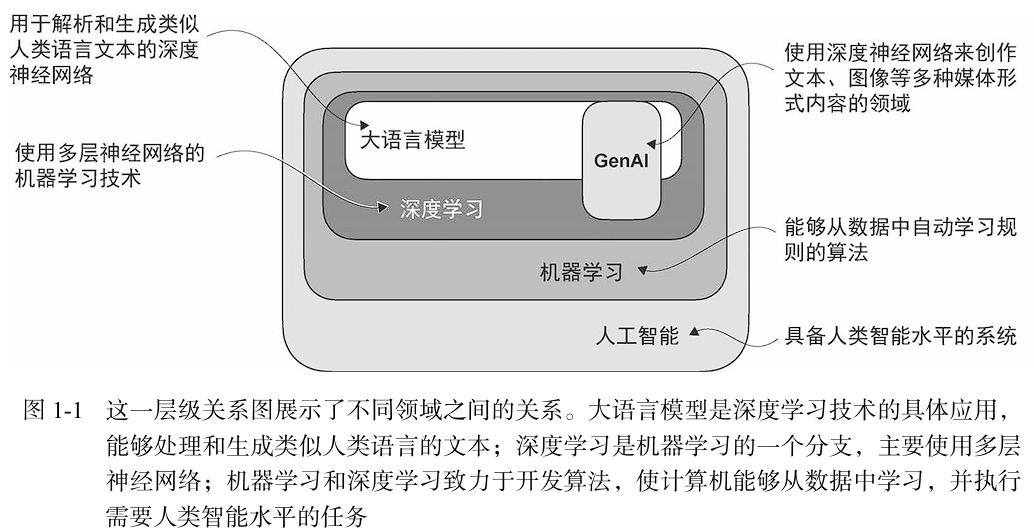
1.大模型的关系
- 传统的机器学习需要人工进行特征提取,对于提取哪些重要特征,需要的是人类专家挑选出最相关的特征。这是相当耗费时间和精力,条件限制多。
- 深度学习并不依赖人工提取的特征,这意味着不再需要由人类专家为模型识别和选择最相关
的特征。 - 无论是传统的机器学习还是用于垃圾邮件分类任务的深度学习,仍然需要收集标签(比如垃圾邮件或非垃圾邮件,这些标签通常由专家或用户提供)。即深度学习的训练数据集仍然是需要有标签的,至少当下的有监督学习是这样的。
2.构建和使用大模型的各个阶段
主要分为预训练 pre-training 与微调 fine-tuning两个阶段。
理解一个计算机概念始终可以从输入输出的角度理解,输入是什么,输出是什么,然后你就能描述这个概念实现的作用是什么!不要过于只注重具象理解
- 预训练:这里的预不要理解为未被训练,而是训练得到基础能力的基础模型。"预训练"中的"预"表明它是模型训练的初始阶段,此时模型会在大规模、多样化的数据集上进行训练,以形成全面的语言理解能力。
- 微调:以预训练模型为基础,微调阶段会在规模较小的特定任务或领域数据集上对模型进行针对性训练,以进一步提升其特定能力。
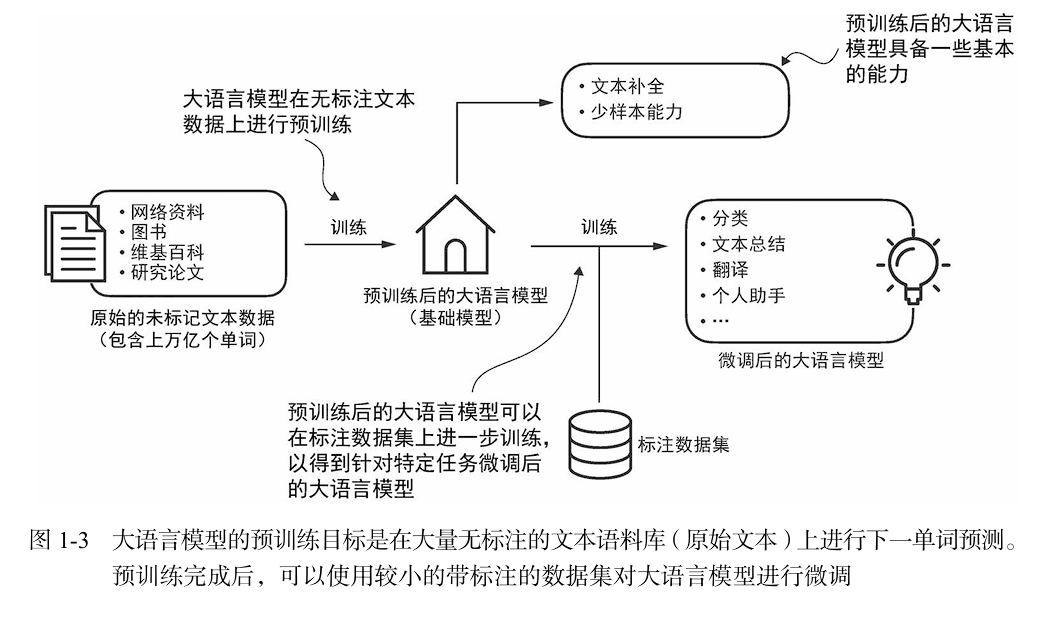
微调分为: - 指令微调:在指令微调(instruction fine-tuning)中,标注数据集由"指令−答案"对(比如翻译任务中的"原文−正确翻译文本")
组成。 - 分类任务微调:在分类任务微调(classification fine-tuning)中,标注数据集由文本及其类别标签(比如已被标记为"垃圾邮件"或"非垃圾邮件"的电子邮件文本)组成
可以理解为机器学习中有监督学习的逻辑回归任务和分类任务。
3.Transformer架构介绍
3.1Transformer核心架构
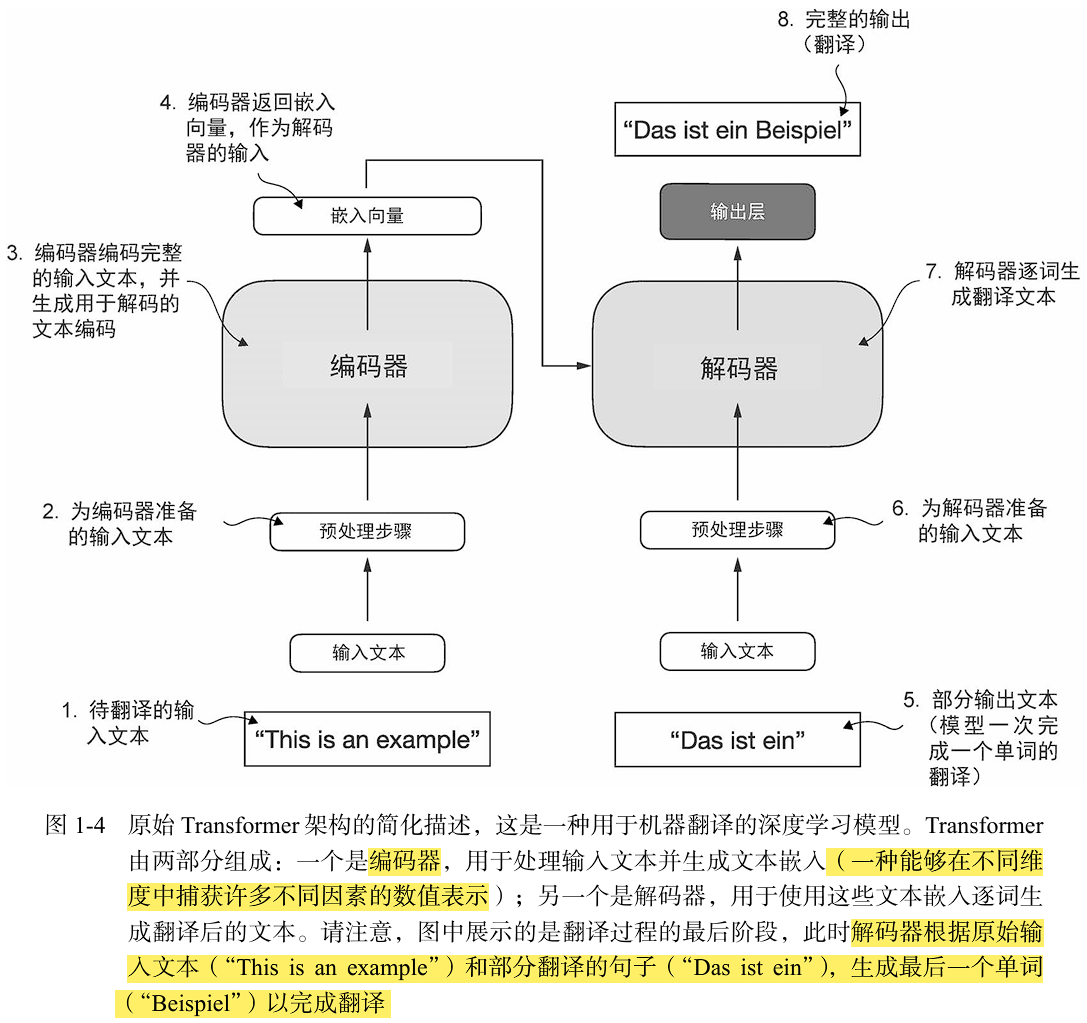
- 编码器:输入文本,编码+计算生成一系列数值和向量,包含上下文信息。
- 解码器:接收编码器输入的向量,生成预测文本。
以翻译任务为例,编码器将源语言的文本编码成向量,解码器则解码这些向量以生成目标语言的文本。编码器和解码器都是由多层组成,这些层通过自注意力机制连接。关于如何对输入进行预处理和编码,我们将在后续章节中逐步解答。
3.2 BERT与GPT区别
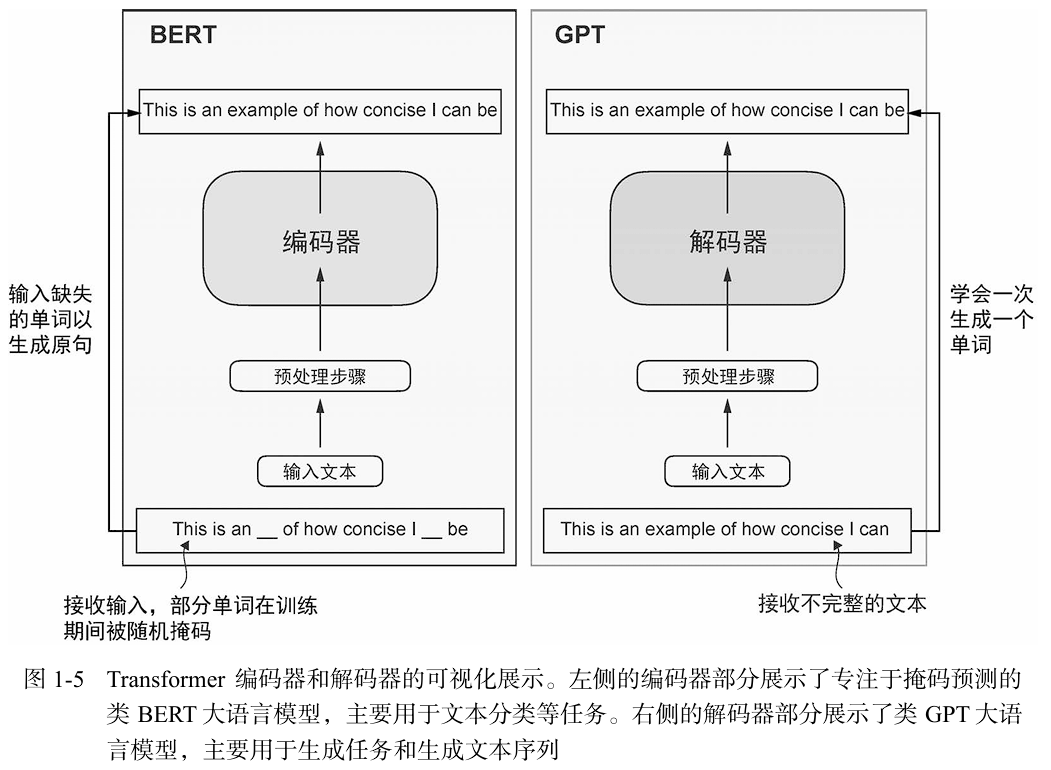
- BETR:测给定句子中被掩码的词。这种独特的训练策略使BERT在情感预测、文档分类等文本分类任务中具有优势。
- GPT:侧重于原始Transformer 架构的解码器部分 。GPT 模型主要被设计和训练用于文本补全(text completion)任务,但它们表现出了出色的
可扩展性。这些模型擅长执行零样本学习任务和少样本学习任务。
零样本学习(zero-shot learning)是指在没有任何特定示例的情况下,泛化到从未见过的任务,而少样本学习(few-shot learning)是指从用户提供的少量示例中进行学习。
4.GPT的架构
GPT模型:仅在相对简单的下一单词预测任务上进行了预训练。

现在的大模型,预训练常用自监督学习,生成推理常用自回归模型,两者搭配撑起 LLM 能力。
- 自监督学习:区别于有监督学习(要人打标签,比如图片标猫 / 狗)、无监督学习(单纯聚类),自己给自己造任务、造标签。
- 自回归模型:自回归模型将之前的输出作为未来预测的输入。因此,在 GPT中,每个新单词都是根据它之前的序列来选择的,这提高了最终文本的一致性。核心逻辑:把序列(文字、语音、时间序列)当成前后关联的链条,数学上满足:当前位置的输出,只由之前所有位置的已知内容决定。
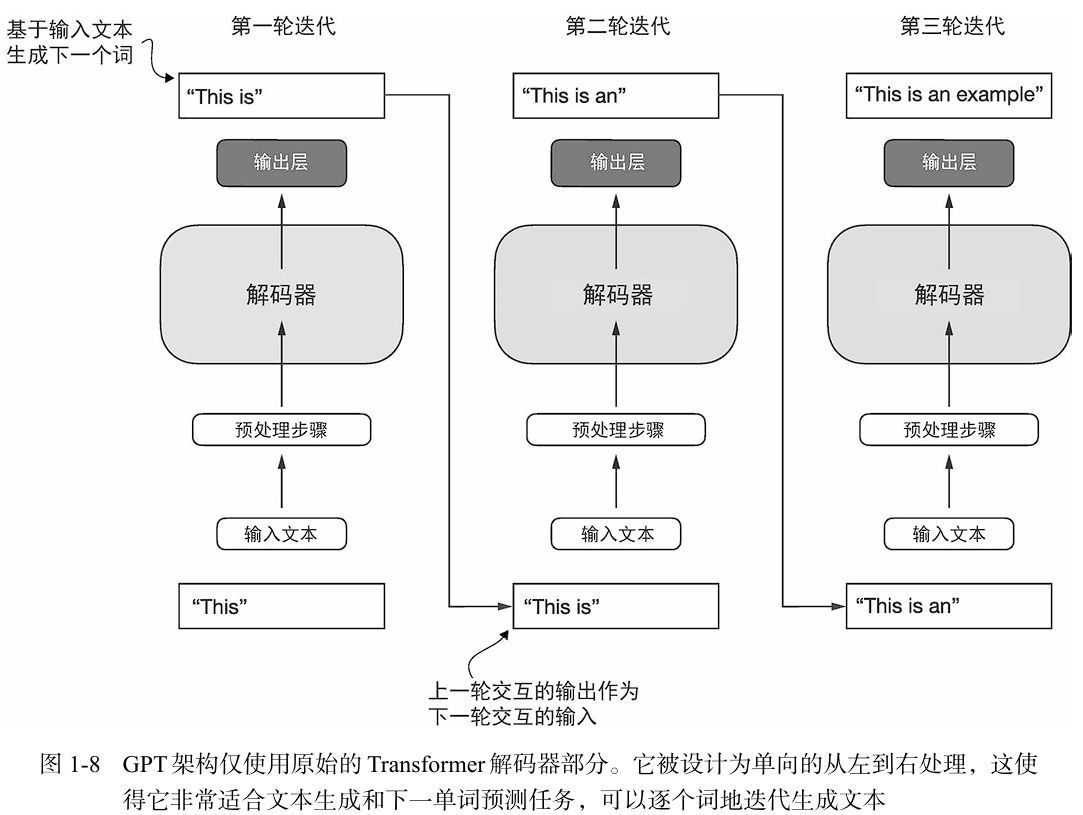
GPT-3等架构的规模远超原始Transformer模型。例如,原始的Transformer模型将编码器模
块和解码器模块重复了6次,而GPT-3总共有96层Transformer和1750亿个参数。
- 涌现:模型能够完成未经明确训练的任务的能力。
这种能力并非模型在训练期间被明确教授所得,而是其广泛接触大量多语言数据和各种上下文的自然结果。即使没有经过专门的翻译任务训练,GPT模型也能够"学会"不同语言间的翻译模式并执行翻译任务。这充分体现了这类大规模生成式语言模型的优势和能力。
因此,无须针对不同的任务使用不同的模型,我们便可执行多种任务。
5.构建大语言模型
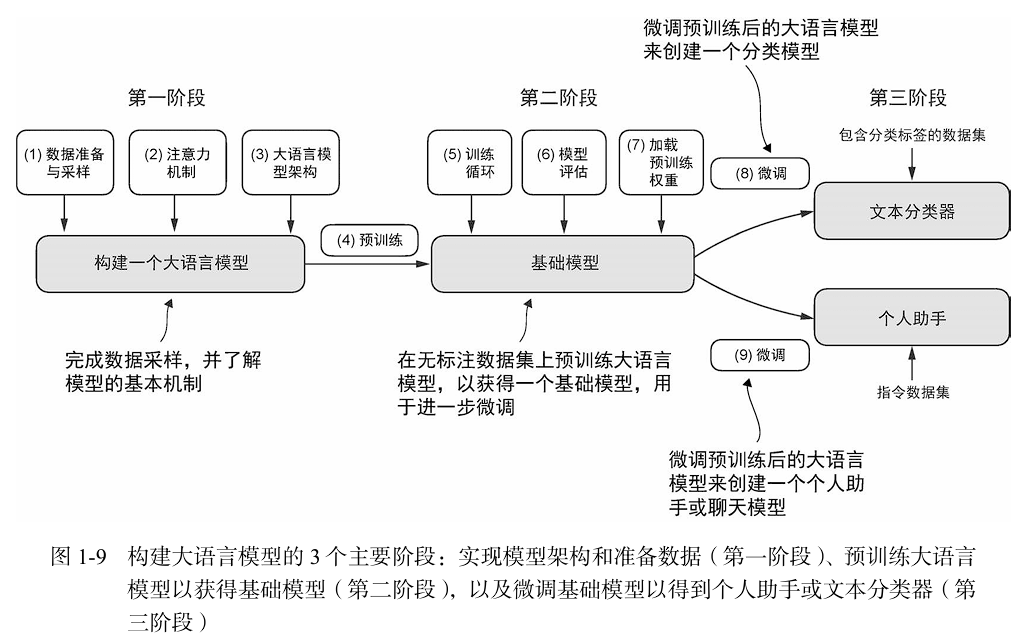
- 第一阶段,我们将学习数据预处理的基本流程,并着手实现大语言模型的核心组件------注
意力机制。 - 第二阶段,我们将学习如何编写代码并预训练一个能够生成新文本的类GPT大语言模型。
同时,我们还将探讨评估大语言模型的基础知识,这对于开发高效的自然语言处理系统至关
重要。 - 第三阶段,我们将对一个预训练后的大语言模型进行微调,使其能够执行回答查询、
文本分类等任务------这是许多真实应用程序和研究中常见的需求。
小结
- 大语言模型彻底革新了自然语言处理领域。在此之前,自然语言处理领域主要采用基于明确规则的系统和较为简单的统计方法。而如今,大语言模型的兴起为这一领域引入了基于深度学习的新方法,在理解、生成和翻译人类语言方面取得了显著的进步。
- 现代大语言模型的训练主要包含两个步骤。
- 首先,在海量的无标注文本上进行预训练,将预测的句子中的下一个词作为"标签"。
- 随后,在更小规模且经过标注的目标数据集上进行微调,以遵循指令和执行分类任务。
- 大语言模型采用的是基于Transformer的架构。这一架构的核心组件是注意力机制,它使得大语言模型在逐词生成输出时,能够根据需要选择性地关注输入序列中的各个部分。
- 原始的Transformer架构由两部分组成:一个是用于解析文本的编码器,另一个是用于生成文本的解码器。
- 专注于生成文本和执行指令的大语言模型(如GPT-3和ChatGPT)只实现了解码器部分,从而简化了整个架构。
- 由数以亿计的语料构成的大型数据集是预训练大语言模型的关键。
- 尽管类GPT大语言模型的常规预训练任务是预测句子中的下一个词,但它们展现出了能够完成分类、翻译或总结文本等任务的"涌现"特性。
- 当一个大语言模型完成预训练后,该模型便能作为基础模型,通过高效的微调来适应各
类下游任务。 - 在自定义数据集上进行微调的大语言模型能够在特定任务上超越通用的大语言模型。
结语:理解一个新概念,要用合适自己的思维方式,然后反复重复!