如果你需要在 Windows 桌面端对同一目录下大量纯文本做批量词频统计,并可选带上 TF-IDF、BM25 两列用于后续筛选或简报,可以用【批量文档词频权重统计工具】。下文只记操作与产物,不写任何公式或底层实现。
前置条件:语料必须是 .txt;放在同一主文件夹内,需要时勾选「遍历子目录」把子文件夹里的 txt 一并扫进来。
主界面选路径支持浏览与拖拽。计算选项里「词频」不可取消;需要对比「跨文档更显眼」的词时勾选 TF-IDF,需要另一种常见检索权重时再勾选 BM25,二者可同开。勾选后「显示排序」下拉里会出现对应字段,便于你在结果区按不同指标预览前 200 条。
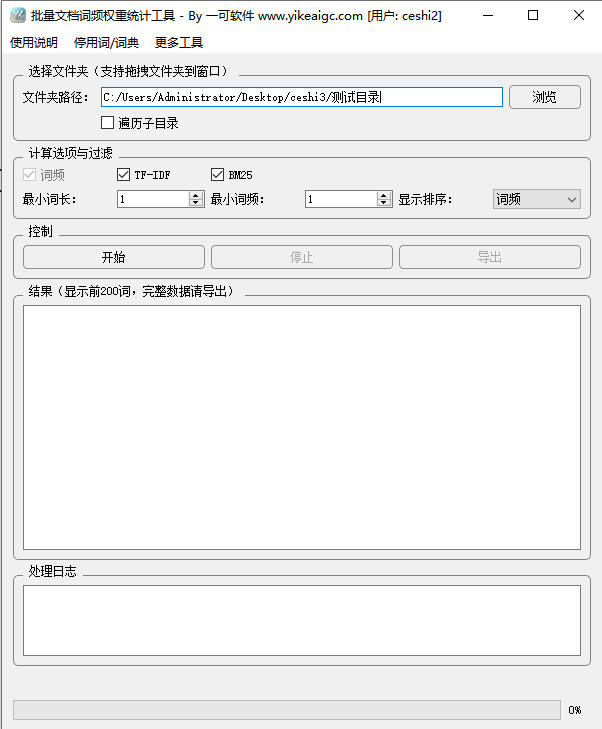
过滤区「最小词长」「最小词频」按语料规模调。噪声多就提高词长或词频门槛。菜单「停用词/词典」里可维护停用词:从 txt 批量导入、导出备份、恢复默认,或在列表里增删。另有「自定义词典」页,按界面示例准备每行词条,可提升领域专有词被整词识别的概率。
点开始后排进度与日志;失败文件会标明读取问题。底部摘要给总文件数、成功/失败/跳过、总词数与去重词数。结果文本框仅展示前两百词,全量请用「导出」生成 CSV:在弹出框选排序字段、升降序、是否导出全部或仅前 N 条。
说明:纯标点、停用表里的词、过短的词以及纯数字形式会被过滤,具体以运行结果为准。若中途停止,是否仍能导出部分结果视当时完成情况而定,建议重要任务一次跑完或先小样验证。