目录
[1. 引言](#1. 引言)
[2. 模态鸿沟:一个被忽视的几何现象](#2. 模态鸿沟:一个被忽视的几何现象)
[2.1 什么是模态鸿沟?](#2.1 什么是模态鸿沟?)
[2.2 模态鸿沟的起源:锥效应与初始化](#2.2 模态鸿沟的起源:锥效应与初始化)
[2.3 关于模态鸿沟与下游性能的争议](#2.3 关于模态鸿沟与下游性能的争议)
[3. 模态鸿沟的新视角:信息不平衡假说](#3. 模态鸿沟的新视角:信息不平衡假说)
[3.1 从 "锥效应" 到 "信息不平衡"](#3.1 从 “锥效应” 到 “信息不平衡”)
[3.2 为何信息不平衡会导致模态鸿沟?](#3.2 为何信息不平衡会导致模态鸿沟?)
[4. 对象偏向:模态鸿沟的另一个侧面](#4. 对象偏向:模态鸿沟的另一个侧面)
[4.1 什么是对象偏向?](#4.1 什么是对象偏向?)
[4.2 对象偏向与信息不平衡](#4.2 对象偏向与信息不平衡)
[4.3 对象偏向与性能的关系](#4.3 对象偏向与性能的关系)
[5. 弥合模态鸿沟的努力](#5. 弥合模态鸿沟的努力)
[5.1 I0T:走向零模态鸿沟](#5.1 I0T:走向零模态鸿沟)
[5.2 AlignCLIP:通过参数共享缩小鸿沟](#5.2 AlignCLIP:通过参数共享缩小鸿沟)
[5.3 梯度流视角:不匹配数据对与温度参数](#5.3 梯度流视角:不匹配数据对与温度参数)
[5.4 DiffGAP:扩散模块弥合跨模态鸿沟](#5.4 DiffGAP:扩散模块弥合跨模态鸿沟)
[5.5 HiMo-CLIP:结构化语义对齐](#5.5 HiMo-CLIP:结构化语义对齐)
[6. 理论统一与开放挑战](#6. 理论统一与开放挑战)
[6.1 最新理论:维度塌缩是模态鸿沟的根源?](#6.1 最新理论:维度塌缩是模态鸿沟的根源?)
[6.2 双椭球几何:CLIP 的另一面](#6.2 双椭球几何:CLIP 的另一面)
[7. 总结与展望](#7. 总结与展望)
1. 引言
近年来,以 CLIP(Contrastive Language-Image Pre-training)为代表的对比视觉语言模型,凭借其在海量图文对上的对比学习预训练,展现出了强大的零样本迁移与跨模态理解能力,成为多模态领域的核心基石。然而,随着研究的不断深入,人们逐渐发现这些模型的表示空间中存在着一些系统性的几何结构与行为偏差,这些隐蔽的特性既可能限制模型的细粒度理解能力,也可能反过来为某些任务提供独特的灵活性。
两个尤为关键的现象引起了学界的广泛关注:模态鸿沟(Modality Gap) 与 对象偏向(Object Bias) 。前者指的是图像嵌入与文本嵌入在共享表示空间中彼此分离、分属两个不同区域的几何现象;后者则表现为模型对物体信息的敏感程度显著高于对属性等细粒度特征的敏感程度。长期以来,这两个现象往往被分开讨论,但最新的研究揭示,它们可能源于同一个根本原因------图文对之间的信息不平衡(Information Imbalance),即图像信息远丰富于对应的文本描述。
本文将围绕这两个核心现象,系统梳理从 2022 年至今的前沿研究工作,探讨它们的成因、几何本质、对下游性能的影响,以及当前主流的缓解策略。我们将看到,模态鸿沟并非简单的模型缺陷,而是对比学习目标、网络初始化与数据分布共同作用下的产物;而对它的深入理解,正推动着多模态表示学习从 "扁平化对齐" 向 "结构化语义理解" 稳步迈进。
2. 模态鸿沟:一个被忽视的几何现象
2.1 什么是模态鸿沟?
2022年,斯坦福大学的 Liang 等人在 NeurIPS 上发表的工作《Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning》首次系统性地揭示了一个令人意外的现象:在 CLIP 这类多模态模型中,图像嵌入和文本嵌入并非均匀分布在共享表示空间中,而是分别位于两个完全分离的区域。论文的作者将这个有趣的现象命名为模态鸿沟(Modality Gap)。
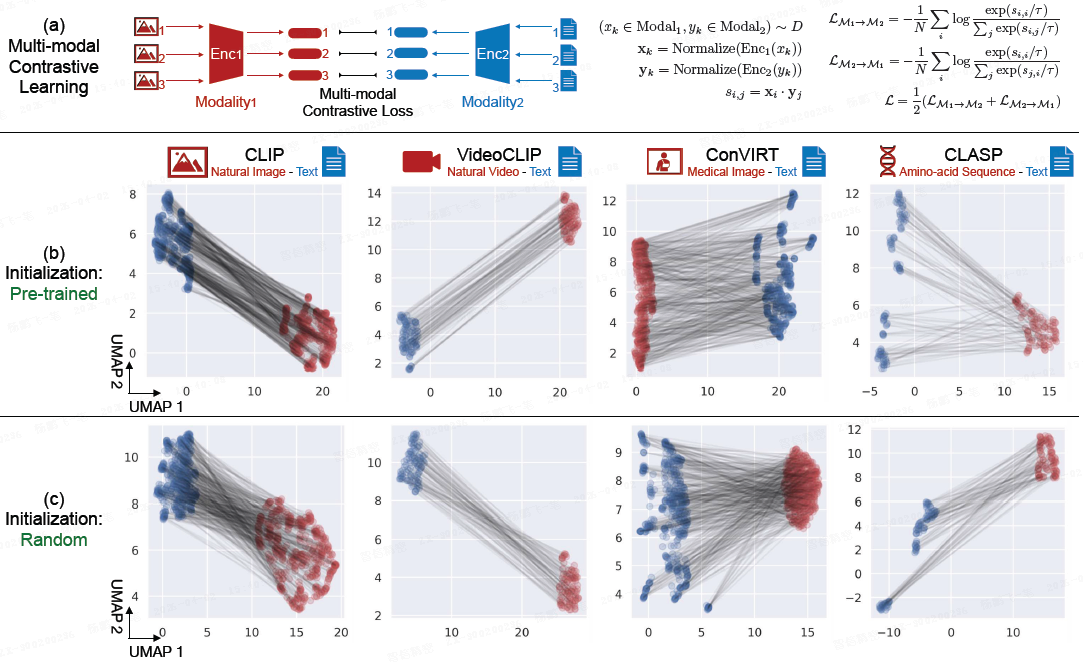
更值得关注的是,这一现象并非 CLIP 独有。Liang 等人的实验表明,无论输入数据是自然图像、医学影像、氨基酸序列还是视频,无论编码器架构是 ResNet 还是 Vision Transformer,模态鸿沟都普遍存在(如上图所示)。更有趣的是,即使使用随机初始化的模型(未经任何训练),这一现象依然可以观察到。
这种分离的直观体现是:图像嵌入和文本嵌入的中心在单位超球面上相距甚远。以 OpenAI 的 CLIP 模型为例,图像嵌入中心与文本嵌入中心的欧氏距离高达 0.82(在单位球面上,这意味着两者几乎处于 "对立" 的位置)。
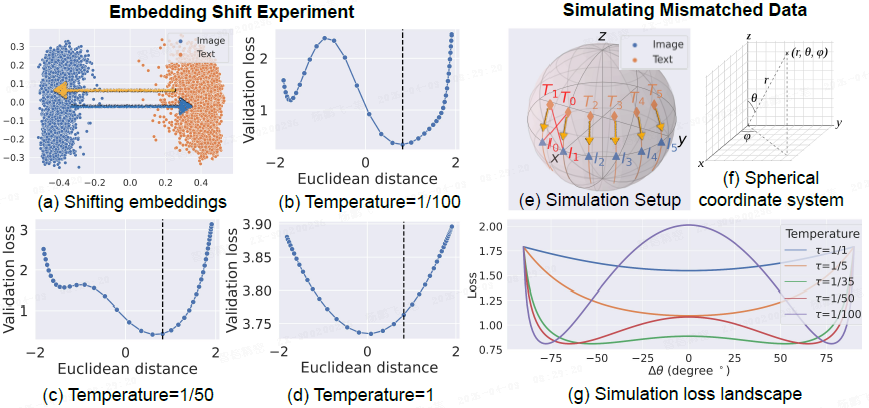
对比学习保留了模态差距。
(a) 嵌入(embedding)偏移实验。为了探究 CLIP 的损失景观(landscapes),通过手动偏移图像嵌入和文本嵌入,来缩小模态间的差距。
(b-d)不同温度参数下的损失景观。
- Y 轴表示对比损失,X 轴表示图像嵌入中心与文本嵌入中心之间的欧氏距离。垂直虚线 x = 0.82 表示 CLIP 原始状态下图像与文本嵌入之间的距离(即未进行任何偏移)。需要注意的是,在 CLIP 中,图像嵌入和文本嵌入都经过了 L2 归一化。换句话说,CLIP 的图像和文本嵌入始终位于单位球面上。
- 这些结果表明,在对比损失的损失函数中存在一种排斥结构,这种结构能保持模态间隔。然而,当温度升高时 (c,d),排斥结构和局部最小值逐渐消失,缩小间隔变得更易实现。这表明排斥结构和最优间隔是与温度相关的。
(e-g) 损失景观的模拟分析。在三维球面上模拟了六对图像-文本嵌入,其中两对为不匹配的样本对。文本嵌入通过向缩小模态差距的方向进行偏移(即修改参数 θ)。
2.2 模态鸿沟的起源:锥效应与初始化
模态鸿沟的形成并非单一因素导致,Liang等人从三个方面给出了系统性解释:
首先,锥效应(Cone Effect) 是关键诱因。
- 研究表明,由于深度神经网络的结构偏置(尤其是 ReLU 等非线性激活函数的存在),嵌入空间被限制在一个极窄的锥形区域内。
- 实验数据显示,在 ResNet 模型中,任意两个嵌入之间的平均余弦相似度高达 0.56,这意味着在 512 维的超球面上,有效嵌入空间仅占球面表面积的不到 1/512。
其次,模型初始化阶段的独立性导致初始分离。图像编码器和文本编码器采用独立随机初始化,各自形成的锥形区域方向截然不同,这直接导致两类嵌入在训练开始前就已产生明显分离。
第三,对比学习的目标函数会"固化"这种分离。Liang 等人的 "嵌入平移" 实验揭示了一个反直觉现象:当试图通过平移嵌入缩小模态鸿沟时,对比损失反而会增大------默认的鸿沟距离恰好处于损失函数的全局最小值,这意味着对比学习在优化过程中会主动维持模态分离。
2.3 关于模态鸿沟与下游性能的争议
模态鸿沟是否影响模型的下游性能?这一问题在过去几年中引发了激烈的讨论。
弗赖堡大学与博世 AI 中心的 Schrodi 等人在 ICLR 2025 发表的《Two Effects, One Trigger》中,对这一问题进行了系统的定量分析。他们评估了 98 个不同的对比视觉语言模型(涵盖 CLIP、SigLIP 等变体,预训练数据集从 CC12M 到 LAION-2B),并使用 Kendall 的 τ rank 相关系数分析了模态鸿沟与下游性能之间的关系。
【均值的 L2 距离(L2-distance between the Means,L2M):
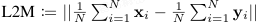
其中,x、y 分别表示 L2 归一化的图像或文本 embedding。
相对模态鸿沟(Relative Modality Gap,RMG):
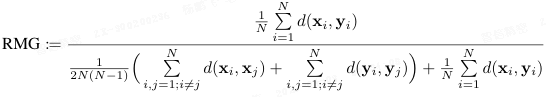
直观来看,
- 分子部分衡量的是关键位置上的差距,即对于图像与文本的匹配对而言;
- 而分母部分则通过使用模态内距离的近似值来反映实际使用的空间情况。
】
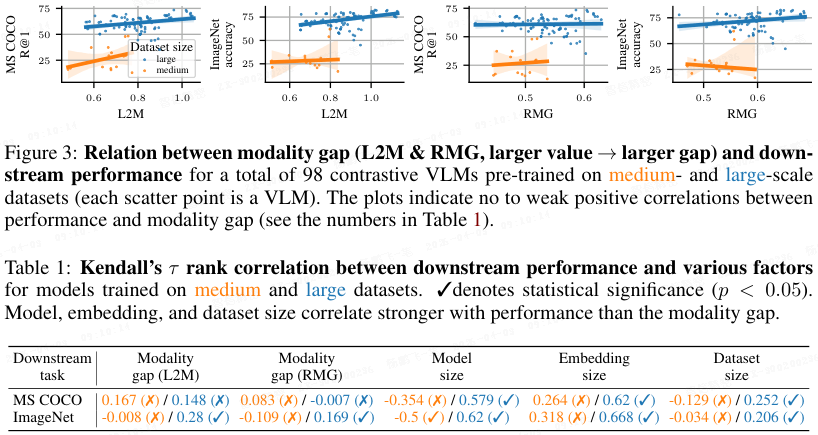
结果发现了一个值得关注的现象:从表面上看,更大的模态鸿沟反而与更好的下游性能存在微弱的正相关。例如,如 图 3 所示,在 MS COCO 图像-文本检索任务上,模态鸿沟(RMG)与性能的 τ rank 相关系数仅为 0.167,在 ImageNet 分类任务上更是低至 -0.008,几乎无相关性。
然而,这种表面上的正相关并不意味着 "更大的模态鸿沟更好"。Schrodi 等人进一步控制混淆因素后发现,模型规模和嵌入维度等变量对性能的影响,远大于模态鸿沟(表 1 )。当按预训练数据集进行分组分析后,他们观察到模态鸿沟与性能之间的负相关趋势------即模态鸿沟越小,性能往往越好(表 3)。
3. 模态鸿沟的新视角:信息不平衡假说
3.1 从 "锥效应" 到 "信息不平衡"
Liang 等人将模态鸿沟的成因归因于锥效应和对比损失的结构性约束,而 Schrodi 等人提出一个更根本性的新视角:模态鸿沟的核心驱动是图文对之间的 信息不平衡(Information Imbalance) 。
所谓信息不平衡,指的是图像与文本所承载的信息量显著不对等。一幅图像通常包含极其丰富的信息------物体、属性、背景、光照、空间关系等,而相应的文本描述往往是高度压缩的,通常只描述了图像中最显著的一个或两个物体以及少量属性。这种 "图像信息富余、文本信息稀疏" 的不对称,构成了对比学习中一个根本性的难题。
为验证这一假说,在 Schrodi 等人的合成数据集 MAD(Multi-modal Attributes and Digits)上,他们通过控制文本描述中包含的属性数量(从 1 个到全部 5 个属性),精确调节信息不平衡的程度,实验结果清晰印证了信息不平衡与模态鸿沟的关联(如下图所示)。
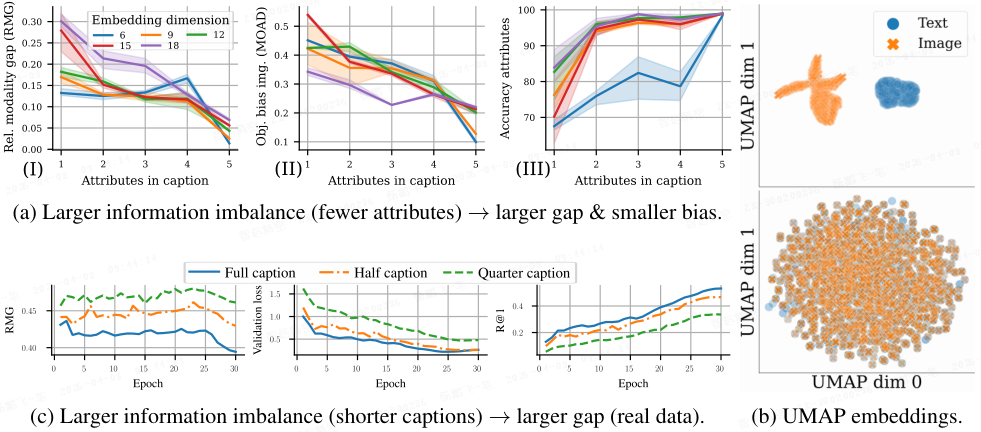
增加模态间的共享信息(即减小信息不平衡)能够提升表征质量。
- (a) 在合成数据 MAD 上,随着模态间共享信息的增加,(I)模态差距减小,(II)对物体的偏差降低,同时(III)下游任务准确率提升。
- (b) 当模态间信息完全共享(无信息不平衡)时,对比损失能够有效缩小模态差距,如模型初始化时(top)和训练完成后(bottom)的 UMAP 嵌入所示。
- (c) 为了在真实数据上验证,在 CC12M 数据集上训练了 CLIP 模型,并通过丢弃 ½ 或 ¾ 的描述文本制造信息不平衡。类似地,发现信息不平衡程度越高,模态差距越大,性能越差。
3.2 为何信息不平衡会导致模态鸿沟?
当图像包含的信息远超文本描述时,图像编码器面临一个 "不确定性问题"------它不知道文本描述中实际包含了哪些信息。为了最大化与匹配文本的相似度,图像编码器的 "最优策略" 是聚焦于那些最可能在文本中出现的特征(通常是物体),而对那些不太可能出现的特征(如属性)分配较小的表示权重。
与此同时,由于匹配对的相似度(alignment)受到信息不平衡的天花板限制,模型在优化过程中会将更多权重放在 "均匀性(uniformity)" 上------即让不匹配的图文对在超球面上尽可能远离。由于对比损失中的排斥力仅作用于跨模态之间,模型最直接的策略就是将两个模态的整体中心推得更远,从而形成模态鸿沟。
4. 对象偏向:模态鸿沟的另一个侧面
4.1 什么是对象偏向?
Bravo 等人(CVPR 2023)最早提出,CLIP 等对比视觉语言模型在属性识别任务上的表现显著差于物体识别任务,这暗示了模型可能存在 "对象偏向"(Object Bias)------即模型更倾向于关注图像中的物体信息,而忽视属性等细粒度特征。
在此基础上,Schrodi 等人提出了第一个正式的度量指标 MOAD(Matching Object Attribute Distance),来量化模型对物体(对象)相比于属性的偏向程度。
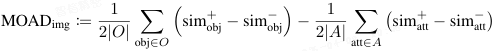
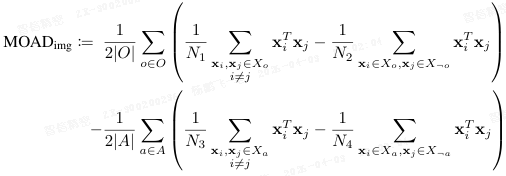
MOAD 的核心思想是:比较模型对 "相同物体" 的图像(或文本)之间的相似度,与 "相同属性" 的图像之间的相似度。如果前者显著大于后者,说明模型在表示中更重视物体信息,MOAD 为正(偏向物体);反之则为负(偏向属性)。
4.2 对象偏向与信息不平衡
Schrodi 等人的实验揭示了一个关键事实:对象偏向与模态鸿沟共享同一个根源------信息不平衡。
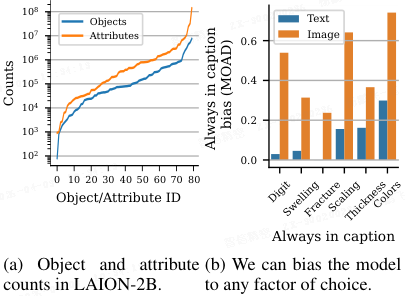
对象偏向是由每个样本中描述文本的存在性偏差导致的。
- (a) 对象偏见并非由词频引起,因为属性在文本中出现的频率实际上高于物体。
- (b) 在 MAD 数据集上训练了 CLIP 模型,并改变了描述文本中始终出现的因子(即描述文本的存在性偏差)。模型会偏向于在描述文本中普遍出现的那个因子(例如颜色、粗细等)。
在 MAD 合成数据集上,Schrodi 等人通过操纵文本中包含的属性数量,观察到一个清晰的模式:当文本只包含少量信息时,模型表现出强烈的对象偏向;随着文本中包含的属性数量增加,对象偏向逐渐减弱。
有趣的是,他们发现对象偏向在图像编码器中比在文本编码器中更为明显。这符合直观预期:文本编码器知道文本中包含了哪些信息,可以精确编码;而图像编码器必须 "猜测" 文本中会包含哪些内容,因此倾向于对所有样本都强调那些最常出现的特征(即物体)。
4.3 对象偏向与性能的关系
一个自然的假设是:对象偏向会损害属性识别任务的性能。然而,Schrodi 等人的数据分析显示,事实并非如此简单。
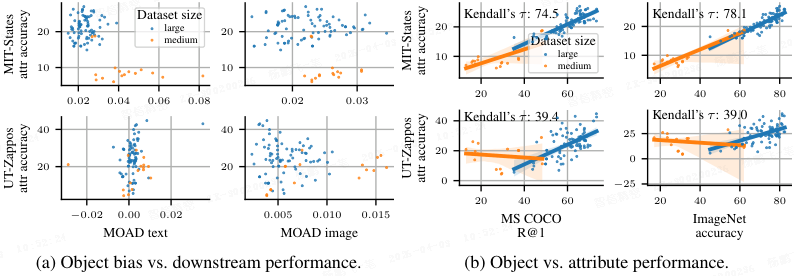
上图 a 显示,大多数对比视觉语言模型(VLM)都如预期般表现出对物体的偏见(MOAD>0)。值得注意的是,与在中等规模数据上训练的模型相比,在大规模数据上训练的模型对物体的偏见较小(正值更小)。然而,并未发现物体偏见与模型表现之间存在明确相关性,尤其是在大规模数据上训练的模型中。
因此,减少物体偏见似乎并不会直接影响属性表现------那么什么才会影响属性表现呢?上图 b 显示,物体任务与属性任务的表现之间存在中到强的相关性。由此可得出一个可能的解释:模型在物体任务上的整体能力提升,会自然地外溢到属性任务上。换言之,提升 CLIP 的根本表示能力,可能比专门针对 "减少对象偏向" 的策略,更能有效改善属性识别性能。
5. 弥合模态鸿沟的努力
5.1 I0T:走向零模态鸿沟
在 ACL 2025 上,An 等人发表了获得杰出论文奖的工作《I0T: Embedding Standardization Method Towards Zero Modality Gap》。他们提出了 I0T 框架,通过将归一化的 embedding 标准化(standardization),在完全不修改模型参数的情况下,将模态鸿沟几乎降低到零。
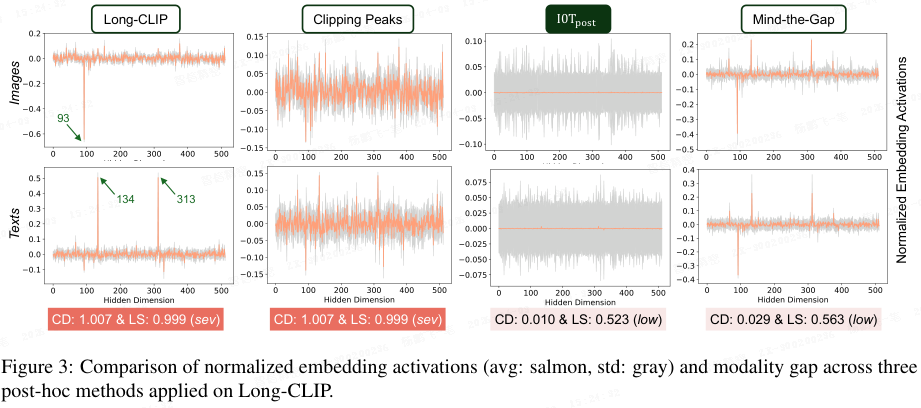
I0T 提供了两种方案:
- I0T_post 是一种后处理方法:

- I0T_async 则在训练过程中为每个编码器添加标准化层,在缓解模态鸿沟问题的同时,保留原始模型的表示能力。
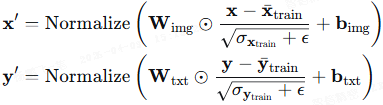
5.2 AlignCLIP:通过参数共享缩小鸿沟
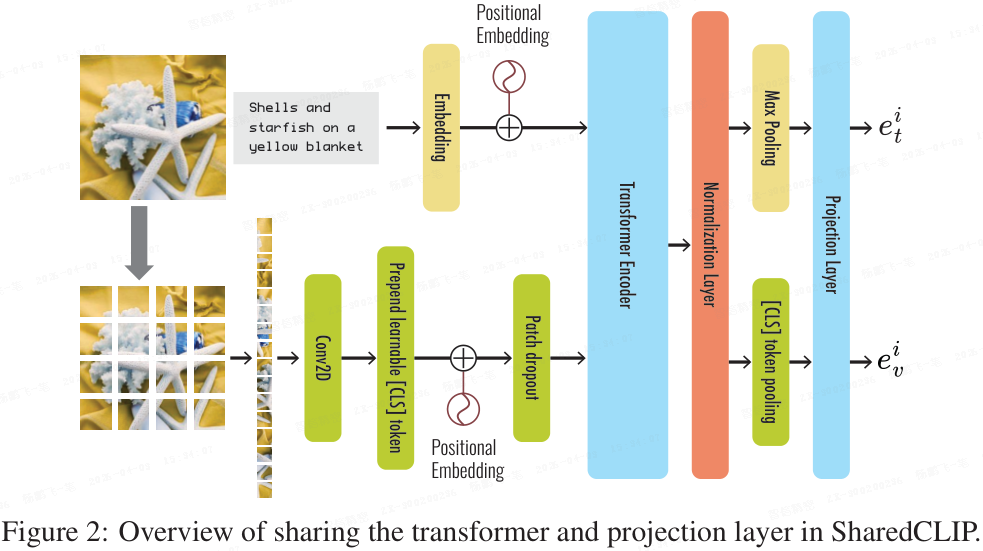
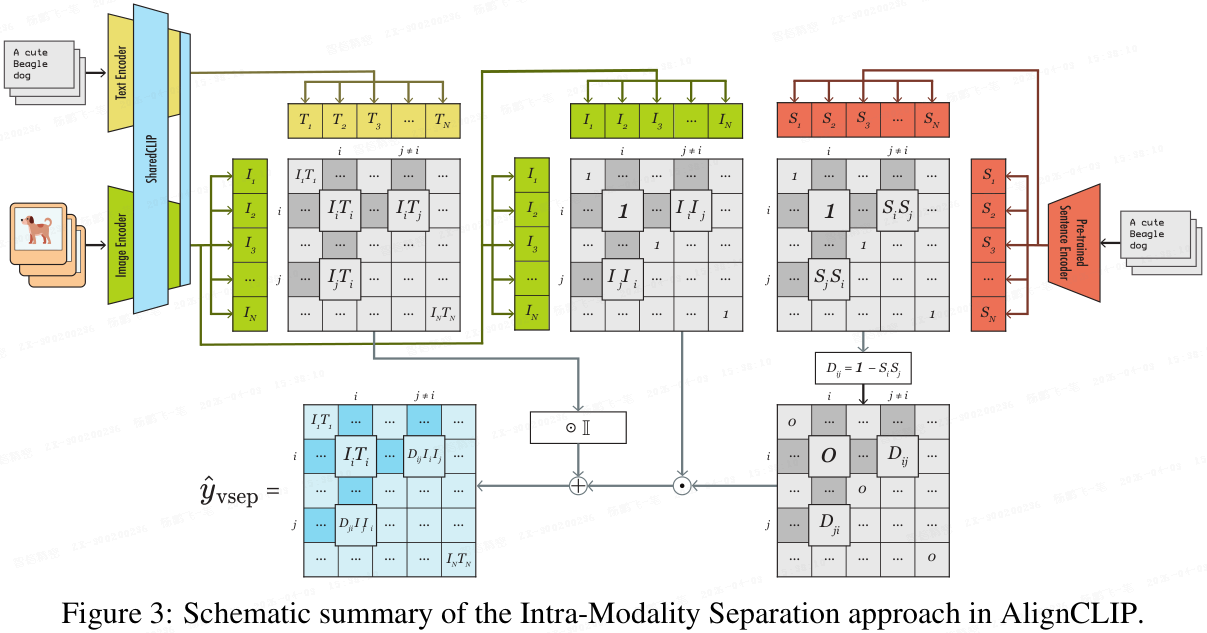
Eslami 和 de Melo 在 ICLR 2025 发表的 AlignCLIP 工作,采用与 I0T 截然不同的思路缩小模态鸿沟。该方法通过在模态编码器之间共享可学习参数,并在单模态嵌入上增加语义正则化的分离目标函数,从而改善图文对齐效果,提升跨模态表示质量。
实验结果表明,AlignCLIP 在多个零样本和微调评估任务中均取得了性能提升,验证了参数共享与语义正则化策略的有效性。
5.3 梯度流视角:不匹配数据对与温度参数
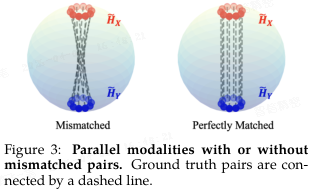
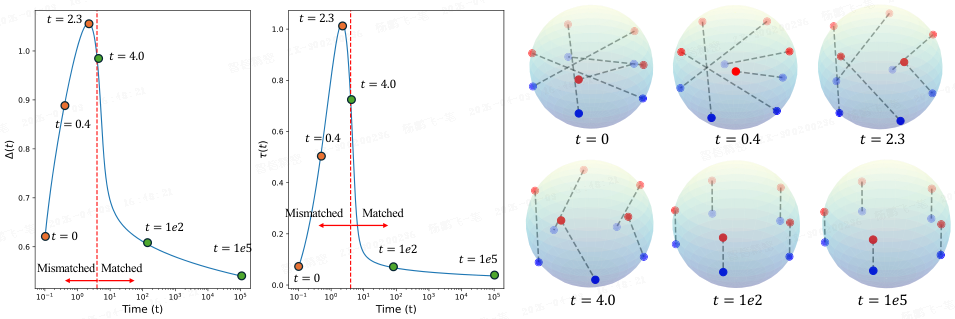
在使用合成数据训练过程中,模态间隙 Δ 与温度系数 τ 的变化动态。
- 来自两种模态的特征分别以红色和蓝色表示,真实配对由连线连接。在 t = 4.0 时,所有配对均成功匹配。
- 初始阶段,由于配对之间存在显著的不匹配,模态间隙增加;但随着不匹配程度的减小,模态间隙逐渐下降。
- 值得注意的是,在整个学习过程中,模态间隙与温度系数呈现出高度耦合的动态特性。
Yaras 等人在 PMLR 2025 发表的《Explaining and Mitigating the Modality Gap in Contrastive Multimodal Learning》中,从梯度流学习动力学的角度,对模态鸿沟进行了深入分析。他们识别了两个关键因素:
-
不匹配的数据对:当数据中存在错误标注或不完美对齐的图文对时,模型会倾向于扩大模态间的分离。
-
可学习的温度参数:温度参数与模态鸿沟存在复杂的相互作用,适当地调度温度参数可以有效缓解模态鸿沟。
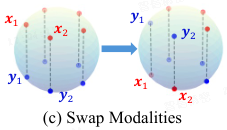
该研究还提出了 "模态交换" 等策略作为缓解模态鸿沟的指导原则,并实证验证了缩小模态鸿沟能够改善图文检索等任务的性能。
-
模态间的硬交换(HS):在训练过程中,随机选择一些图像及其配对的文本描述。然后,在共享特征空间中交换这些图像和配对文本的特征,如上图所示。
-
模态间的软交换(SS):与硬交换不同,对于一对图像和文本特征,软交换将两个特征混合,生成一对新的图像和文本特征。
5.4 DiffGAP:扩散模块弥合跨模态鸿沟
Mo 等人(DiffGAP,ICASSP 2025)发现,单一对比损失显著提升了文本、视频和音频嵌入的对齐效果,但这些方法忽略了双向交互和各模态内的固有噪声,限制了跨模态融合的质量。
因此,他们引入了一个轻量级的生成模块,通过双向扩散过程来弥合跨模态鸿沟。具体操作为,先以视频特征为条件对音频进行去噪,m 步后以音频特征为条件对视频进行去噪,之后每 m 步交替模态条件。
该工作扩展到了文本-音频-视频等多个模态的对齐场景,在 VGGSound 和 AudioCaps 数据集上展现了有效性。
5.5 HiMo-CLIP:结构化语义对齐
在工业界前沿,中国联通数据科学与人工智能研究院提出了 HiMo-CLIP 框架,入选 AAAI 2026 Oral。
他们认为,现有的 CLIP 等图文对齐方法,将文本视为扁平序列,难以处理复杂、组合式和长文本描述。具体而言,它们无法捕捉语言的两个本质属性:
- 语义层次性:反映文本的多层(对象类别→属性→上下文细节)组合结构
- 语义单调性:更丰富的描述应与视觉内容产生更强的对齐
该框架通过两个核心组件,让模型具备了 "分层理解" 和 "越详细越匹配" 的能力。这一突破不仅提升了长文本检索性能,更标志着多模态学习从 "扁平化" 向 "结构化" 的重要转变。
1)层次化分解(Hierarchical Decomposition,HiDe):通过 batch 内 PCA,从长文本中提取潜在语义组件,实现不同语义粒度下的灵活、batch 感知对齐。
对 batch 内文本嵌入矩阵 U ∈ R^{N×d} 进行均值中心化后 PCA:
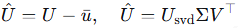
取前 m 个主方向 P ∈ R^{m×d}(由解释方差阈值 τ 确定),投影得:
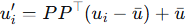
**解析:**PCA 提取方差最大的方向,对应文本中的高层语义(如类别),而低层细节(如句法)方差较小被滤除。
2)单调性感知对比损失(Monotonicity-Aware Contrastive Loss,MoLo):联合对齐全局和组件级表征,鼓励模型内化语义排序和对齐强度。
全局损失(保持 CLIP 的全局对齐):
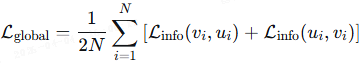
组件级损失(对齐图像嵌入 v_i 与语义组件 u′_i):
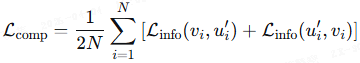
最终 MoLo 损失:
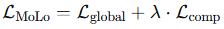
单调性原理:设 u^(1) = u′(高层语义),u^(K) = u(完整语义),中间表示为
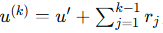
其中,r_j 为语义增量且 ⟨v, r_j⟩ > 0。则:
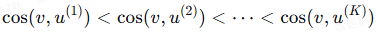
即语义完整度越高,对齐强度越强。
6. 理论统一与开放挑战
6.1 最新理论:维度塌缩是模态鸿沟的根源?
Yi 等人在 arXiv 2025 发表的《Decipher the Modality Gap in Multimodal Contrastive Learning》中,提出了第一个系统性理论框架,用于分析模态对比学习的收敛最优表示,试图从理论层面揭示模态鸿沟的本质。
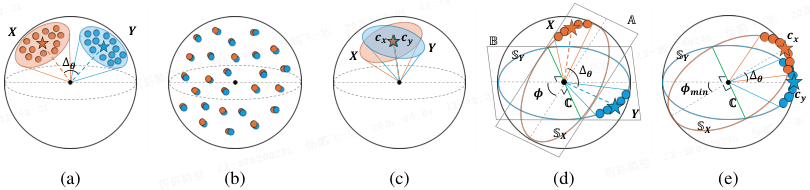
**多模态对比学习 的收敛最优表示:**橙色点和蓝色点分别代表 X 和 Y。五角星表示 X 和 Y 的中心(即 c_x,c_y)。Δθ 表示模态间隙的大小。
-
(a) 模型初始化时:(X,Y) 位于两个不同的锥体内。
-
(b) 无任何约束时:(X,Y) 收敛到配对的均匀分布,且 Δθ→0。
-
(c) 受锥体约束时:即使受锥体约束,模态间隙也会收敛到 0(Δθ→0)。
-
(d) 子空间约束下:(X,Y) 分别坍缩到两个不同的超平面 A 和 B 上。绿线表示共享空间 C=A∩B
-
(e) 子空间约束下,训练优化后:c_x,c_y⊥C,且 Δθ→ϕ_min。
该工作证明了一个关键结论:维度塌缩(Dimension Collapse)是模态鸿沟的根本起源 。具体而言,在无约束或锥约束(锥效应)条件下,模态鸿沟可以收敛到零;但在子空间约束条件下(即两种模态的表示因维度塌缩而落入两个不同的超平面),模态鸿沟将收敛到两个超平面之间的最小夹角。这一理论统一了此前关于模态鸿沟的各种经验观察,也为设计缓解策略提供了明确的理论指引。
他们表明,在子空间约束下,成对样本无法完美对齐。模态差距通过影响样本对之间的对齐来影响下游性能。
该工作证明,在这种情况下,可以通过两种方式实现两个模态之间的完美对齐:超平面旋转 和 共享空间投影。
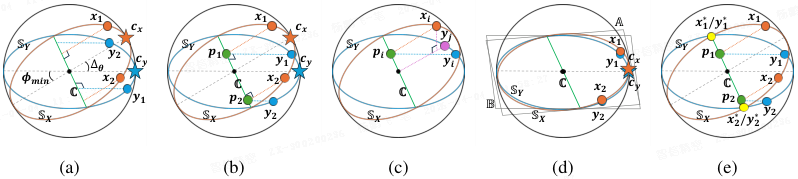
模态对齐:
-
(a):**满足条件:**即两个模态的中心向量都垂直于共享子空间(c_x, c_y⊥C)且模态内等距(x_i⋅c_x = y_i⋅c_y)
-
(b):当训练优化时,对于非中心的样本对 (x_i,y_i)_{i≠c},它们在共享子空间 C 上的投影会收敛到同一个点 p_i。这意味着,虽然原始样本在不同模态中,但它们包含的 "共享信息" 在训练后变得一致。
-
(c):在子空间约束下,成对样本 (x_i, y_i)_{i≠c} 无法完美对齐。
-
(d):**超平面旋转:**将 X 所在的超平面 A 向 B 旋转,X 和 Y 可以实现完美对齐。
-
(e):共享空间投影:将 (x_i, y_i) 投影到 C 上并重新归一化,得到 (x*_i, y*_i)(黄色点),实现完美对齐。
6.2 双椭球几何:CLIP 的另一面
Levi 和 Gilboa 在 ICML 2025 发表的《The Double-Ellipsoid Geometry of CLIP》中,从几何角度给出了对模态鸿沟的新理解,打破了此前对模态鸿沟 "纯粹负面" 的认知。
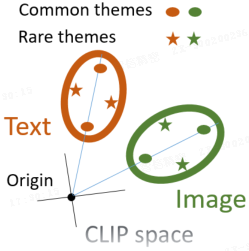
他们发现,文本和图像的嵌入位于线性可分的椭球壳上,且不经过原点(origin)。当一个主题(theme)在训练数据集中变得越来越罕见(不确定性降低)时,它们就会远离平均模态向量。
这种结构具有功能性优势------能够根据实例在对比训练过程中的 "不确定性" 来更好地嵌入实例。
【从信息论的角度而言:事件发生的概率 p 越低,其不确定性越高,对应的信息熵 −log p 也就越大。
如前文所述,
- 当简洁的文本描述匹配内容复杂的图像时,多模态信息不平衡,文本承载的信息量偏低,对图像的描述确定性不足(不确定性偏高),因此文本与图像的模态差距较大
- 而逐步扩充文本长度,使其包含更丰富的信息后,模态间的信息趋于平衡,模态差距也随之缩小。】
他们提出了 "一致性(Conformity)" 概念:定义为集合中一个向量与集合中其他向量的余弦相似度的期望值)
他们还证明,CLIP 的模态鸿沟实际上优化了图像与文本之间一致性分布的匹配:为文本和图像设置分离的嵌入,可以分别控制每个实例在每种模态下的不确定性,从而使两种模态具有一致性分布。
【这里我的理解是,既然无法完全消除模态差距,那么就利用好它。利用 "文本和图像分离的嵌入",通过 "分别控制每个实例在每种模态下的不确定性,从而使两种模态具有一致性分布",从而减小模态差距。这与(5.3 梯度流视角:不匹配数据对与温度参数)的论证一致。】
7. 总结与展望
模态鸿沟的揭示是多模态对比学习领域近年的重要突破。从 2022 年 Liang 等人的开创性工作,到 2025-2026 年涌现的多篇理论与实证研究,我们对这一现象的理解经历了从 "观察" 到 "解释" 再到 "解决" 的演进:
-
锥效应与初始化:深度神经网络的偏置导致嵌入空间被限制在狭窄的锥形区域,两个编码器的随机初始化造成模态分离的起点(Liang et al., NeurIPS 2022)。
-
信息不平衡:图像与文本之间的信息不对等是模态鸿沟和对象偏向的共同根源(Schrodi et al., ICLR 2025)。
-
维度塌缩:维度塌缩是模态鸿沟的根本起源,为理论统一提供了基础(Yi et al., arXiv 2025)。
-
缓解策略:I0T(ACL 2025 Outstanding Paper)、AlignCLIP(ICLR 2025)、GR-CLIP、HiMo-CLIP(AAAI 2026 Oral)等多种方法从后处理、训练优化、数据增强等不同角度探索了弥合模态鸿沟的可能路径。
当前的研究共识是:模态鸿沟既非纯粹的 "Bug" 也非纯粹的 "Feature"------它在某些场景下为模型提供了调控熵值(不确定度)的灵活性,但在另一些场景下却制约了模型的属性理解和细粒度对齐能力。未来的研究需要在以下方向继续突破:
-
理论深化:进一步完善多模态对比学习的收敛理论,明确维度塌缩、锥效应、信息不平衡三者之间的内在关联,建立更具普适性的理论框架。
-
数据优化:设计更高质量、更低信息不平衡的多模态数据集,从根本上缓解模态鸿沟。
-
训练策略:开发能够动态调节模态鸿沟的自适应训练方法,兼顾性能提升与计算成本,在不同任务之间取得最佳平衡。
-
多模态扩展:将模态鸿沟的研究从图像-文本拓展到更广泛的多模态场景(视频、音频、医学影像等)。
模态鸿沟的发现与探讨,不仅深化了我们对 CLIP 等模型内部工作机制的理解,也为未来多模态表示学习的发展提供了重要的理论指引和实践工具。正如该领域的一句名言所言:"要弥合鸿沟,首先得承认它的存在。"(To bridge the gap, one must first acknowledge it.)
参考文献
-
Liang, W., Zhang, Y., Kwon, Y., Yeung, S., & Zou, J. (2022). Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning. NeurIPS 2022.
-
Schrodi, S., Hoffmann, D. T., Argus, M., Fischer, V., & Brox, T. (2025). Two Effects, One Trigger: On the Modality Gap, Object Bias, and Information Imbalance in Contrastive Vision-Language Models. ICLR 2025.
-
An, N. M., Kim, E., Thorne, J., & Shim, H. (2025). I0T: Embedding Standardization Method Towards Zero Modality Gap. ACL 2025 (Outstanding Paper Award).
-
Eslami, S., & de Melo, G. (2025). Mitigate the Gap: Improving Cross-Modal Alignment in CLIP. ICLR 2025.
-
Yaras, C., Chen, S., Wang, P., & Qu, Q. (2025). Explaining and Mitigating the Modality Gap in Contrastive Multimodal Learning. *PMLR 280:1365-1387*.
-
Levi, M. Y., & Gilboa, G. (2025). The Double-Ellipsoid Geometry of CLIP. ICML 2025.
-
Yi, L., et al. (2025). Decipher the Modality Gap in Multimodal Contrastive Learning: From Convergent Representations to Pairwise Alignment. arXiv:2510.03268.
-
Mo, S., Chen, Z., Bao, F., & Zhu, J. (2025, April). Diffgap: A lightweight diffusion module in contrastive space for bridging cross-model gap. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 1-5). IEEE.
-
Bravo, M. A., Mittal, S., Ging, S., & Brox, T. (2023). Open-vocabulary Attribute Detection. CVPR 2023.
-
Wu, R., Chen, P., Shen, F., Zhao, S., Hui, Q., Gao, H., ... & Lian, S. (2026, March). HiMo-CLIP: Modeling Semantic Hierarchy and Monotonicity in Vision-Language Alignment. AAAI 2026