一、研究背景
时间序列预测在金融、气象、电力负荷、设备故障诊断等领域具有广泛应用。实际信号往往具有非线性、非平稳、多尺度 特征,单一预测模型难以捕捉其复杂动态特性。为此,研究者常采用信号分解 + 深度学习的混合建模方法。本代码实现了一种结合:
- CEEMDAN(完全自适应噪声集合经验模态分解)
- 样本熵 + K-means 聚类
- VMD(变分模态分解)
- Transformer + BiLSTM 网络
的多级分解与深度学习融合预测模型,旨在提高复杂时间序列的预测精度。
二、主要功能
main1_CEEMDAN_Kmeans_VMD.m
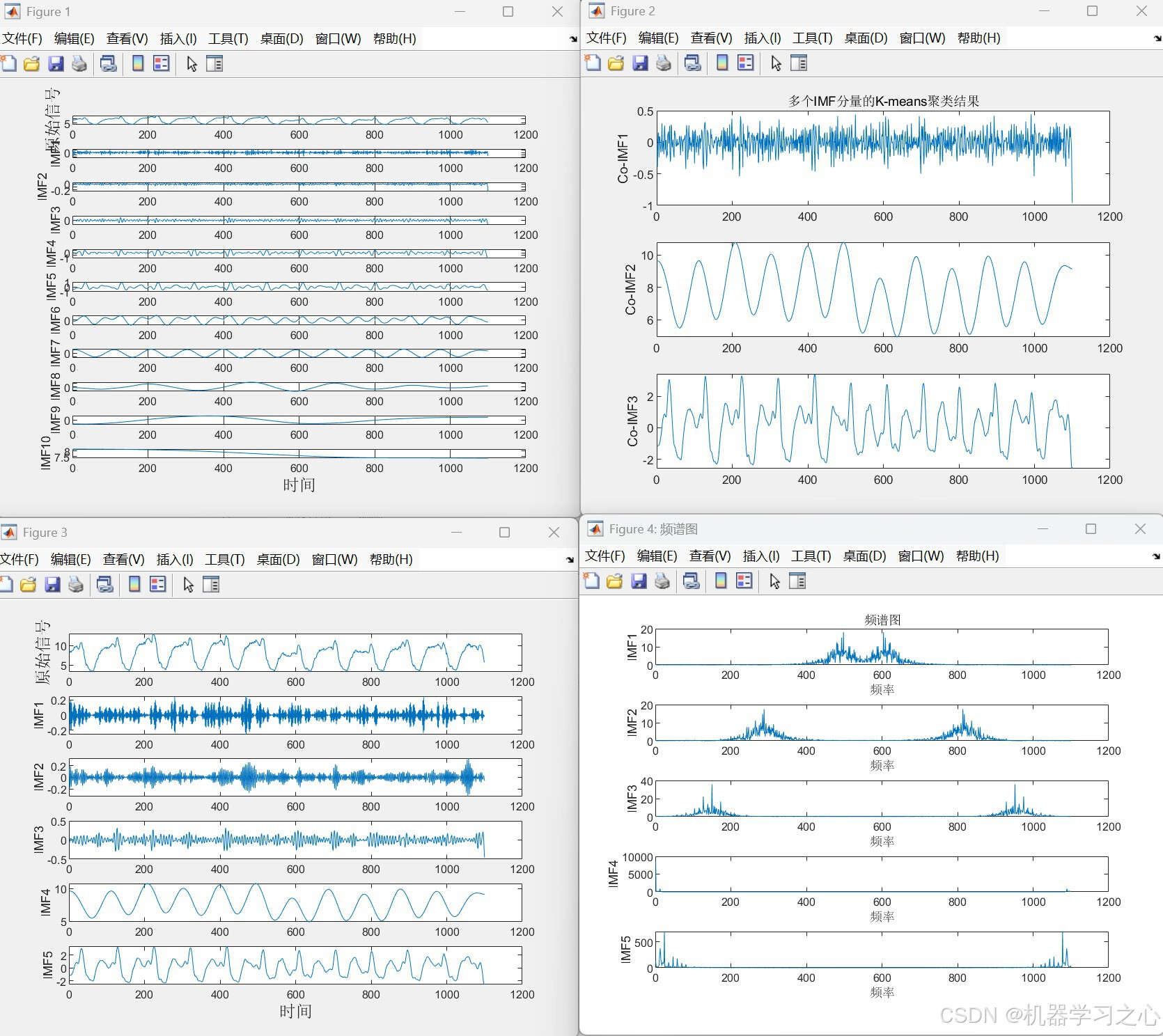
- 读取原始时间序列数据。
- 使用 CEEMDAN 将信号分解为多个本征模态函数(IMF)。
- 计算每个 IMF 的样本熵。
- 基于样本熵使用 K-means 聚类将 IMF 重构成高、中、低频三个分量。
- 对高频分量 进一步使用 VMD 分解。
- 保存最终分解后的分量数据
Co_data.mat。
main2_CEEMDAN_VMD_Transformer_BiLSTM.m
- 加载分解后的分量数据。
- 对每个分量分别构建 Transformer + BiLSTM 模型进行预测。
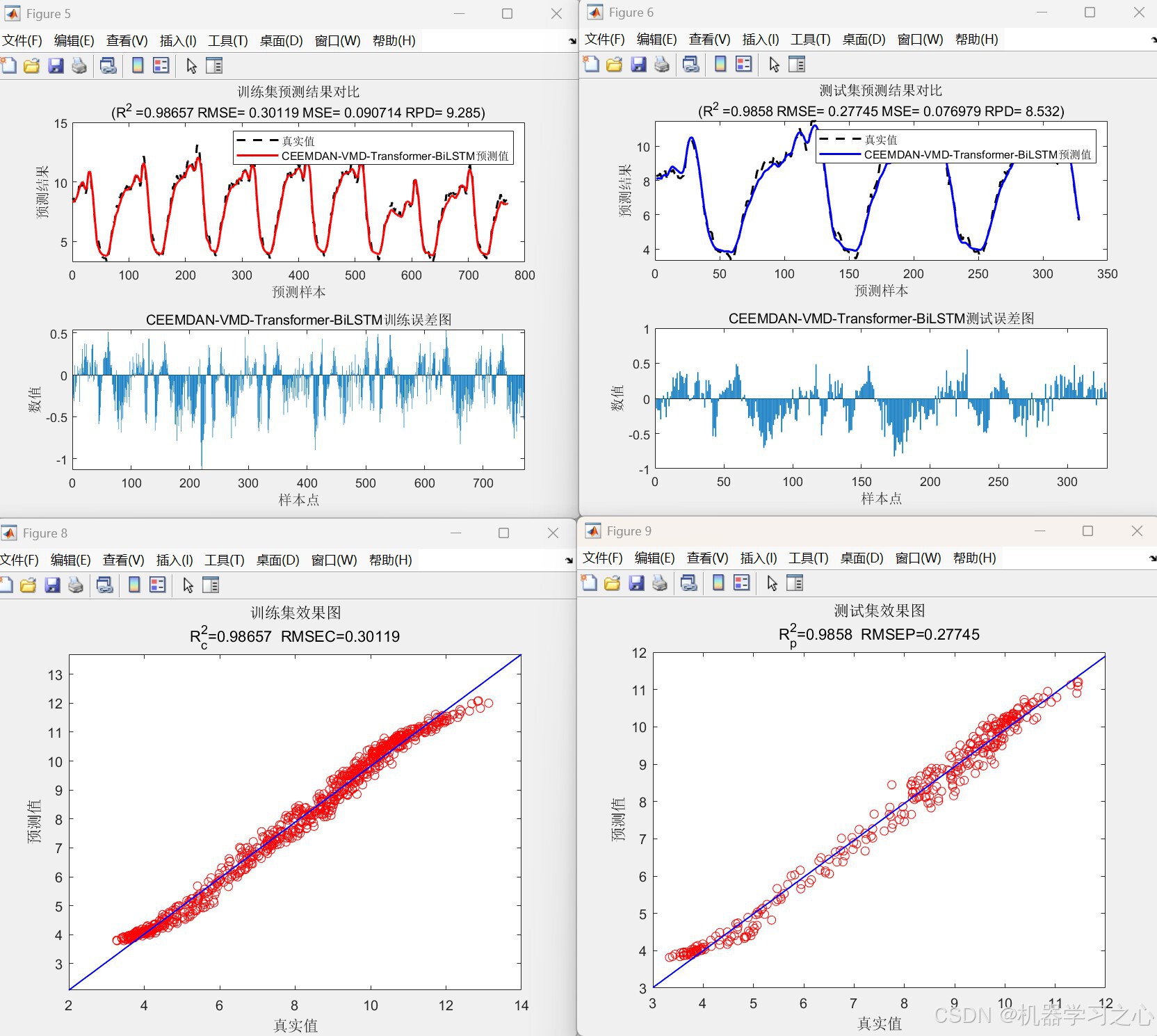
- 将所有分量的预测结果求和得到最终预测值。
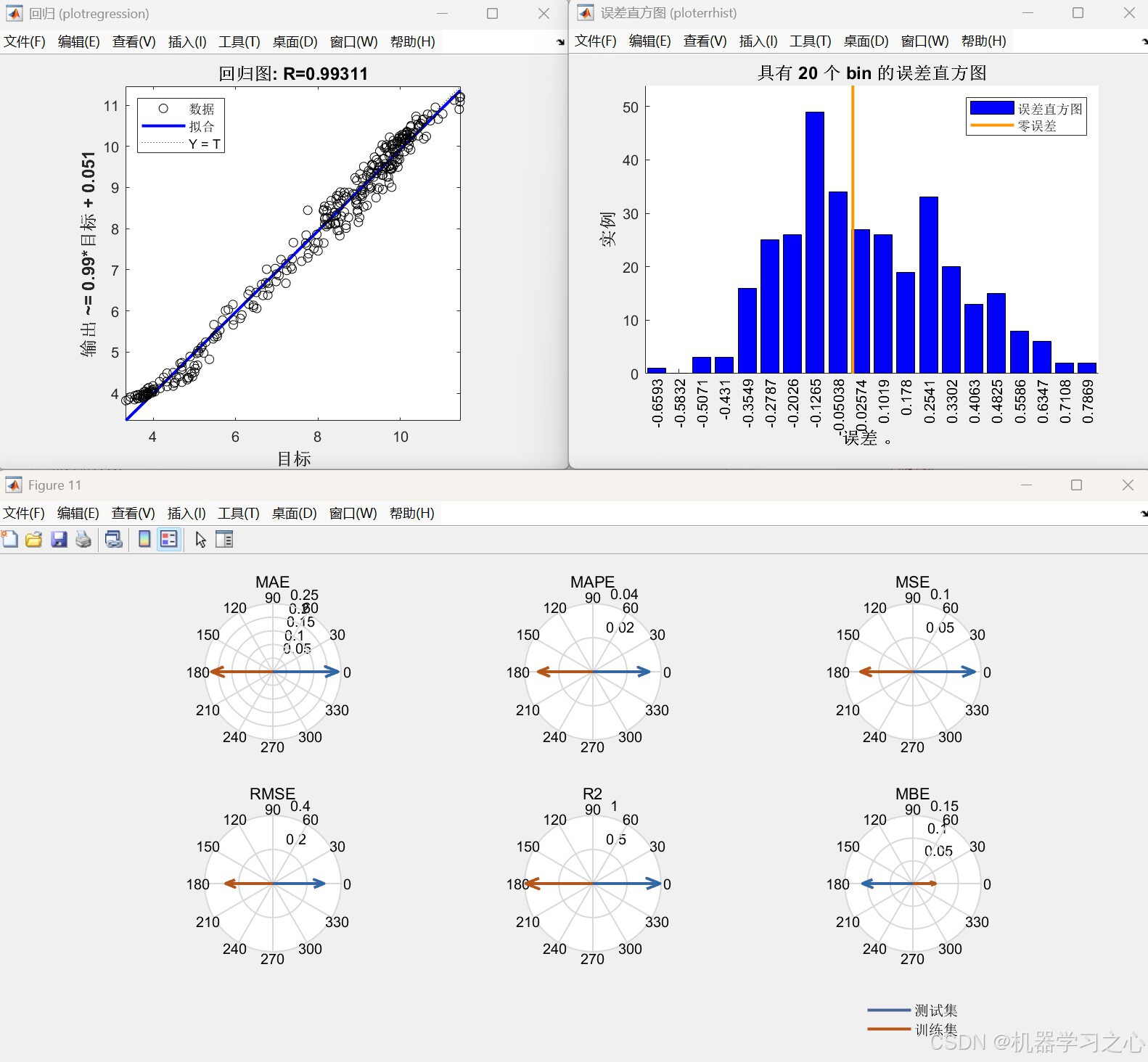
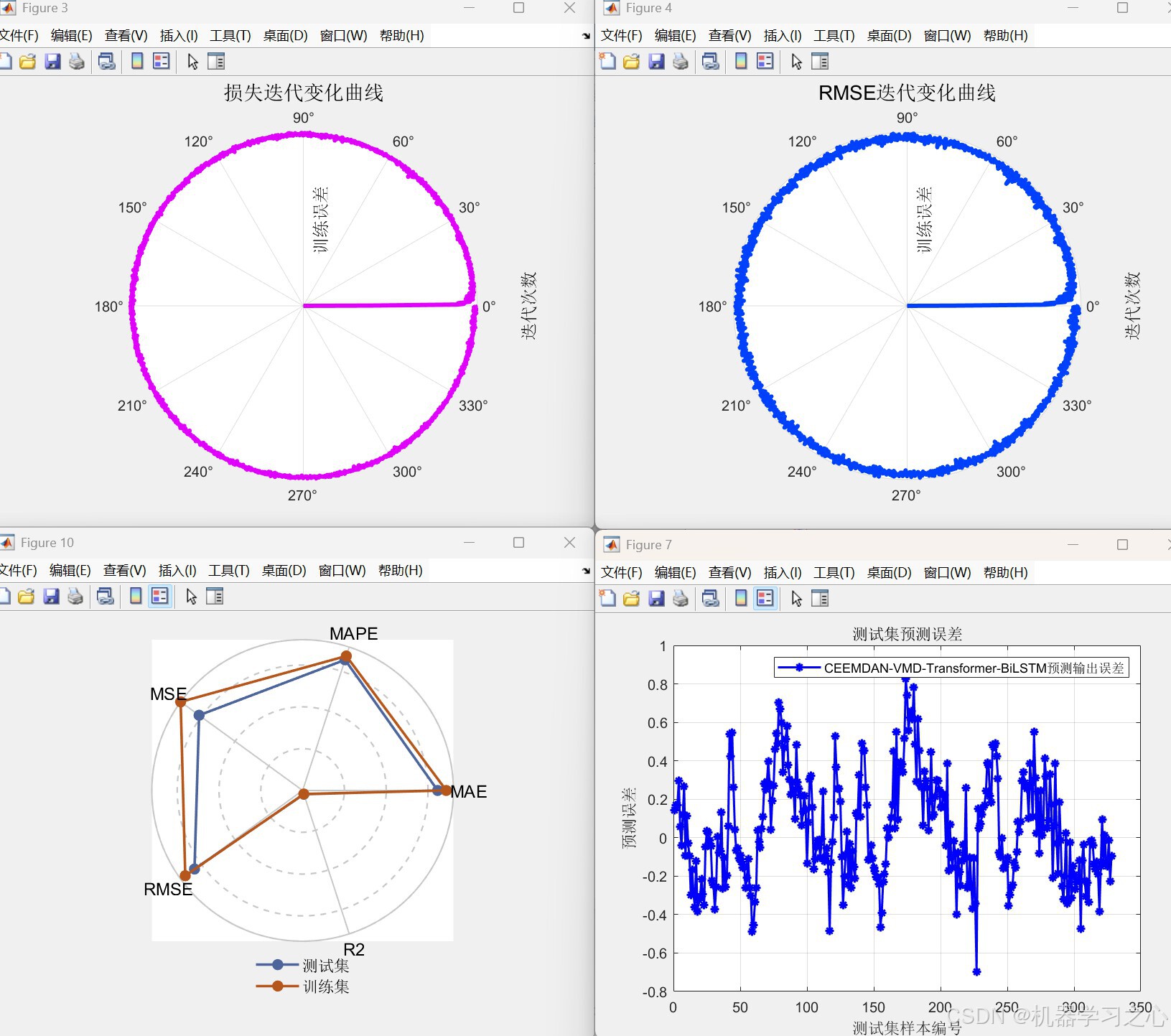
- 输出多种评价指标(MAE、MSE、RMSE、R²、MAPE、RPD 等)。
- 绘制预测对比图、误差图、雷达图、罗盘图等。
三、算法步骤
步骤1:CEEMDAN 分解
- 对原始信号
X进行 CEEMDAN 分解,得到多个 IMF。
步骤2:样本熵计算与聚类
- 计算每个 IMF 的样本熵。
- 使用 K-means(k=3)将 IMF 聚类为三类:高频、中频、低频。
- 分别求和得到三个重构分量
Co_IMF1(高频)、Co_IMF2(中频)、Co_IMF3(低频)。
步骤3:VMD 二次分解
- 对高频分量
Co_IMF1进行 VMD 分解(K=3),得到更细粒度的子分量。
步骤4:构建预测数据集
- 对每个分量,使用滑动窗口构造输入输出样本(
kim历史步长,zim预测步长)。
步骤5:Transformer-BiLSTM 建模
- 对每个分量训练一个包含:
- 位置嵌入层
- 自注意力层(因果 + 标准)
- BiLSTM 层
- 全连接回归层
的深度网络。
步骤6:预测与重构
- 每个分量输出预测结果,求和得到最终预测。
步骤7:评估与可视化
- 计算训练集/测试集的多种误差指标。
- 绘制预测曲线、误差直方图、雷达图、罗盘图等。
四、技术路线
text
原始信号
↓
CEEMDAN(多尺度分解)
↓
样本熵 + K-means(重构高/中/低频)
↓
高频 → VMD(二次分解)
↓
各分量分别建模(Transformer + BiLSTM)
↓
预测结果求和
↓
误差评估 & 可视化五、公式原理简述
1. CEEMDAN
通过在 EMD 分解过程中添加自适应白噪声,解决模态混叠问题。第 k 阶 IMF 定义为:
IMFk=1N∑i=1NE1(rk−1+εk−1wi) IMF_k = \frac{1}{N} \sum_{i=1}^{N} E_1(r_{k-1} + \varepsilon_{k-1} w_i) IMFk=N1i=1∑NE1(rk−1+εk−1wi)
其中 E1E_1E1为 EMD 算子,wiw_iwi为白噪声,ε\varepsilonε 为噪声系数。
2. 样本熵(Sample Entropy)
衡量序列复杂度:
SampEn(m,r,N)=−lnAB SampEn(m, r, N) = -\ln\frac{A}{B} SampEn(m,r,N)=−lnBA
- mmm:嵌入维数
- rrr:相似容限
- AAA:匹配m+1m+1m+1个点的对数
- BBB:匹配mmm个点的对数
3. VMD
将信号分解为 K 个带限模态uku_kuk,最小化各模态带宽之和:
minuk,ωk∑k∥∂t(δ(t)+jπt)∗uk(t)e−jωkt∥22 \min_{u_k, \omega_k} \sum_k \left\| \partial_t \left \\left( \\delta(t) + \\frac{j}{\\pi t} \\right) \* u_k(t) \\right e^{-j\omega_k t} \right\|_2^2 uk,ωkmink∑ ∂t(δ(t)+πtj)∗uk(t)e−jωkt 22
4. Transformer 自注意力机制
Attention(Q,K,V)=softmax(QKTdk)V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right) V Attention(Q,K,V)=softmax(dk QKT)V
5. BiLSTM
双向 LSTM 同时利用过去和未来信息:
ht⃗=LSTM(xt,h⃗t−1),ht←=LSTM(xt,h←t+1) \vec{h_t} = LSTM(x_t, \vec{h}{t-1}), \quad \overleftarrow{h_t} = LSTM(x_t, \overleftarrow{h}{t+1}) ht =LSTM(xt,h t−1),ht =LSTM(xt,h t+1)
Ht=ht⃗,ht← H_t = \\vec{h_t}, \\overleftarrow{h_t} Ht=ht ,ht
六、参数设定
| 参数 | 值 | 说明 |
|---|---|---|
Nstd |
0.2 | CEEMDAN 噪声标准差 |
NR |
500 | CEEMDAN 集成次数 |
MaxIter |
5000 | CEEMDAN 最大迭代次数 |
dim |
2 | 样本熵嵌入维数 |
r |
0.2*std(x) | 样本熵相似容限 |
K(VMD) |
3 | VMD 分解模态数 |
kim |
2 | 历史步长 |
zim |
1 | 预测步长 |
best_numHeads |
8 | 自注意力头数 |
best_hd |
64 | BiLSTM 隐藏单元数 |
best_lr |
0.01 | 初始学习率 |
best_l2 |
0.001 | L2 正则化系数 |
MaxEpochs |
500 | 最大训练轮数 |
MiniBatchSize |
256 | 批次大小 |
七、运行环境
- 软件:MATLAB(建议 R2024b 及以上)
八、应用场景
- 电力负荷预测:处理具有强波动性和周期性的负荷数据。
- 风速/光伏功率预测:非平稳气象时间序列。
- 设备振动信号预测:如轴承、齿轮箱故障趋势预测。
- 金融时间序列预测:如股票、汇率等高频数据。
- 环境监测:如空气质量、水质指标时序预测。
该模型特别适合非线性、多尺度、含噪声的复杂时间序列预测任务。