我们正迎来 AI Agent 的时代。在这个时代,其核心能力在于大型语言模型对工具调用的掌握。这如同为原本具备超级智慧的智能体赋予了行动的双手,使其能力边界得以大幅拓展。
然而,大模型在实际应用落地时,难免会遇到其能力边界、瓶颈或表现不足的情况。Harness Engineering 正是在此背景下应运而生的一种工程化思路。它主张:当模型自身能力受限或犯错时,优先考虑通过精心设计和构建一套围绕大模型的环境与机制来弥补不足、扩展功能。这套环境的核心目标,是作为桥梁和扩展器,主动、系统地提升大模型的表现和能力范围。
而 Claude code 就是最好的 Harness Engineering 实践。
一. Context 系统
1.1 上下文构建
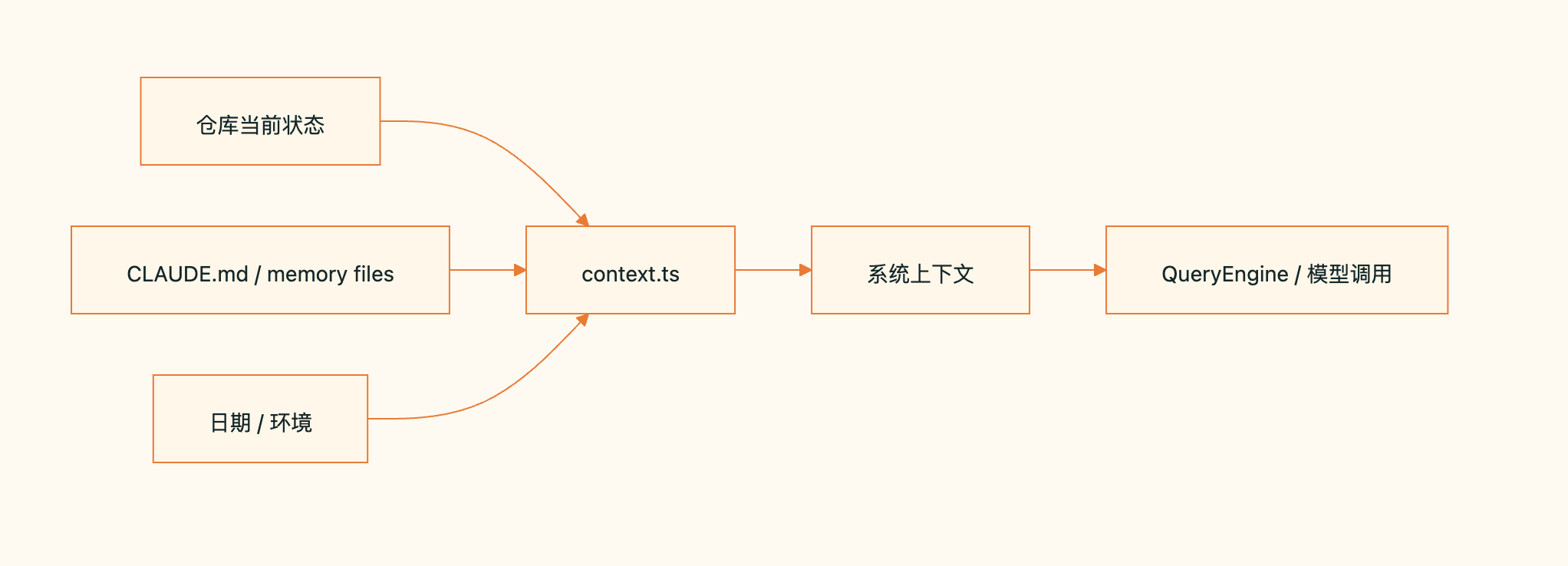
仓库状态 : 通过 Git 来管控。 它会尝试收集:当前分支,主分支,工作区状态,最近提交 ,Git 用户信息。
用户与项目约束 : 通过 Claude.md 和 memory 文件聚焦在编码规范,库结构约束 ,特殊命令 ,团队约定 ,某些需要避免的操作。
日期/环境 : 交代所处环境时间,避免多余思考。
从源码可以看出,claude code 的上下文机制
- 最大程度交代清楚约束,环境,状态
- 精简到极致的提示词
1.2 上下文压缩机制
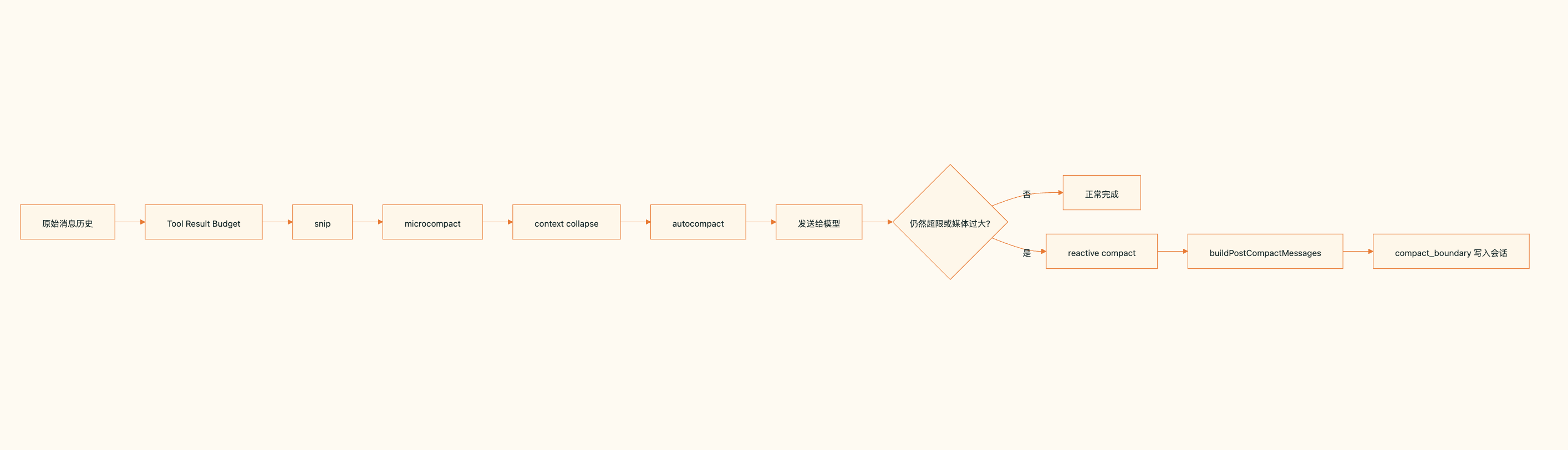
Claude code上下文压缩机制是层层递进的,他会在上下文的额度内尽可能的保证历史消息。它们的执行顺序:
- 先裁掉过大的工具结果
- 再做 snip
- 再做 microcompact
- 再投影 context collapse
- 最后才尝试 autocompact
也就是说,Claude Code 并不急着把旧历史粗暴压成一段摘要,而是优先尝试保留更多细节。
| 机制 | 触发方式 | 作用粒度 | 核心文件 |
|---|---|---|---|
| Snip | 消息边界检测 | 移除旧消息 | query.ts |
| Microcompact | 时间间隔 / 缓存策略 | 清除工具结果内容 | services/compact/microCompact.ts |
| Autocompact | Token 阈值 | 整段对话 → 摘要 | services/compact/autoCompact.ts |
| Context Collapse | Token 百分比 | 分层归档(实验性) | services/contextCollapse/ |
1. Snip --- 历史消息截断
触发 :特性门 HISTORY_SNIP,检测到 snip boundary message 时。
做什么:直接移除消息列表里的旧消息(不生成摘要),保留最近的对话。
与其他机制的关系:
- 返回
tokensFreed,传给 autocompact 做阈值补偿------即 snip 已删掉的 token 不再计入 autocompact 的触发判断。
2. Microcompact --- 工具结果清除
两条独立路径,按顺序尝试,触发一条即短路返回:
路径 1:时间基础微压缩(Time-Based)
触发条件 :距上次 assistant 消息 ≥ 60 分钟(GrowthBook gate tengu_slate_heron)。
逻辑 :直接将旧工具结果替换为 [Old tool result content cleared],保留最近 5 条。
为什么:服务端缓存 TTL 为 1 小时,超时后缓存前缀失效,需重写。提前清除旧内容可减少重写量。
路径 2:缓存编辑微压缩(Cached)
触发条件 :特性门 CACHED_MICROCOMPACT + 主线程 + 模型支持。
逻辑:
- 不修改本地消息 ,而是生成
CacheEditsBlock - 在 API 请求层附加
cache_reference/cache_edits - 服务端用编辑后的版本,本地消息保持不变(UI 回滚不受影响)
可压缩的工具类型:FileRead、Shell、Grep、Glob、WebSearch、WebFetch、FileEdit、FileWrite。
3. Autocompact --- 整段对话总结
阈值计算
有效上下文窗口 = 模型上下文窗口 - min(最大输出 tokens, 20000)
Autocompact 阈值 = 有效上下文窗口 - 13000(缓冲)
可通过环境变量覆盖:
CLAUDE_CODE_AUTO_COMPACT_WINDOW ← 覆盖上下文窗口大小
CLAUDE_AUTOCOMPACT_PCT_OVERRIDE ← 按百分比设置阈值触发判断(shouldAutoCompact)
以下任一条件会阻止 autocompact:
querySource是session_memory或compact(防止递归)- Context Collapse 已启用(互斥,见下文)
REACTIVE_COMPACT模式下配置了只反应不主动
4. Context Collapse --- 分层归档(实验性)
特性门 :CONTEXT_COLLAPSE
核心差异:
- Autocompact → 单一综合摘要,丢失细节
- Context Collapse → 分层归档,保留粒度化上下文
与 Autocompact 的关系:完全互斥
typescript
// autoCompact.ts 注释原文:
// Collapse IS the context management system when it's on ---
// the 90% commit / 95% blocking-spawn flow owns the headroom problem.
// Autocompact firing at ~93% sits right between collapse's
// commit-start (90%) and blocking (95%), would race collapse
// and nuke granular context that collapse was about to save.错误恢复:API 返回 413 时,先尝试 Collapse 排干队列,失败后 fallback 到 Reactive Compact。
二. Memory 系统
架构分层
5 层,从临时到持久,从个人到团队:
| 层级 | 名称 | 作用域 | 存储位置 |
|---|---|---|---|
| 0 | 上下文窗口(临时记忆) | 当前对话内 | 内存,mutableMessages[] |
| 1 | CLAUDE.md | 代码库级 | 项目目录内,版本控制 |
| 2 | Session Memory | 跨会话级 | ~/.claude/sessions/<id>/session_memory.md |
| 3 | Auto Memory | 项目级(个人) | ~/.claude/projects/<repo>/memory/ |
| 4 | Team Memory | 项目级(团队) | 同上 memory/team/ + 服务器同步 |
加载顺序(每次处理消息时)
启动时:
CLAUDE.md 文件树扫描 → 合并注入 system prompt
loadMemoryPrompt() → auto/team 记忆目录指导注入
每条消息处理时:
findRelevantMemories() → 扫描 200 文件 → Sonnet 选 5 个 → nested_memory 注入
回合结束时:
extractMemories forked agent → 判断是否写入 Auto Memory
session memory forked agent → 判断是否更新会话摘要
后台(Team Memory):
watcher 监听本地 team/ 变化 → push/pull 与服务器同步
### 第 0 层:上下文窗口 --- 临时记忆层
**本质**:`QueryEngine` 中的 `mutableMessages[]` 数组,当前对话的所有消息直接存在内存里,每次 API 调用都完整发送。
**特点**:
- 无需任何检索机制,模型天然"知道"
- 受上下文窗口大小硬限制(不同模型不同,通常 200K tokens)
- 会话结束即消失,不持久化
**与其他层的关系**:窗口快满时触发压缩系统(Microcompact / Autocompact),压缩后丢失的内容由 Session Memory 补救注入。第 1 层:CLAUDE.md --- 代码库文档层
本质:普通 Markdown 文件,随代码版本控制。
读取时机 :每次启动时,getUserContext() 调用 getMemoryFiles() 扫描项目目录树,自动发现并合并所有层级的 CLAUDE.md(根目录 + 子目录)。
| 层级 | 范围 | 位置 | 是否共享 | 优先级 | 典型用途 |
|---|---|---|---|---|---|
| 1 | 用户级(Global) | ~/.claude/CLAUDE.md |
❌ 不共享 | ⭐ 最低 | 个人习惯、编码偏好 |
| 2 | 仓库级(Repo Root) | <repo>/CLAUDE.md |
✅ 共享 | ⭐⭐ | 项目整体规范、架构说明 |
| 3 | 子目录级(Directory Scoped) | <repo>/subdir/CLAUDE.md |
✅ 共享 | ⭐⭐⭐ 最高 | 模块级规则、局部约束 |
写入方式:人工维护(或 Claude 应你要求写入)。
用途:项目约定、架构说明、行为规范。这是给模型的"说明书",团队成员共享。
第 2 层:Session Memory --- 会话摘要层
本质:当前会话的滚动摘要,防止长对话丢失早期上下文。
触发条件(满足之一):
- 对话达到 10,000 tokens → 初始化
- 初始化后,每增长 5,000 tokens + 3 次工具调用 → 更新
运行方式:post-sampling hook 中启动一个 forked agent,读取当前消息,更新摘要文件,不阻塞主流程。
生命周期:会话结束即冻结,不跨会话累积。
与压缩的关系:Session Memory 是 Autocompact 的"优先选项"------autocompact 触发时先尝试用 session memory 替代传统摘要,保留更多结构。
第 3 层:Auto Memory --- 项目持久记忆层
本质 :跨会话的个人知识库,核心是 MEMORY.md 索引 + 多个内容文件。
目录结构:
~/.claude/projects/<sanitized-repo-path>/memory/
├── MEMORY.md ← 索引,200 行上限,每行一条指针
├── user_role.md
├── feedback_testing.md
├── project_deadline.md
└── reference_linear.md记忆文件格式:
yaml
---
name: 记忆标题
description: 一行描述(用于相关性筛选)
type: user | feedback | project | reference
---
详细内容...四种类型:
| 类型 | 存什么 | 示例 |
|---|---|---|
user |
用户画像、偏好、背景 | "用户是数据科学家,Go 专家但不熟悉前端" |
feedback |
行为规范、做事方式 | "不要在每次回复末尾总结,用户能读 diff" |
project |
项目状态、决策、截止日期 | "周四后冻结 merge,mobile 发版" |
reference |
外部资源指针 | "Linear 项目 INGEST 跟踪 pipeline bug" |
写入方式:
- 用户显式要求("帮我记住...")
extractMemories自动提取:回合结束且无 tool calls 时,forked agent 自动判断是否有值得保存的内容
读取方式(每次消息处理时):
- 扫描 memory 目录最多 200 个文件
- 读取每个文件的 frontmatter description
- 用 Claude Sonnet 通过
sideQuery()选出最相关的最多 5 个 - 作为
nested_memoryattachment 注入对话
第 4 层:Team Memory --- 团队共享层
本质:Auto Memory 的团队扩展,通过服务器同步,repo 内所有成员共享。
存储:
~/.claude/projects/<repo>/memory/team/
├── MEMORY.md ← 团队索引
├── team_api_patterns.md
└── team_deployment_rules.md启用条件 :Auto Memory 开启 + Feature Flag tengu_herring_clock(目前非默认开启)。
2.2 记忆系统 vs 压缩系统的关系
两者共同解决同一个问题:上下文窗口有限。
上下文窗口满了
↓
两条出路
出路 A:压缩(腾空间,丢细节)
└─ Microcompact → 只清工具结果内容
└─ Autocompact → 整段压缩成摘要
└─ Snip → 直接删旧消息
出路 B:记忆(提前存下来,需要时取回)
└─ Session Memory → 会话内摘要,compact 后重新注入
└─ Auto Memory → 跨会话价值内容,下次对话按需取回三个关键交叉点:
-
Autocompact 优先用 Session Memory 替代传统摘要
→ Session Memory 保留更多结构,比模型临时生成的摘要质量更高。
-
Session Memory 是 compact 的"救生圈"
→ 没有它,compact 后早期上下文永久丢失;有了它,摘要在 compact 后重新注入,连续性得以保留。
-
Auto Memory 在 compact 后也会重新注入
→
postCompactCleanup清除用户上下文缓存,下次构建 prompt 时重新扫描 memory 目录,长期记忆在压缩后不丢失。
一句话:压缩是被动应对窗口满,记忆是主动保留有价值内容,Session Memory 是两者的桥梁。
三. Tools 系统
3.1. Tool 负责定义统一协议
Tool.ts 不是某个具体工具实现,而是全系统的工具抽象层。
这里最重要的价值有两个:
- 统一工具的输入、输出、上下文和权限语义
- 给所有工具提供相同的运行契约
Tool 没有继承体系 。它是一个纯 TypeScript 接口(duck typing),所有工具都是平等的对象字面量 ,通过 buildTool() 工厂函数构建,,它提供失败安全的默认值:
typescript
const TOOL_DEFAULTS = {
isEnabled: () => true,
isConcurrencySafe: () => false, // 保守:假设不安全
isReadOnly: () => false, // 保守:假设有写操作
isDestructive: () => false,
checkPermissions: () => ({ behavior: 'allow' }),
userFacingName: () => def.name,
}3.2 Tools 的核心分类
核心构成
Tool<Input, Output, Progress> ← 唯一接口,无子类
│
│ buildTool(def) ← 唯一构建方式(填充安全默认值)
│
├── 内置工具(Built-in) ← 编译进 CLI,静态注册
│ ├── 元工具(管理其他工具)
│ │ ├── AgentTool ← 生成子代理,子代理有自己的工具池
│ │ ├── SkillTool ← 执行 Skill,单一实例,内部动态分发
│ │ └── ToolSearchTool ← 按需搜索推荐工具给模型
│ │
│ ├── 核心 I/O 工具
│ │ ├── BashTool
│ │ ├── FileReadTool / FileEditTool / FileWriteTool
│ │ ├── GlobTool / GrepTool
│ │ └── NotebookEditTool
│ │
│ ├── 任务管理工具(条件加载)
│ │ └── TaskCreateTool / TaskGetTool / TaskUpdateTool / TaskListTool...
│ │
│ └── 其他条件工具(Feature Flag 控制)
│ ├── REPLTool ← 启用时隐藏 REPL_ONLY_TOOLS(Bash等)
│ ├── CronCreateTool ← feature('AGENT_TRIGGERS')
│ ├── SleepTool ← feature('PROACTIVE') || feature('KAIROS')
│ └── RemoteTriggerTool / MonitorTool ...
│
├── MCP 工具(Dynamic) ← 运行时动态注入,appState.mcp.tools
│ ├── 模板: MCPTool ← buildTool() 创建的基础对象
│ └── 每个连接的 MCP Server × 每个工具
│ → {...MCPTool, name, call(), isMcp: true, mcpInfo: {...}}
│ (对象展开覆盖,不是继承)
│
└── 合成工具(Synthetic) ← 非交互会话按需创建
└── SyntheticOutputTool ← createSyntheticOutputTool(schema)
(WeakMap 缓存,每个 schema 一个实例)工具分类 :
| 工具 | 本质 |
|---|---|
| BashTool | 系统调用封装,含最复杂的权限/安全系统 |
| FileReadTool | 带 LRU 缓存的文件读取,顺便触发 Skill 发现 |
| AgentTool | 嵌套的完整 Claude Code 实例 |
| SkillTool | 单入口多出口的 Skill 路由器 |
| ToolSearchTool | 工具的工具,解决系统提示过长问题 |
| MCPTool | 远程 RPC 调用的本地代理对象 |
| SyntheticOutputTool | 强制结构化输出的 JSON Schema 验证器 |
工具池的组装流程
每次 API 调用前,工具池动态组装:
getAllBaseTools() ← 内置工具(受 feature flags 过滤)
+
appState.mcp.tools ← 运行时动态注入的 MCP 工具
↓
assembleToolPool()
↓
filterToolsByDenyRules() ← 黑名单过滤
↓
REPL 模式隐藏 ← 启用 REPLTool 时隐藏 Bash/Read 等
↓
ToolSearch 延迟 ← 工具太多时延迟加载非核心工具
↓
最终工具池 → 注入系统提示去重规则 :内置工具优先(uniqBy by name),同名 MCP 工具被丢弃。
四. 权限控制
Claude Code 的权限系统是一套多层防御 + 规则引擎的设计,核心思路:
默认不信任(deny by default),但以 ask 而非 deny 作为兜底 ------ 保留人类最终决策权,只有真正危险的模式才硬编码
deny。
4.1 规则来源
| 优先级 | 层级 | 来源 | 是否可被覆盖 | 生命周期 | 典型场景 |
|---|---|---|---|---|---|
| 1 | cliArg | 命令行参数 | ❌ 不可被下层覆盖 | 单次启动 | claude --permission-mode bypassPermissions(CI/CD 一次性授权) |
| 2 | policySettings | 企业/组织策略 | ❌ 强制 | 长期 | 企业限制:禁止 rm、限制访问 /etc |
| 3 | localSettings | .claude/settings.local.json |
✅ 可覆盖更低层 | 本机持久 | 本地开发特殊配置,不提交 Git |
| 4 | projectSettings | .claude/settings.json |
✅ 可覆盖更低层 | 项目级 | 项目允许 npm test、make build |
| 5 | userSettings | ~/.claude/settings.json |
✅ 可覆盖更低层 | 用户全局 | 个人习惯:默认允许 git commit |
| 6 | session | 会话内动态规则 | ✅ 临时覆盖 | 会话级 | "这个命令以后不用问" |
| 7 | command | Slash 命令注入 | ✅ 临时覆盖 | 瞬时/短期 | /allowed-tools bash 临时放权 |
4.2 权限模式
| 模式 | 含义 | UI 颜色 | 风险等级 |
|---|---|---|---|
| default | 默认,危险操作需人工确认 | 白色 | 🟢 安全 |
| plan | 只规划不执行(dry-run) | 蓝色 | 🟢 安全 |
| acceptEdits | 文件编辑自动接受,Shell 仍需确认 | 橙色 ⏵⏵ | 🟡 中等 |
| bypassPermissions | 完全绕过所有权限检查 | 红色 ⏵⏵ | 🔴 危险 |
| dontAsk | 不询问用户,静默执行 | 红色 ⏵⏵ | 🔴 危险 |
用户可通过 CLI flag 或 settings.json 的 defaultMode 字段设置全局权限模式:
4.3 权限三要素
规则的三要素
type PermissionRule = {
source: PermissionRuleSource // 来自哪一层
ruleBehavior: 'allow' | 'deny' | 'ask' // 行为
ruleValue: {
toolName: string // 匹配哪个工具,如 "Bash"
ruleContent?: string // 匹配具体内容,支持通配符
}
}实际规则示例:
// projectSettings 层:允许执行测试命令
{ source: 'projectSettings', ruleBehavior: 'allow',
ruleValue: { toolName: 'Bash', ruleContent: 'npm test*' } }
// policySettings 层:禁止删除操作
{ source: 'policySettings', ruleBehavior: 'deny',
ruleValue: { toolName: 'Bash', ruleContent: 'rm -rf*' } }
// session 层:用户临时授权
{ source: 'session', ruleBehavior: 'allow',
ruleValue: { toolName: 'Bash', ruleContent: 'docker*' } }五 Skill 系统
5.1 Skill 本质
Skill 是 Command 类型中的 PromptCommand,核心字段:
typescript
PromptCommand = {
type: 'prompt'
description: string
allowedTools?: string[] // Skill 内可使用的工具白名单
model?: string // 覆盖主模型(opus/sonnet/haiku)
context?: 'inline' | 'fork' // 执行方式
agent?: string // fork 时使用的代理类型
effort?: EffortValue
paths?: string[] // 条件激活(gitignore 语法)
argNames?: string[] // 参数名列表
getPromptForCommand(args, context): Promise<ContentBlockParam[]>
}5.2 SKILL.md 格式
markdown
---
name: 显示名称(可选)
description: 一句话描述(必填)
when-to-use: 何时使用
allowed-tools: [Bash, Read, Edit, Grep]
model: opus
effort: high
context: fork # inline(默认)或 fork
agent: general-purpose
arguments: [pattern, output-file]
paths: src/**/*.ts # 仅当用户操作匹配文件时激活
user-invocable: true # 用户能否用 /skill-name 调用
disable-model-invocation: false # 模型能否调用
---
# Skill 正文(Markdown)
详细的操作步骤和指令...
参数使用:$0 第一个参数,${pattern} 命名参数
特殊变量:${CLAUDE_SKILL_DIR}、${CLAUDE_SESSION_ID}
Shell 执行:!`git status` (反引号内容在加载时执行)5.3 Skill 加载来源(优先级从高到低)
1. 项目级 .claude/skills/<name>/SKILL.md
2. 用户级 ~/.claude/skills/<name>/SKILL.md
3. Managed 管理员推送的 Policy Skills
4. Bundled 编译进 CLI 的内置 Skills(commit、review-pr、pdf...)
5. Plugin 第三方插件提供
6. MCP MCP 服务器提供5.4 SkillTool 本身就是 Tool
typescript
const SkillTool = buildTool({
name: 'Skill',
searchHint: 'invoke a slash-command skill',
inputSchema: z.object({
skill: z.string(),
args: z.string().optional(),
}),
// ...
})模型看到的 :一个叫 Skill 的工具,加上可用 Skills 的列表说明。
5.5 协作全景
用户输入
↓
系统提示中包含:
├─ 所有可用 Tools(直接列出 or ToolSearch 按需)
└─ SkillTool 说明 + 可用 Skills 列表(限制 1% 上下文 ≈ 8000 字符)
↓
Claude 决策:
├─ 直接调用 Tool(Bash、Read、Grep...)
│ → 执行 → 结果追加 → 继续
│
└─ 调用 SkillTool(skill="commit", args="...")
→ Inline:展开 SKILL.md → 新消息注入 → 模型继续(用 allowed-tools)
→ Fork:子代理独立执行 → 结果返回