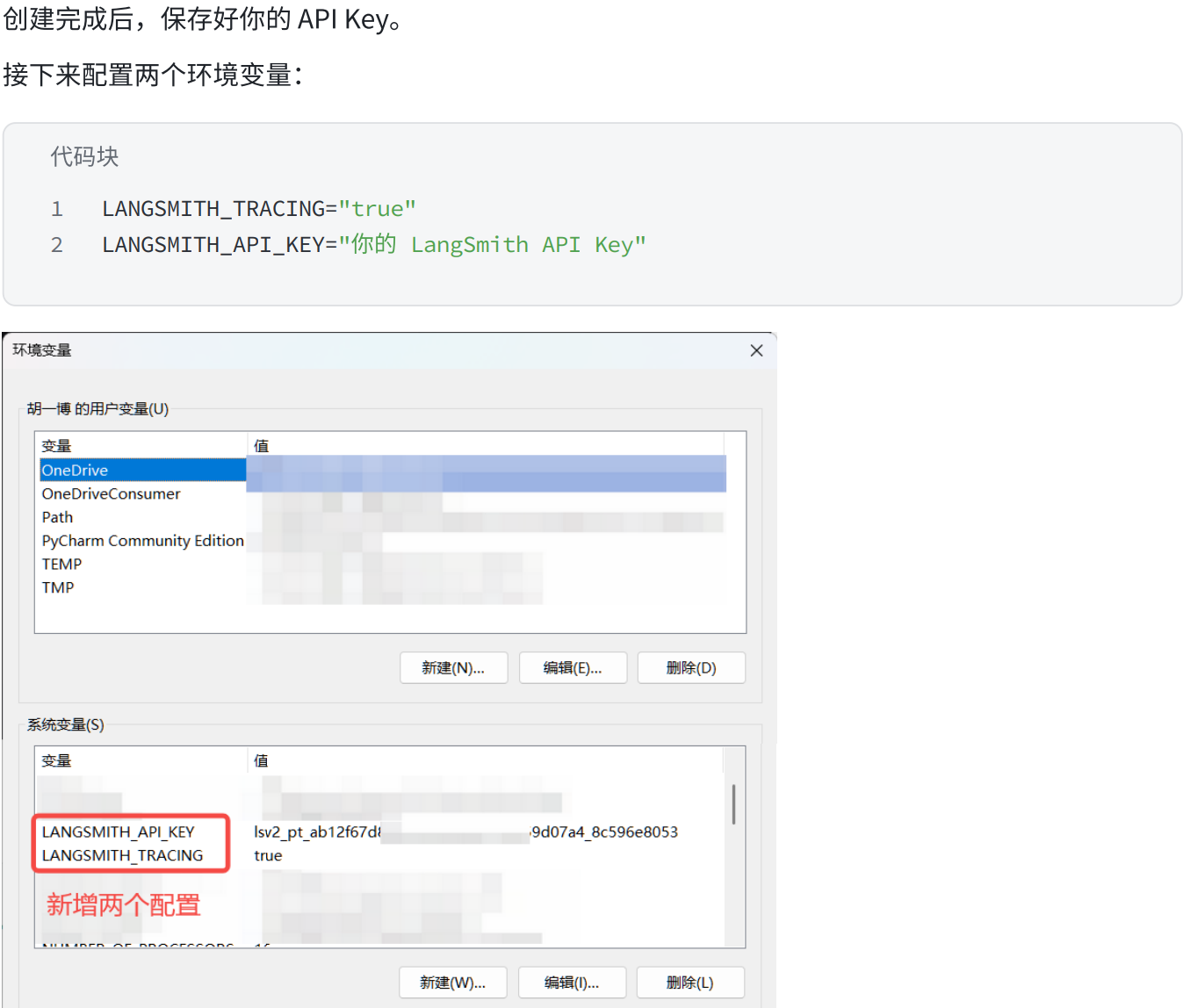


他就会自动追踪我们所有的调用的代码