一、TF-IDF
1、文本分析之关键字提取
任务:给定任意一篇文本,然后提取该文本的关键词
如何进行关键词提取?
步骤
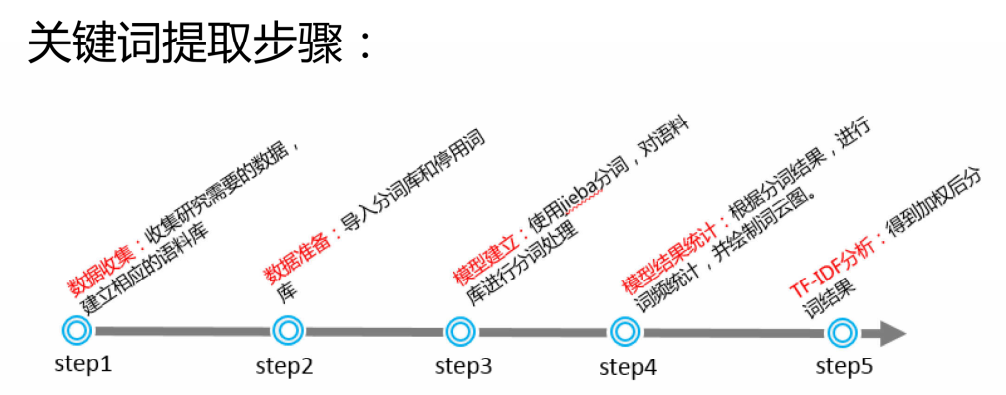
2、语料库的创建
1)什么是语料库?
(1)语料库中存放的是在语言的实际使用中真实出现过的语言材料
(2)语料库是以电子计算机为载体承载语言知识的基础资源
(3)真实语料需要经过加工(分析和处理),才能成为有用的资源
2)如何构建语料库?
将所需要被分析的文档读入计算机内存,利用python构建语料库
3、进行中文分词
1)导入分词库
固定词组,jieba并没有内置的词组
2)导入停用词库
没有意义的词,如:的,了,呀等
3)使用jieba库分词
将原文章完全分词即可
4、词云图绘制
词云图又叫文字云,是对文字数据中出现频率较高的关键词予以视觉上的突出,形成"关键的渲染",就类似云一样的彩色图片,从而过滤掉大量的文本信息,使人一眼就可以领略文本数据的主要表达意思
5、TF-IDF分析
1)TF
指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总次数),以防止它偏向长的文件

2)IDF
逆向文档频率。IDF的主要思想是:如果包含词条t的文档越少,IDF越大,则说明词条具有很好的类别区分能力
逆文档频率(IDF) = log(语料库的文档总数 / 包含该词的文档数)
3)TF-IDF
因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语
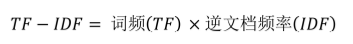
4)举例
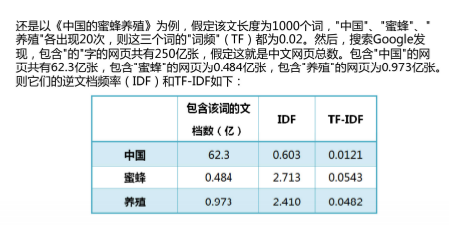
5)总结
TF-IDF相当于加权
6、实际运用
1)计算task_1.txt文件中的TF-IDF
task2_1.txt中内容
This is the first document
This document is the second document
And this is the third one
Is this the first document
This line has several words
This is the final document
python
from sklearn.feature_extraction.text import TfidfVectorizer#补充内容:TF-IDF的方式计算
import pandas as pd
a=open(r".\task2_1.txt", 'r')
corpus = a.readlines()
vectorizer = TfidfVectorizer() #类,转为TF-IDF的向量转换对象
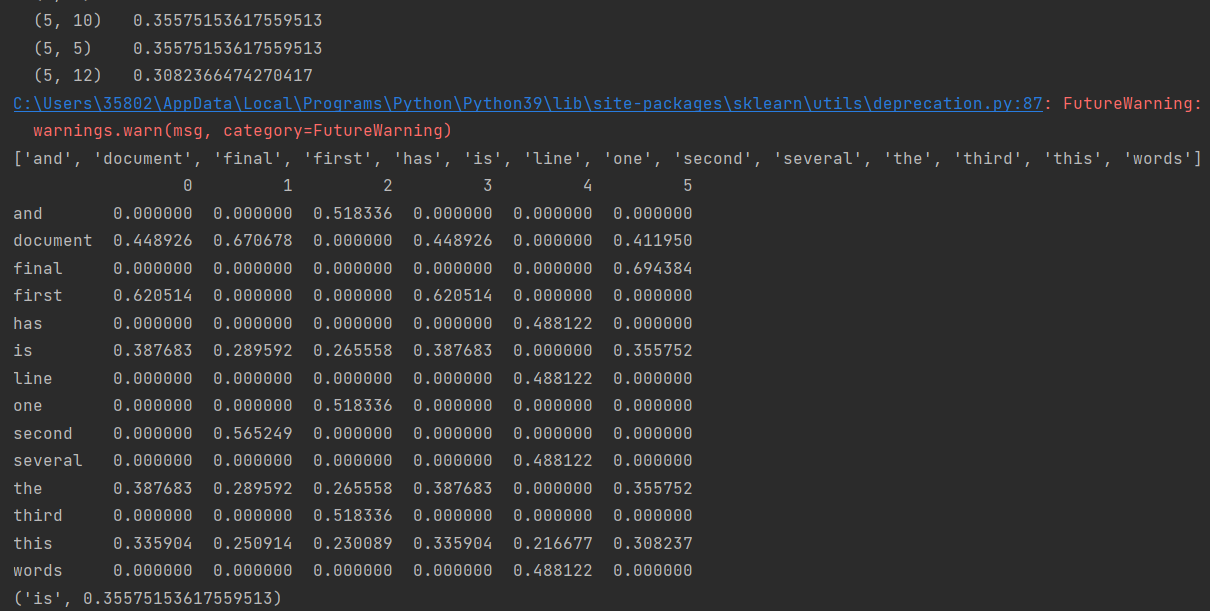
tfidf = vectorizer.fit_transform(corpus) #传入数据,返回包含TF-IDF的向量值
print(tfidf)
wordlist = vectorizer.get_feature_names() #获取特征名称,所有的词
print(wordlist)
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)#tfidf.T.todense()恢复为稀疏矩阵
print(df)
featurelist = df.iloc[:,5].to_list() #通过索引号获取第2列的内容并转换为列表
resdict = {} #排序以及看输出结果对不对
for i in range(0, len(wordlist)):
resdict[wordlist[i]] = featurelist[i]
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
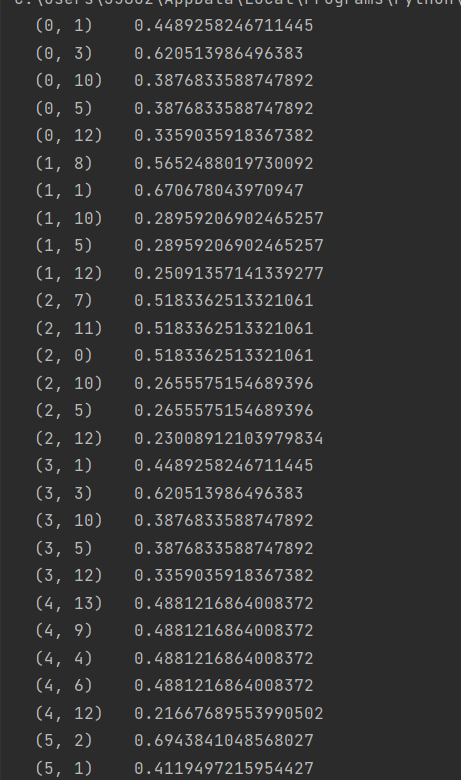
print(resdict[2])运行结果
7、TF-IDF红楼梦案例
通过网盘分享的文件:红楼梦.txt
链接: https://pan.baidu.com/s/1fhjq26nacK4TagNSi7bOLw 提取码: e83t
任务:将红楼梦文件 按卷 分隔为 多个文件,
使用TF-IDF算法实现提取每个文件的前10个关键词
对红楼梦文件进行读取,定位到章节任务1: 将红楼梦 根据卷名 分隔成 卷文件
python
import os #python标准库,不需要安装。关于操作系统的库
file = open("C:\红楼梦\红楼梦.txt",encoding='utf-8')#
flag = 0#用来标记当前是不是在第一次保存文件
juan_file = open('C:\红楼梦\红楼梦卷开头.txt','w',encoding='utf-8')
for line in file: #开始遍历整个红楼梦
if '卷 第' in line: #找到标题
juan_name = line.strip() +'.txt'
juan_name = juan_name.replace('\u3000', ' ')
path = os.path.join('C:\红楼梦\分卷' , juan_name)#构建一个完整的路径
print(path)
if flag == 0: #判断是否 是第1次读取到 卷 第
juan_file = open(path,'w',encoding='utf-8') #创建第1个卷文件
flag = 1
else: #判断是否 不是第1次读取到 卷 第
juan_file.close() #关闭第1次及 上一次的文件对象
juan_file = open(path,'w',encoding='utf-8') #创建一个新的 卷文件
continue
juan_file.write(line)
juan_file.close()运行结果: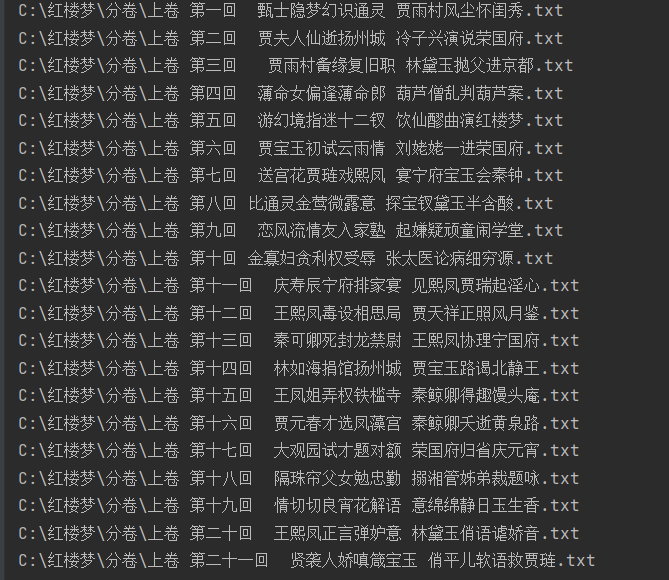
生成120以每一回标题为名称的文件
上卷第一回文件内容如下,其他文件中内容都是类似的

任务2:对每个卷进行分词,并删除包含停用词的内容
a、遍历所有卷的内容,并添加到内存中
b、将词库添加到jieba库中(注:jieba不一定能识别出所有的词,需要手动添加词库)
c、读取停用词(删除无用的关键词)
d、对每个卷内容进行分词,将分词进行比较,删除停用词
e、将所有分词后的内容写入到分词后汇总.txt1)遍历所有卷的内容,添加到内存中,并整理成表格格式
python
import pandas as pd #数据预处理的库
import os
filePaths = []#保存文件的路径
fileContents = []#保存文件路径对应的内容
for root, dirs, files in os.walk(r"C:\红楼梦\分卷"): # os.walk是直接对文件夹进行遍历 #os.listdir()遍历分卷中的所有文件
for name in files:
filePath = os.path.join(root, name) #获取每个卷文件的路径
print(filePath)
filePaths.append(filePath) #卷文件路径添加到列表filePaths中
f = open(filePath, 'r', encoding='utf-8')
fileContent = f.read() #读取每一卷中的文件内容
f.close()
fileContents.append(fileContent) #将每一卷的文件内容添加到列表fileContents
corpos = pd.DataFrame({ #将文件路径及文件内容添加为DataFrame框架中
'filePath': filePaths,
'fileContent': fileContents})#训练大家的数据处理能力
print(corpos)2)将词库添加到jieba库中,读取停用词(删除无用的关键词) ,对每个卷内容进行分词,将分词进行比较,删除停用词 ,并将所有分词后的内容写入到分词后汇总.txt
由于TF-IDF只能用于类似于task2_1.txt中的标准格式内容,所以,我们想要计算TF-IDF就需要将一回的内容放在同一行,并且有些类似于'的,你,我,漂亮'之类的词不需要计算TF-IDF值,并且有些红楼梦中的专属词语不能被分开,所以我们又使用了
专属词库:C:\红楼梦\红楼梦词库.txt
停用词库:C:\红楼梦\StopwordsCN.txt通过网盘分享的文件:红楼梦词库.txt
链接: https://pan.baidu.com/s/1SfsE0riyB9hW8uOg2SiHMg 提取码: ztgd
通过网盘分享的文件:StopwordsCN.txt
链接: https://pan.baidu.com/s/1RAMvpbQIH-IRO-bH3WjPiw 提取码: j6wh
python
import jieba
jieba.load_userdict(r"C:\红楼梦\红楼梦词库.txt") #导入分词库,把红楼梦专属的单词添加到jieba词库中。
# #导入停用词库 ,把无关的词提出。
stopwords = pd.read_csv(r"C:\红楼梦\StopwordsCN.txt",
encoding='utf8', engine='python',index_col=False) #engine读取文件时的解析引擎
# # '''进行分词,并与停用词表进行对比删除'''
file_to_jieba = open(r'C:/红楼梦/分词后汇总.txt','w',encoding='utf-8')#创建一个新文本
for index, row in corpos.iterrows(): #iterrows遍历行数据
juan_ci = '' #空的字符串
filePath = row['filePath']
fileContent = row['fileContent']
segs = jieba.cut(fileContent) #对文本内容进行分词,返回一个可遍历的迭代器
for seg in segs: #遍历每一个词
if seg not in stopwords.stopword.values and len(seg.strip())>0 :#剔除停用词和字符为0的内容
juan_ci += seg+' ' #juanci = '手机 电子书 '
# print(juan_ci)
words = juan_ci.strip().split()
# 删除前13个词
if len(words) > 13:
# 保留从第14个词开始的所有词
processed_words = words[13:]
else:
processed_words = []
# 第三步:重新组合成字符串
if processed_words:
processed_ci = ' '.join(processed_words)
else:
processed_ci = ''
# 第四步:写入文件
file_to_jieba.write(processed_ci + '\n')
file_to_jieba.close()删除前13个词语后,每一行内容

若不删前13个词语,每一行内容如下

3)任务3:计算TF-IDF值
python
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
inFile = open(r"C:\红楼梦\分词后汇总.txt", 'r',encoding='utf-8')
corpus = inFile.readlines()#返回一个列表,列表一个元素就是一行内容,一行内容一篇分词后的文章
vectorizer = TfidfVectorizer() #类,转为TF-IDF的向量器
tfidf = vectorizer.fit_transform(corpus) #传入数据,返回包含TF-IDF的向量值
wordlist = vectorizer.get_feature_names_out() #获取特征名称,所有的词
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)#tfidf.T.todense()恢复为稀疏矩阵
for i in range(len(corpus)):#排序,将重要的关键词排序在最前面
featurelist = df.iloc[:,i].to_list() #通过索引号获取第i列的内容并转换为列表
resdict = {} #排序以及看输出结果对不对
for j in range(0, len(wordlist)):
resdict[wordlist[j]] = featurelist[j] #[('贾宝玉',0.223),()]
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)#字典的键值对,元组数据类型返回
print('第{}回的核心关键词:'.format(i+1),resdict[0:10])运行结果:

可以看到每一行的TF-IDF值按从大到小依次排列