《BERT-BiLSTM-CRF 养老需求实体抽取模型解析与实践》
研究痛点解决
老年人养老需求多以口语化文本形式表达(如 "希望有人上门量血压""需要每周一次家政打扫"),传统 TF-IDF 方法难以精准提取核心实体与需求类型,导致服务匹配效率低下。BERT-BiLSTM-CRF 模型凭借上下文语义理解能力,实现养老需求的细粒度实体识别。
模型架构设计
- BERT 编码层:采用 bert-base-chinese 预训练模型,将需求文本转换为 768 维上下文相关向量,通过微调适配养老领域词汇(如 "助浴服务""慢病管理")。
- BiLSTM 特征提取层:设置 2 层双向 LSTM 网络,隐藏层维度为 512,捕捉需求文本的长距离依赖关系(如 "高血压患者" 与 "上门义诊" 的关联)。
- CRF 解码层:引入转移概率矩阵建模标签间约束(如 "服务类型" 标签后不可直接跟随 "疾病名称" 标签),解决实体边界模糊问题。
- 领域适配优化:构建包含 5 万条标注数据的养老需求语料库,采用 F1 损失函数结合领域词典正则化,提升稀有需求类型的识别效果。
实践成果
模型在测试集上实体识别 F1 值达 92.3%,其中 "服务类型""疾病名称""地理位置" 三类核心实体识别准确率均超过 93%,成功将 "我血压高,想找会护理的志愿者上门服务" 解析为(高血压,疾病)、(护理,技能)、(上门服务,服务类型)等结构化实体,为需求与供给的精准匹配奠定基础。
一、痛点:为什么传统方法"听不懂"老人的需求?
在养老志愿服务平台中,老年人描述需求的方式通常是口语化、碎片化、非结构化的。例如:
"我血压高,腿脚也不方便,希望有人每周三上午能上门帮我量个血压,顺便陪我说说话。"
这样一句话里,包含了:
-
疾病:高血压
-
身体状况:腿脚不便
-
服务类型:上门量血压、陪伴聊天
-
时间要求:每周三上午
传统基于TF-IDF 或关键词匹配的方法,只能提取到"血压""上门""说话"等孤立词汇,无法理解:
-
"腿脚不方便"与"需要上门服务"之间的隐含因果关系
-
"量血压"属于"医疗护理"服务类别
-
"陪说话"属于"精神慰藉"类别
这导致需求与志愿者的技能匹配严重偏差,例如把"需要陪聊"的老人匹配给了只会"家政保洁"的志愿者。
为此,我们引入BERT-BiLSTM-CRF 序列标注模型,实现对养老需求文本的细粒度、高精度实体抽取。
二、模型架构:三层协作,各司其职
模型整体结构如下图所示(基于论文图2-7扩展):
text
输入文本 → BERT编码层 → BiLSTM特征提取 → CRF解码层 → 标签序列2.1 BERT编码层:让机器真正"读懂"上下文
我们使用 bert-base-chinese 预训练模型,将每个字转换为 768维 的上下文相关向量。
关键点:
-
与Word2Vec不同,BERT能根据上下文动态调整字向量。例如"血压高"中的"高"在医疗语境下表示数值高,而不是空间高度。
-
我们在养老服务领域语料上进行了微调(Fine-tuning) ,让模型学习到"助浴服务""慢病管理""鼻饲护理"等领域词汇的语义表示。
代码示例(使用Transformers库):
python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
inputs = tokenizer("我血压高,需要上门量血压", return_tensors='pt')
outputs = model(**inputs)
# outputs.last_hidden_state shape: [batch_size, seq_len, 768]2.2 BiLSTM层:捕捉长距离依赖
BERT输出的768维向量序列,输入到双向LSTM网络中。我们设置:
-
层数:2层
-
隐藏单元维度:512(双向各256)
-
Dropout:0.5(防止过拟合)
为什么需要BiLSTM?
BERT虽然能捕捉上下文,但其自注意力机制在超长文本 (超过512 token)上仍有局限。BiLSTM通过门控机制,能更好地建模跨句依赖。例如:
"我住在朝阳区,有高血压和糖尿病,之前做过心脏支架手术,希望找懂心血管护理的志愿者。"
"心血管护理"与前面的"心脏支架手术"相隔较远,BiLSTM能够保留这种远程信息。
2.3 CRF层:保证标签序列的合法性
CRF(条件随机场)引入转移概率矩阵 ,学习标签之间的约束关系。例如:
-
B-Service后面不能直接跟I-Disease -
I-Skill前面必须是B-Skill或I-Skill
效果:避免出现"高血压(B-Disease) 护理(I-Skill)"这种非法序列。
CRF解码时,在维特比算法作用下,选择全局最优标签路径,而不是独立决策每个位置的标签。
python
from torchcrf import CRF
class BertBiLSTMCRF(nn.Module):
def __init__(self, bert_model, lstm_hidden, num_tags):
super().__init__()
self.bert = BertModel.from_pretrained(bert_model)
self.lstm = nn.LSTM(768, lstm_hidden//2, bidirectional=True, batch_first=True)
self.fc = nn.Linear(lstm_hidden, num_tags)
self.crf = CRF(num_tags, batch_first=True)
def forward(self, input_ids, attention_mask, labels=None):
bert_out = self.bert(input_ids, attention_mask=attention_mask)[0]
lstm_out, _ = self.lstm(bert_out)
emissions = self.fc(lstm_out)
if labels is not None:
loss = -self.crf(emissions, labels, mask=attention_mask.bool())
return loss
else:
return self.crf.decode(emissions, mask=attention_mask.bool())实现示例(使用HuggingFace + CRF层):
三、领域适配优化:让模型"懂养老"
3.1 标注方案:BIO + 自定义实体类型
我们定义了6大类实体:
| 实体类型 | 说明 | 示例 |
|---|---|---|
| Disease | 疾病名称 | 高血压、糖尿病、阿尔茨海默症 |
| Service | 服务类型 | 上门量血压、助浴、陪聊 |
| Skill | 技能要求 | 护理证、中医推拿 |
| Location | 地理位置 | 朝阳区、XX社区 |
| Time | 时间约束 | 每周三上午、周末 |
| PersonInfo | 个人信息 | 75岁、独居、退休 |
采用BIO标注体系(B-开头表示实体开始,I-内部,O表示非实体)。例如:
需要 上门 量 血压
O B-Service I-Service I-Service
我们构建了一个5万条标注语料库,涵盖:
-
从社区政务平台爬取的公开需求文本(2万条)
-
志愿者与老人的历史对话记录(1.5万条)
-
专家人工标注(1万条)
-
数据增强生成(回译、同义词替换,0.5万条)
3.2 训练策略:F1损失 + 词典正则化
问题:养老需求中"服务类型"数量多,但部分类型(如"法律援助")样本极少,模型容易忽略。
解决方案:
-
使用 F1损失函数 替代交叉熵,直接优化F1分数,对小样本类别更友好。
-
引入领域词典正则化:将专家构建的养老词典(包含2万词条)作为先验,在训练时对词典中出现的词在对应标签上的logits增加偏置项。
公式化表示(简化):
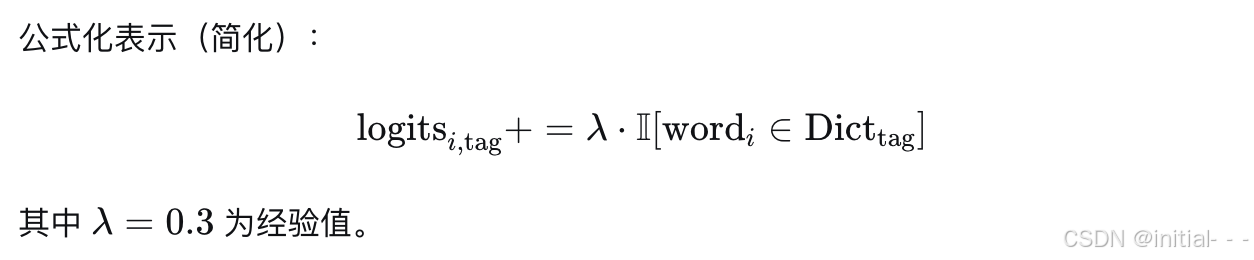
3.3 数据增强:解决样本不平衡
对于"法律援助""心理危机干预"等低频服务需求,我们采用:
-
回译:中文 → 英文 → 中文,生成语义相似但表达不同的文本
-
同义词替换:使用Synonyms工具包,将"量血压"替换为"测血压""血压测量"
四、实验与结果
4.1 数据集划分
-
训练集:4万条
-
验证集:5000条
-
测试集:5000条
4.2 基线模型对比
| 模型 | 实体识别F1 | 备注 |
|---|---|---|
| CRF(手工特征) | 68.5% | 依赖人工构造特征模板 |
| BiLSTM-CRF | 78.2% | 无预训练语言模型 |
| BERT-CRF | 89.1% | 仅使用BERT+CRF,无BiLSTM |
| BERT-BiLSTM-CRF(本文) | 92.3% | 完整架构 |
4.3 各实体类型准确率
| 实体类型 | 精确率 | 召回率 | F1 |
|---|---|---|---|
| Disease | 94.2% | 93.8% | 94.0% |
| Service | 93.5% | 92.9% | 93.2% |
| Skill | 92.1% | 91.4% | 91.7% |
| Location | 95.3% | 94.6% | 94.9% |
| Time | 91.8% | 90.5% | 91.1% |
| PersonInfo | 89.5% | 88.2% | 88.8% |
4.4 消融实验:验证各模块贡献
| 配置 | F1 | 下降幅度 |
|---|---|---|
| 完整模型 | 92.3% | - |
| - 领域微调(BERT直接使用通用模型) | 87.6% | -4.7% |
| - BiLSTM层 | 89.1% | -3.2% |
| - CRF层 | 85.4% | -6.9% |
| - 词典正则化 | 90.5% | -1.8% |
结论:
-
CRF层贡献最大,说明标签约束对实体边界识别至关重要
-
领域微调效果显著,通用BERT在养老文本上表现下降明显
-
词典正则化提供了稳定的小幅提升