schoober-ai-sdk:核心ReAct 引擎的实现
github:Schoober AI SDK GitHub 仓库
各位看官求🌟一下,小的先在此谢过
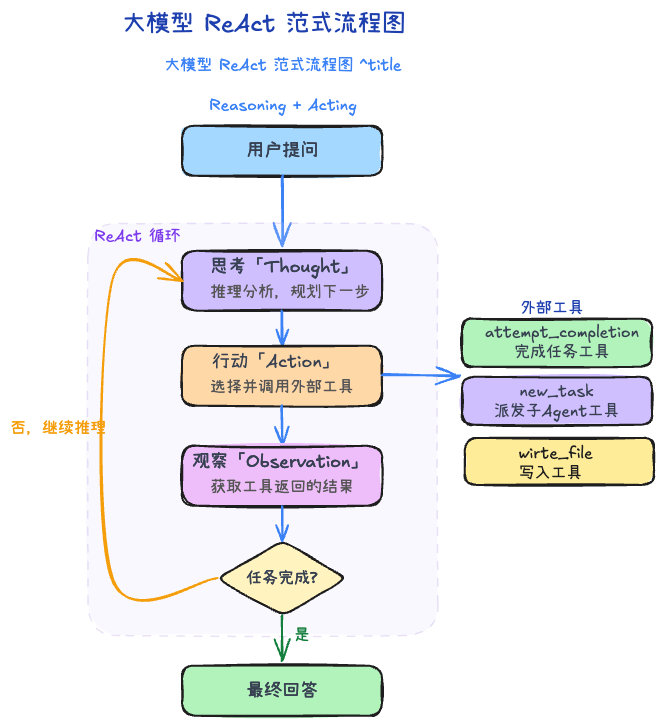
1. 从论文到工程:ReAct 模式回顾
ReAct(Reasoning + Acting)源自 2022 年的同名论文,核心思想是让 LLM 在推理(Reason)和行动(Act)之间交替进行,而非一次性生成最终答案。每一轮循环包含三个阶段:
Reason → LLM 分析当前状态,决定下一步行动
Act → 调用外部工具执行具体操作
Observe → 获取工具返回的结果,作为下一轮推理的输入这个循环持续进行,直到 LLM 判断任务已完成(或无法继续)。
如下图所示:
在 schoober-ai-sdk 中,这个循环由三个核心模块协作完成:
| 模块 | 职责 |
|---|---|
ReActEngine |
驱动 Reason→Act→Observe 循环,控制启停 |
ExecutionManager |
执行单次 LLM 请求,处理流式响应 |
ErrorTracker |
追踪错误,决定是否暂停循环 |
下面逐层拆解实现。
2. ReActEngine:循环的驱动者
2.1 循环结构
ReActEngine.run() 是整个 Agent 的心跳。它的结构出乎意料地简单------一个 while 循环:
typescript
async run(): Promise<void> {
this.abortController = new AbortController();
let loopCount = 0;
let consecutiveNoToolExecutionCount = 0;
while (this.callbacks.getStatus() === TaskStatus.RUNNING) {
loopCount++;
// 检查是否被外部中止
if (this.abortController.signal.aborted) {
break;
}
// 执行单步 ReAct
const result = await this.executeStep();
// 根据执行结果决定下一步...
}
}循环的退出条件不是内部标志,而是直接检查任务状态。这意味着当工具调用了 attempt_completion 将状态设为 COMPLETED,或者外部调用了 task.abort(),循环会在下一次检查时自然停止。这种设计避免了内部状态和外部状态不一致的问题。
2.2 单步执行:executeStep()
每一轮 executeStep() 做了四件事:
1. 收集上下文 → 获取消息历史 + 动态生成 systemPrompt
2. 调用 LLM → 通过 ExecutionManager 发起流式请求
3. 解析响应 → 将流式输出分离为 text(推理)和 tool_use(行动)
4. 执行工具 → 调用对应工具,将结果写回消息历史其中最关键的是第 1 步------每一轮循环都会重新生成 systemPrompt:
typescript
// 获取当前任务状态快照
const taskState = this.callbacks.getTaskState();
// 动态生成系统提示词(每轮都会重新生成)
const systemPrompt = await this.callbacks.buildSystemPrompt(taskState);
// 动态生成环境变量提示词(注入实时上下文)
const envPrompt = await this.callbacks.buildEnvironmentPrompt(taskState);为什么每轮都要重新生成?因为任务状态在不断变化------工具注册/注销、子任务状态更新、重试计数增加------这些变化需要实时反映到 LLM 的输入中。systemPrompt 的组合顺序是:
coreSystemPrompt(行为规范)
↓
rolePromptBuilder(动态角色信息,如重试次数)
↓
工具定义列表(Zod Schema → 可读文本)
↓
子 Agent 信息(如果有)environmentPromptBuilder 的输出则作为消息队列末尾的一条 user 消息注入,适合放置实时上下文(如当前时间、环境变量)。
3. ExecutionManager:流式响应的处理
3.1 流式处理流程
ExecutionManager.execute() 负责与 LLM Provider 交互。整个流程是:
构建 StreamConfig → 创建流 → 逐 chunk 处理 → 等待工具执行 → 完成流式响应的处理在 handleStream() 中完成,这是整个引擎最复杂的部分。它需要同时处理四种类型的 chunk:
typescript
for await (const chunk of stream) {
switch (chunk.type) {
case 'text': // LLM 的文本输出(推理过程)
case 'usage': // Token 使用统计
case 'error': // 流级别错误
case 'end': // 流结束信号
}
}3.2 文本与工具调用的分离
text 类型的 chunk 是最核心的。每个 text chunk 到达后,会经过 MessageParser 解析,产出两种内容:
- TextContent:LLM 的推理文本,直接流式推送给前端
- ToolUse:工具调用指令,包含工具名、参数、requestId
typescript
case 'text':
// 解析 chunk,可能产出 text 或 tool_use
const parsedContents = this.messageParser.parseChunk(chunk.text);
const content = parsedContents[processContentIndex];
if (content.type === 'text') {
// 文本:await 保证顺序输出
await callbacks.onTextContent(textContent.text);
} else if (content.type === 'tool_use') {
// 工具调用:不 await,收集 Promise 并行执行
const promise = callbacks.onToolUse(toolUse);
toolExecutionPromises.push(promise);
}
// 当前内容块完成,移动到下一个
if (content.partial === false) {
processContentIndex++;
}注意这里的设计差异:文本输出是 await 的 (保证流式输出的顺序),而工具调用不 await(收集 Promise,允许多个工具并行执行)。
3.3 工具的并行执行与同步等待
当一次 LLM 响应中包含多个工具调用时(比如同时调用搜索工具和数据库查询工具),它们会被并行执行:
typescript
// 流结束后,等待所有工具执行完成
if (toolExecutionPromises.length > 0) {
const results = await Promise.allSettled(toolExecutionPromises);
// 记录失败的工具执行(不影响其他工具)
results.forEach((result, index) => {
if (result.status === 'rejected') {
// 记录错误日志
}
});
}
// 所有工具完成后,才调用流结束回调
if (callbacks?.onStreamEnd) {
await callbacks.onStreamEnd();
}使用 Promise.allSettled 而非 Promise.all,确保单个工具失败不会阻断其他工具的执行。
3.4 API 消息的记录时序
还有一个容易忽略的细节:API 消息(LLM 的原始返回)的记录发生在工具执行之前:
typescript
// 先完成 API 消息记录
if (callbacks?.onApiMessageFinalize) {
await callbacks.onApiMessageFinalize(apiMessageContent);
}
// 再等待工具执行
await Promise.allSettled(toolExecutionPromises);这个顺序保证了即使工具执行失败或超时,LLM 的原始响应也已经被持久化,不会丢失。
4. 兜底策略:防止 LLM 空转
LLM 并不总是"听话"地调用工具。有时它会生成一段文本但不调用任何工具,导致循环空转、浪费 token。ReActEngine 对此有两层防护:
4.1 提醒机制
当一轮执行没有任何工具调用时,引擎会向消息历史中插入一条提醒:
typescript
if (!result.hasToolExecution) {
consecutiveNoToolExecutionCount++;
await this.callbacks.insertReminderMessage(
'You must call a tool. Please select an appropriate tool ' +
'based on the current task progress, or use the ' +
'attempt_completion tool to complete or abort the task.'
);
continue; // 继续下一轮循环
}这条消息会作为 user 角色出现在消息历史中,在下一轮 LLM 请求时被"看到",引导 LLM 回到正轨。
4.2 硬性阈值
如果连续 3 次都没有工具调用,说明 LLM 可能陷入了无法恢复的状态(比如不理解工具的使用方式,或者 systemPrompt 的指令被忽略)。此时引擎会强制暂停任务:
typescript
if (consecutiveNoToolExecutionCount >= 3) {
await this.callbacks.pauseTask();
break; // 退出循环
}暂停而非终止,是为了给外部(用户或上层系统)一个介入的机会------可以调整 prompt、更换模型、或手动恢复。
5. 中止机制:AbortController
ReActEngine 的中止基于 Web 标准的 AbortController:
typescript
// 引擎启动时创建
this.abortController = new AbortController();
// 外部调用 abort()
abort(): void {
if (this.abortController) {
this.abortController.abort();
}
}AbortSignal 会传递给 ExecutionManager,后者再传递给 LLM Provider。这意味着中止会层层传播:
task.abort()
→ ReActEngine.abort()
→ AbortController.abort()
→ ExecutionManager 检测到 signal.aborted,停止处理流
→ LLM Provider 中止网络请求中止后,run() 方法中的 finally 块会清理 AbortController:
typescript
try {
// ... 循环逻辑
} finally {
this.abortController = undefined;
}6. 错误追踪:ErrorTracker
并非所有错误都应该终止任务。网络抖动、LLM 偶发超时都是正常现象。ErrorTracker 通过错误签名和计数来决定何时真正暂停:
typescript
class ErrorTracker {
private errorHistory: Map<string, ErrorRecord> = new Map();
private maxSameErrorCount: number = 3; // 相同错误的最大重复次数
trackError(error: Error): boolean {
const signature = this.getErrorSignature(error);
const record = this.errorHistory.get(signature);
if (record) {
record.count++;
// 相同错误达到 3 次,返回 true → 暂停任务
return record.count >= this.maxSameErrorCount;
} else {
// 首次出现,记录但不暂停
this.errorHistory.set(signature, { signature, count: 1, ... });
return false;
}
}
}错误签名的生成策略有两种:
- simple :
error.name + error.message,适合大多数场景 - detailed:还包含堆栈前 3 行,用于区分同一错误消息但不同调用点的情况
在 ReActEngine 中,错误追踪贯穿两个层面:
typescript
// 层面 1:单步执行中的工具错误
onToolUse: async (toolUse) => {
try {
await this.callbacks.handleToolExecution(toolUse);
} catch (error) {
const shouldPause = this.callbacks.trackError(errorObj);
if (shouldPause) {
await this.callbacks.pauseTask();
return;
}
// 未达阈值:将错误写入消息历史,让 LLM 自行修正
await this.callbacks.insertReminderMessage(
`工具执行失败: ${toolUse.name}\n错误: ${errorObj.message}`
);
}
}
// 层面 2:循环级别的 LLM 请求错误
while (status === RUNNING) {
try {
await this.executeStep();
} catch (error) {
const shouldPause = this.callbacks.trackError(errorObj);
if (shouldPause) {
await this.callbacks.pauseTask();
break;
}
continue; // 继续下一轮,尝试恢复
}
}设计思路是:偶发错误交给 LLM 自愈,持续错误交给外部处理。
7. 完整数据流
将以上模块串联起来,一次完整的 ReAct 循环数据流如下:
用户输入: "查一下北京的天气"
│
▼
┌─ ReActEngine.run() ─────────────────────────────────────┐
│ │
│ Loop 1: │
│ ┌─ executeStep() ─────────────────────────────────┐ │
│ │ │ │
│ │ 1. buildSystemPrompt(taskState) │ │
│ │ → corePrompt + rolePrompt + 工具定义 │ │
│ │ │ │
│ │ 2. ExecutionManager.execute(messages, options) │ │
│ │ → LLM 返回: │ │
│ │ text: "我来查一下北京的天气" │ │
│ │ tool_use: get_weather({city: "北京"}) │ │
│ │ │ │
│ │ 3. 流式处理: │ │
│ │ text → 推送给前端(await,保证顺序) │ │
│ │ tool_use → 收集 Promise(并行执行) │ │
│ │ │ │
│ │ 4. 工具执行: │ │
│ │ get_weather({city: "北京"}) │ │
│ │ → 返回: {temperature: 22, condition: "晴"} │ │
│ │ → setToolResult() 写入消息历史 │ │
│ │ │ │
│ └───────────────────────────────────────────────────┘ │
│ result: { hasToolExecution: true } │
│ → 重置 consecutiveNoToolExecutionCount = 0 │
│ │
│ Loop 2: │
│ ┌─ executeStep() ─────────────────────────────────┐ │
│ │ │ │
│ │ 消息历史现在包含了天气查询的结果 │ │
│ │ LLM 看到结果后调用 attempt_completion: │ │
│ │ tool_use: attempt_completion({ │ │
│ │ result: "北京当前天气:22°C,晴" │ │
│ │ }) │ │
│ │ → 任务状态变为 COMPLETED │ │
│ │ │ │
│ └───────────────────────────────────────────────────┘ │
│ │
│ while 条件检查: status !== RUNNING → 退出循环 │
│ │
└──────────────────────────────────────────────────────────┘8. 小结
ReActEngine 的设计遵循了几个原则:
- 状态外置:循环条件基于外部任务状态,而非内部标志,避免状态不一致
- 关注点分离:ReActEngine 只管循环控制,ExecutionManager 管 LLM 交互,ErrorTracker 管错误策略
- 渐进式降级:偶发错误 → LLM 自愈;持续错误 → 暂停等待外部介入;外部中止 → 层层传播到网络层
- 流式优先:文本保证顺序输出,工具允许并行执行,API 消息在工具执行前持久化