关键词提取步骤
Step1:数据收集:收集研究需要的数据,建立相应的语料库
Step2:数据准备:导入分词库喝停用词库
Step3:模型建立:使用jieba分词,对语料库进行分词处理
Step4:模型结果统计:根据分词结果,进行词频统计,并绘制词云图
Step5:TF-IDF分析:得到加权分词结果
语料库的创建
1、什么是语料库
(1)语料库中存放的是在语言的实际使用中真实出现过的语言材料;
(2)语料库是以电子计算机为载体承载语言知识的基础资源;
(3)真实语料需要经过加工(分析和处理),才能成为有用的资源。
2、如何构建语料库
将所需要被分析的文档读入计算机内存;
利用Python构建语料库.
如何进行中文分词
中文文本与英文文本不同,英文单词之间有天然的空格分隔,而中文词汇之间没有明显界限,因此 "分词" 是中文关键词提取的必经步骤。
在分词前,需要提前准备两个核心工具库:分词库和停用词库。
-
分词库:中文分词的基础工具分词库是用于识别中文词汇边界的算法集合,目前 Python 中最常用的是 jieba 库(结巴分词)。需要注意的是,jieba 库本身没有内置固定词组,默认通过词典匹配和概率模型进行分词,若需处理专业领域文本(如医学、法律),可自行添加专业词汇词典,提高分词准确性。
-
停用词库:过滤无意义词汇停用词是指在文本中频繁出现,但对表达核心意思无实质帮助的词汇,如 "的、了、是、呀、吗" 等助词、语气词,以及 "我们、他们、这里" 等代词。这些词汇若不过滤,会严重干扰关键词的筛选,因此需要导入停用词库,在分词后自动剔除这些词汇。
使用 jieba 库进行中文分词
数据准备完成后,即可进入分词环节,这是将连续文本拆解为离散词汇的关键步骤。使用 jieba 库分词的操作简单高效,核心流程如下:
-
安装并导入 jieba 库:通过 pip install jieba 命令安装后,在 Python 代码中导入 jieba 模块;
-
读取语料库中的文本:利用 Python 的文件操作函数,读取语料库中的单篇或多篇文本;
-
执行分词:调用 jieba.cut () 函数对文本进行分词,该函数支持精确模式、全模式和搜索引擎模式三种分词模式,其中精确模式适用于大多数关键词提取场景,能准确分割出词汇;
-
过滤停用词:将分词结果与停用词库进行比对,剔除停用词,得到净化后的分词列表。
例如,对文本 "秦始皇陵兵马俑是西安的著名景点,吸引了大量游客前来参观" 进行分词,经 jieba 精确模式分词并过滤停用词后,得到结果:"秦始皇陵", "兵马俑", "西安", "著名景点", "吸引", "大量", "游客", "参观"。
词云图绘制
词云图又叫文字云,是对文本数据中出现频率较高的关键词予以视觉上的突出,形成"关键词的渲染"就类似云一样的彩色图片,从而过滤掉大量的文本信息,使人一眼就可以领略文本数据的主要表达意思。

制作词云图的步骤如下:首先安装 wordcloud 库和 matplotlib 库;然后将分词后的词汇列表拼接成字符串;接着配置词云图参数(如背景颜色、字体路径、最大词数等);最后生成并显示词云图。
从文中给出的旅游相关词云图示例可以看到,"西安""兵马俑""华清宫""临潼区" 等词汇因出现频率较高,在词云图中以较大字体呈现,而 "骗子""黑车" 等负面词汇也通过词云图直观展现,让我们快速把握文本的核心主题和情感倾向。
TF-IDF 分析
词频统计虽然简单直接,但存在明显缺陷:一些在所有文本中都频繁出现的通用词汇(如 "中国" 在很多中文文本中都高频出现),仅通过词频无法区分其在特定文本中的重要性。而 TF-IDF 算法通过 "词频(TF)" 与 "逆文档频率(IDF)" 的乘积,有效解决了这一问题,能更精准地筛选出具有区分度的关键词。
TF-IDF 的核心公式与原理
词频(TF)
指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数),以防止它偏向长的文件。
计算公式为:TF = 某个词在文章中的出现次数 / 文章的总词数。
其核心作用是体现该词在当前文本中的重要性,出现次数越多,TF 值越高。
逆文档频率(IDF)
逆向文档频率。**IDF的主要思想是:如果包含词条t的文档越少,IDF越大,则说明词条具有很好的类别区分能力。**反映该词在整个语料库中的独特性
计算公式为:IDF = log (语料库的文档总数 / (包含该词的文档数 + 1))。
分母加 1 是为了避免分母为 0 的情况。
TF-IDF
TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
计算公式为:TF-IDF = 词频(TF) × 逆文档频率(IDF)
该值越大,说明该词在当前文本中越重要,且在整个语料库中越独特,是理想的关键词。
举例:
TF-IDF 的实际计算示例以文中《中国的蜜蜂养殖》为例,我们来详细拆解 TF-IDF 的计算过程:
-
已知条件:文章总词数 1000,"中国""蜜蜂""养殖" 各出现 20 次;语料库(中文网页总数)250 亿,包含 "中国" 的网页 62.3 亿,包含 "蜜蜂" 的网页 0.484 亿,包含 "养殖" 的网页 0.973 亿。
-
计算 TF 值:三个词的 TF 均为 20/1000 = 0.02。
-
计算 IDF 值:
-
中国的 IDF = log (250 / (62.3 + 1)) ≈ log (250/63.3) ≈ 0.603
-
蜜蜂的 IDF = log (250 / (0.484 + 1)) ≈ log (250/1.484) ≈ 2.713
-
养殖的 IDF = log (250 / (0.973 + 1)) ≈ log (250/1.973) ≈ 2.410
-
-
计算 TF-IDF 值:
-
中国的 TF-IDF = 0.02 × 0.603 ≈ 0.0121
-
蜜蜂的 TF-IDF = 0.02 × 2.713 ≈ 0.0543
-
养殖的 TF-IDF = 0.02 × 2.410 ≈ 0.0482
-
从结果可以看出,虽然三个词的 TF 值相同,但 "蜜蜂" 和 "养殖" 的 IDF 值远高于 "中国",因此它们的 TF-IDF 值也更高,成为更具区分度的核心关键词。这也符合文本主题 ------《中国的蜜蜂养殖》的核心内容是 "蜜蜂养殖",而非泛泛的 "中国"。
简单来说,TF-IDF就相当于是加权
python实现案例
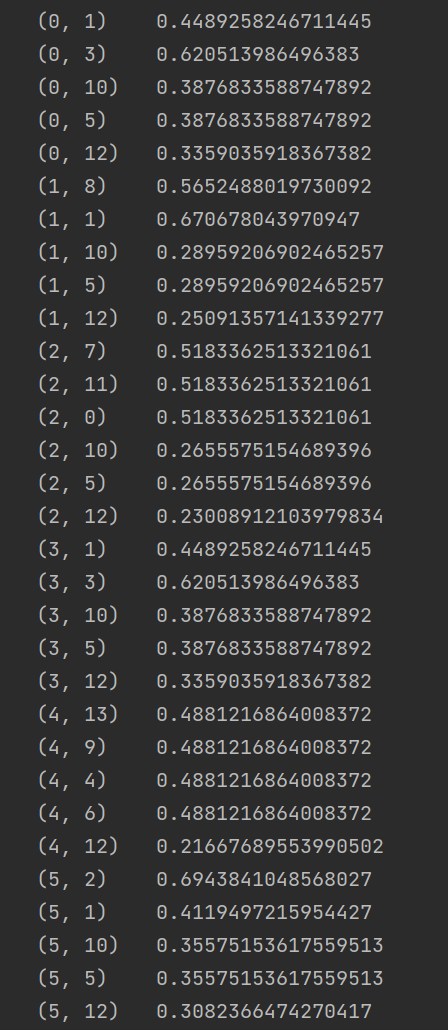
假如有以下句子作为语料库
This is the first document
This document is the second document
And this is the third one
Is this the first document
This line has several words
This is the final document
项目代码:
python
from sklearn.feature_extraction.text import TfidfVectorizer#补充内容:TF-IDF的方式计算
import pandas as pd
inFile = open(r".\task2_1.txt", 'r')
corpus = inFile.readlines()#
vectorizer = TfidfVectorizer() #类,转为TF-IDF的向量转换对象
tfidf = vectorizer.fit_transform(corpus) #传入数据,返回包含TF-IDF的向量值
print(tfidf)
wordlist = vectorizer.get_feature_names() #获取特征名称,所有的词
print(wordlist)
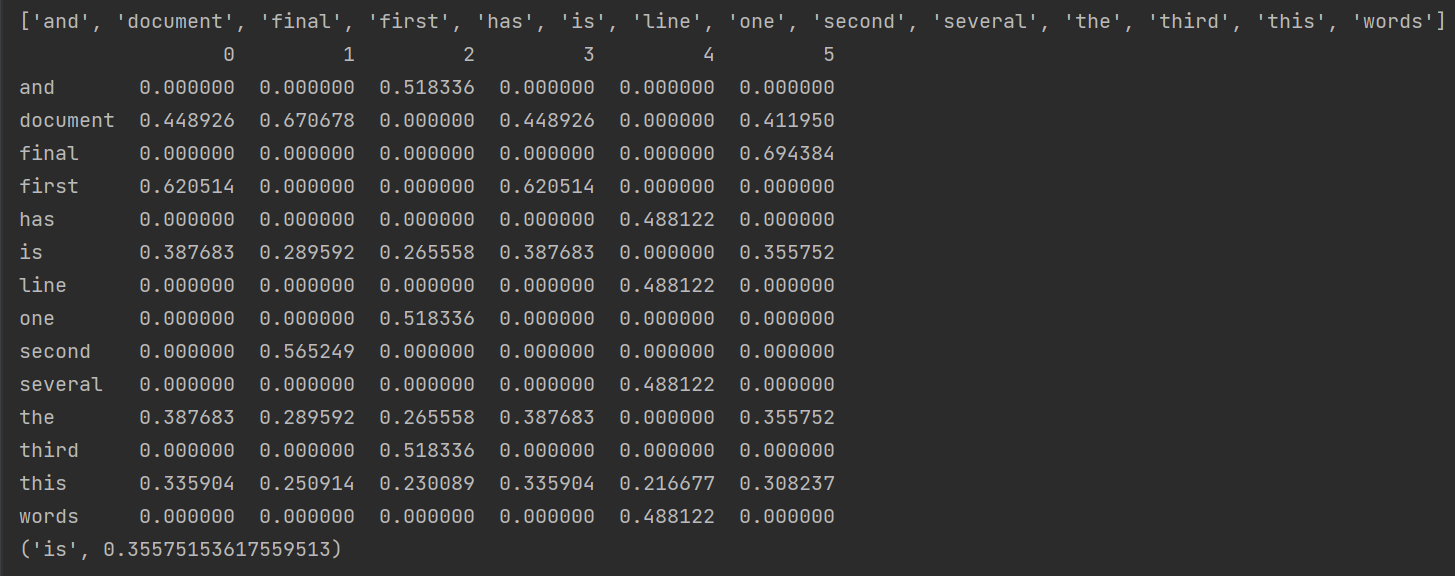
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)#tfidf.T.todense()恢复为稀疏矩阵
print(df)
featurelist = df.iloc[:,5].to_list() #通过索引号获取第2列的内容并转换为列表
resdict = {} #排序以及看输出结果对不对
for i in range(0, len(wordlist)):
resdict[wordlist[i]] = featurelist[i]
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
print(resdict[2])
#实现,pd实现,把所有的文章中关键词都进行排序,并且将排名在前5的关键词打印输出运行结果: