AI时代四项核心技能
- 掌握AI,成为同龄人中最好使用AI的那个人
- 练习敏捷训练,每周预留一个小时更新自己对AI的认识
- 坚持道德底线,拒绝用AI做监控武器和操控
- 停止亲信
你不知道的大语言模型训练原理
大模型训练其实是一条流水线
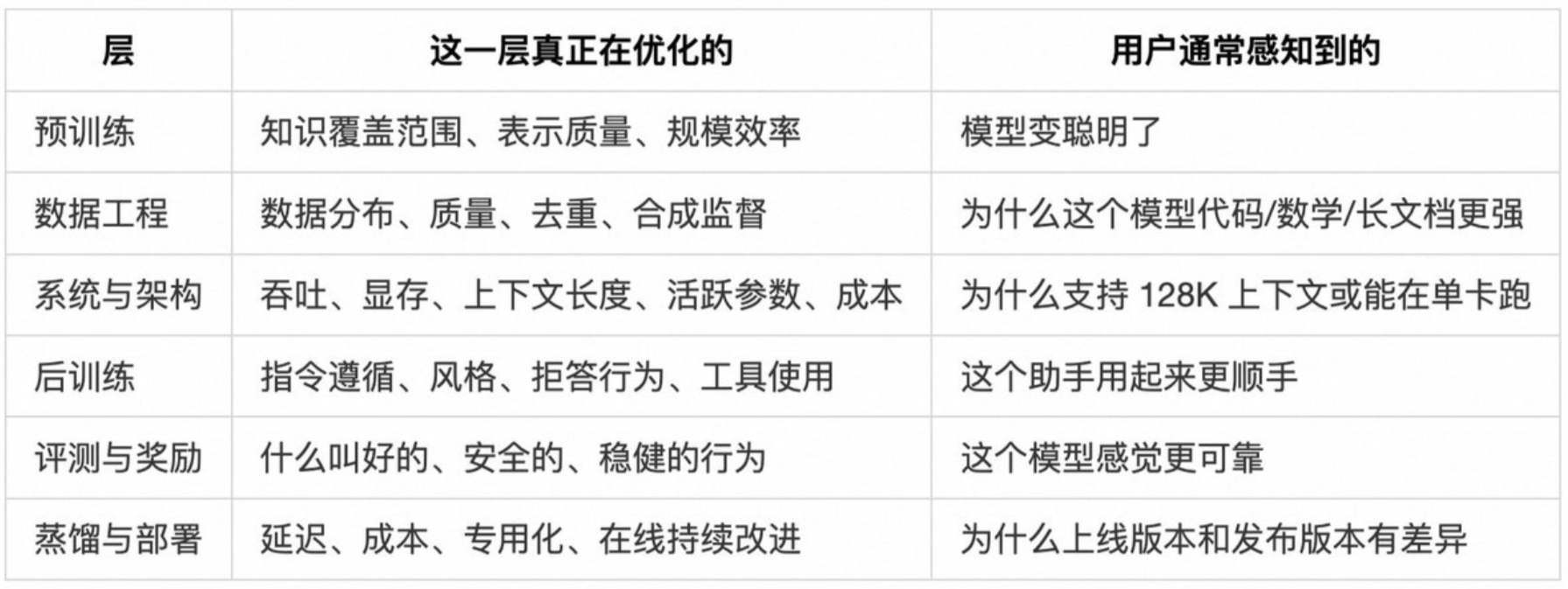
平时我们使用豆包,符合心意,是因为其后训练做到位了
完整的9个阶段
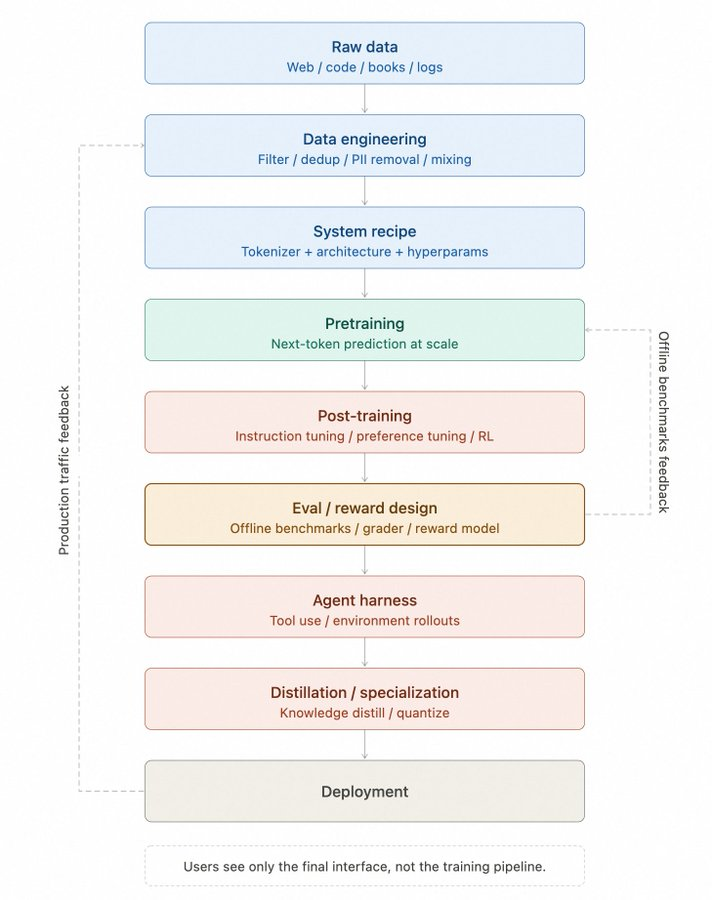
预训练模型的底座
预训练仍然是训练链路的起点,搞清楚它到底在做什么,才能理解后面的每一层都在补充什么。没有这一步,就没有语言建模能力,没有知识压缩,也没有后面那些能力迁移的空间。在工程上,它要做的不只是让模型学会预测下一个 token:把语言分布学进去,把大规模文本里的知识和模式压进参数,还要给后面的能力激活留出空间。下一个 token 预测只描述了训练形式,解释不了为什么规模上来之后,模型会突然多出一些之前没有的能力。
预训练更像是给模型能力打地基,决定知识范围、泛化潜力和模式归纳能力,也决定后训练有没有可以利用的空间。但听不听指令、配不配合用户、关键任务跑起来稳不稳,这些预训练都是管不到的。
数据配方决定模型能力
参数规模是过去几年大家比较的重要指标,但这两年更重要的东西叫「数据配方」。
这个过程表面看是清洗数据,实际上是完整的数据生产工程。网页、代码仓库、书籍、论坛这些原始数据,要先走完文本抽取、语言识别、质量过滤、隐私处理、安全过滤和去重,才能进入预训练,下图展示了完整的漏斗处理流程。
系统和架构的约束,训练前就要想清楚
很多人把训练理解成研究问题:目标函数怎么设,损失怎么降,模型结构怎么改。但真正的大模型训练里系统约束这一块非常重要,是分布式系统问题,而非单机上的深度学习问题。GPU 数量、显存带宽、并行策略、容错和成本,这些不能等到训练完才去调优,最开始就决定了你能训多大、支持多长上下文、能不能跑更复杂的后训练这些点。
后训练才决定用户真正感受到的差距
普通用户真正能感受到的很多提升,其实都发生在预训练之后。指令微调(Instruction tuning)用标注好的指令-回答数据对模型做监督训练。它改变的是回答方式,把怎么接任务、怎么组织输出、怎么像个配合的助手这些要求变成监督信号。一个基础模型也许已经具备不少潜在能力,但如果没有这一步,这些能力往往不会以用户期待的形式稳定冒出来。
- RLHF(基于人类反馈的强化学习)先模仿高质量回答,再用偏好比较做强化
- DPO(直接偏好优化)把这条路径缩短,直接从偏好对比里学,不需要单独训奖励模型
- RFT(强化微调)是工程上更容易落地的接口,把任务定义、grader 设计和奖励信号放到产品化流程里
Eval、Grader、Reward 在重新定义训练目标
具体到实现里,ORM 是结果奖励模型,只给最终答案打分,信号稀疏,成本低,适合先起步,但也更容易让模型走捷径。PRM 是过程奖励模型,给中间步骤打分,信号更密,对数学和代码推理通常更强,但标注和系统成本都高很多。OpenAI 在数学推理实验里看到,PRM 不只提高了正确率,也更容易把过程约束住,因为每一步都在被监督;问题也很直接,PRM 的成本通常是 ORM 的数倍,所以大多数真实系统还是先从 ORM 起步,只有在数学、代码、逻辑这类可验证任务里,才更有条件把 PRM 自动化,用程序去验证中间步骤,绕开人工标注瓶颈。
到了 Agent 训练,优化的不只是模型本身了
这时候训练对象不再只是一个会回答问题的模型,而是一个能规划、调用工具、接收反馈、在长任务里保持连贯的系统。于是训练栈也跟着变了,浏览器、终端、搜索、执行沙盒、内存系统、工具服务器、编排框架都开始进入训练系统。
更准确地说,harness 是包在模型外层的控制程序,这个概念不只属于 Agent 运行时,训练阶段同样有它:决定模型看到什么输入、以什么形式接收反馈、何时裁剪上下文、何时调工具。prompt construction、memory update、retrieval policy、context editing、tool orchestration 都在这里。环境也不再只是静态验证器,而是训练和部署都要直接面对的一层。
以后怎么看一个模型为什么变强了
后面再看一个模型为什么突然变强,可以先看三件事:
- 先看变化发生在预训练层,还是后面的训练流程。很多能力提升确实来自更强的预训练和更好的数据配方,但也有很多体感变化,其实主要出在后训练。模型会不会听指令、会不会用工具、回答风格稳不稳,常常不是多训一点语料自己长出来的。
- 再看提升来自哪一层:是权重和训练配方,还是 reward / eval / grader,还是 harness code 和 deployment loop。到了推理模型和 Agent 这一段,用户感受到的变强,很多时候已经不是基础模型单独做出来的结果。评测怎么设、奖励怎么打、工具环境稳不稳、retrieval 和记忆怎么组织、summary 和上下文怎么剪、上线时选了哪个 checkpoint,这些都会一起改掉最后的产品表现。
- 最后看上线版本在优化什么。有些版本是在追求更高上限,有些版本是在压成本、延迟和回归风险,还有些版本是在给某一类场景做专用化。发布版本本来就是产品决策,不是训练曲线最右边那个点,所以看模型更新时,顺手看它到底在优化什么,会更接近真实情况。
你真的了解Github吗?搜索篇
我们先对齐GitHub的认知,我认为:
1、GitHub是全世界最强的资源网站、代码网站和信息网站
2、GitHub是未来新的注意力窗口
我翻遍了全x,有很多GitHub项目推荐,但发现没有关于GitHub的入门文章,这篇文章旨在帮助小白可以熟练上手GitHub,先从最简单的搜索开始。
下文主要分享了GitHub项目信息的四种搜索方式,以及GitHub中都有什么信息。
GitHub项目四种搜索方式
1、闲逛搜索
第一步:主页点击三个横杠
第二步:点击explore
你会进入下图中的区域,在这里面,第一个区域是GitHub根据算法推荐的项目,第二个区域是trending榜单。
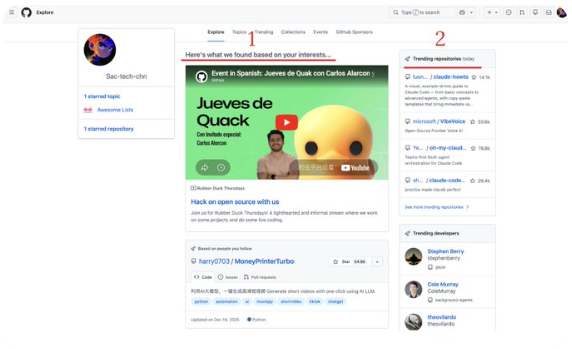
2、直接搜索 点击 Type 搜索,直接输入关键词搜索
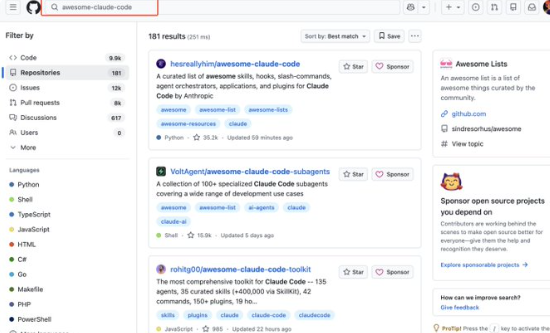
小tips: 搜索时添加"awesome" ,可以更快找到高质量资源汇总仓库,图中以「awesome-claude-code」为例子
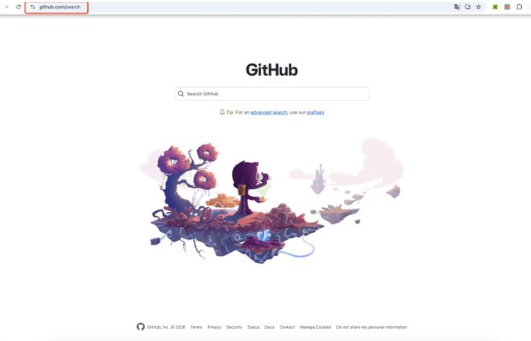
3、高级搜索(强烈推荐) 第一步:网页端直接输入「github.com/search 」
第二步:点击 advanced search
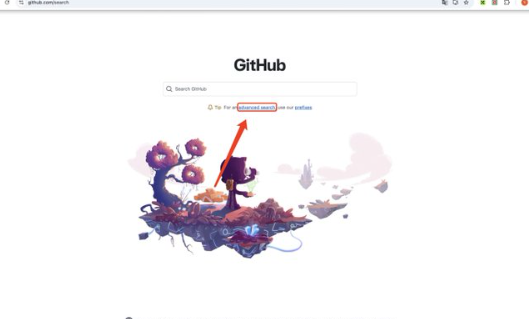
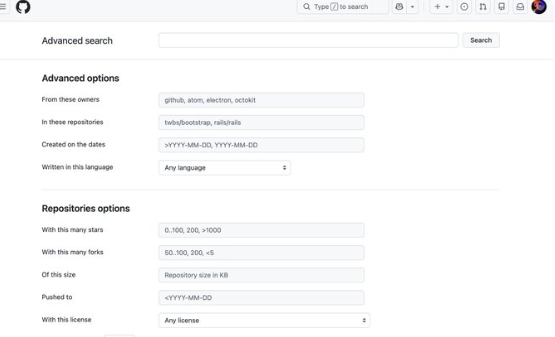
在高级搜索中,你可以限定关键词、作者、stars数等等,非常实用。
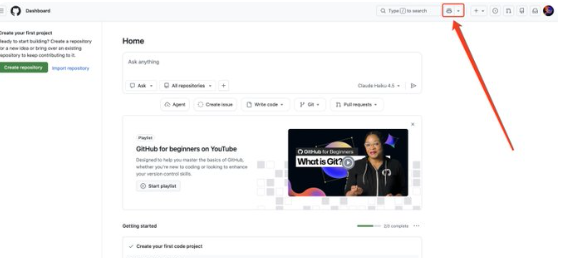
4、Copilot( GitHub 内置AI)
第一步:点击图标进入Copilot
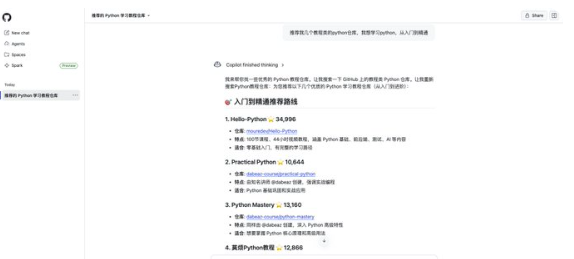
第二步:根据自己的需求搜索,图中以「推荐几个教程类python仓库」为例
GitHub中具体信息
1、 GitHub 是最强的资源网站 以学习资源为例,你几乎可以找到你任何想学习的内容,我们用python举例子:
GitHub中有一系列的python教程,从入门到精通,从理论到实战。
基础入门:
1、30-Days-Of-Python:
https://github.com/asabeneh/30-days-of-python
2、Python-100-Days:
https://github.com/jackfrued/Python-100-Days
算法与数据结构:
TheAlgorithms/Python:
https://github.com/TheAlgorithms/Python
数据科学与机器学习:PythonDataScienceHandbook:
https://github.com/jakevdp/PythonDataScienceHandbook
项目实战:
project-based-learning:
https://github.com/practical-tutorials/project-based-learning
2、 GitHub 是最强的信息网站 在GitHub中,信息资源是丰富与庞大的, 下面我列举了些例子: (1)大厂信息动态: 飞书、OpenAI、Anthropic等。比如以飞书为例,你可以看到任何关于飞书推出的最新 Github 项目
(2) 泛资源:你任何需要的资源都可以在这里搜索试试
1、雅思资料:
https://github.com/hefengxian/my-ielts
2、数字游民指南 :https://github.com/lukasz-madon/awesome-remote-job
3、tg频道整理:https://github.com/AZeC4/TelegramGroup
3、GitHub是最强的代码网站 GitHub 本身就是为开发者打造的,有着非常多的代码资源,这一块就不过多赘述了。