文章目录
- [1. 椭圆曲线群](#1. 椭圆曲线群)
- [2. 椭圆曲线的加法乘法](#2. 椭圆曲线的加法乘法)
- [3. 对称加密和非对称加密(公钥加密)](#3. 对称加密和非对称加密(公钥加密))
- [4. 椭圆曲线数字签名算法(ECDSA)](#4. 椭圆曲线数字签名算法(ECDSA))
- [5. FLUSH+RELOAD 攻击](#5. FLUSH+RELOAD 攻击)
-
- [5.1 攻击思路](#5.1 攻击思路)
- [5.2 攻击者测量时段的选择](#5.2 攻击者测量时段的选择)
- [6. OpenSSL 实现的 ECDSA(有漏洞)](#6. OpenSSL 实现的 ECDSA(有漏洞))
-
- [6.1 OpenSSL 的 ECDSA实现(论文攻击的就是它)](#6.1 OpenSSL 的 ECDSA实现(论文攻击的就是它))
- [6.2 初读时我的疑问](#6.2 初读时我的疑问)
- [7. 蒙哥马利阶梯](#7. 蒙哥马利阶梯)
- [8. 攻击者怎么用 FLUSH+RELOAD 攻击获取 k?](#8. 攻击者怎么用 FLUSH+RELOAD 攻击获取 k?)
-
- [8.1 攻击步骤](#8.1 攻击步骤)
- [8.2 为什么这样就能恢复出K](#8.2 为什么这样就能恢复出K)
- [9. 论文中提到的FLUSH+RELOAD 攻击的三个局限性](#9. 论文中提到的FLUSH+RELOAD 攻击的三个局限性)
-
- [9.1 时间分辨率不够](#9.1 时间分辨率不够)
- [9.2 内存访问与探测重叠](#9.2 内存访问与探测重叠)
- [9.3 CPU 缓存优化的干扰](#9.3 CPU 缓存优化的干扰)
- [10. 密钥越小,对攻击的抵御能力越强?](#10. 密钥越小,对攻击的抵御能力越强?)
- [11. 恢复完整的K、攻击的局限性和影响、防御方法](#11. 恢复完整的K、攻击的局限性和影响、防御方法)
- [12. 结论与未来工作](#12. 结论与未来工作)
- 总结
补充一些预备知识
1. 椭圆曲线群


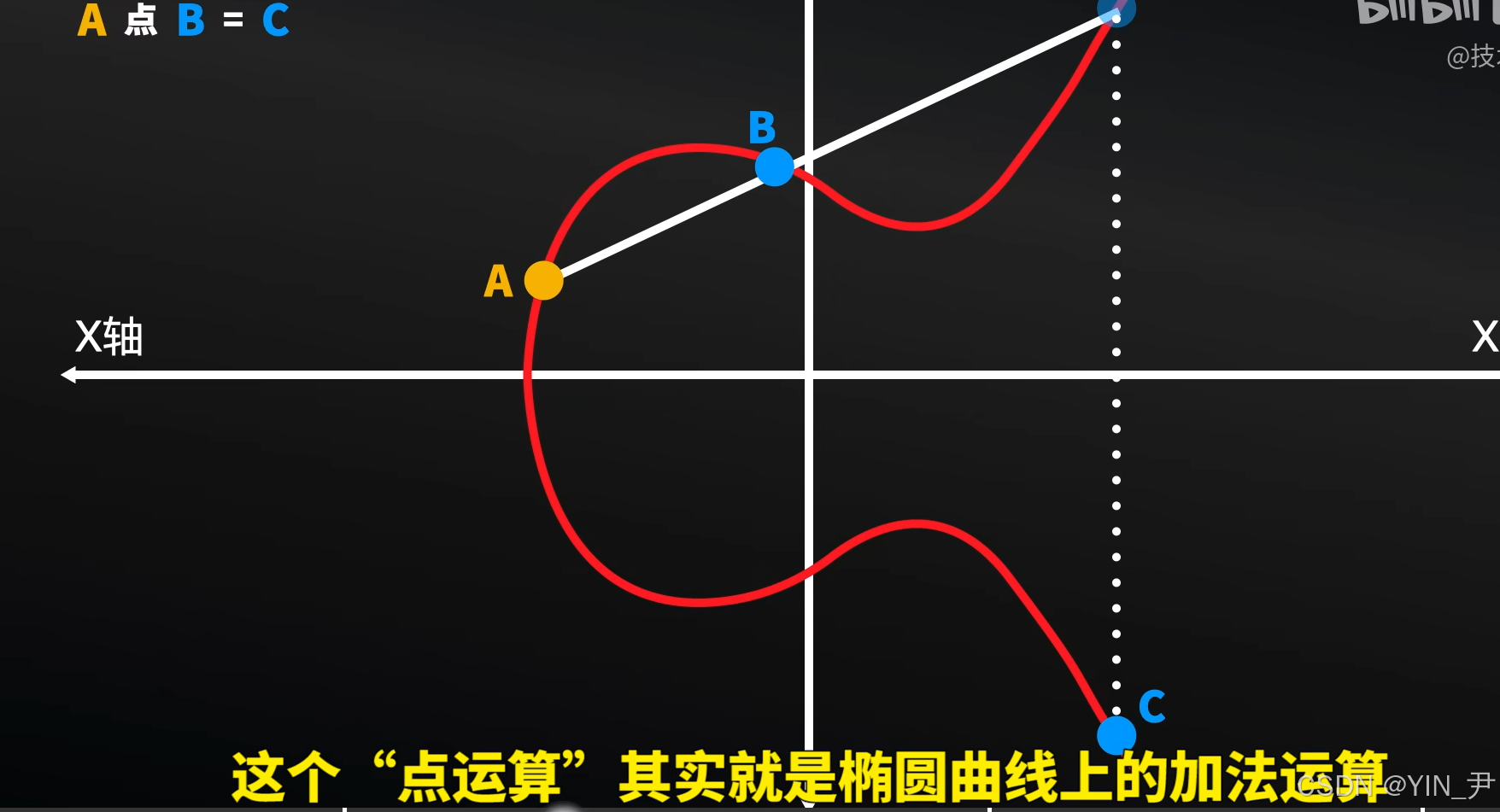
2. 椭圆曲线的加法乘法
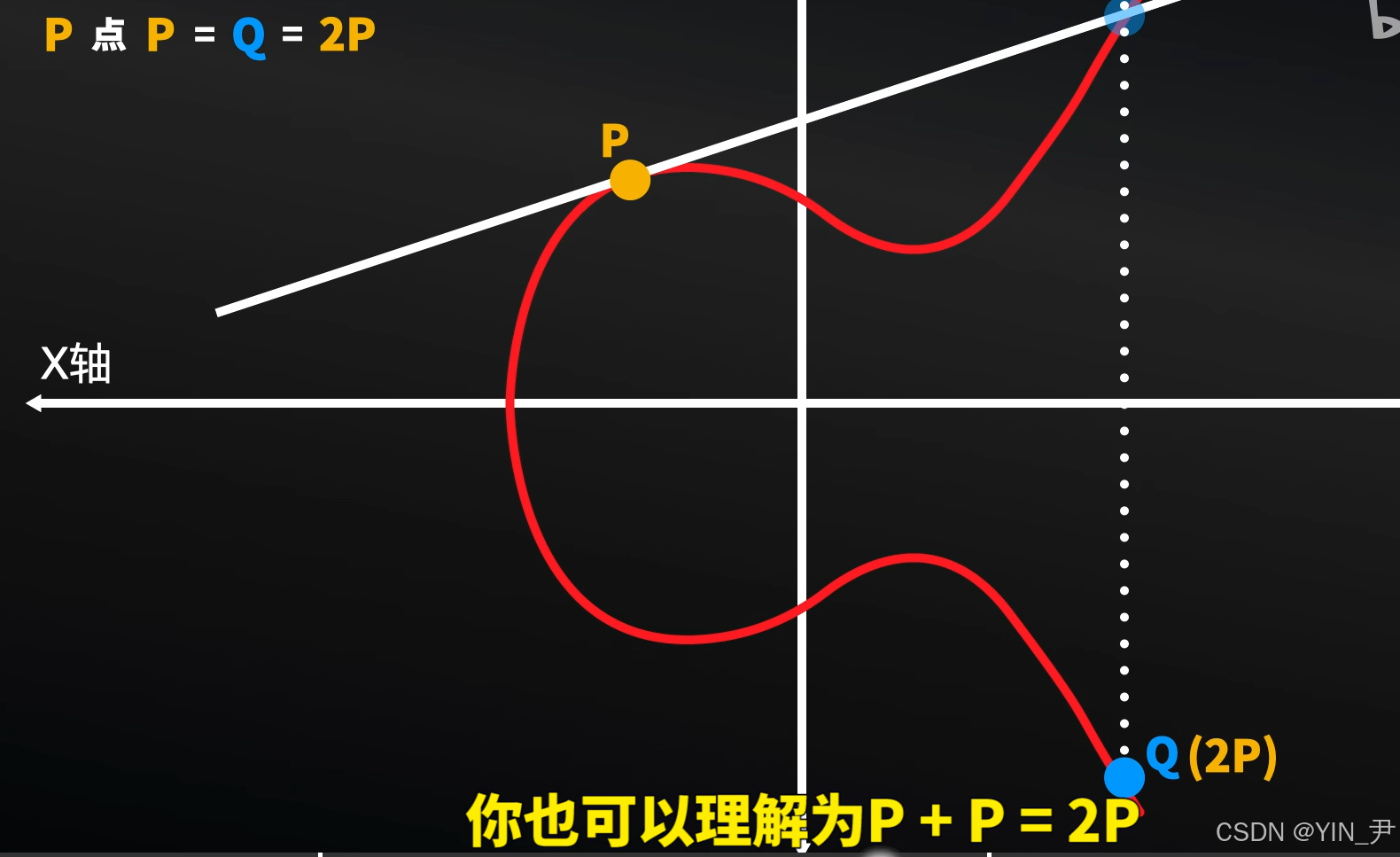
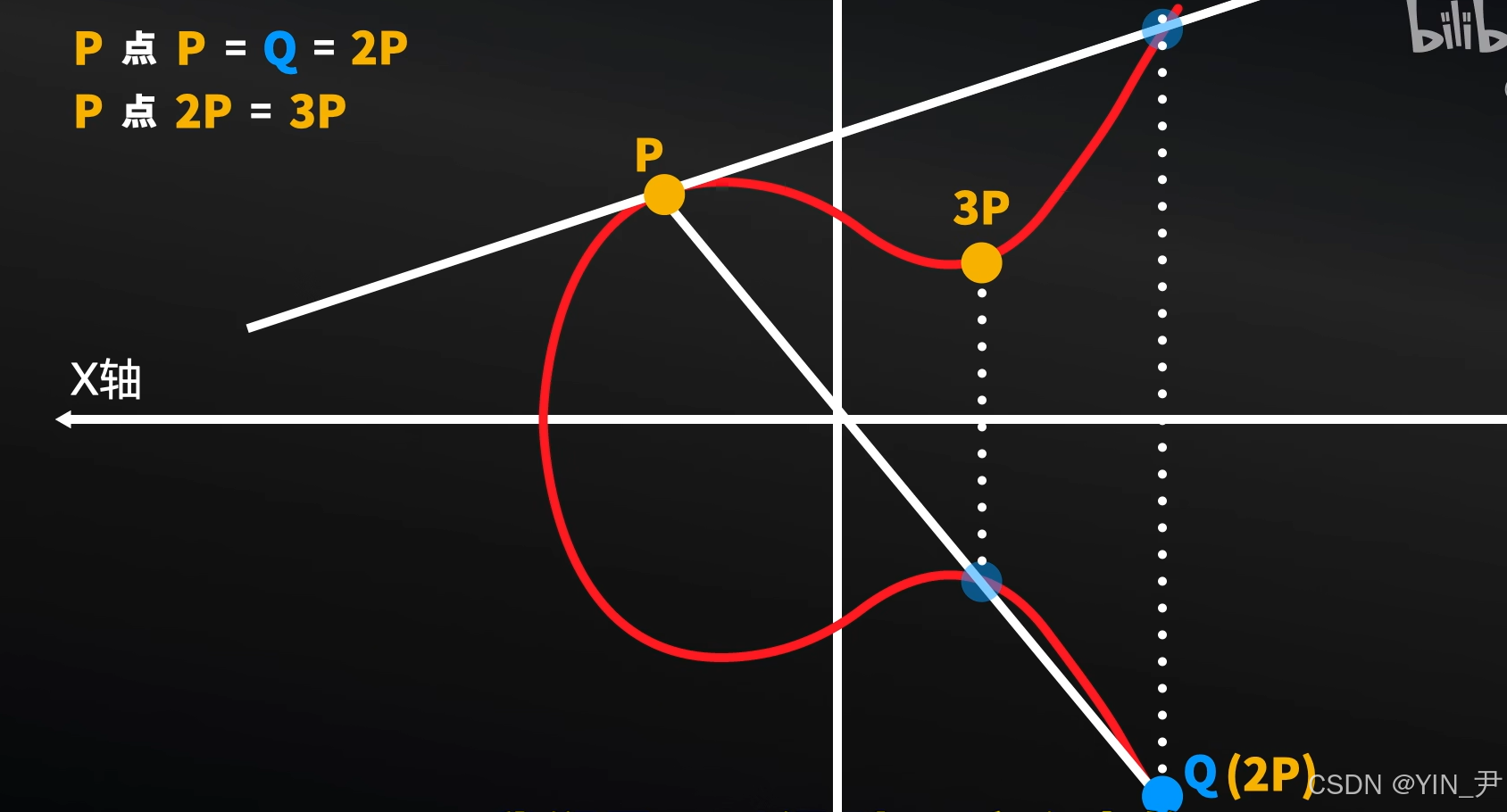
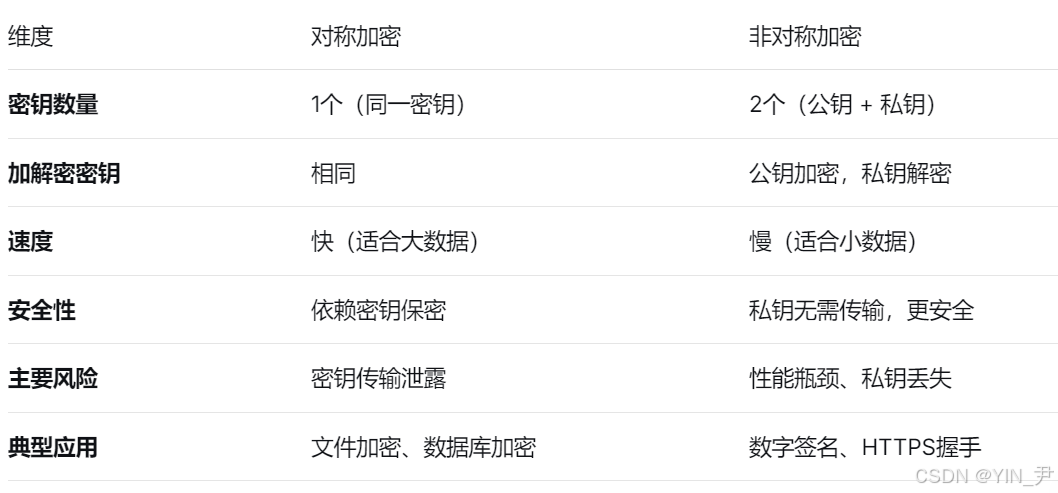
3. 对称加密和非对称加密(公钥加密)


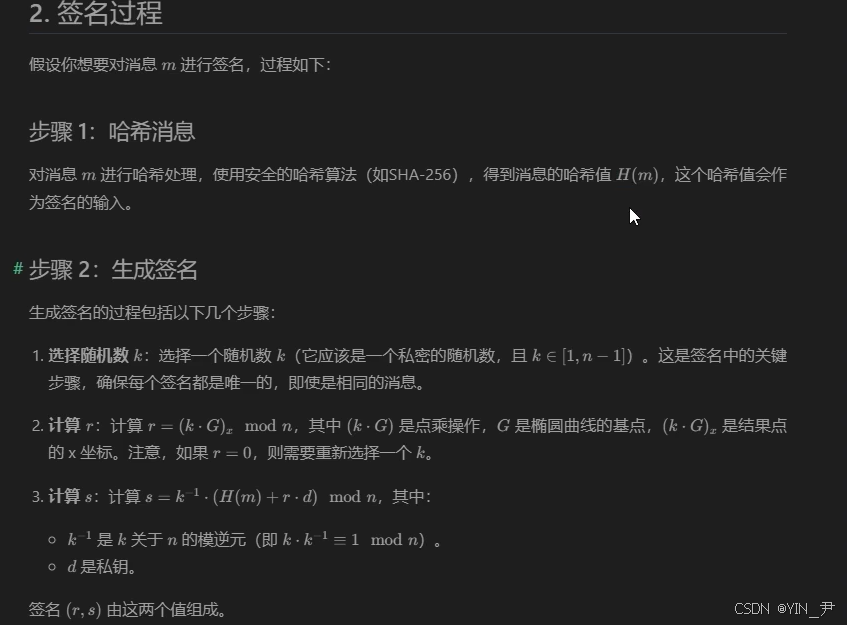
4. 椭圆曲线数字签名算法(ECDSA)


5. FLUSH+RELOAD 攻击
5.1 攻击思路
第一步flush:攻击者先用 clflush 指令清空指定cache行的数据。
第二步wait:清掉之后,如果受害者在攻击者 reload之前访问了同一块物理内存(比如执行了那段 if 分支的代码),这时CPU就会因为cache未命中而从主存重新加载数据,加载过程就会把数据再次放进cache。
第三步reload:然后攻击者如果再去访问它刚才清空的那个位置,因为受害者刚刚把数据加载进了缓存,所以如果攻击者读取时速度很快(cache命中),说明受害者访问过;反之如果慢(cache未命中),说明受害者没访问过。
最终攻击者通过"速度快慢",就能知道受害者程序刚才访问了哪块内存!
OpenSSL 的实现里,虽然运算序列固定,但内部有一个 if 判断(根据密钥的当前比特决定走哪个分支)。攻击者通过追踪程序执行时走了哪个分支,就能反推出来这个比特值。
5.2 攻击者测量时段的选择
- 当受害者的内存访问与攻击者的测量时段重叠时,攻击者会错过该次访问。因此,增加时段长度会缩短攻击者进行测量的时间占比,从而降低访问被错过的概率。
受害者的签名运算一直在跑,而攻击者的监听是一段一段、断断续续的(测完一个窗口,要等下一个窗口再测)。
如果受害者访问内存的时间,刚好卡在两个监听窗口的间隙里,攻击者就完全抓不到这次访问,相当于漏了 k 的一个比特。
时间槽越短 → 窗口间隙越多 → 漏抓的概率越高
时间槽越长 → 窗口间隙越少 → 漏抓的概率越低
- 另一方面,攻击者无法在单个时段内区分对同一内存行的多次访问,也无法确定在同一时段内对不同内存行的内存访问顺序。因此,延长时段会降低攻击的分辨率。
时间槽就像一个「大篮子」,你只能知道「篮子里有没有东西」,但不知道:
同一个篮子里,东西放了几次(比如同一行内存被访问了 2 次,你只能看到「有访问」,看不到次数)
篮子里的东西,是先放 A 还是先放 B(比如两个不同缓存行的访问,你分不清先后顺序)
时间槽越短 → 篮子越小 → 能精准区分每一次访问,细节拉满(分辨率高)
时间槽越长 → 篮子越大 → 多次访问混在一起,细节全糊了(分辨率低)
- 由此可见,选择时段长度需要在攻击分辨率和内存访问被错过的概率之间做出权衡。
6. OpenSSL 实现的 ECDSA(有漏洞)
6.1 OpenSSL 的 ECDSA实现(论文攻击的就是它)
AI调整后加注释的代码:
c
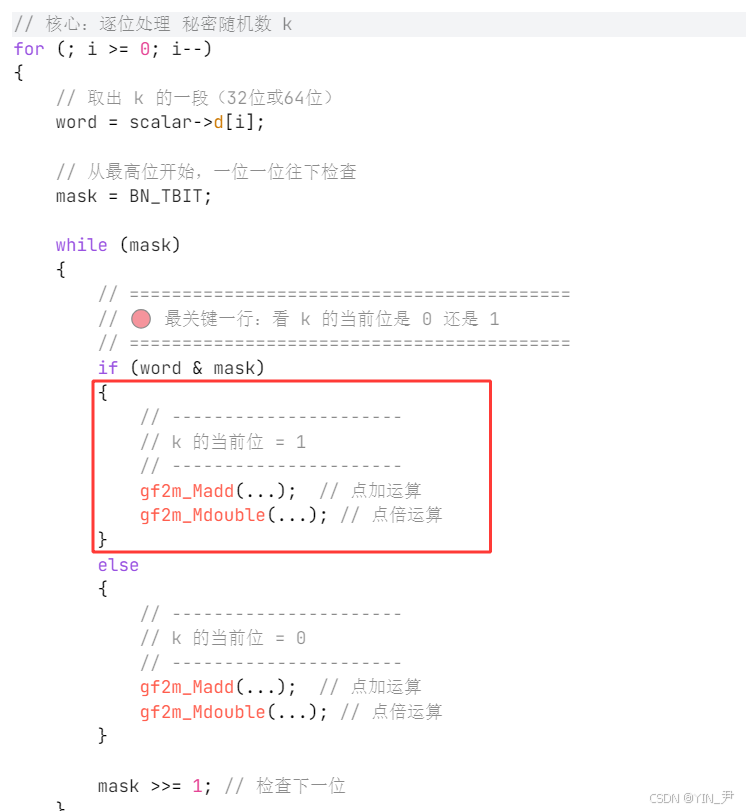
// 核心:逐位处理 秘密随机数 k
for (; i >= 0; i--)
{
// 取出 k 的一段(32位或64位)
word = scalar->d[i];
// 从最高位开始,一位一位往下检查
mask = BN_TBIT;
while (mask)
{
// ==========================================
// 🔴 最关键一行:看 k 的当前位是 0 还是 1
// ==========================================
if (word & mask)
{
// ----------------------
// k 的当前位 = 1
// ----------------------
gf2m_Madd(...); // 点加运算
gf2m_Mdouble(...); // 点倍运算
}
else
{
// ----------------------
// k 的当前位 = 0
// ----------------------
gf2m_Madd(...); // 点加运算
gf2m_Mdouble(...); // 点倍运算
}
mask >>= 1; // 检查下一位
}
}6.2 初读时我的疑问
- 这段代码是干嘛的?
这是在算 ECDSA 签名里最核心的一步:计算 k × G
(攻击者的目标就是获取这个K, 恢复ECDSA签名时的随机数
𝑘,从而就可以算出私钥)
- k的类型是什么,这里为什么要一比特一比特的逐位处理?
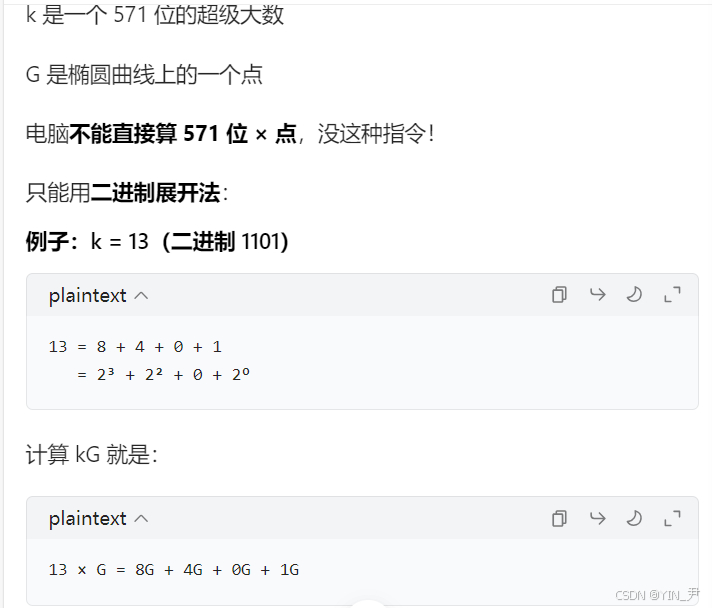
k 是一个 "超级大整数",大到电脑普通变量存不下。
电脑里普通整数:int 只有 32 位
但 ECDSA 的 k:最少 256 位,论文里是 571 位
这么大的数,一个变量存不下
所以 OpenSSL 用 数组(一串小数字) 来存它
scalar->d[i];// d 是一个unsigned int 数组,每一格存 32位
为什么要一比特一比特地取?
因为椭圆曲线乘法 kG 只能按位算,没有别的办法!
每一位代表:要不要加这一段 G
是 1 → 要加
是 0 → 不加
c
初始化结果 = 0
循环每一位:
结果 = 结果 × 2 (点倍)
如果当前位是 1:
结果 = 结果 + G (点加)你必须一位一位看 k,才能决定这一步要不要做加法!
- mask = BN_TBIT,mask是掩码的意思,BN_TBIT是啥?
BN_TBIT = 一个 "最高位是 1、其他全是 0" 的固定数字,作为掩码掩码(用来一位一位 "扫描" k 的工具)
怎么做到一位一位扫描呢?
if (word & mask)&------按位与:有0则0,全1才1
word是这一轮循环取出的K的当前一位,与mask(开始为1000...000)
两者进行按位与之后,就取出了K的最高一位(从最高位开始)
然后
mask >>= 1右移一位,那就变成了0100...000循环上去再进行
(word & mask)就取到了K 的次高比特位,后续也是如此,就可以依次取到K的每一位进行判断
关键点:
如果是1,那么
word & mask结果为真
执行if对应的分支
如果为0,执行else,进行的分支
- if分支和else分支里面具体做了什么?
if 和 else 里面做的事情几乎一模一样 ,唯一区别:操作的变量顺序 / 对象换了一下!
但 ------ 它们是两段不同的代码,在内存里位置不同 → 这就是漏洞!
都在做椭圆曲线的点加 + 点倍
数学功能完全一样
但 CPU 执行的指令不一样!内存地址不一样!缓存行不一样!
ps:CPU 要执行某一行代码,必须先让这段指令加载到 CPU 的缓存(Cache)中,然后 CPU 才能从缓存里读取并执行。如果不在缓存里,CPU 会通过硬件自动从内存把它加载到缓存,然后才执行。

- 为什么这就是漏洞?(论文核心)
k 是 0 还是 1 → 决定 CPU 访问哪一段内存 → 攻击者靠缓存就能看出来!
k=1 → 访问内存 A
k=0 → 访问内存 B
FLUSH+RELOAD 攻击
只要看你访问了 A 还是 B,就知道 k 这一位是 0 还是 1!
k 是秘密,但代码用 k 的每一位来选择走哪条路,等于直接把秘密泄露给了攻击者!
7. 蒙哥马利阶梯
这是计算 kG(一个点乘一个数)的一种算法
特点:每轮循环都做相同的操作(先加后倍或先倍后加),不依赖 k 的比特值,理论上抗侧信道攻击
计算 kG 最直接的方法是用"倍点-加法"算法,但它的操作会根据 k 的比特变化,容易被攻击者看出来。
蒙哥马利阶梯是一种更安全的算法:它不管 k 的比特是0还是1,每一轮都执行一次加法和一次倍点,操作序列固定。所以从运算时间上看不出区别。
但是:
OpenSSL 的实现里,虽然操作序列一样,但程序会走不同的 if 分支。这个分支可以被攻击者看到。
8. 攻击者怎么用 FLUSH+RELOAD 攻击获取 k?
8.1 攻击步骤
- 第一步:FLUSH
攻击者先把 if 和 else 两段代码从缓存里强行删掉!
clflush( 地址A );
clflush( 地址B );
- 第二步:等待
等待受害者签名程序运行,代码开始依次处理K的每一位:
k 某一位是 1 → 跑 if → 把地址 A 加载进缓存
k 某一位是 0 → 跑 else → 把地址 B 加载进缓存
- 第三步:reload
攻击者再去读:
读地址 A,看快不快
读地址 B,看快不快
规则:
读得快 = 在缓存里 = 刚才访问过 = 走了这条路
读得慢 = 不在缓存里 = 没走过
8.2 为什么这样就能恢复出K
根据走的分支不同就可以判断 k 这一位是 0 还是 1:
情况 1:
地址 A 快
地址 B 慢
→ 刚才走了 if → k 这一位 = 1
情况 2:
地址 A 慢
地址 B 快
→ 刚才走了 else → k 这一位 = 0
进而就一比特一比特的恢复出K了
然后用 k 就可以算出私钥:
私钥 d = (s*k - e) / r私钥直接到手!
→ 可以无限伪造签名
9. 论文中提到的FLUSH+RELOAD 攻击的三个局限性
9.1 时间分辨率不够
CPU 执行指令超级快
两次内存访问可能只隔几纳秒
FLUSH+RELOAD 是周期性探测,不是全程盯着
如果两次访问挨太近 → 攻击分不清谁先谁后
9.2 内存访问与探测重叠
即攻击者在 "测量" 的时候,刚好受害者在 "访问内存"
攻击流程是:
清缓存(FLUSH)
等待
读内存测时间(RELOAD)
如果在第 3 步攻击者正在测的时候,
受害者刚好在访问同一段内存,
结果:
攻击者把这段内存 "刚读进 Cache",
受害者紧接着又访问一次。
攻击者的测量会被干扰,这次访问直接漏掉
9.3 CPU 缓存优化的干扰
CPU 有个优化叫 空间预取:
如果你访问了内存行 A
CPU 会自动把相邻的 B 也读进缓存
为了跑得快
这就会影响到攻击者:
攻击者本来想监视 A
结果 B 也被加载了
攻击分不清是程序真的执行了 B,还是 CPU 预取的
即:该攻击不是万能的,它会看不清、会漏抓、会被 CPU 干扰。
10. 密钥越小,对攻击的抵御能力越强?
密钥越小,分组操作的时间越短
密钥短→秘密数k位数少→算kG(签名核心运算)的步骤少、跑的时间飞快。
从而迫使时间片更短
运算太快,攻击者来不及慢悠悠监听,只能把监听的时间槽(时段)缩得特别短。
更短的时间片,增加了重叠概率
时间槽越短,攻击者测速、清缓存的操作,越容易和受害者的内存访问撞在一起(即上面提到的内存访问与探测重叠)。
进而增加比特位丢失的概率
一重叠→测量被干扰→这一位k的 0/1 直接漏抓;漏的位一多,最后补全密钥的难度就增大了
11. 恢复完整的K、攻击的局限性和影响、防御方法
完全恢复
由于攻击已经恢复了绝大部分比特,论文中提到,剩下的部分可以通过经典的"大步小步法"在不到1秒内补齐。也就是说,攻击者最终能得到完整的k,进而算出私钥。
局限性
定点打击:该攻击针对的是OpenSSL的标量乘法实现,因此仅适用于使用该实现以及类似Montgomery梯形实现的场景。此实现的漏洞源于秘密随机数的位数决定了程序执行哪条条件分支。
影响
这种攻击不仅适用于密码软件,也可能威胁到其他类型的软件(比如通过缓存访问模式泄露用户按键、网络流量等信息)。
防御方法
FLUSH+RELOAD攻击利用的是X86架构允许非特权进程使用 clflush 指令清空缓存行的特性,如果能限制clflush指令的使用权限,可以在一定程度上防御这种攻击。
12. 结论与未来工作
结论
- 论文研究的结果表明,当标量乘法步骤涉及秘密参数时,在所有椭圆曲线协议的实现中都应避免使用 OpenSSL 的蒙哥马利梯级实现。
- 密钥越短越安全,建议避免使用这种实现,正如NaCl 库(不依赖分支的恒定时间算法)采用的那种方法
未来工作
将攻击扩展到其他密码算法
研究对非密码软件的威胁
评估这种攻击对隐私的实际影响
总结
- 这篇论文干了什么?
用FLUSH+RELOAD攻击OpenSSL的ECDSA签名,恢复了随机数k,拿到了私钥
- 为什么能成功?
因为OpenSSL的实现里,k的每个比特会影响程序走哪个if分支,分支对应不同内存地址,FLUSH+RELOAD能探测到
我知道了这种缓存侧信道攻击是怎么做的,后面我是要研究如何防御这种攻击的!