scikit-learn 决策树分类详解:从原理、可视化到剪枝实战掌握 DecisionTreeClassifier
决策树(Decision Tree)是机器学习中最经典的一类分类模型。它的优势非常直接:规则清晰、可解释性强、上手门槛低;与此同时,它也有一个非常典型的问题,那就是容易过拟合。
这也是学习 DecisionTreeClassifier 的意义所在。学习决策树,不只是学会调用一个分类器,更是在理解监督学习中的几个核心问题:模型如何利用特征逐步完成分类,什么是节点纯度,为什么它决定了划分效果,以及为什么树越深,训练集表现通常越好,但泛化能力未必越强。进一步说,决策树还是理解参数控制、模型复杂度和剪枝思想的理想入口。
本文将结合 scikit-learn 中的 DecisionTreeClassifier,从原理、可视化到工程实践,系统梳理决策树分类的核心知识。
1. 决策树的核心思想
决策树本质上是在不断做划分。它会在当前节点上选择一个最合适的特征和阈值,把样本切分到更"纯"的子区域中,直到叶节点能够给出最终的分类结果。
从结构上看,一棵决策树由根节点、内部节点、分支和叶节点构成。根节点是整棵树的起点,内部节点负责根据某个特征做条件判断,分支表示不同条件下的流向,而叶节点则给出最终的类别输出。
以鸢尾花分类任务为例,模型可能先判断花瓣长度是否小于某个阈值,再根据花瓣宽度继续做区分,最终将样本归入某一类别。这样的判断过程非常接近人类日常的决策逻辑,也正因为如此,决策树天然具有较强的可解释性。与很多"黑盒模型"不同,决策树的判断路径可以被直接看到,模型是如何一步步得出结论的,也能够清楚地展示出来。
2. 可视化环境配置
为了保证全文中的图表既能正常显示中文,又具有统一、清爽的视觉风格,先完成环境配置:
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.colors import ListedColormap
from sklearn.datasets import load_iris, load_wine
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.tree import DecisionTreeClassifier, plot_tree, export_text
from sklearn.metrics import (
accuracy_score,
classification_report,
confusion_matrix,
ConfusionMatrixDisplay
)
sns.set_theme(
style="whitegrid",
context="notebook",
font="SimHei",
rc={
"axes.unicode_minus": False,
"axes.titlesize": 15,
"axes.labelsize": 12,
"legend.fontsize": 10
}
)
plt.rcParams["figure.figsize"] = (8, 5)
plt.rcParams["axes.spines.top"] = False
plt.rcParams["axes.spines.right"] = False这组配置的作用主要有三点。第一,它解决了中文显示和负号乱码的问题;第二,它统一了整篇文章中图表的字体、标题和标签大小;第三,它去掉了多余的边框,让图形在博客页面中看起来更干净。
3. 数据准备与分布观察
本文使用经典的鸢尾花数据集(Iris)来演示决策树分类。这个数据集包含 150 个样本、4 个特征和 3 个类别,是分类任务入门中最常见的数据集之一。
python
iris = load_iris()
X = iris.data
y = iris.target
df = pd.DataFrame(X, columns=iris.feature_names)
df["类别"] = [iris.target_names[i] for i in y]
df.head()| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | 类别 | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
在正式建模之前,先观察数据的基本分布是一个很好的习惯。首先看类别分布:
python
plt.figure(figsize=(8, 5))
ax = sns.countplot(
data=df,
x="类别",
palette="Set2",
edgecolor="black",
linewidth=1.0
)
for p in ax.patches:
ax.annotate(
f"{int(p.get_height())}",
(p.get_x() + p.get_width() / 2, p.get_height()),
ha="center",
va="bottom",
fontsize=11,
xytext=(0, 4),
textcoords="offset points"
)
plt.title("鸢尾花数据集类别分布", pad=12, weight="bold")
plt.xlabel("类别")
plt.ylabel("样本数量")
plt.tight_layout()
plt.show()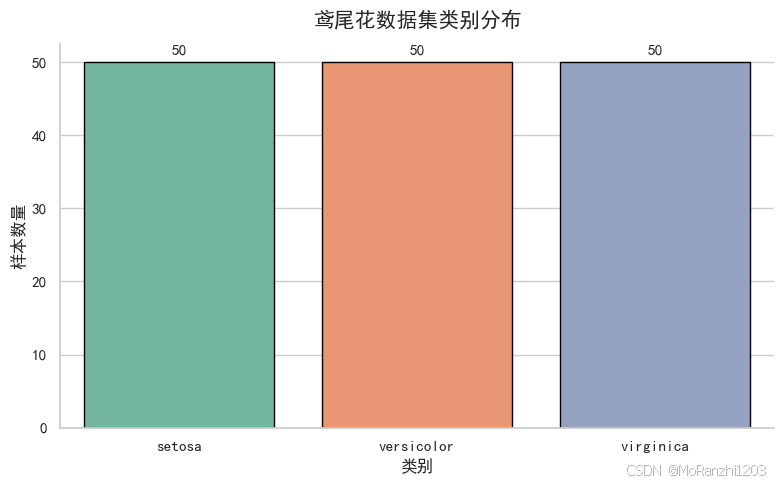
从结果可以看出,三个类别的样本数比较均衡,没有明显的类别不平衡问题。这一点很重要,因为如果某一类样本明显更少,模型评估时就需要额外关注类别偏置问题。
接着再看两个关键特征的二维分布情况:
python
plt.figure(figsize=(10, 6))
sns.scatterplot(
data=df,
x="petal length (cm)",
y="petal width (cm)",
hue="类别",
palette="Set2",
s=90,
edgecolor="white",
linewidth=0.8,
alpha=0.9
)
plt.title("不同类别在花瓣长度与花瓣宽度上的分布", pad=12, weight="bold")
plt.xlabel("花瓣长度 (cm)")
plt.ylabel("花瓣宽度 (cm)")
plt.legend(title="类别", frameon=True)
plt.tight_layout()
plt.show()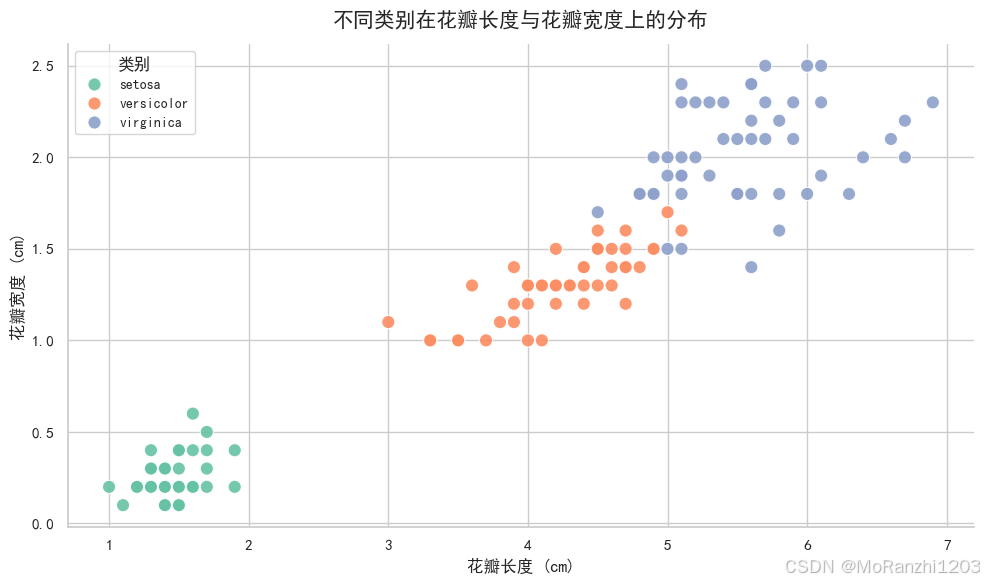
从散点图中可以直观看到,不同类别在花瓣长度和花瓣宽度上的分布差异较为明显。这说明这两个特征本身就具有较强的区分能力,也为后续的树模型划分提供了良好的基础。决策树并不是凭空"猜"出类别,而是在现有特征差异的基础上逐步找到有效的划分规则。
4. 决策树如何选择最优划分
决策树训练的关键问题是:当前节点应该按哪个特征划分,才能让划分后的子节点更纯?
为了回答这个问题,需要引入"节点纯度"这一概念。所谓节点纯度,指的是一个节点中的样本是否尽可能来自同一类别。如果一个节点里的样本高度混杂,那么这个节点的区分能力就比较弱;反过来,如果一个节点里大部分样本都属于同一类,那么这个节点就更有利于做出明确判断。
在决策树中,常见的划分质量衡量指标有熵、信息增益和基尼指数。
4.1 熵
熵用于衡量节点中样本类别分布的混乱程度,其定义为:
H(D)=−∑k=1Kpklog2pk H(D)=-\sum_{k=1}^{K} p_k \log_2 p_k H(D)=−k=1∑Kpklog2pk
其中,pkp_kpk 表示第 kkk 类样本所占比例。
从直觉上理解,如果一个节点中的样本全部属于同一类,那么它的熵为 0;如果不同类别分布得越均匀,熵就越大,说明这个节点越混乱。
4.2 信息增益
信息增益表示某个特征完成一次划分之后,让当前节点的不确定性减少了多少。它的定义为:
Gain(D,A)=H(D)−∑v=1V∣Dv∣∣D∣H(Dv) Gain(D, A)=H(D)-\sum_{v=1}^{V}\frac{|D_v|}{|D|}H(D_v) Gain(D,A)=H(D)−v=1∑V∣D∣∣Dv∣H(Dv)
信息增益越大,说明这个特征越适合用于当前节点的划分。
4.3 基尼指数
在 scikit-learn 中,DecisionTreeClassifier 默认使用的是基尼指数,其定义为:
Gini(D)=1−∑k=1Kpk2 Gini(D)=1-\sum_{k=1}^{K} p_k^2 Gini(D)=1−k=1∑Kpk2
基尼指数越小,表示节点越纯。虽然基尼指数和熵的表达形式不同,但它们本质上都在衡量一个节点的类别混杂程度。
4.4 熵、基尼指数与信息增益的变化趋势
严格来说,信息增益并不像熵和基尼指数那样,只由一个节点内部的类别概率直接决定,它依赖于划分前后的整体变化。为了帮助读者建立更直观的认识,这里在二分类场景下给出一个演示版本:假设父节点熵固定为 1,再观察子节点纯度变化时的信息减少量。
python
p = np.linspace(0.001, 0.999, 500)
entropy = -(p * np.log2(p) + (1 - p) * np.log2(1 - p))
gini = 2 * p * (1 - p)
# 演示信息增益趋势:假设父节点熵固定为 1
parent_entropy = 1.0
info_gain_demo = parent_entropy - entropy
plt.figure(figsize=(8.5, 5.2))
plt.plot(p, entropy, label="熵(Entropy)", linewidth=2.5)
plt.plot(p, gini, label="基尼指数(Gini)", linewidth=2.5)
plt.plot(p, info_gain_demo, label="信息增益(示意)", linewidth=2.5, linestyle="--")
plt.title("二分类下熵、基尼指数与信息增益变化趋势", pad=12, weight="bold")
plt.xlabel("某一类别的概率 p")
plt.ylabel("指标值")
plt.grid(alpha=0.25, linestyle="--")
plt.legend(frameon=True)
plt.tight_layout()
plt.show()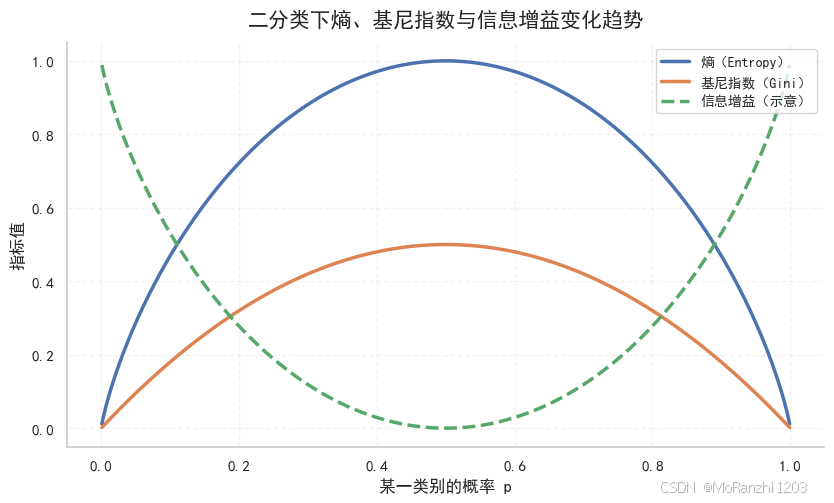
从图中可以看出,当类别概率接近 0.5 时,节点最混乱,熵和基尼指数都较大;当类别概率接近 0 或 1 时,节点会变得更纯,相应的熵和基尼指数都会下降。在这个演示设定下,节点越纯,信息增益越大。
这里最重要的不是机械记忆公式,而是理解背后的核心逻辑:决策树每做一次划分,目标都是让子节点更纯,让后续分类更容易。
5. DecisionTreeClassifier 的基础使用
下面先看一个标准的分类流程:
python
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
clf = DecisionTreeClassifier(
criterion="gini",
max_depth=3,
random_state=42
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("准确率:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
txt
准确率: 0.9666666666666667
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 0.90 0.95 10
2 0.91 1.00 0.95 10
accuracy 0.97 30
macro avg 0.97 0.97 0.97 30
weighted avg 0.97 0.97 0.97 30这段代码完成了一个标准的监督学习流程:先划分训练集和测试集,再创建决策树分类器并在训练集上完成拟合,最后在测试集上进行预测并输出评估结果。这里设置 max_depth=3 的目的,是避免模型无限制地增长,从而降低过拟合风险。
为了更直观地观察分类结果,可以进一步绘制混淆矩阵。
python
fig, ax = plt.subplots(figsize=(6, 5), dpi=150)
disp = ConfusionMatrixDisplay.from_estimator(
clf,
X_test,
y_test,
display_labels=iris.target_names,
cmap="Blues",
ax=ax,
colorbar=False
)
# 先关闭主网格
ax.grid(False)
# 只在边界位置设置 minor ticks
n = len(iris.target_names)
ax.set_xticks(np.arange(-0.5, n, 1), minor=True)
ax.set_yticks(np.arange(-0.5, n, 1), minor=True)
# 只绘制 minor 网格线
ax.grid(which="minor", color="white", linestyle='-', linewidth=2)
ax.tick_params(which="minor", bottom=False, left=False)
# 边框
for spine in ax.spines.values():
spine.set_visible(True)
spine.set_color("black")
spine.set_linewidth(1.2)
ax.set_title("决策树分类混淆矩阵", pad=12, weight="bold")
plt.tight_layout()
plt.show()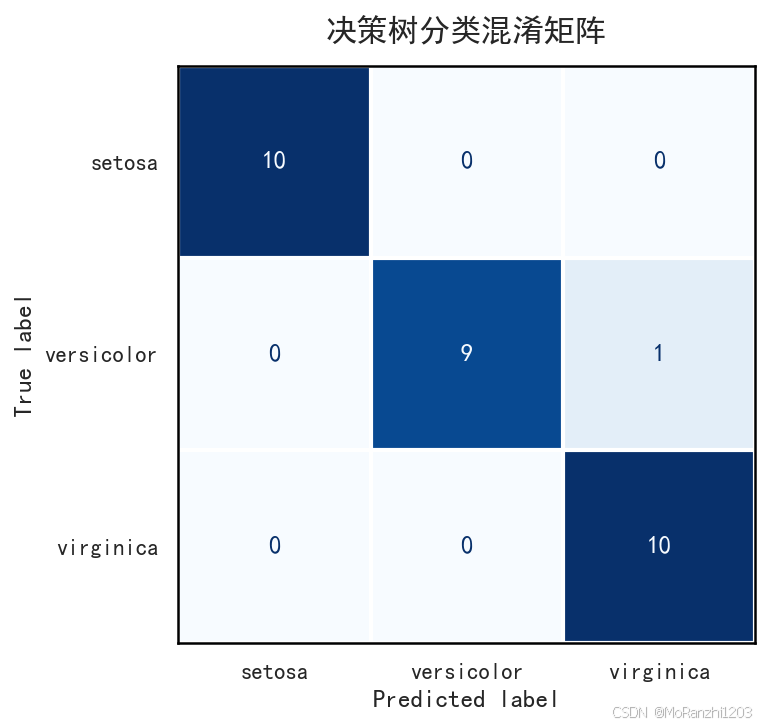
混淆矩阵的价值在于,它比单一准确率更有解释力。准确率只能告诉我们模型总体上"对了多少",而混淆矩阵可以进一步展示哪些类别分类得较好,哪些类别之间更容易混淆。
6. 决策边界与树结构可视化
决策树特别适合通过可视化来理解,因为它既能展示"特征空间如何被切分",也能展示"规则是如何一步步形成的"。
6.1 决策边界可视化
下面使用花瓣长度和花瓣宽度两个特征绘制决策边界:
python
X_vis = iris.data[:, [2, 3]]
y_vis = iris.target
clf_vis = DecisionTreeClassifier(max_depth=3, random_state=42)
clf_vis.fit(X_vis, y_vis)
x_min, x_max = X_vis[:, 0].min() - 1, X_vis[:, 0].max() + 1
y_min, y_max = X_vis[:, 1].min() - 1, X_vis[:, 1].max() + 1
xx, yy = np.meshgrid(
np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02)
)
Z = clf_vis.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
bg_cmap = ListedColormap(["#DFF3E3", "#DDEBFF", "#FCE1E4"])
pt_palette = ["#4C9F70", "#4F81BD", "#D65A6F"]
plt.figure(figsize=(9, 6))
plt.contourf(xx, yy, Z, alpha=0.45, cmap=bg_cmap)
sns.scatterplot(
x=X_vis[:, 0],
y=X_vis[:, 1],
hue=[iris.target_names[i] for i in y_vis],
palette=pt_palette,
s=85,
edgecolor="white",
linewidth=0.9,
alpha=0.95
)
plt.title("决策树分类决策边界", pad=12, weight="bold")
plt.xlabel("花瓣长度 (cm)")
plt.ylabel("花瓣宽度 (cm)")
plt.legend(title="类别", frameon=True)
plt.tight_layout()
plt.show()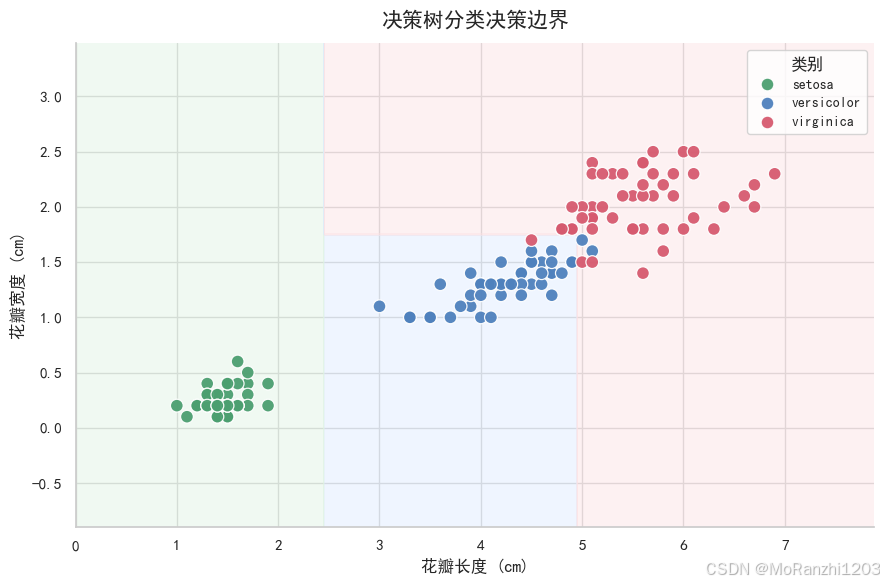
从图中可以看到,决策树的边界并不是平滑曲线,而是由多个水平或垂直切分组成的矩形区域。这正是树模型处理非线性问题的典型方式。它不是通过一条连续曲线去拟合类别边界,而是在特征空间中不断"切分区域",最终让不同区域尽可能对应不同类别。
6.2 树结构可视化
除了看空间上的切分结果,更重要的是直接查看树本身的结构。这里不再使用容易和背景混在一起的白色卡片效果,而是直接采用彩色填充节点,并设置更柔和的画布背景。
python
plt.figure(figsize=(20, 10), facecolor="#F4F6F8")
ax = plt.gca()
ax.set_facecolor("#F4F6F8")
plot_tree(
clf,
feature_names=["萼片长度", "萼片宽度", "花瓣长度", "花瓣宽度"],
class_names=iris.target_names,
filled=True,
rounded=True,
fontsize=10,
proportion=False,
precision=2
)
plt.title("决策树结构可视化", pad=14, weight="bold")
plt.tight_layout()
plt.show()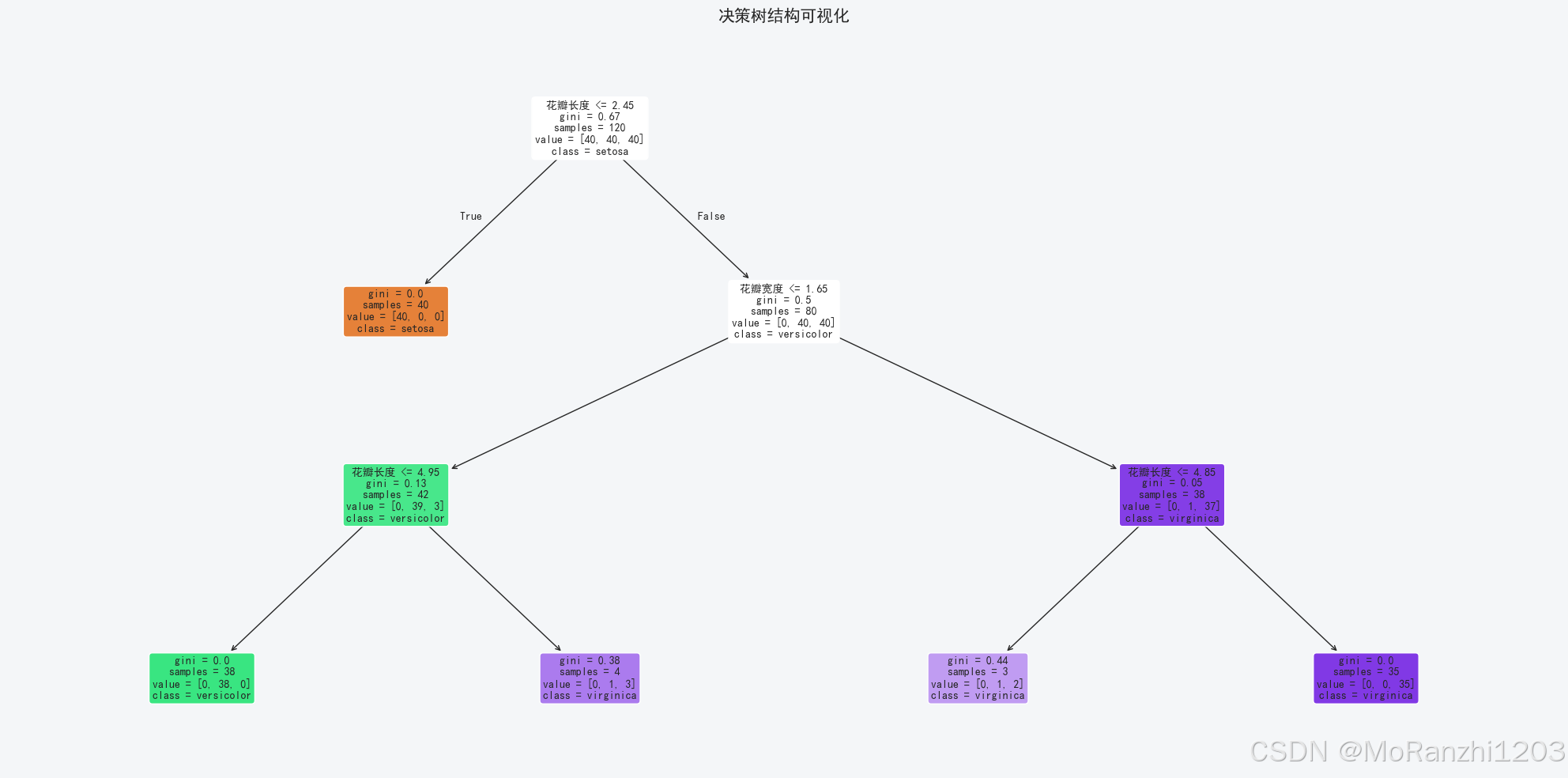
在树结构图中,通常可以直接看到当前节点的划分条件、节点纯度指标、样本数量、各类别样本分布以及当前节点的预测类别。相比很多模型只能看到输入和输出,决策树的内部逻辑是可以被完整展开的。
如果不想使用图,也可以直接导出文本规则:
python
rules = export_text(
clf,
feature_names=["萼片长度", "萼片宽度", "花瓣长度", "花瓣宽度"]
)
print(rules)|--- 花瓣长度 <= 2.45
| |--- class: 0
|--- 花瓣长度 > 2.45
| |--- 花瓣宽度 <= 1.65
| | |--- 花瓣长度 <= 4.95
| | | |--- class: 1
| | |--- 花瓣长度 > 4.95
| | | |--- class: 2
| |--- 花瓣宽度 > 1.65
| | |--- 花瓣长度 <= 4.85
| | | |--- class: 2
| | |--- 花瓣长度 > 4.85
| | | |--- class: 2
决策边界图和树结构图结合在一起,非常适合帮助读者真正理解决策树的工作过程。前者展示的是"空间如何被切分",后者展示的是"规则如何被组织"。
7. 常用参数与模型复杂度控制
决策树最容易出问题的地方,不是模型不会调用,而是树长得太深。因此,参数控制往往比基础调用更重要。
criterion 用于指定划分标准。实际使用中最常见的是 gini 和 entropy,前者对应基尼指数,后者对应信息熵。大多数场景下,默认的 gini 就足够使用。
python
DecisionTreeClassifier(criterion="gini")
DecisionTreeClassifier(criterion="entropy")max_depth 表示树的最大深度,它是控制模型复杂度最直接的参数之一。深度太小,模型可能欠拟合;深度太大,模型则容易过拟合。
python
DecisionTreeClassifier(max_depth=3)min_samples_split 表示一个节点至少包含多少个样本,才允许继续分裂。这个参数可以抑制模型在样本过少的局部区域继续细分。
python
DecisionTreeClassifier(min_samples_split=4)min_samples_leaf 表示叶节点中至少保留多少个样本。相比 min_samples_split,它对最终叶节点规模的控制更直接,因此在实际调参中往往更加稳定。
python
DecisionTreeClassifier(min_samples_leaf=2)这些参数的共同作用,本质上都在回答同一个问题:树到底应该长到什么程度才合适。决策树不是越复杂越好,而是在足够表达数据规律和避免过拟合之间找到一个平衡点。
8. 过拟合现象与剪枝方法
决策树最大的风险就是过拟合。如果不做任何限制,树会不断分裂,直到叶节点非常纯,甚至只剩下极少量样本。这样做的结果通常是训练集准确率很高,但模型对新数据的泛化能力反而下降。
8.1 观察 max_depth 对性能的影响
python
depth_list = range(1, 11)
train_scores = []
test_scores = []
for depth in depth_list:
model = DecisionTreeClassifier(max_depth=depth, random_state=42)
model.fit(X_train, y_train)
train_scores.append(model.score(X_train, y_train))
test_scores.append(model.score(X_test, y_test))
plt.figure(figsize=(8.5, 5.2))
plt.plot(depth_list, train_scores, marker="o", linewidth=2.2, label="训练集准确率")
plt.plot(depth_list, test_scores, marker="s", linewidth=2.2, label="测试集准确率")
plt.title("max_depth 对模型性能的影响", pad=12, weight="bold")
plt.xlabel("树的最大深度")
plt.ylabel("准确率")
plt.xticks(list(depth_list))
plt.grid(alpha=0.25, linestyle="--")
plt.legend(frameon=True)
plt.tight_layout()
plt.show()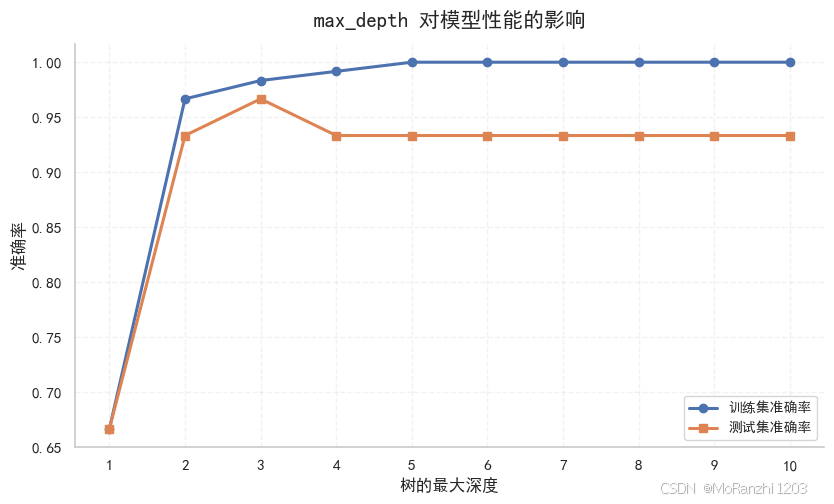
通常会看到一个很典型的现象:随着树深增加,训练集准确率不断上升,但测试集准确率往往先升后稳,甚至开始下降。这正是过拟合的典型特征。模型在训练集上学得越来越细,但学到的已经不只是有用规律,也包括了训练数据中的局部噪声。
需要说明的是,这里的实验主要用于展示参数变化趋势。正式调参时,不应仅依赖单次训练集/测试集划分的结果,而应结合交叉验证综合判断。
8.2 min_samples_split 与 min_samples_leaf 的影响
python
split_list = range(2, 11)
split_scores = []
for s in split_list:
model = DecisionTreeClassifier(min_samples_split=s, random_state=42)
model.fit(X_train, y_train)
split_scores.append(model.score(X_test, y_test))
plt.figure(figsize=(8.5, 5.2))
sns.lineplot(
x=list(split_list),
y=split_scores,
marker="o",
linewidth=2.2
)
plt.title("min_samples_split 对测试集准确率的影响", pad=12, weight="bold")
plt.xlabel("内部节点最小分裂样本数")
plt.ylabel("测试集准确率")
plt.grid(alpha=0.25, linestyle="--")
plt.tight_layout()
plt.show()
leaf_list = range(1, 11)
leaf_scores = []
for leaf in leaf_list:
model = DecisionTreeClassifier(min_samples_leaf=leaf, random_state=42)
model.fit(X_train, y_train)
leaf_scores.append(model.score(X_test, y_test))
plt.figure(figsize=(8.5, 5.2))
sns.lineplot(
x=list(leaf_list),
y=leaf_scores,
marker="o",
linewidth=2.2
)
plt.title("min_samples_leaf 对测试集准确率的影响", pad=12, weight="bold")
plt.xlabel("叶节点最小样本数")
plt.ylabel("测试集准确率")
plt.grid(alpha=0.25, linestyle="--")
plt.tight_layout()
plt.show()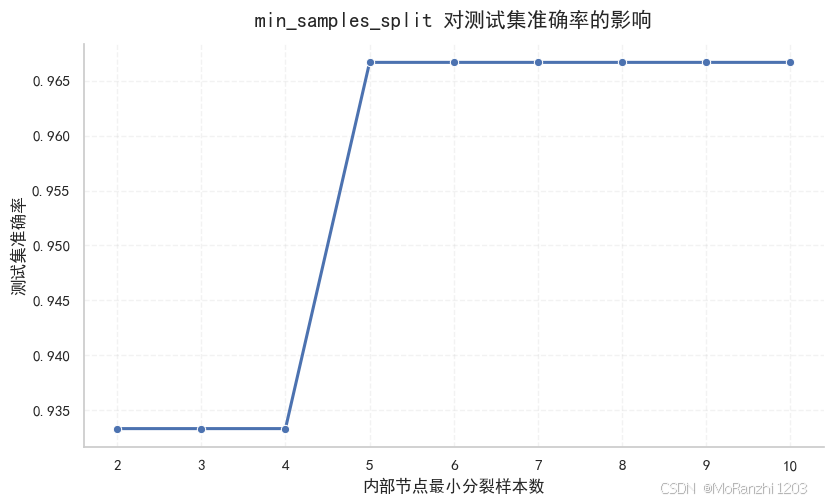
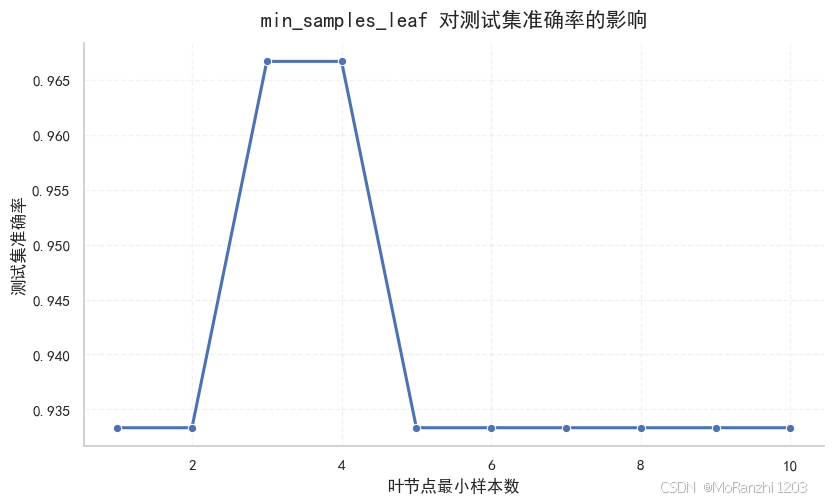
这两个参数都会影响树的复杂度。参数越小,模型越容易继续分裂;参数越大,模型越保守。如果设置过大,模型也可能因为过早停止划分而欠拟合。因此,它们并不是越大越好,而是要在抑制过拟合和保持足够表达能力之间找到合适的平衡。
8.3 预剪枝与后剪枝
控制过拟合的思路通常可以分为两类。第一类是预剪枝,也就是在训练过程中直接限制树的增长;第二类是后剪枝,也就是先生成一棵较完整的树,再删除其中不必要的分支。
预剪枝最常见的实现方式,就是直接设置 max_depth、min_samples_split、min_samples_leaf 或 max_leaf_nodes 等参数。例如:
python
pruned_clf = DecisionTreeClassifier(
max_depth=4,
min_samples_split=5,
min_samples_leaf=2,
random_state=42
)
pruned_clf.fit(X_train, y_train)
print("预剪枝后测试集准确率:", pruned_clf.score(X_test, y_test))预剪枝后测试集准确率: 0.9666666666666667
后剪枝的思路则不同,它允许树先充分生长,然后再根据复杂度惩罚去掉不必要的分支。在 scikit-learn 中,最常见的后剪枝方式是代价复杂度剪枝,对应参数 ccp_alpha。
下面用 wine 数据集观察剪枝效果:
python
wine = load_wine()
X_wine = wine.data
y_wine = wine.target
Xw_train, Xw_test, yw_train, yw_test = train_test_split(
X_wine, y_wine, test_size=0.3, random_state=42, stratify=y_wine
)
path = DecisionTreeClassifier(random_state=42).cost_complexity_pruning_path(Xw_train, yw_train)
ccp_alphas = path.ccp_alphas
alpha_list = []
train_scores = []
test_scores = []
for alpha in ccp_alphas:
model = DecisionTreeClassifier(random_state=42, ccp_alpha=alpha)
model.fit(Xw_train, yw_train)
alpha_list.append(alpha)
train_scores.append(model.score(Xw_train, yw_train))
test_scores.append(model.score(Xw_test, yw_test))
plt.figure(figsize=(8.5, 5.2))
plt.plot(alpha_list, train_scores, marker="o", linewidth=2.2, label="训练集准确率")
plt.plot(alpha_list, test_scores, marker="s", linewidth=2.2, label="测试集准确率")
plt.title("ccp_alpha 对剪枝后模型性能的影响", pad=12, weight="bold")
plt.xlabel("ccp_alpha")
plt.ylabel("准确率")
plt.grid(alpha=0.25, linestyle="--")
plt.legend(frameon=True)
plt.tight_layout()
plt.show()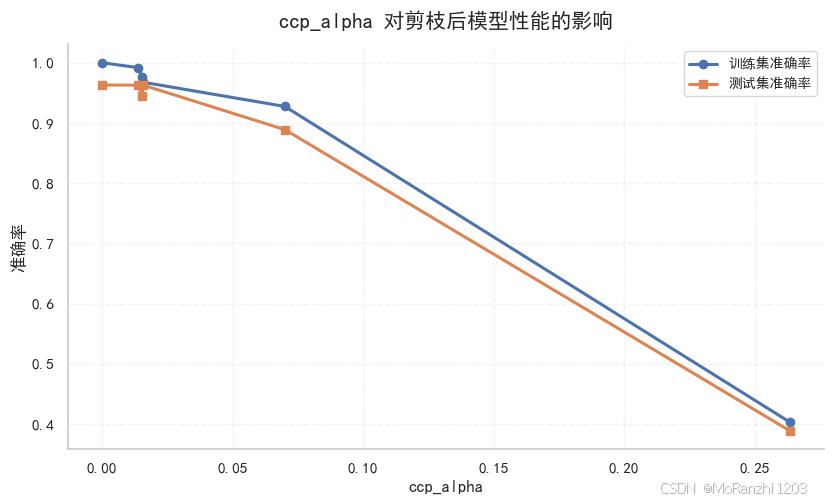
从结果中通常可以看到,ccp_alpha=0 时树最复杂;随着 ccp_alpha 增大,模型会被逐渐简化。训练集准确率一般会下降,而测试集准确率则可能在某个范围内更稳定。剪枝的目标从来不是让训练集表现最好,而是让模型在新数据上表现得更可靠。
9. 特征重要性与参数调优
训练好模型后,我们还可以进一步分析模型更依赖哪些特征,以及如何通过系统化搜索找到更合适的参数组合。
9.1 特征重要性分析
python
feature_importance = pd.DataFrame({
"特征": ["萼片长度", "萼片宽度", "花瓣长度", "花瓣宽度"],
"重要性": clf.feature_importances_
}).sort_values("重要性", ascending=True)
plt.figure(figsize=(8, 5))
bars = plt.barh(
feature_importance["特征"],
feature_importance["重要性"],
color=sns.color_palette("Greens", len(feature_importance)),
edgecolor="black",
linewidth=0.8
)
for bar in bars:
plt.text(
bar.get_width() + 0.01,
bar.get_y() + bar.get_height() / 2,
f"{bar.get_width():.3f}",
va="center",
fontsize=10
)
plt.title("决策树特征重要性", pad=12, weight="bold")
plt.xlabel("重要性得分")
plt.ylabel("特征")
plt.xlim(0, max(feature_importance["重要性"]) + 0.08)
plt.tight_layout()
plt.show()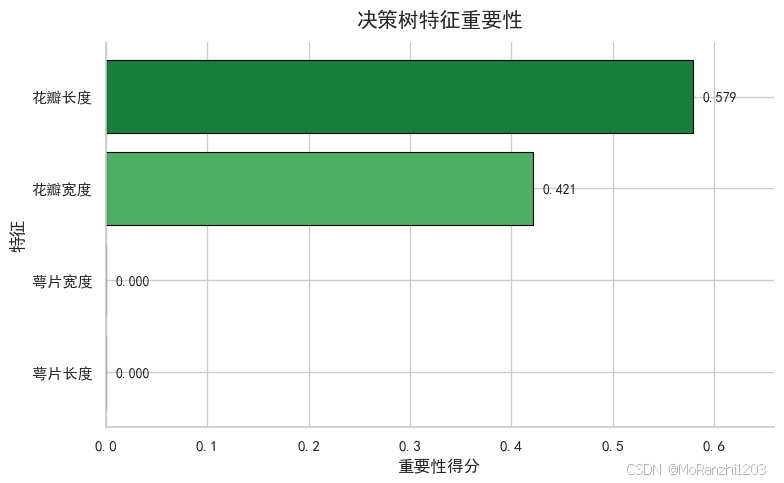
在鸢尾花数据集中,花瓣相关特征通常更重要,因为它们对类别区分更明显。不过需要注意,决策树给出的特征重要性并不等于因果关系,也不一定在所有场景下都稳定。特别是在特征高度相关或样本量较小时,重要性分数需要结合具体业务背景一起理解。
9.2 使用网格搜索调参
在实际项目中,参数通常不应凭经验硬设,而应结合交叉验证进行搜索:
python
param_grid = {
"criterion": ["gini", "entropy"],
"max_depth": [2, 3, 4, 5, None],
"min_samples_split": [2, 4, 6],
"min_samples_leaf": [1, 2, 3]
}
grid = GridSearchCV(
DecisionTreeClassifier(random_state=42),
param_grid=param_grid,
cv=5,
scoring="accuracy"
)
grid.fit(X_train, y_train)
best_model = grid.best_estimator_
y_pred = best_model.predict(X_test)
print("最优参数:", grid.best_params_)
print("交叉验证最佳得分:", grid.best_score_)
print("测试集准确率:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
txt
最优参数: {'criterion': 'gini', 'max_depth': 4, 'min_samples_leaf': 1, 'min_samples_split': 2}
交叉验证最佳得分: 0.9416666666666668
测试集准确率: 0.9333333333333333
precision recall f1-score support
0 1.00 1.00 1.00 10
1 0.90 0.90 0.90 10
2 0.90 0.90 0.90 10
accuracy 0.93 30
macro avg 0.93 0.93 0.93 30
weighted avg 0.93 0.93 0.93 30如果希望继续保留模型的可解释性,还可以把最优模型画出来:
python
plt.figure(figsize=(20, 10), facecolor="#F4F6F8")
ax = plt.gca()
ax.set_facecolor("#F4F6F8")
plot_tree(
best_model,
feature_names=["萼片长度", "萼片宽度", "花瓣长度", "花瓣宽度"],
class_names=iris.target_names,
filled=True,
rounded=True,
fontsize=10,
precision=2
)
plt.title("网格搜索得到的最优决策树结构", pad=14, weight="bold")
plt.tight_layout()
plt.show()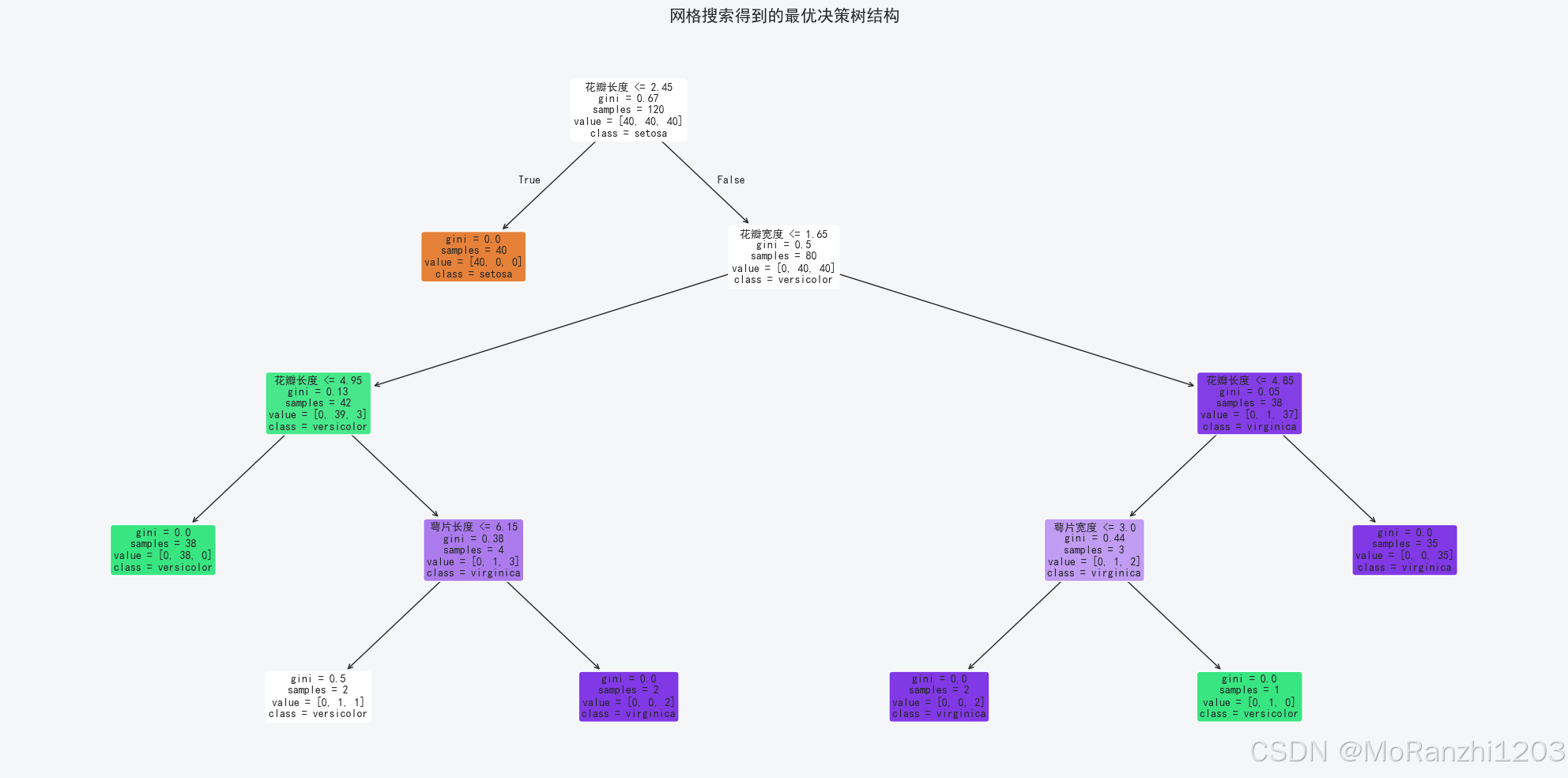
相比手动试参数,网格搜索的优点在于它能够系统地遍历给定的参数空间,并用交叉验证来衡量不同组合的泛化能力。这种方式通常比凭经验试几个参数更稳妥,也更符合实际工程流程。
10. 决策树的优缺点与适用场景
决策树之所以在机器学习中始终占据重要位置,原因并不只是它容易上手,更因为它在"可解释性"和"建模直觉"上具有很强的优势。
它的第一个优点是可解释性强。模型最终可以被表示为一套清晰的判断规则,非常适合教学演示、规则挖掘和结果解释。第二个优点是对数据预处理要求较低,通常不依赖特征标准化,也不要求特征之间具有线性关系。第三个优点是能够自然处理非线性分类问题,并且支持多分类任务。更重要的是,决策树还是随机森林、GBDT、XGBoost 等树模型家族的基础,学好它对于后续理解集成学习非常有帮助。
当然,它的局限也同样明显。最典型的问题就是容易过拟合,尤其是在树深不受限制时。除此之外,单棵决策树对数据扰动比较敏感,训练数据稍有变化,树结构可能就会明显不同。因此,在真实项目中,单棵决策树更常被用作基线模型、解释模型,或者作为集成模型的基础单元,而不是最终性能最强的选择。
如果你的任务比较看重模型可解释性,希望快速建立一个非线性分类基线,或者想直观看到特征如何影响预测结果,那么 DecisionTreeClassifier 通常是一个很好的起点。如果你的目标是追求更强、更稳定的预测性能,那么单棵决策树往往只是起点,而不是终点。
11. 总结
DecisionTreeClassifier 是 scikit-learn 中最值得深入理解的入门分类模型之一。
它的重要性并不只在于"能做分类",而在于它把机器学习中的许多关键问题变得具体且可观察。通过一棵树,我们可以直接看到节点纯度如何影响划分,模型复杂度如何逐步增长,过拟合为什么会发生,以及剪枝和参数调优为什么能够改善泛化能力。
从工程角度看,单棵决策树通常不是预测性能最强的模型,但它依然是理解树模型体系的关键起点。真正吃透决策树,往往意味着你已经不只是会调用 API,而是开始真正理解机器学习建模本身。
如果你愿意,我下一步可以继续把这篇文章再做一轮"发布前精修",专门统一代码注释风格、图题表达和段落衔接。