📖标题:F2LLM-v2: Inclusive, Performant, and Efficient Embeddings for a Multilingual World
🌐来源:arXiv, 2603.19223v1
摘要
我们提出了F2 LLM-v2,一个新的通用多语言嵌入模型家族,有8种不同的大小,从80 M到14 B。F2 LLM-v2在6000万个公开的高质量数据样本的新组合上训练,支持200多种语言,特别强调以前服务不足的中等和低资源语言。通过整合两阶段LLM-基于嵌入训练管道,结合matryoshka学习、模型修剪和知识蒸馏技术,我们提出的模型在保持竞争性能的同时,远比以前基于LLM的嵌入模型更有效。广泛的评估证实,F2 LLMv 2 - 14 B在11个MTEB基准测试中排名第一,同时,该系列中的较小模型也为资源受限的应用程序设定了新的技术水平。为了促进开源嵌入模型研究,我们发布了所有模型,数据,代码和中间检查点。
🛎️文章简介
🔸研究问题:如何解决当前文本嵌入模型存在的严重英语中心主义偏见以及训练数据和方法不透明的问题?
🔸主要贡献:论文提出了 F2LLM-v2 系列模型,通过公开海量多语数据和两阶段训练策略,在支持 200 多种语言的同时实现了从 80M 到 14B 参数规模的高效性能平衡。
📝重点思路
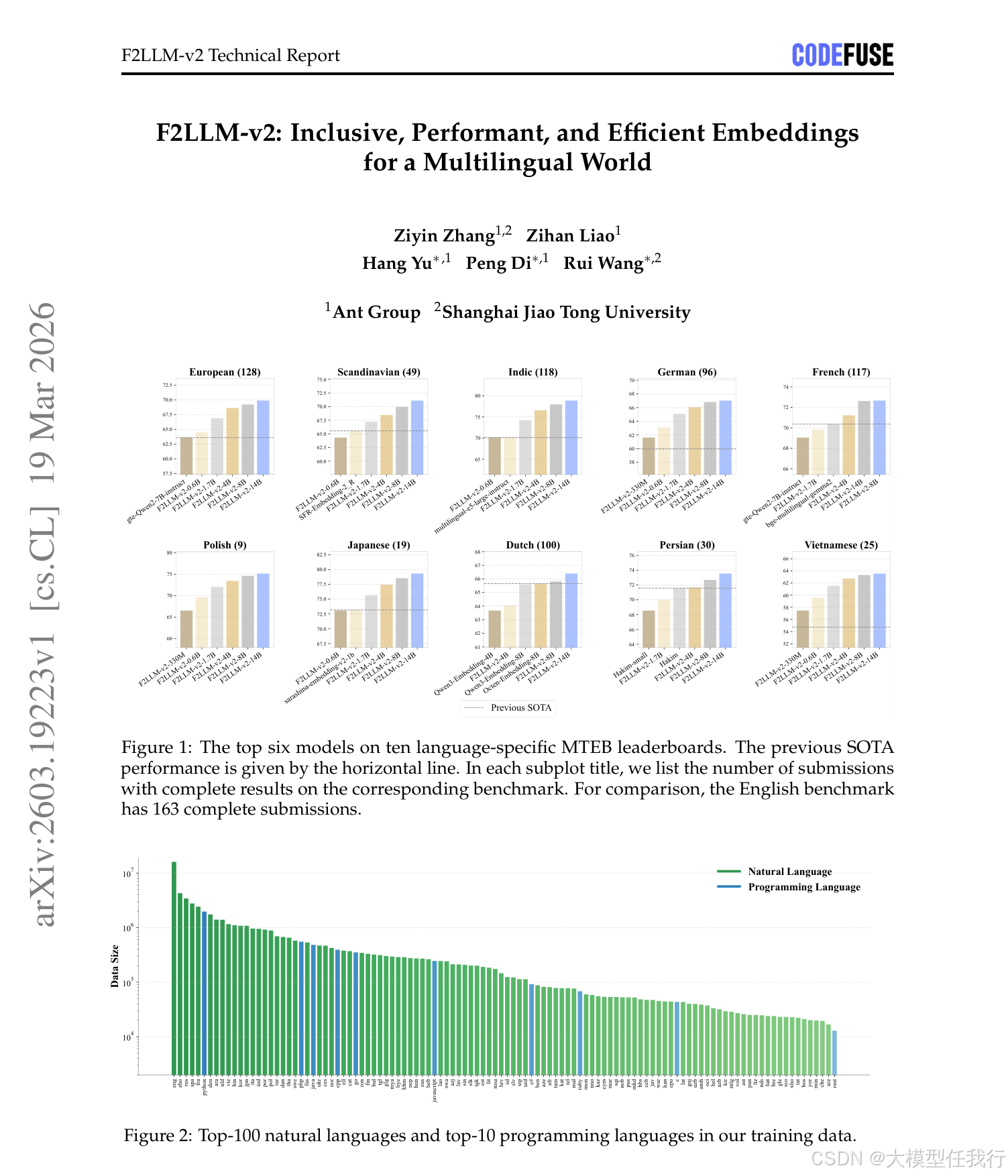
🔸构建了包含 6000 万样本的高质量训练语料库,覆盖 282 种自然语言和 40 多种编程语言,特别关注中低资源语言,且所有数据均源自公开资源以确保透明度。
🔸采用基于 Qwen3 架构的解码器型 Transformer 模型,提供 8 种不同参数量级(80M 至 14B),其中小模型通过对大模型进行结构化剪枝获得。
🔸实施两阶段训练策略:第一阶段利用大规模检索数据构建鲁棒语义基础,第二阶段引入任务特定指令微调以增强分类、重排序等下游任务能力。
🔸结合套娃表示学习(MRL)、模型剪枝和知识蒸馏技术,使小模型在保持极低计算成本的同时,能够继承大模型的语义表达能力并支持动态维度截断。
🔎分析总结
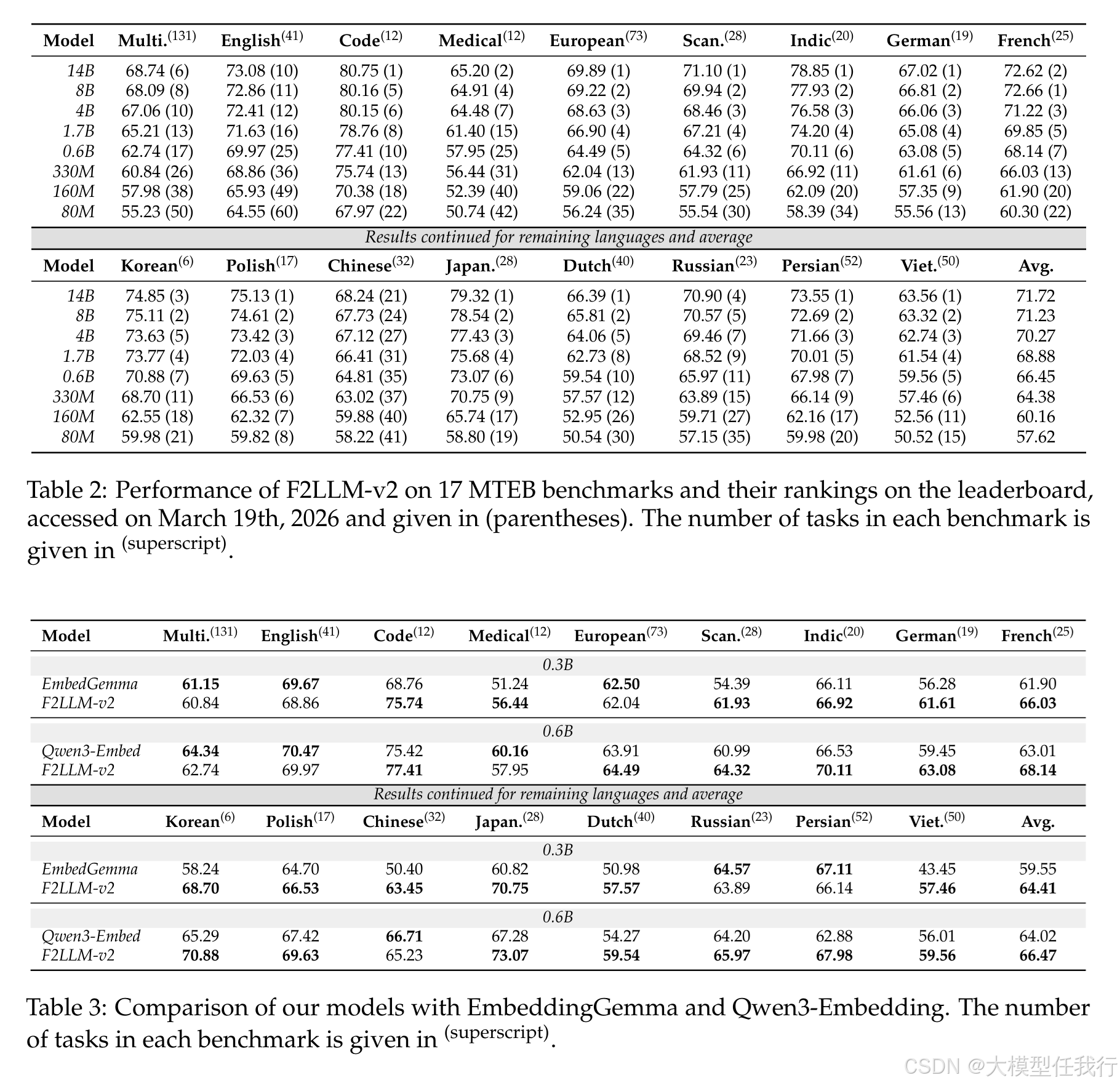
🔸F2LLM-v2-14B 模型在 17 个 MTEB 基准测试中的 11 个上取得了最先进成绩,特别是在代码、医疗及多个特定语言(如波兰语、日语)榜单上表现卓越。
🔸小规模模型(如 330M 和 0.6B)在多数语言特定基准和代码任务上超越了同量级的 Qwen3-Embedding 和 EmbeddingGemma 模型,证明了其在资源受限场景下的优越性。
🔸消融实验证实知识蒸馏显著提升了剪枝后小模型的性能,避免了因参数量减少导致的能力大幅下降。
🔸套娃表示学习验证有效,模型在低维嵌入空间(如 32 维)下仍能保留核心语义信息,使得小模型能以极低成本达到与大模型全维度相当的效果。
💡个人观点
论文通过精心构建的多语种长尾数据分布,让中低资源语言获得了高质量的语义表示能力。
🧩附录