从K-Means到PCA,一篇讲透无监督学习的核心算法
引言:为什么你需要关注无监督学习?
在工业4.0时代,数据每天都在以惊人的速度增长。然而,现实情况往往是:数据堆积如山,标签却寥寥无几。获取标注数据需要大量的人工成本和时间投入,这在许多场景下几乎不可行。这正是无监督学习大显身手的地方。
无监督学习,顾名思义,在没有任何标签的情况下,仅依靠数据本身的内在结构来发现规律。它就像一名侦探,面对一堆杂乱的线索,不需要任何人告诉他真相是什么,而是依靠线索之间的关联自己推理出模式。
从市场细分到图像分割,从异常检测到基因分析,无监督学习正悄然改变着各个行业的运作方式。2026年的一项研究显示,基于Transformer的无监督异常检测模型USAGI在MVTec AD数据集上的AUROC达到了98.2%,在VisA数据集上更是高达99.5%,展现出惊人的性能。这表明,无监督学习不仅在"可行"的范畴内,更正在走向"卓越"。
本文将带你系统掌握无监督学习的两大核心领域------聚类和降维。我们会深入到K-Means、层次聚类、DBSCAN、SVD和PCA的数学原理,并结合最新的应用案例和完整的代码实战,让你不仅"知其然",更"知其所以然"。
一、聚类------让数据"物以类聚"
1.1 什么是聚类?
聚类的核心思想其实就一句话:物以类聚,人以群分。它试图将数据集中的样本划分为若干个"簇",使得同一簇内的对象彼此相似,不同簇间的对象差异明显。由于聚类算法不需要预先标注的标签,它完全依赖数据本身的内在结构和特征进行分组。聚类结果所代表的"概念"和"语义"需要由使用者来把握和命名,这也是无监督学习"无监督"二字的含义所在。
聚类的实现通常包含三个核心步骤:定义相似性(选择一个合适的度量标准,如欧氏距离、余弦相似度等来衡量对象间的距离)、分组(根据相似性将对象分配到不同的簇中)、优化(通过迭代或直接计算来调整簇的划分,最大化簇内相似性和簇间差异性)。
聚类算法的三大流派:根据其核心思想,聚类算法可以大致分为以下三类:
|-----|-------------------|--------------|---------------|
| 流派 | 代表算法 | 核心思想 | 适用场景 |
| 划分式 | K-Means、K-Medoids | 将数据划分为K个互斥的簇 | 数据量大、簇形状近似球形 |
| 层次式 | 聚合聚类、分裂聚类 | 构建簇的层次树状结构 | 需要探索不同粒度的聚类结果 |
| 密度式 | DBSCAN、OPTICS | 将高密度区域视为簇 | 簇形状不规则、存在噪声数据 |
1.2 K-Means聚类:简洁而强大的划分式方法
K-Means可能是最广为人知的聚类算法。它基于一个朴素的想法:每个簇应该有一个"中心点",而数据点应该归属于离它最近的那个中心点。
(1)数学原理
K-Means的核心是最小化样本到其所属簇中心的距离平方和:
W(C)=∑l=1k∑i=1nl∥xi−xˉl∥2W(C)=∑l=1k∑i=1nl∥xi−xˉl∥2
其中,\\bar{x}_l是第l个簇的中心。这是一个组合优化问题,n个样本分到k个簇的所有可能分法数目为:
S(n,k)=1k!∑l=0k(−1)l(kl)(k−l)nS(n,k)=k!1∑l=0k(−1)l(lk)(k−l)n
这个数目是指数级的,在现实中无法穷举,因此通常采用迭代近似求解。
(2)算法流程
K-Means的执行过程可以用一个简单的循环概括:
-
初始化
:随机选择k个样本点作为初始簇中心
-
分配
:计算每个样本到各个簇中心的距离,将样本分配到最近的簇
-
更新
:重新计算每个簇内所有样本的均值,作为新的簇中心
-
重复
:步骤2-3,直到簇中心不再变化或达到迭代上限
(3)K值的确定------肘部法则
K-Means最大的痛点之一就是需要事先指定K值。如何找到最优的K值?肘部法则(Elbow Method)是最常用的方法之一。它通过绘制不同K值对应的簇内平方和(WCSS,Within-Cluster Sum of Squares)曲线,寻找"肘部点"------即WCSS下降速度显著减缓的位置。肘部法在学术研究和工业实践中都被广泛采用,例如在K-means-XGBoost集成分类方法中,研究者正是使用肘部法来确定最优的聚类数量。
(4)K-Means的局限与改进
K-Means虽然简单高效,但也有着明显的短板:
-
对初始中心敏感
:不同的初始化可能导致完全不同的聚类结果。为此,scikit-learn中默认使用k-means++初始化策略,通过概率分布选择初始中心,能够显著提高收敛速度和聚类质量。
-
不适合非凸形状簇
:K-Means假设簇是球形的,对于环形、月牙形等复杂形状的数据无能为力。
-
对噪声敏感
:离群点会严重影响簇中心的计算。
1.3 层次聚类:构建数据的家族谱系
层次聚类不要求指定K值,而是构建一个簇的"家谱树",称为树状图(Dendrogram)。它主要分为两种方式:
-
聚合聚类(自下而上)
:开始时每个样本自己就是一个簇,然后反复将最近的两个簇合并,直到达到预设的簇数量或满足停止条件。
-
分裂聚类(自上而下)
:开始时所有样本在一个簇中,然后反复将簇分裂,直到每个样本自成一组。
层次聚类的结果以树状图形式呈现,纵轴表示簇间距离。通过在不同高度"横切"这棵树,我们可以得到不同粒度的聚类结果。这种多层级结构在生物信息学中尤为常见------基因表达数据的层次聚类可以同时展示物种大类(门类)和具体物种(科属)的关系。
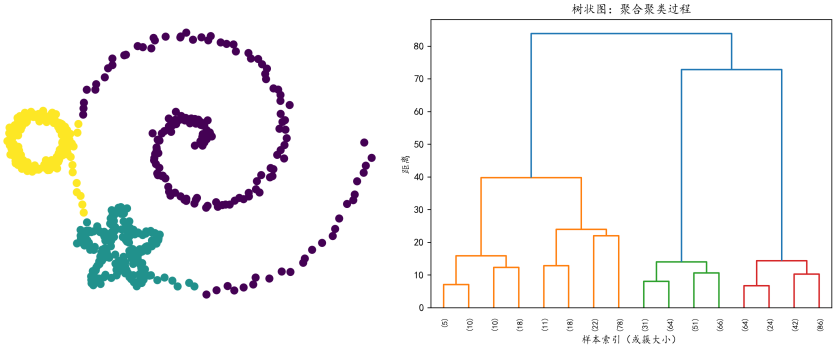
2025年,层次聚类技术有了令人振奋的突破。研究者提出了HERCULES(Hierarchical Embedding-based Recursive Clustering Using LLMs for Efficient Summarization),这是一个将分层K-Means与大语言模型深度集成的Python包。HERCULES通过递归应用K-Means构建簇的层次结构,并利用LLM为每一层的簇生成语义丰富的标题和描述,大大增强了聚类结果的可解释性。具体而言,它支持两种模式:直接模式 (基于原始数据嵌入或数值特征进行聚类)和描述模式(基于LLM生成的摘要的嵌入进行聚类),用户还可以通过提供topic_seed来引导LLM的摘要生成方向。
1.4 DBSCAN:密度驱动的聚类革命
如果数据点的分布形状不规则,或者存在大量噪声,K-Means和层次聚类可能会力不从心。这时,基于密度的聚类算法DBSCAN就能大显身手。
(1)核心概念
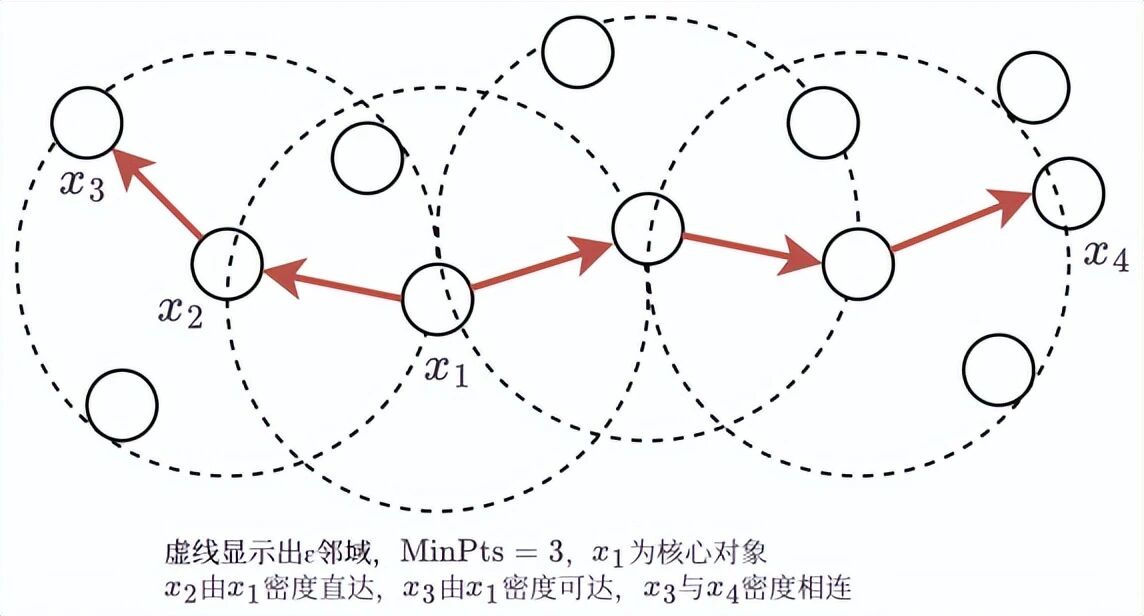
DBSCAN的核心思想是:簇是由高密度区域构成的,这些区域被低密度区域分隔开。它引入了几个关键概念:
-
核心对象(Core Object)
:在半径\\epsilon的邻域内,包含至少MinPts个样本的点
-
密度直达
:点q在点p的\\epsilon邻域内,且p是核心对象
-
密度可达
:存在一系列密度直达的点,从p到q连通
-
密度相连
:存在核心对象o,使p和q都从o密度可达
(2)算法流程
-
根据\\epsilon和MinPts找出所有核心对象
-
从任一核心对象出发,找出所有由其密度可达的样本,形成一个簇
-
重复步骤2,直到所有核心对象都被访问过
-
未被归入任何簇的样本被标记为噪声点
(3)DBSCAN的优势与改进
DBSCAN的优势显而易见:不需要指定K值、可以发现任意形状的簇、能够自动识别噪声点。然而,它也不是完美的。算法对\\epsilon和MinPts两个参数非常敏感,且在处理不同密度区域时效果欠佳。
针对这些问题,研究者们提出了大量改进方案。2025年,一项研究提出了基于改进DBSCAN的道路障碍物点云聚类方法,利用孤立核函数改进传统的距离度量方式,显著提高了DBSCAN对不同密度区域的适应性和准确性。同年,NaGB-DBSCAN算法通过结合自然邻居(Natural Neighbor)和颗粒球(Granular-Ball)的概念,有效解决了DBSCAN参数调优困难的问题。此外,还有研究者使用多智能体强化学习提出了AR-DBSCAN框架,实现了对聚类参数的动态自适应调整。
二、聚类效果如何评估?
由于聚类任务没有预定义的标签作为参考,我们无法像监督学习那样计算准确率或F1分数。聚类的评估必须完全依赖于数据本身的内部结构。以下是最常用的几种评估方法。
2.1 轮廓系数(Silhouette Coefficient)
轮廓系数同时考虑了簇内的紧密度(内聚度)和簇间的分离度。对于每个样本点i:
-
计算a_i:该点到同簇其他样本的平均距离(内聚度)
-
计算b_i:该点到最近其他簇样本的平均距离(分离度)
单个样本的轮廓系数为:
si=bi−aimax(ai,bi)∈−1,1si=max(ai,bi)bi−ai∈−1,1
-
s_i越接近1:表示该点被很好地聚类,远离其他簇
-
s_i接近0:表示该点位于两个簇的边界上
-
s_i为负数:表示该点可能被分配到了错误的簇
总体轮廓系数是全部s_i的平均值,通常取平均轮廓系数最大的K值作为最佳聚类数。轮廓系数在实际应用中也常与肘部法则结合使用,肘部法则通过寻找WCSS曲线拐点确定K值范围,轮廓系数则从中选出最优解。
2.2 肘部法则与WCSS
WCSS(簇内平方和)衡量的是所有样本点到其所属簇中心的总距离平方和:
WCSS=∑k=1K∑i∈Ck∥xi−μk∥2WCSS=∑k=1K∑i∈Ck∥xi−μk∥2
随着K值增大,WCSS会逐渐减小。肘部法则就是要找到WCSS下降速度显著放缓的那个点------即"肘部"点,这个点通常被认为是最佳的K值。
2.3 CH指数(Calinski-Harabasz Index)
CH指数综合考虑了簇间分散度和簇内紧密度,其计算公式为:
CH=BCSS/(K−1)WCSS/(N−K)CH=WCSS/(N−K)BCSS/(K−1)
其中BCSS是簇间平方和,WCSS是簇内平方和。CH指数越大,表示簇间距离越大、簇内距离越小,聚类效果越好。值得注意的是,CH指数在业界也有实际应用------例如在客户细分研究中,研究者使用FAMD(Factor Analysis of Mixed Data)方法结合K-Means和层次聚类进行客户细分时,就使用了包括CH指数在内的多种指标来评估聚类质量。
2.4 聚类评估代码实战
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score, calinski_harabasz_score
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 生成3个簇的样本数据,增加标准差使数据有一定重叠
X, y_true = make_blobs(n_samples=300, centers=3, cluster_std=5)
# K-Means聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
centers = kmeans.cluster_centers_
# 可视化
plt.scatter(X[:, 0], X[:, 1], s=50, c=y_kmeans, cmap="viridis")
plt.scatter(centers[:, 0], centers[:, 1], s=200, c="red", marker="*", label="簇中心")
plt.legend()
plt.show()
# 输出评估指标
print("簇内平方和: ", kmeans.inertia_)
print("轮廓系数: ", silhouette_score(X, y_kmeans))
print("CH指数: ", calinski_harabasz_score(X, y_kmeans))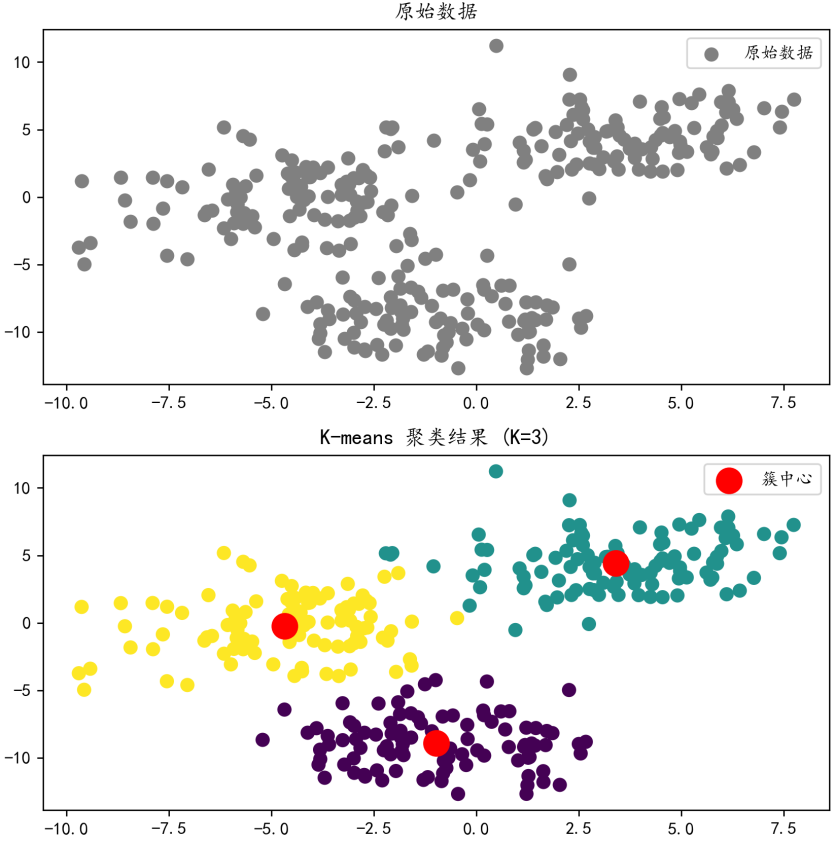
三、降维------化繁为简的数据压缩术
在机器学习和数据分析中,高维数据往往会带来"维度灾难"------数据变得极其稀疏,计算复杂度呈指数级增长,模型容易过拟合。降维技术应运而生,它旨在用更少的特征捕捉数据的主要信息。
3.1 奇异值分解(SVD)------矩阵分解的基石
奇异值分解(Singular Value Decomposition, SVD)是一种通用的矩阵分解方法。SVD的理论基础是:任何一个实矩阵都可以分解为三个矩阵的乘积:
A=UΣVTA=UΣVT
-
U和V都是正交矩阵(UU\^T = I,VV\^T = I)
-
\\Sigma是由奇异值构成的对角矩阵,且奇异值按降序排列:\\sigma_1 \\geq \\sigma_2 \\geq \\dots \\geq \\sigma_p \\geq 0
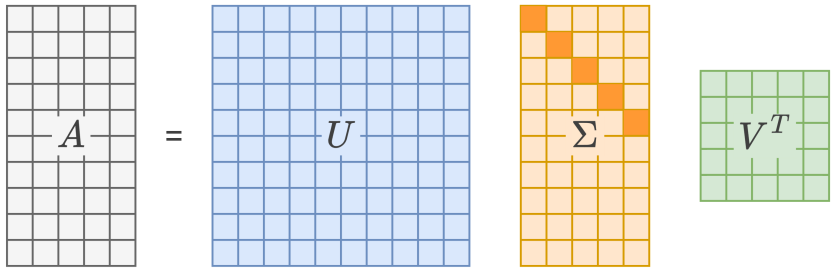
SVD的一个重要性质是:保留最大的r个奇异值及其对应的奇异向量,可以得到原始矩阵的最优低秩近似。这一性质使得SVD成为数据压缩和降维的强大工具。
SVD的计算过程:
传统上,SVD可以通过以下步骤计算:
-
计算A\^TA的特征值和特征向量,得到V和\\Sigma
-
利用u_j = \\frac{1}{\\sigma_j} A v_j计算左奇异向量
-
补充额外的正交向量构造完整的U矩阵
下面以矩阵A = \\begin{bmatrix} 1 \& 1 \\ 2 \& 2 \\end{bmatrix}为例演示计算过程:
-
A\^TA = \\begin{bmatrix} 5 \& 5 \\ 5 \& 5 \\end{bmatrix}
-
特征值\\lambda_1 = 10, \\lambda_2 = 0,对应特征向量v_1 = \\begin{bmatrix} 1/\\sqrt{2} \\ 1/\\sqrt{2} \\end{bmatrix}, v_2 = \\begin{bmatrix} 1/\\sqrt{2} \\ -1/\\sqrt{2} \\end{bmatrix}
-
奇异值\\sigma_1 = \\sqrt{10}, \\sigma_2 = 0
-
左奇异向量u_1 = \\frac{1}{\\sqrt{10}} A v_1 = \\begin{bmatrix} 1/\\sqrt{5} \\ 2/\\sqrt{5} \\end{bmatrix}
最终分解得到A = U\\Sigma V\^T。不过,上述过程只是为说明计算原理,实际应用中使用的是更为高效的数值计算方法。
3.2 主成分分析(PCA)------寻找数据的主方向
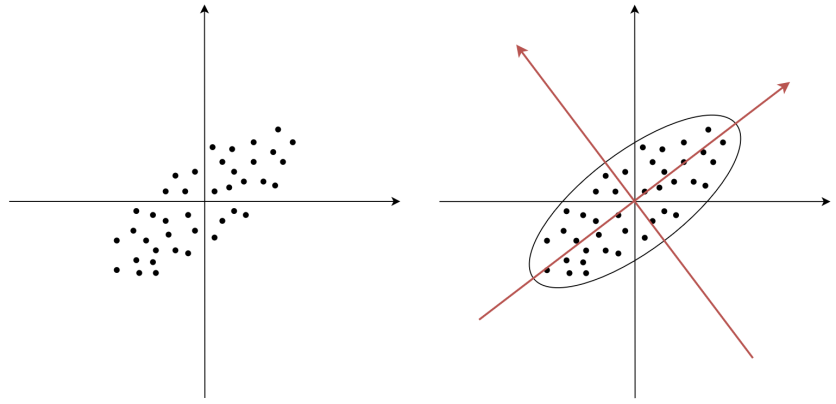
主成分分析(Principal Component Analysis, PCA)是最常用的降维方法。它的目标非常直观:找到数据中方差最大的方向,并用这些方向重新表达数据。
(1)核心思想
想象一下,你面前有一片三维空间中的点云,它们可能近似分布在一个平面上。PCA就是要找到这个"平面"的方向,然后将所有点投影到这个平面上。这样,我们就用两个维度(平面的两个基向量)替代了原来的三个维度。
更正式地说,PCA通过正交变换将可能线性相关的原始特征转换为一组线性无关的新特征(称为主成分)。主成分按照方差大小排序,第一个主成分捕捉了数据中最大的变异方向,第二个主成分在与第一个正交的方向上捕捉次大的变异方向,以此类推。
(2)数据预处理
在进行PCA之前,有一个至关重要的步骤------数据标准化。这是因为PCA对方差敏感,如果不同特征的量纲差异很大(例如一个特征以"米"为单位,另一个以"厘米"为单位),PCA会错误地将量纲大的特征视为主要变异来源。通常的做法是将每个特征规范化为均值为0、方差为1。
(3)PCA的数学原理
传统PCA通过协方差矩阵的特征值分解来实现:
SX=XTXn−1SX=n−1XTX
其中X是标准化后的样本矩阵(每列为一个特征,每行为一个样本)。特征值分解S_X = V\\Lambda V\^T得到的特征向量V就是主成分的方向,特征值\\lambda_i衡量了第i个主成分所解释的方差大小。
(4)用SVD实现PCA
现代PCA实现通常采用SVD而非直接进行特征值分解,主要原因有三:
-
数值稳定性更好
:避免了计算X\^TX可能带来的数值精度损失
-
计算效率更高
:对于大规模稀疏矩阵尤其明显
-
可以处理矩阵非方阵的情况
:具有更好的通用性
数学上可以验证:将标准化后的样本矩阵X进行SVD分解X = U\\Sigma V\^T,代入协方差公式:
SX=XTXn−1=VΣTΣn−1VT=VΛVTSX=n−1XTX=Vn−1ΣTΣVT=VΛVT
这正是协方差矩阵的特征值分解形式,其中V的列向量就是主成分方向,而特征值\\lambda_i = \\frac{\\sigma_i\^2}{n-1}。
每个主成分的方差贡献率为:
σi2∑i=1pσi2∑i=1pσi2σi2
这个比例帮助我们决定需要保留多少个主成分------通常选择累计贡献率达到85%-95%的前r个主成分。
(5)PCA的代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
# 加载数据
iris = load_iris()
X = iris.data
y = iris.target
# 标准化(PCA前必须做的预处理)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 执行PCA,降维到2维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# 查看解释方差比例
print("各主成分解释方差比例:", pca.explained_variance_ratio_)
print("累计解释方差比例:", np.cumsum(pca.explained_variance_ratio_))
# 可视化
plt.figure(figsize=(8, 6))
colors = ['red', 'green', 'blue']
for i, color in enumerate(colors):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1],
color=color, label=iris.target_names[i])
plt.xlabel('第一主成分')
plt.ylabel('第二主成分')
plt.title('PCA降维后的Iris数据集')
plt.legend()
plt.show()(6)PCA的最新应用
PCA远非一个"过时的老方法"。2025年,PCA在多领域的应用持续深化:
-
生物信息学
:一项研究提出了将PCA与MOORA多准则决策方法融合的新框架,用于基因表达数据中的无监督特征选择。该框架在多个生物信息学数据集上验证,相比单独使用PCA或MOORA,在分类准确率和特征约简方面均有显著提升。
-
网络安全
:在软件定义网络(SDN)的DDoS检测中,研究者首先基于领域相关性对新生成的特征进行分类,然后对每个类别分别应用PCA进行降维,实现了更精准的检测。
-
神经科学
:2025年提出的概率几何PCA(Probabilistic Geometric PCA)方法,为神经数据分析提供了更灵活的概率框架,克服了传统PCA只能处理线性结构的局限。
四、实战案例------从理论到应用
4.1 客户细分
客户细分是市场营销中应用最广泛的无监督学习场景。电商平台希望了解用户的消费行为模式,从而制定差异化的营销策略。通过K-Means聚类,可以根据用户的消费频率、消费金额、品类偏好等特征,将用户划分为几个典型的客户群体。
2025年的研究表明,结合因子分析混合数据(FAMD)和K-Means与层次聚类的方法,能够在客户细分中获得更高质量的聚类结果,为企业提供更精准的客户画像。
典型应用流程:
-
收集用户的消费记录、浏览行为、基本信息等数据
-
对数据进行清洗和特征工程,构建用户画像特征
-
使用肘部法则确定最优K值
-
执行K-Means聚类,获得用户分组
-
分析每个簇的特征,赋予商业含义(如"高价值用户"、"流失风险用户"等)
4.2 图像分割
图像分割是将图像划分为若干有意义的区域的过程。2025年,无监督图像分割取得了突破性进展:
-
CLASP框架
:研究者提出的CLASP(Clustering via Adaptive Spectral Processing)是一个轻量级的无监督图像分割框架,它首先使用自监督ViT编码器(DINO)提取图像块特征,然后构建亲和矩阵并应用谱聚类。通过特征值间隙(eigengap)轮廓搜索自动确定分割数量,并使用DenseCRF锐化边界。在COCO Stuff和ADE20K数据集上,CLASP达到了与最新无监督基线相当的mIoU和像素精度,且完全无需标注数据或微调。
-
农作物分割
:华中科技大学与中国科学院遗传与发育生物学研究所联合发布了DepthCropSeg++,这是全球首个农作物分割基础模型。该模型巧妙利用单目深度估计模型Depth Anything V2自动生成高质量的作物掩码,实现了近乎无监督的作物分割,在田间、无人机、高通量平台、手机拍摄等多个真实场景下均表现出色。
4.3 异常检测
在工业质检、金融风控、网络安全等领域,异常检测有着重要的应用价值。2025-2026年,无监督异常检测技术不断刷新性能记录:
-
USAGI模型
:USAGI(Unsupervised Segmentation and Anomaly Gradient Interpretation)是一个基于Transformer的无监督异常检测框架。它创新性地设计了Memory Transformer(记忆转换器)和Retrieval Transformer(检索转换器)两个核心组件:前者在训练阶段从正常特征中构建记忆库,后者在测试阶段检索并比较特征,实现了细粒度的异常重建和分割。USAGI在MVTec AD数据集上达到98.2%的AUROC,在VisA数据集上更是高达99.5%,证明了无监督方法在复杂视觉异常检测中的巨大潜力。
-
自动驾驶中的点云聚类
:在智能交通和自动驾驶中,道路障碍物检测至关重要。2025年,研究者提出了TCCO-DBSCAN算法,利用孤立核函数改进距离度量,并使用改进的猎豹优化算法自适应确定DBSCAN参数。在八个UCI数据集上的测试表明,该方法在F-Measure、ARI、NMI等指标上均优于现有方法,并成功应用于激光雷达点云数据的道路障碍物聚类。
五、总结
回顾全文,无监督学习的价值已经不言而喻。在数据日益庞大、标注成本居高不下的今天,无监督学习为我们提供了一条从数据中自主发现知识的有效路径。
核心要点速记:
|---------|--------------------------------------------------------------------|------------|-------------|
| 算法 | 核心公式 | 优点 | 缺点 |
| K-Means | W(C) = \\sum_{l=1}\^k \\sum_{i=1}\^{n_l} \|x_i - \\bar{x}_l\|\^2 | 简单高效 | 需指定K,对初始值敏感 |
| 层次聚类 | 树状图 | 无需K值,多粒度结果 | 计算复杂度高 |
| DBSCAN | 密度可达/相连 | 任意形状,抗噪声 | 参数敏感 |
| PCA/SVD | X = U\\Sigma V\^T | 降维保信息 | 线性假设 |
| 轮廓系数 | s_i = \\frac{b_i - a_i}{\\max(a_i, b_i)} | 综合评估内聚与分离 | 计算复杂度O(n²) |
| 肘部法 | WCSS vs K曲线拐点 | 直观易用 | 肘部点可能不明显 |
聚类算法的选择在很大程度上取决于数据的特点:如果数据呈球形分布且计算效率是首要考虑,K-Means是首选;如果需要探索不同粒度的层次关系,层次聚类不可或缺;如果数据形状不规则或存在大量噪声,DBSCAN则是不二之选。而在面对高维数据时,PCA和SVD则是最好的"信息浓缩"工具。
随着大语言模型的崛起,无监督学习正在迎来新的范式。HERCULES将LLM的语义理解能力融入层次聚类,为聚类结果提供了前所未有的可解释性;USAGI将Transformer架构引入异常检测,刷新了多个基准数据集的最佳成绩。可以预见,无监督学习将在数据科学和人工智能领域扮演越来越重要的角色。
希望这篇文章能帮你建立起对无监督学习核心算法的完整认知。如果你对某个算法还有疑问,欢迎在评论区留言讨论!