为什么做归一化和标准化
特征单位或者大小相差较大,或者某个特征的方差相比其他的特征要打出几个数量级,容易影响(支配)目标,使得一些模型(算法)无法学习到其他特征
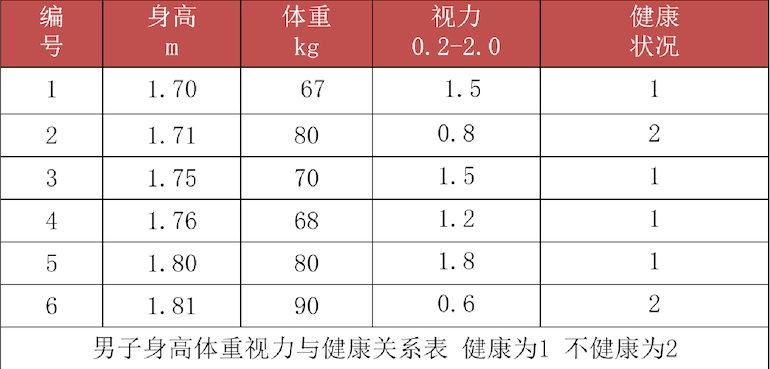
身高、体重、视力 都是特征
健康状况 为标签
这个特征数据就存在量纲问题。
归一化:
通过对原始数据进行变换把数据映射到【mi,mx】(默认为0,1)之间
第一步:
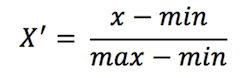

x :特征值
min: 这一列最小特征值
max: 这一列最大特征值
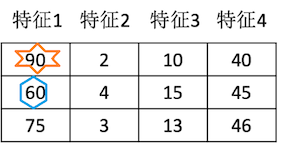
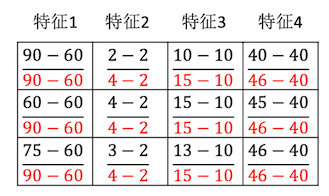
这个数据存在量纲问题,使用归一化公式
注意:这里是指所有的数据都需要进行归一化

第二步:
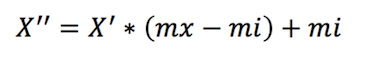

mi,mx 默认为0,1
mx 这里为 1
mi 这里为0
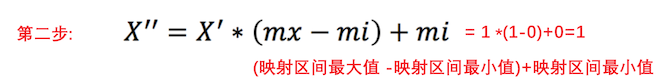
第二步后得出的结果
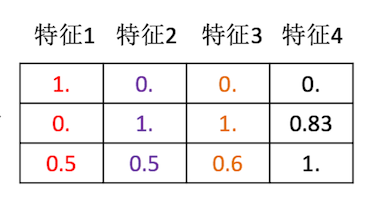
总结:
归一化弊端,容易收到 最大值和最小值的影响
python
from sklearn.preprocessing import MinMaxScaler
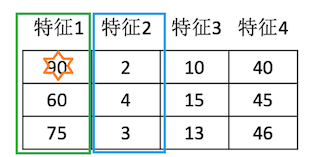
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
transfer = MinMaxScaler(feature_range=(0, 1)) #归一化对象 默认之前(0, 1)
new_data = transfer.fit_transform(data)
print(new_data)
标准化:
通过对原始数据进行标准化,转换为均值为0 标注差为1 的标准正态分布的数据
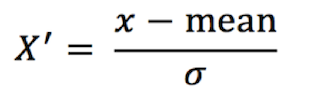

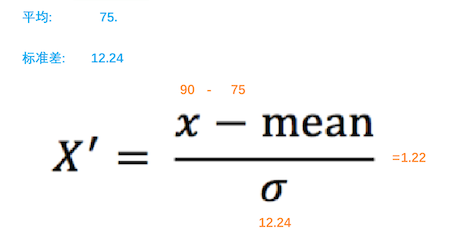

python
from sklearn.preprocessing import StandardScaler
data = [[90, 2, 10, 40],
[60, 4, 15, 45],
[75, 3, 13, 46]]
#标准化 对象
transfer = StandardScaler()
new_data = transfer.fit_transform(data)
print(f'标准化的结果:\n{new_data}')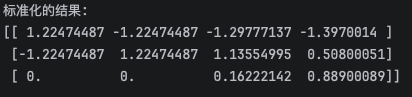
归一化 vs 标准化 快速对比
| 方法 | 公式 | 适用场景 | 优点 | 注意事项 |
|---|---|---|---|---|
| 归一化 (Min-Max) | 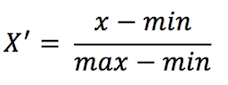 |
特征边界明确、无极端异常值 | 缩放到 0,1,直观 | 对异常值敏感 |
| 标准化 (Z-score) | 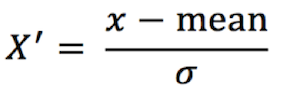 |
特征近似正态分布、或含异常值 | 稳健,均值为0方差为1 | 结果无固定范围 |
sklearn.preprocessing MinMaxScaler (归一化)
sklearn.preprocessing StandardScaler. (标准化)