如何在个人电脑部署大模型实现Token自由
一、选择合适的大模型
这一步可以交给AI,把你的电脑配置发给它,比如我的:
bash
我的电脑配置如下,请问我电脑上可以部署什么大模型?
处理器 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80GHz 2.80 GHz
机带 RAM 16.0 GB (15.8 GB 可用)
存储 954 GB SSD WD PC SN740 SDDPNQD-1T00-1127
显卡 Intel(R) Iris(R) Xe Graphics (128 MB)给我推荐的模型如下
| 模型类型 | 推荐模型(使用量化版,如Q4_K_M) | 推荐理由 |
|---|---|---|
| 最优选择 | GPT-OSS-20B | 专为16GB内存优化,推理速度快,性能均衡,性价比极高reference:0reference:1reference:2。 |
| 最佳中文选择 | Qwen3-7B / 14B (通义千问) | 中文能力强,7B版流畅运行,14B版可挑战上限,适合复杂任务reference:3。 |
| 轻量灵活之选 | DeepSeek-R1-7B / 1.5B | 7B版是中文能力与资源消耗的平衡点reference:4;1.5B版入门首选,占用内存极少reference:5reference:6。 |
| 其他潜力之选 | LLaMA 3 (8B) Phi-3 (7B) Gemma 2 (9B) | 均为国际主流模型,有中文变体,性能出色,社区支持好。 |
我尝试安装了GPT-OSS-20B、Qwen3.5-4B。对于我这个i7处理器、16G运行内存、集成显卡的电脑,实测结果如下:
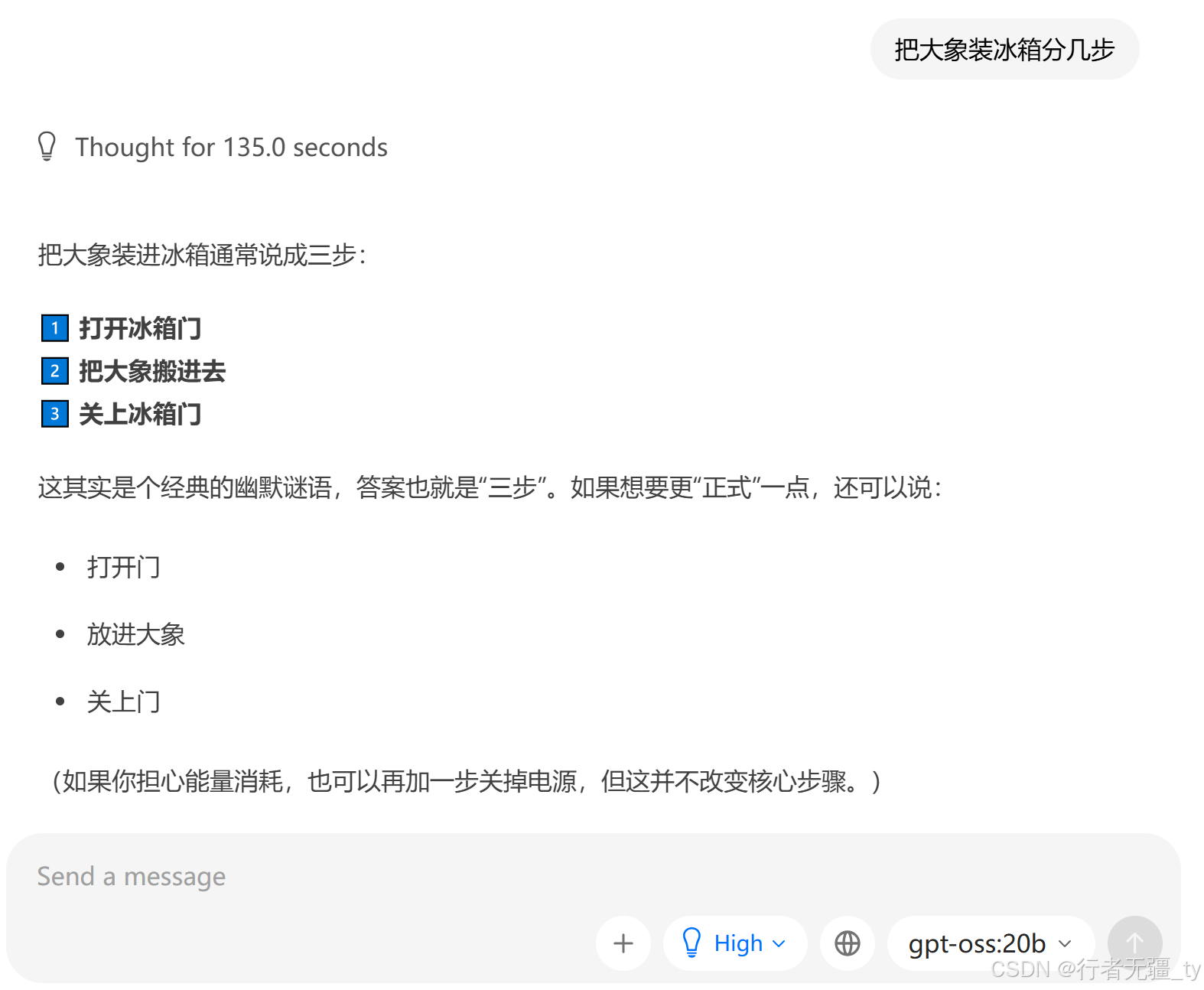
统一测试问题:把大象装冰箱分几步?
①GPT-OSS-20B 模型思考了135秒后开始回答,最终回答正确;
②Qwen3.5-4B模型陷入了死循环,无法给出回答。另外问它是谁,也得思考50多秒,token生成很慢,看着它几个字几个字的蹦,很捉急,这个量级的模型能力还是弱了点。
二、下载Ollama
对于部署工具,推荐使用 Ollama,它是目前最流行的本地大模型部署工具,仅需一条命令即可完成下载和启动,非常适合新手。
1.进入官网下载Ollama:https://ollama.com/download
注意:要求win10以上系统。
安装好了。
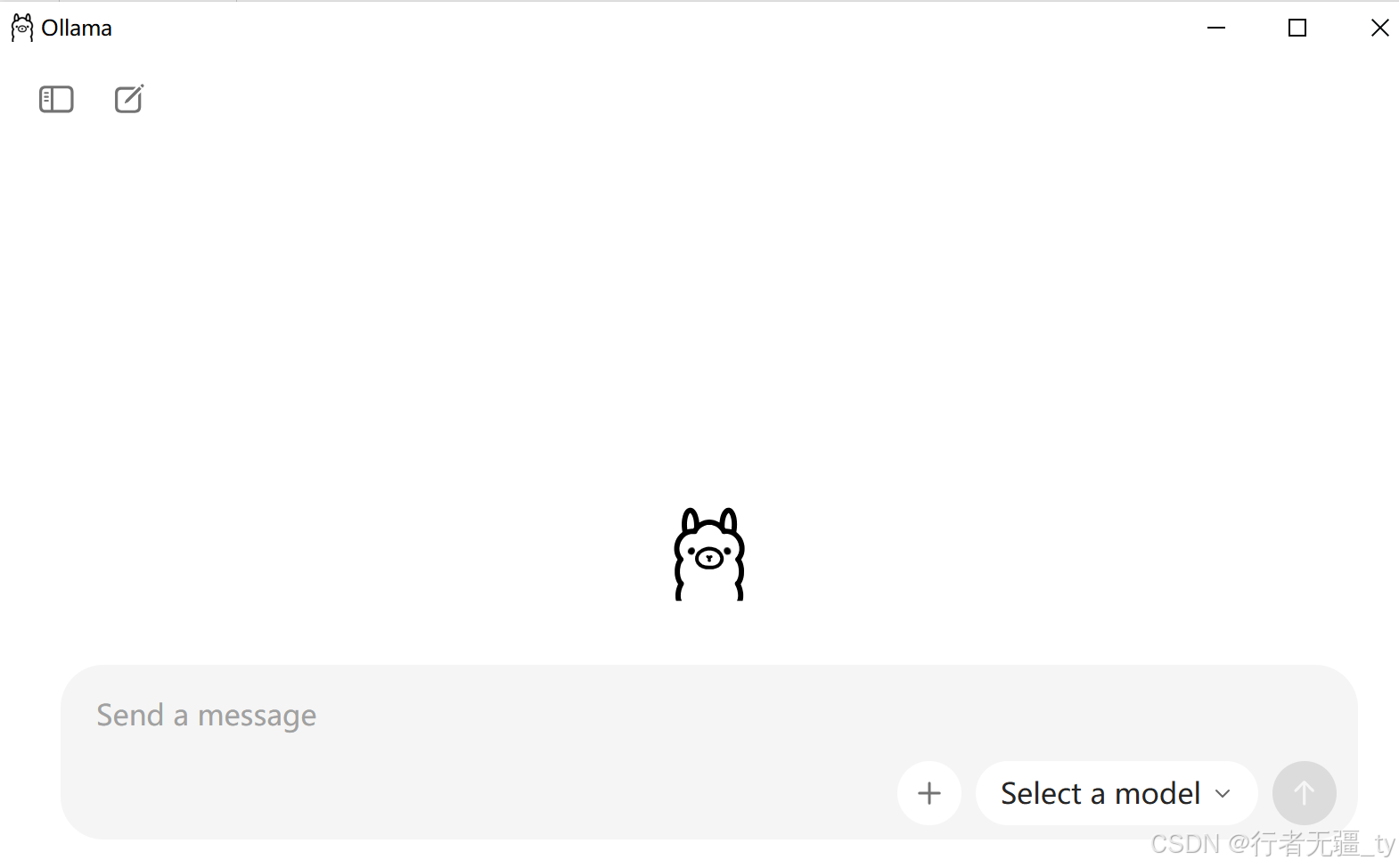
再验证一下,命令行输入 ollama --version 并回车,如果能看到版本号(例如 0.1.44),就说明安装成功了。
三、部署模型
在 CMD 中输入命令:
bash
ollama run gpt-oss:20bOllama 会自动开始下载并部署。你只需要等待即可,下载时间与模型大小有关,比如qwen3.5:4b需要下载3.4G。
四、使用模型
方式1:在 CMD 中输入命令:
bash
ollama run gpt-oss:20b当看到 >>> 的提示符时,你就可以像和朋友聊天一样,直接输入问题,模型就会开始回答你了。

方式2:可视化界面
ollama也提供了可视化界面,打开ollama,选择已经部署的模型(也可以选云上api模型),即可对话。