文章目录
- 一、前言
- [二、LlamaIndex 的基本概念](#二、LlamaIndex 的基本概念)
-
- [2.1 提示](#2.1 提示)
- [2.2 加载](#2.2 加载)
-
- [2.2.1 文档和节点](#2.2.1 文档和节点)
- [2.2.2 目录读取器](#2.2.2 目录读取器)
- [2.2.3 数据连接器](#2.2.3 数据连接器)
- [2.2.4 节点解析器](#2.2.4 节点解析器)
- [2.2.5 文本分割器](#2.2.5 文本分割器)
- [2.2.6 摄取管道](#2.2.6 摄取管道)
- [2.3 索引](#2.3 索引)
-
- [2.3.1 向量存储索引](#2.3.1 向量存储索引)
- [2.3.2 属性图表索引](#2.3.2 属性图表索引)
- [2.3.3 文件管理索引](#2.3.3 文件管理索引)
- [2.3.4 元数据提取](#2.3.4 元数据提取)
- [2.4 存储](#2.4 存储)
-
- [2.4.1 向量存储](#2.4.1 向量存储)
- [2.4.2 文档存储](#2.4.2 文档存储)
- [2.4.3 索引存储](#2.4.3 索引存储)
- [2.4.4 键值存储](#2.4.4 键值存储)
- [2.5 查询](#2.5 查询)
-
- [2.5.1 检索器](#2.5.1 检索器)
- [2.5.2 查询引擎](#2.5.2 查询引擎)
- [2.5.3 聊天引擎](#2.5.3 聊天引擎)
- [2.5.4 响应合成器](#2.5.4 响应合成器)
- [2.6 总结](#2.6 总结)
- 三、本章练习题及其答案
-
- [3.1 选择题](#3.1 选择题)
-
- [3.1 选择题答案](#3.1 选择题答案)
- [3.2 填空题](#3.2 填空题)
-
- [3.2 填空题答案](#3.2 填空题答案)
- [3.3 简答题](#3.3 简答题)
-
- [3.3 简答题答案](#3.3 简答题答案)
- [3.4 实操题](#3.4 实操题)
-
- [3.4 实操题答案(可运行代码)](#3.4 实操题答案(可运行代码))
- 四、总结
一、前言
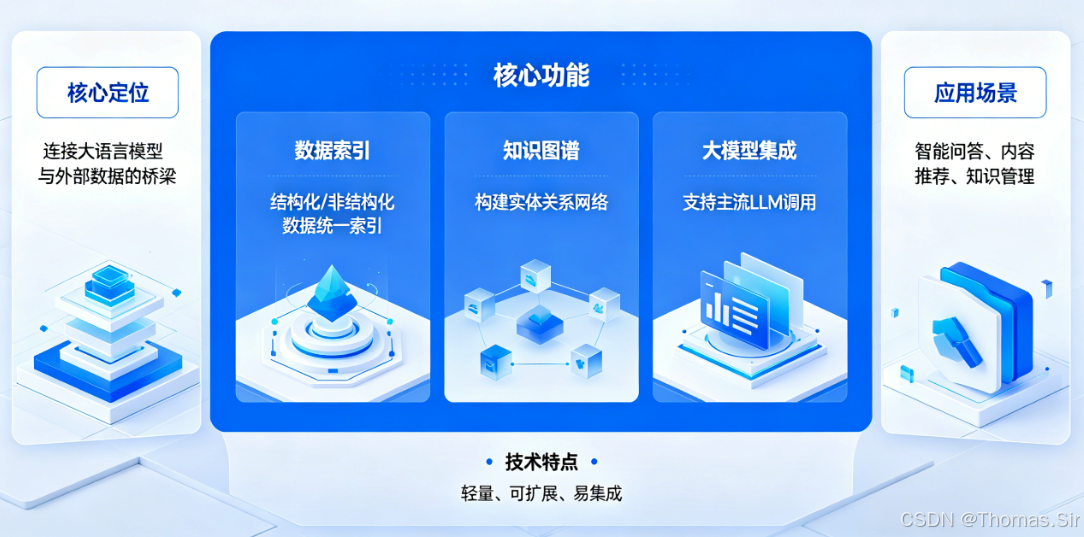
随着大语言模型(LLM)的快速发展,越来越多的开发者、AI爱好者及在校学生开始尝试将LLM与自有数据结合,构建个性化的AI应用。但LLM本身存在上下文窗口有限、无法直接处理私有数据、检索精度不足等问题,而LlamaIndex(曾用名GPT Index)的出现,完美解决了这些痛点。
LlamaIndex是一款开源的Python数据框架,专为构建基于大型语言模型(LLM)的应用程序而设计,完全免费且开源,GitHub星数截至2026年2月已突破80K,是开发者搭建企业级知识库的首选工具。它作为LLM与私有数据之间的"桥梁",提供了一套完整的工具链,帮助用户高效加载、索引、存储和查询各类数据,轻松实现检索增强生成(RAG)等核心场景。
二、LlamaIndex 的基本概念
2.1 提示
提示(Prompt)是LlamaIndex与LLM交互的核心载体,本质是一段结构化的文本指令,用于告诉LLM"该做什么、怎么做"。与直接调用LLM不同,LlamaIndex的提示会自动整合数据上下文、查询意图等信息,无需用户手动拼接复杂指令,大幅降低LLM调用的门槛。
LlamaIndex内置了丰富的默认提示模板,覆盖索引构建、查询检索、响应合成等全流程,同时支持用户自定义提示,适配不同场景需求。提示的质量直接影响LLM的响应效果,合理的提示能让LLM更精准地利用索引数据,生成符合预期的结果。
核心特点:
-
结构化设计:默认提示模板包含固定格式(如系统指令、上下文、用户问题),确保LLM能清晰理解任务;
-
动态适配:会根据检索到的节点数据、用户查询类型,自动填充提示内容,无需手动修改;
-
高度可定制:支持修改默认模板、添加自定义指令(如格式要求、语气要求),适配个性化需求。
代码示例(自定义提示模板):
python
from llama_index.core import PromptTemplate
# 1. 定义自定义提示模板(以问答场景为例)
# 模板中{context}会自动填充检索到的节点数据,{question}会填充用户问题
custom_prompt = PromptTemplate(
template="""系统指令:你是一个专业的答疑助手,仅基于提供的上下文回答问题,不要编造信息。
上下文:{context}
用户问题:{question}
请用简洁、准确的语言回答,字数不超过50字。"""
)
# 2. 查看默认提示模板(以响应合成为例)
from llama_index.core.response_synthesizers import get_response_synthesizer
# 获取默认合成器,查看其提示模板
response_synthesizer = get_response_synthesizer()
print("默认响应合成提示模板:")
print(response_synthesizer._prompt_helper.prompt_templates["response_synthesizer"])代码说明:上述代码定义了一个自定义问答提示模板,指定了系统指令、上下文和问题的占位符,后续使用时LlamaIndex会自动替换占位符;同时展示了如何查看默认提示模板,方便用户根据需求修改。
2.2 加载
加载(Loading)是LlamaIndex处理数据的第一步,核心作用是将本地文件、数据库、API接口等多种来源的数据,统一转换为LlamaIndex可识别的"文档"格式,为后续的索引构建、查询检索提供数据基础。LlamaIndex提供了丰富的加载工具,支持多种数据类型,且操作简单、可扩展性强。
加载的核心流程:数据来源 → 读取数据 → 转换为文档对象 → (可选)解析为节点 → 进入摄取管道,整个流程可通过简单代码实现,无需手动处理数据格式转换。
2.2.1 文档和节点
文档(Document)和节点(Node)是LlamaIndex中最基础的数据载体,二者是"整体与部分"的关系,共同构成了LlamaIndex的数据基础。
-
文档(Document):是数据加载的"原始容器",代表一个完整的数据源(如一个PDF文件、一篇Markdown文档、一个数据库表)。每个文档包含原始文本内容、元数据(如文件路径、创建时间、作者)等信息,是LlamaIndex加载数据的最小"整体单位"。
-
节点(Node):是文档的"拆分单元",由文档拆分而来(如将一篇长文档拆分为多个短文本块)。每个节点包含一段独立的文本、元数据、与其他节点的关联关系等信息,是LlamaIndex进行索引构建、检索的最小"操作单位"。
核心区别:文档是完整的数据源,节点是文档拆分后的片段;索引构建、检索等操作均基于节点,而非文档,这样可以解决LLM上下文窗口有限的问题,提升检索精度。
代码示例(创建文档和节点):
python
from llama_index.core import Document
from llama_index.core.schema import TextNode
# 1. 创建文档(模拟本地文档内容)
# 文档包含文本内容和元数据(可自定义元数据字段)
doc = Document(
text="LlamaIndex是一款开源的LLM应用框架,用于连接LLM和私有数据,支持数据加载、索引、存储和查询。"
"它能帮助开发者快速构建RAG应用,解决LLM无法处理私有数据的问题。",
metadata={
"source": "本地文档",
"author": "AI爱好者",
"create_time": "2026-04-06"
}
)
print("文档内容:", doc.text)
print("文档元数据:", doc.metadata)
# 2. 创建节点(手动拆分文档,也可通过节点解析器自动拆分)
node1 = TextNode(
text="LlamaIndex是一款开源的LLM应用框架,用于连接LLM和私有数据,支持数据加载、索引、存储和查询。",
metadata={"source": "本地文档", "chunk_id": 1} # 节点元数据可继承文档元数据,也可新增
)
node2 = TextNode(
text="它能帮助开发者快速构建RAG应用,解决LLM无法处理私有数据的问题。",
metadata={"source": "本地文档", "chunk_id": 2}
)
print("n节点1内容:", node1.text)
print("节点2内容:", node2.text)代码说明:手动创建了一个文档和两个节点,展示了文档和节点的基本结构,节点的元数据可继承文档的元数据,也可根据需求新增(如拆分ID),方便后续追踪节点来源。
2.2.2 目录读取器
目录读取器(Directory Reader)是LlamaIndex中最常用的加载工具,核心作用是批量读取指定目录下的所有文件,自动转换为文档对象,支持多种文件格式(如TXT、PDF、Markdown、Word等),无需手动逐个读取文件。
LlamaIndex内置了SimpleDirectoryReader(简单目录读取器),支持递归读取子目录、过滤指定格式文件、并行加载等功能,是快速加载本地目录文件的首选工具。
核心功能:
-
自动识别文件格式,无需手动指定解析方式;
-
支持递归读取子目录,批量加载多个文件;
-
可过滤指定格式、排除指定文件,灵活控制加载范围;
-
支持并行加载,提升大量文件的加载效率。
代码示例(使用目录读取器加载本地文件):
python
from llama_index.core import SimpleDirectoryReader
import os
# 1. 准备本地目录(创建一个测试目录,放入几个测试文件,如TXT、MD)
test_dir = "./llamaindex_test_data"
os.makedirs(test_dir, exist_ok=True) # 确保目录存在
# 2. 向目录中写入测试文件(模拟本地文件)
with open(f"{test_dir}/test1.txt", "w", encoding="utf-8") as f:
f.write("这是测试文件1,用于测试目录读取器的功能。")
with open(f"{test_dir}/test2.md", "w", encoding="utf-8") as f:
f.write("# 测试文件2n这是Markdown格式的测试文件,LlamaIndex可自动解析。")
# 3. 创建目录读取器,加载目录中的文件
# input_dir:指定要读取的目录
# recursive:是否递归读取子目录(默认False)
# required_exts:指定要加载的文件格式(可选)
reader = SimpleDirectoryReader(
input_dir=test_dir,
recursive=False, # 不递归读取子目录
required_exts=[".txt", ".md"] # 只加载TXT和MD文件
)
# 4. 加载数据,返回文档列表
documents = reader.load_data()
print(f"加载的文档数量:{len(documents)}")
# 5. 查看每个文档的内容和元数据
for i, doc in enumerate(documents):
print(f"n文档{i+1}内容:", doc.text)
print(f"文档{i+1}元数据:", doc.metadata) # 元数据包含文件路径、名称等信息代码说明:首先创建一个测试目录并写入测试文件,然后使用SimpleDirectoryReader加载目录中的TXT和MD文件,返回文档列表,最后打印每个文档的内容和元数据。运行代码前需确保安装了对应的文件解析依赖(如markdown2、python-docx等),可通过pip install markdown2 python-docx pypdf安装。
2.2.3 数据连接器
数据连接器(Data Connector)是LlamaIndex加载非本地文件数据的核心工具,用于连接外部数据源(如数据库、API接口、云存储、Notion、Slack等),将外部数据读取并转换为文档对象,扩展了LlamaIndex的数据加载范围。
LlamaIndex内置了多种常用数据连接器,同时支持自定义连接器,适配不同的外部数据源。常见的数据连接器包括:数据库连接器(MySQL、PostgreSQL)、云存储连接器(S3、Google Drive)、API连接器、Notion连接器等。
核心作用:打破本地文件的限制,实现外部数据源与LlamaIndex的无缝对接,无需手动编写数据读取代码,提升数据加载的效率和灵活性。
代码示例(使用MySQL数据库连接器加载数据):
python
# 首先安装依赖:pip install llama-index-readers-database pymysql
from llama_index.readers.database import DatabaseReader
import pymysql
# 1. 连接MySQL数据库(需提前准备MySQL环境,创建数据库和表)
# 数据库配置(替换为自己的数据库信息)
db_config = {
"host": "localhost",
"user": "root",
"password": "123456",
"database": "test_db",
"port": 3306
}
# 2. 创建数据库连接
conn = pymysql.connect(**db_config)
# 3. 创建数据库连接器,指定查询语句(读取test_table表中的数据)
reader = DatabaseReader(
connection=conn,
query="SELECT title, content FROM test_table;" # 要执行的SQL查询
)
# 4. 加载数据,返回文档列表(每条查询结果对应一个文档)
documents = reader.load_data()
print(f"从数据库加载的文档数量:{len(documents)}")
# 5. 查看文档内容(文档文本为查询结果的拼接,元数据包含字段信息)
for i, doc in enumerate(documents):
print(f"n文档{i+1}内容:", doc.text)
print(f"文档{i+1}元数据:", doc.metadata)
# 6. 关闭数据库连接
conn.close()代码说明:使用DatabaseReader连接MySQL数据库,通过SQL查询读取表中的数据,将每条查询结果转换为一个文档,文档文本为查询字段的拼接,元数据包含字段信息。运行代码前需确保MySQL服务正常运行,且已创建对应的数据库和表。
2.2.4 节点解析器
节点解析器(Node Parser)的核心作用是将文档拆分为多个节点,解决"长文档无法放入LLM上下文窗口"的问题,同时让检索更精准(检索时可定位到具体的文本片段,而非整个文档)。
LlamaIndex内置了多种节点解析器,适配不同的文档类型和拆分需求,常见的有:SimpleNodeParser(简单节点解析器)、SentenceSplitter(句子拆分器)、TokenSplitter(Token拆分器)等,每种解析器都有其适用场景。
核心功能:
-
将长文档拆分为短节点,适配LLM上下文窗口;
-
保留节点与文档的关联关系,方便追踪节点来源;
-
支持自定义拆分规则(如拆分长度、拆分分隔符);
-
自动处理节点的元数据,继承文档的元数据。
代码示例(使用节点解析器拆分文档):
python
from llama_index.core import Document
from llama_index.core.node_parser import SimpleNodeParser, SentenceSplitter
# 1. 创建一个长文档(模拟长文本)
long_doc = Document(
text="LlamaIndex是一款开源的LLM应用框架,用于连接LLM和私有数据。它提供了完整的工具链,包括数据加载、索引构建、存储管理和查询检索。"
"使用LlamaIndex,开发者可以快速构建RAG应用,解决LLM无法处理私有数据、上下文窗口有限的问题。"
"LlamaIndex支持多种数据来源,包括本地文件、数据库、API接口等,同时支持自定义扩展,适配不同的业务场景。"
"此外,LlamaIndex还提供了丰富的索引类型和查询方式,满足不同的检索需求。",
metadata={"source": "长文档测试", "create_time": "2026-04-06"}
)
# 2. 方式1:使用SimpleNodeParser(简单拆分,按固定长度拆分)
simple_parser = SimpleNodeParser(
chunk_size=100, # 每个节点的最大长度(字符数)
chunk_overlap=10 # 节点之间的重叠长度(避免拆分后上下文断裂)
)
simple_nodes = simple_parser.get_nodes_from_documents([long_doc])
print("SimpleNodeParser拆分的节点数量:", len(simple_nodes))
for i, node in enumerate(simple_nodes):
print(f"节点{i+1}(简单拆分):", node.text)
# 3. 方式2:使用SentenceSplitter(按句子拆分,更贴合语义)
sentence_parser = SentenceSplitter(
chunk_size=100,
chunk_overlap=10,
separator="。" # 中文句子分隔符
)
sentence_nodes = sentence_parser.get_nodes_from_documents([long_doc])
print("nSentenceSplitter拆分的节点数量:", len(sentence_nodes))
for i, node in enumerate(sentence_nodes):
print(f"节点{i+1}(句子拆分):", node.text)代码说明:创建了一个长文档,分别使用SimpleNodeParser(按固定字符长度拆分)和SentenceSplitter(按句子拆分)进行拆分,展示了不同节点解析器的拆分效果。句子拆分更贴合语义,能避免拆分后句子断裂,是更常用的拆分方式。
2.2.5 文本分割器
文本分割器(Text Splitter)是节点解析器的"核心组件",负责具体的文本拆分逻辑,本质是将长文本按照指定规则拆分为短文本片段,是实现文档到节点转换的关键。
与节点解析器的区别:节点解析器是"上层工具",负责调用文本分割器、处理节点元数据、维护节点关联关系;文本分割器是"底层工具",仅负责文本拆分,不涉及节点的其他处理。
LlamaIndex内置的文本分割器与节点解析器一一对应,常见的有:CharacterSplitter(字符分割器)、SentenceSplitter(句子分割器)、TokenSplitter(Token分割器)、RecursiveCharacterSplitter(递归字符分割器)等。
核心参数:
-
chunk_size:每个拆分片段的最大长度(可按字符、Token计算);
-
chunk_overlap:拆分片段之间的重叠长度,避免上下文断裂;
-
separator:拆分分隔符(如换行符、句号、逗号等)。
代码示例(使用文本分割器直接拆分文本):
python
from llama_index.core.text_splitter import CharacterSplitter, TokenSplitter
# 1. 定义测试文本
test_text = "LlamaIndex是一款开源的LLM应用框架,用于连接LLM和私有数据。它提供了完整的工具链,包括数据加载、索引构建、存储管理和查询检索。"
"使用LlamaIndex,开发者可以快速构建RAG应用,解决LLM无法处理私有数据、上下文窗口有限的问题。"
# 2. 方式1:CharacterSplitter(按字符分割)
char_splitter = CharacterSplitter(
chunk_size=50, # 每个片段最大50个字符
chunk_overlap=5 # 重叠5个字符
)
char_chunks = char_splitter.split_text(test_text)
print("CharacterSplitter拆分结果(按字符):")
for i, chunk in enumerate(char_chunks):
print(f"片段{i+1}:{chunk}")
# 3. 方式2:TokenSplitter(按Token分割,适配LLM的Token计算方式)
# 需安装transformers依赖:pip install transformers
token_splitter = TokenSplitter(
chunk_size=30, # 每个片段最大30个Token
chunk_overlap=3 # 重叠3个Token
)
token_chunks = token_splitter.split_text(test_text)
print("nTokenSplitter拆分结果(按Token):")
for i, chunk in enumerate(token_chunks):
print(f"片段{i+1}:{chunk}")代码说明:直接使用文本分割器拆分文本,展示了按字符和按Token两种拆分方式。按Token拆分更贴合LLM的处理逻辑,能避免拆分后的片段超出LLM的上下文窗口,适合用于RAG场景。
2.2.6 摄取管道
摄取管道(Ingestion Pipeline)是LlamaIndex中"数据加载-解析-处理"的一站式工具,将文档加载、节点解析、文本分割、元数据提取等多个步骤整合为一个流水线,无需手动依次执行每个步骤,大幅提升数据处理的效率。
摄取管道的核心优势:可配置化、可扩展,支持添加多个处理步骤(如拆分、元数据提取、嵌入生成),同时支持批量处理文档,适合大规模数据的摄取。
核心流程:文档输入 → 文本分割/节点解析 → 元数据提取 → 嵌入生成(可选) → 节点输出,每个步骤可灵活配置,也可自定义添加处理逻辑。
代码示例(使用摄取管道处理文档):
python
from llama_index.core import Document, IngestionPipeline
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.extractors import TitleExtractor # 元数据提取器(提取标题)
from llama_index.embeddings.openai import OpenAIEmbeddings # 嵌入生成器(需安装依赖)
import os
from dotenv import load_dotenv
# 1. 加载环境变量(使用OpenAI嵌入需配置API密钥)
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 准备测试文档
documents = [
Document(
text="LlamaIndex入门指南nLlamaIndex是一款开源的LLM应用框架,用于连接LLM和私有数据。"
"它提供了数据加载、索引构建、存储管理和查询检索等功能,帮助开发者快速构建RAG应用。",
metadata={"source": "入门文档"}
),
Document(
text="LlamaIndex核心功能n1. 数据加载:支持本地文件、数据库、API等多种数据源;"
"2. 索引构建:支持向量索引、属性图表索引等多种索引类型;"
"3. 查询检索:支持问答、聊天等多种查询方式。",
metadata={"source": "功能文档"}
)
]
# 3. 创建摄取管道,配置处理步骤
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=100, chunk_overlap=10), # 步骤1:句子拆分
TitleExtractor(), # 步骤2:提取标题作为元数据
OpenAIEmbeddings() # 步骤3:生成节点的嵌入向量(可选)
]
)
# 4. 执行摄取管道,处理文档,生成节点
nodes = pipeline.run(documents=documents)
print(f"摄取管道处理后生成的节点数量:{len(nodes)}")
# 5. 查看节点信息(包含拆分后的文本、提取的标题元数据、嵌入向量)
for i, node in enumerate(nodes):
print(f"n节点{i+1}:")
print(f"文本:{node.text}")
print(f"元数据(含提取的标题):{node.metadata}")
print(f"嵌入向量长度:{len(node.embedding) if node.embedding else '未生成'}")代码说明:创建了一个包含三个处理步骤的摄取管道,分别是句子拆分、标题提取、嵌入生成,处理两个测试文档并生成节点。运行代码前需安装依赖(pip install llama-index-embeddings-openai python-dotenv),并配置OpenAI API密钥。
2.3 索引
索引(Index)是LlamaIndex的核心组件,本质是对节点数据的"结构化组织",目的是提升查询检索的效率和精度。通过构建索引,LlamaIndex可以快速定位到与用户查询相关的节点,避免对所有节点进行遍历,大幅提升检索速度。
LlamaIndex支持多种索引类型,每种索引类型有其适用场景,核心索引类型包括:向量存储索引、属性图表索引、文件管理索引等,同时支持索引的动态更新、删除和刷新。
索引的核心作用:
-
结构化组织节点数据,建立检索索引;
-
快速匹配用户查询与相关节点,提升检索效率;
-
支持动态更新,可新增、删除、修改节点;
-
适配不同的查询场景,提供多样化的检索方式。
2.3.1 向量存储索引
向量存储索引(Vector Store Index)是LlamaIndex中最常用的索引类型,基于向量嵌入技术,将每个节点转换为向量(嵌入向量),并存储到向量数据库中,查询时通过计算用户查询向量与节点向量的相似度,快速检索出相关节点。
核心原理:利用向量嵌入(将文本转换为数值向量)的语义相似度,匹配用户查询与节点,适合语义检索场景(如问答、摘要),是RAG应用的核心索引类型。
适用场景:私有文档问答、语义检索、摘要生成等,几乎适用于所有LLM应用场景。
代码示例(构建向量存储索引并进行检索):
python
from llama_index.core import VectorStoreIndex, Document, SimpleDirectoryReader
from llama_index.embeddings.openai import OpenAIEmbeddings
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
import os
from dotenv import load_dotenv
# 1. 加载环境变量,配置OpenAI API密钥
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 准备数据(可加载本地文件,也可手动创建文档)
# 方式1:加载本地文件(使用目录读取器)
# reader = SimpleDirectoryReader("./llamaindex_test_data")
# documents = reader.load_data()
# 方式2:手动创建文档
documents = [
Document(
text="LlamaIndex的向量存储索引基于向量嵌入技术,将节点转换为向量存储,支持语义检索。",
metadata={"source": "向量索引文档"}
),
Document(
text="向量嵌入是将文本转换为数值向量的技术,能捕捉文本的语义信息,用于相似度计算。",
metadata={"source": "向量嵌入文档"}
)
]
# 3. 初始化Chroma向量存储(本地持久化,避免每次重新构建索引)
chroma_client = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = chroma_client.get_or_create_collection("vector_index_test")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# 4. 构建向量存储索引
index = VectorStoreIndex.from_documents(
documents,
vector_store=vector_store,
embed_model=OpenAIEmbeddings(), # 指定嵌入模型
show_progress=True # 显示构建进度
)
# 5. 进行检索(两种方式:直接检索节点、通过查询引擎查询)
# 方式1:直接检索节点(获取与查询相关的前2个节点)
retriever = index.as_retriever(similarity_top_k=2)
query = "什么是向量嵌入?"
retrieved_nodes = retriever.retrieve(query)
print("检索到的节点:")
for i, node in enumerate(retrieved_nodes):
print(f"节点{i+1}:{node.text},相似度:{node.score:.4f}")
# 方式2:通过查询引擎查询(直接获取LLM生成的回答)
query_engine = index.as_query_engine()
response = query_engine.query(query)
print(f"n查询回答:{response}")代码说明:使用Chroma向量数据库构建向量存储索引,手动创建两个测试文档,将文档转换为向量并存储到本地,然后通过检索器检索相关节点,同时通过查询引擎获取LLM生成的回答。运行代码前需安装依赖(pip install llama-index-vector-stores-chroma chromadb)。
2.3.2 属性图表索引
属性图表索引(Property Graph Index)是基于知识图谱的索引类型,将节点数据转换为"实体-关系-属性"的图表结构,存储实体之间的关联关系,适合需要挖掘实体关联的场景(如知识问答、关系推理)。
核心原理:将文档中的实体(如人物、事物、概念)和实体之间的关系(如包含、关联、因果)提取出来,构建知识图谱,查询时通过遍历图谱,获取与查询相关的实体和关系,生成更精准的回答。
适用场景:知识问答、关系推理、实体检索等,适合需要挖掘数据关联的场景。
代码示例(构建属性图表索引并查询):
python
from llama_index.core import PropertyGraphIndex, Document
from llama_index.core.indices.property_graph import SimpleLLMPathExtractor
from llama_index.llms.openai import OpenAI
import os
from dotenv import load_dotenv
# 1. 加载环境变量,配置OpenAI API密钥
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 准备测试文档(包含实体和关系)
documents = [
Document(
text="LlamaIndex是一款开源的LLM应用框架,由Run Llama团队开发,支持数据加载、索引构建、查询检索等功能。"
"它可以与OpenAI、Hugging Face等LLM模型集成,用于构建RAG应用。",
metadata={"source": "知识图谱文档"}
)
]
# 3. 配置LLM和图谱提取器(用于提取实体和关系)
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
kg_extractor = SimpleLLMPathExtractor(
llm=llm,
max_paths_per_chunk=5 # 每个文档片段最多提取5个实体关系对
)
# 4. 构建属性图表索引
index = PropertyGraphIndex.from_documents(
documents,
kg_extractors=[kg_extractor], # 指定图谱提取器
show_progress=True
)
# 5. 保存索引(持久化,避免重新构建)
index.storage_context.persist(persist_dir="./property_graph_index")
# 6. 进行查询(支持关系查询、实体查询)
query_engine = index.as_query_engine(
include_text=True, # 回答中包含原始文本片段
similarity_top_k=2 # 检索前2个相关节点
)
# 查询1:实体关系查询
response1 = query_engine.query("LlamaIndex由哪个团队开发?")
print("查询1回答:", response1)
# 查询2:功能查询
response2 = query_engine.query("LlamaIndex支持哪些功能?")
print("查询2回答:", response2)代码说明:使用SimpleLLMPathExtractor提取文档中的实体和关系,构建属性图表索引,然后通过查询引擎进行实体关系查询和功能查询。运行代码前需安装依赖(pip install llama-index-llms-openai),并配置OpenAI API密钥。
2.3.3 文件管理索引
文件管理索引(Document Management Index)是用于管理文档生命周期的索引类型,核心作用是跟踪文档的新增、删除、更新和刷新,确保索引与原始文档保持同步,适合文档频繁更新的场景(如企业知识库、动态文档库)。
核心功能:支持文档的插入、删除、更新、刷新操作,自动维护索引与文档的关联关系,无需手动重新构建索引,提升文档管理的效率。
适用场景:企业知识库、动态文档库、需要频繁更新文档的RAG应用等。
代码示例(使用文件管理索引管理文档):
python
from llama_index.core import SummaryIndex, Document
from llama_index.core.storage import StorageContext
from llama_index.core.docstore import SimpleDocumentStore
# 1. 初始化存储上下文(用于持久化文档和索引)
doc_store = SimpleDocumentStore()
storage_context = StorageContext.from_defaults(docstore=doc_store)
# 2. 初始化文件管理索引(使用SummaryIndex作为基础索引)
index = SummaryIndex([], storage_context=storage_context)
# 3. 插入文档(新增文档)
doc1 = Document(text="这是第一个文档,用于测试文件管理索引的插入功能。", id_="doc_1")
doc2 = Document(text="这是第二个文档,后续会进行更新。", id_="doc_2")
index.insert(doc1)
index.insert(doc2)
print("插入文档后,索引中的文档数量:", len(index.ref_doc_info))
# 4. 查询文档(验证插入结果)
query_engine = index.as_query_engine()
response = query_engine.query("第二个文档的内容是什么?")
print("查询结果(插入后):", response)
# 5. 更新文档(修改已有文档的内容)
updated_doc2 = Document(text="这是更新后的第二个文档,内容已修改。", id_="doc_2")
index.update_ref_doc(updated_doc2)
response_updated = query_engine.query("第二个文档的内容是什么?")
print("查询结果(更新后):", response_updated)
# 6. 删除文档(删除指定ID的文档)
index.delete_ref_doc("doc_1", delete_from_docstore=True)
print("删除文档后,索引中的文档数量:", len(index.ref_doc_info))
# 7. 刷新文档(批量更新文档,自动检测变化)
new_docs = [
Document(text="这是更新后的第二个文档,内容再次修改。", id_="doc_2"),
Document(text="这是新增的第三个文档,用于测试刷新功能。", id_="doc_3")
]
refreshed = index.refresh_ref_docs(new_docs)
print("刷新文档结果(是否更新/新增):", refreshed)
response_refresh = query_engine.query("第三个文档的内容是什么?")
print("查询结果(刷新后):", response_refresh)代码说明:使用SummaryIndex作为基础索引,实现文档的插入、更新、删除和刷新操作,展示了文件管理索引的核心功能。刷新操作会自动检测文档的变化,更新已有文档并新增未存在的文档,适合动态文档管理场景。
2.3.4 元数据提取
元数据提取(Metadata Extraction)是索引构建的辅助功能,核心作用是从文档或节点中提取额外的元数据(如标题、作者、日期、关键词等),丰富节点的信息,提升检索精度和结果的可解释性。
元数据的作用:
-
辅助检索:可根据元数据(如作者、日期)过滤检索结果,提升检索精度;
-
结果解释:检索结果中展示元数据,方便用户了解节点的来源和背景;
-
结构化组织:通过元数据对节点进行分类,便于后续管理和查询。
LlamaIndex内置了多种元数据提取器,如TitleExtractor(标题提取器)、KeywordExtractor(关键词提取器)等,同时支持自定义元数据提取器。
代码示例(提取文档元数据):
python
from llama_index.core import Document, IngestionPipeline
from llama_index.core.extractors import TitleExtractor, KeywordExtractor
from llama_index.llms.openai import OpenAI
import os
from dotenv import load_dotenv
# 1. 加载环境变量,配置OpenAI API密钥
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 准备测试文档
documents = [
Document(
text="LlamaIndex元数据提取教程n本文主要介绍LlamaIndex中的元数据提取功能,包括标题提取、关键词提取等。"
"元数据提取能丰富节点信息,提升检索精度,适用于各类RAG应用场景。",
metadata={"source": "教程文档", "create_time": "2026-04-06"}
)
]
# 3. 配置元数据提取器
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
extractors = [
TitleExtractor(llm=llm), # 提取标题作为元数据
KeywordExtractor(llm=llm, max_keywords=5) # 提取最多5个关键词作为元数据
]
# 4. 创建摄取管道,执行元数据提取
pipeline = IngestionPipeline(transformations=extractors)
nodes = pipeline.run(documents=documents)
# 5. 查看提取的元数据
for node in nodes:
print("节点文本:", node.text)
print("提取的元数据:", node.metadata)
# 元数据中会新增title(标题)和keywords(关键词)字段
print("提取的标题:", node.metadata.get("title"))
print("提取的关键词:", node.metadata.get("keywords"))代码说明:使用TitleExtractor和KeywordExtractor提取文档的标题和关键词,作为节点的元数据,展示了元数据提取的过程和效果。提取的元数据可用于后续的检索过滤和结果解释。
2.4 存储
存储(Storage)是LlamaIndex的"数据底座",负责保存索引、文档、节点、嵌入向量等所有数据,确保数据的持久化和可复用,避免每次使用时重新构建索引和加载数据。
LlamaIndex的存储体系由多个可插拔的子模块构成,每个模块负责管理特定类型的数据,由统一的StorageContext(存储上下文)进行管理,既能使用内置的轻量级存储,也能替换为企业级基础设施,灵活性极高。
核心存储类型包括:向量存储、文档存储、索引存储、键值存储,同时支持自定义存储,适配不同的业务需求。
2.4.1 向量存储
向量存储(Vector Store)是专门用于存储节点嵌入向量的存储组件,核心作用是持久化向量数据,并提供高效的向量相似度查询功能,是向量存储索引的核心依赖。
LlamaIndex支持多种向量存储,包括:内置的内存向量存储(适合测试)、Chroma、Pinecone、FAISS、Milvus等,开发者可根据场景选择合适的向量存储(如本地测试用Chroma,生产环境用Pinecone)。
核心功能:向量的插入、删除、更新、相似度查询,支持批量操作,提升向量处理效率。
代码示例(使用FAISS向量存储持久化向量数据):
python
from llama_index.core import VectorStoreIndex, Document
from llama_index.embeddings.openai import OpenAIEmbeddings
from llama_index.vector_stores.faiss import FaissVectorStore
import faiss
import os
from dotenv import load_dotenv
# 1. 加载环境变量,配置OpenAI API密钥
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 准备测试文档
documents = [
Document(
text="FAISS是Facebook开发的向量检索库,用于高效的向量相似度查询,适合大规模向量数据。",
metadata={"source": "FAISS文档"}
),
Document(
text="LlamaIndex支持FAISS向量存储,可用于本地持久化向量数据,适合测试和小规模应用。",
metadata={"source": "LlamaIndex文档"}
)
]
# 3. 初始化FAISS向量存储(指定维度,与嵌入模型维度一致)
embed_dim = 1536 # OpenAI Embeddings的维度是1536
index = faiss.IndexFlatL2(embed_dim) # 初始化FAISS索引
vector_store = FaissVectorStore(faiss_index=index)
# 4. 构建向量索引并持久化
vector_index = VectorStoreIndex.from_documents(
documents,
vector_store=vector_store,
embed_model=OpenAIEmbeddings()
)
# 5. 保存FAISS向量存储(持久化到本地文件)
faiss.write_index(index, "faiss_vector_store.index")
print("FAISS向量存储已保存到本地")
# 6. 加载本地FAISS向量存储(后续可直接使用,无需重新构建)
loaded_faiss_index = faiss.read_index("faiss_vector_store.index")
loaded_vector_store = FaissVectorStore(faiss_index=loaded_faiss_index)
loaded_index = VectorStoreIndex.from_vector_store(loaded_vector_store)
# 7. 测试加载后的索引
query_engine = loaded_index.as_query_engine()
response = query_engine.query("FAISS是什么?")
print("查询回答:", response)代码说明:使用FAISS向量存储持久化向量数据,将向量索引保存到本地文件,后续可直接加载使用,避免重新构建索引。运行代码前需安装依赖(pip install llama-index-vector-stores-faiss faiss-cpu)。
2.4.2 文档存储
文档存储(Document Store)是用于存储文档和节点的存储组件,核心作用是持久化文档和节点数据,维护文档与节点的关联关系,确保数据不丢失,可复用。
文档存储与向量存储的区别:文档存储存储的是原始文档和节点的文本、元数据;向量存储存储的是节点的嵌入向量,二者分工不同,共同构成LlamaIndex的存储体系。
LlamaIndex内置了多种文档存储,如SimpleDocumentStore(简单文档存储,内存/本地文件)、MongoDocumentStore(MongoDB文档存储)、PostgresDocumentStore(PostgreSQL文档存储)等。
代码示例(使用SimpleDocumentStore持久化文档和节点):
python
from llama_index.core import Document, SimpleDocumentStore, StorageContext
from llama_index.core.node_parser import SentenceSplitter
# 1. 初始化文档存储(本地持久化,保存到文件)
doc_store = SimpleDocumentStore.from_persist_dir(persist_dir="./doc_store")
# 2. 初始化存储上下文,关联文档存储
storage_context = StorageContext.from_defaults(docstore=doc_store)
# 3. 准备文档并拆分节点
documents = [
Document(
text="文档存储用于持久化文档和节点数据,维护文档与节点的关联关系。",
metadata={"source": "文档存储教程"}
)
]
parser = SentenceSplitter(chunk_size=100)
nodes = parser.get_nodes_from_documents(documents)
# 4. 将文档和节点保存到文档存储
doc_store.add_documents(documents + nodes)
# 5. 持久化文档存储(保存到本地目录)
storage_context.persist(persist_dir="./doc_store")
print("文档存储已持久化到本地")
# 6. 加载本地文档存储
loaded_doc_store = SimpleDocumentStore.from_persist_dir(persist_dir="./doc_store")
loaded_storage_context = StorageContext.from_defaults(docstore=loaded_doc_store)
# 7. 查看加载的文档和节点
loaded_documents = loaded_doc_store.get_all_documents()
loaded_nodes = loaded_doc_store.get_all_nodes()
print(f"加载的文档数量:{len(loaded_documents)}")
print(f"加载的节点数量:{len(loaded_nodes)}")
print("加载的文档内容:", loaded_documents[0].text)代码说明:使用SimpleDocumentStore持久化文档和节点数据,将数据保存到本地目录,后续可直接加载使用。SimpleDocumentStore适合小规模应用和测试,生产环境可选择MongoDB、PostgreSQL等更稳定的文档存储。
2.4.3 索引存储
索引存储(Index Store)是用于存储索引结构信息的存储组件,核心作用是持久化索引的元数据、结构信息(如向量索引的关联关系、属性图表索引的图谱结构),确保索引可以被快速加载、修改和复用,避免每次使用时重新构建索引。
简单理解:索引是"数据的组织方式",索引存储就是"保存这种组织方式的说明书",记录索引的类型、配置参数、与文档/节点的关联关系等。
LlamaIndex内置了多种索引存储,如SimpleIndexStore(简单索引存储)、PostgresIndexStore(PostgreSQL索引存储)等,可根据存储需求选择。
代码示例(使用SimpleIndexStore持久化索引):
python
from llama_index.core import VectorStoreIndex, Document, StorageContext
from llama_index.core.storage.index_store import SimpleIndexStore
from llama_index.embeddings.openai import OpenAIEmbeddings
import os
from dotenv import load_dotenv
# 1. 加载环境变量,配置OpenAI API密钥
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 初始化索引存储(本地持久化)
index_store = SimpleIndexStore.from_persist_dir(persist_dir="./index_store")
# 3. 初始化存储上下文,关联索引存储和向量存储(此处使用内存向量存储,仅用于测试)
storage_context = StorageContext.from_defaults(index_store=index_store)
# 4. 准备文档并构建索引
documents = [
Document(
text="索引存储用于持久化索引的结构信息,确保索引可复用,避免重新构建。",
metadata={"source": "索引存储教程"}
)
]
index = VectorStoreIndex.from_documents(
documents,
storage_context=storage_context,
embed_model=OpenAIEmbeddings()
)
# 5. 持久化索引存储
storage_context.persist(persist_dir="./index_store")
print("索引存储已持久化到本地")
# 6. 加载本地索引存储,重建索引(无需重新加载文档和构建向量)
loaded_index_store = SimpleIndexStore.from_persist_dir(persist_dir="./index_store")
loaded_storage_context = StorageContext.from_defaults(index_store=loaded_index_store)
loaded_index = VectorStoreIndex.from_storage(loaded_storage_context)
# 7. 测试加载后的索引
query_engine = loaded_index.as_query_engine()
response = query_engine.query("索引存储的作用是什么?")
print("查询回答:", response)代码说明:使用SimpleIndexStore持久化索引的结构信息,将索引存储到本地,后续可直接加载索引,无需重新加载文档和构建向量,大幅提升效率。
2.4.4 键值存储
键值存储(Key-Value Store)是一种轻量级存储组件,以"键(Key)-值(Value)"对的形式,存储LlamaIndex运行过程中的辅助数据,不存储原始文档、节点或向量,仅用于存储配置信息、缓存数据等。
核心作用:存储非向量、非原始文档的辅助信息,如索引的缓存数据、会话历史(聊天引擎用)、Embedding模型的配置、节点的元数据映射等,提升框架运行效率。
LlamaIndex内置了多种键值存储,如SimpleKVStore(简单键值存储)、RedisKVStore(Redis键值存储)、S3KVStore(S3键值存储)等。
代码示例(使用SimpleKVStore存储配置信息):
python
from llama_index.core.storage.kvstore import SimpleKVStore
import os
# 1. 初始化键值存储(本地持久化,保存到JSON文件)
kv_store = SimpleKVStore.from_persist_dir(persist_dir="./kv_store")
# 2. 存储键值对(模拟存储配置信息)
config_data = {
"embed_model": "openai",
"chunk_size": 100,
"chunk_overlap": 10
}
kv_store.put(key="llamaindex_config", value=config_data)
# 3. 存储会话历史(模拟聊天引擎的会话数据)
chat_history = [
{"role": "user", "content": "什么是LlamaIndex?"},
{"role": "assistant", "content": "LlamaIndex是一款开源的LLM应用框架,用于连接LLM和私有数据,提供完整的数据加载、索引、存储和查询工具链。"}
]
kv_store.put(key="chat_history_1", value=chat_history)
# 4. 读取键值对(获取存储的配置和会话数据)
loaded_config = kv_store.get(key="llamaindex_config")
loaded_chat_history = kv_store.get(key="chat_history_1")
print("加载的配置信息:", loaded_config)
print("加载的会话历史:", loaded_chat_history)
# 5. 删除指定键值对
kv_store.delete(key="chat_history_1")
print("删除会话历史后,是否存在:", kv_store.get(key="chat_history_1")) # 输出None表示已删除
# 6. 持久化键值存储(确保数据保存到本地)
kv_store.persist(persist_dir="./kv_store")
print("键值存储已持久化到本地")
# 7. 加载本地键值存储(后续可直接复用数据)
loaded_kv_store = SimpleKVStore.from_persist_dir(persist_dir="./kv_store")
loaded_config_again = loaded_kv_store.get(key="llamaindex_config")
print("重新加载的配置信息:", loaded_config_again)代码说明:使用SimpleKVStore存储配置信息和会话历史,实现了键值对的存储、读取、删除和持久化操作。SimpleKVStore将数据保存为JSON文件,适合小规模辅助数据的存储,生产环境中若需高性能、高并发的键值存储,可替换为RedisKVStore。
2.5 查询
查询(Query)是LlamaIndex的核心功能之一,本质是用户通过输入问题或指令,从构建好的索引中检索相关节点,并结合LLM生成精准回答的过程。LlamaIndex提供了多样化的查询方式和工具,适配不同的查询场景(如问答、聊天、摘要),同时支持自定义查询逻辑,满足个性化需求。
查询的核心流程:用户输入查询 → 检索器从索引中获取相关节点 → 响应合成器将节点数据与LLM结合 → 生成最终回答,整个流程无需用户手动干预,高效且精准。
LlamaIndex的查询体系主要包括:检索器、查询引擎、聊天引擎、响应合成器,四者协同工作,构成完整的查询链路。
2.5.1 检索器
检索器(Retriever)是查询流程的"数据筛选器",核心作用是根据用户的查询,从索引中快速筛选出最相关的节点,为后续的回答生成提供数据支撑。检索器的检索精度直接影响最终回答的质量,LlamaIndex内置了多种检索器,适配不同的索引类型。
常见的检索器类型:
-
向量检索器(Vector Retriever):适配向量存储索引,通过计算查询与节点的向量相似度检索相关节点,适合语义检索场景;
-
关键词检索器(Keyword Retriever):通过关键词匹配检索节点,适合精准关键词查询场景;
-
属性检索器(Property Retriever):根据节点的元数据(如作者、日期)检索节点,适合过滤式查询场景;
-
混合检索器(Hybrid Retriever):结合向量检索和关键词检索的优势,兼顾语义相似度和关键词匹配,提升检索精度。
代码示例(使用向量检索器和混合检索器检索节点):
python
from llama_index.core import VectorStoreIndex, Document
from llama_index.embeddings.openai import OpenAIEmbeddings
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
from llama_index.core.retrievers import HybridRetriever
from llama_index.core.retrievers import VectorIndexRetriever, KeywordTableRetriever
import os
from dotenv import load_dotenv
# 1. 加载环境变量,配置OpenAI API密钥
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 准备文档并构建向量存储索引
documents = [
Document(
text="LlamaIndex的向量检索器基于向量相似度计算,适合语义检索场景,能精准匹配用户查询的语义。",
metadata={"source": "向量检索器文档"}
),
Document(
text="关键词检索器通过关键词匹配检索节点,适合用户输入明确关键词的查询场景,检索速度快。",
metadata={"source": "关键词检索器文档"}
),
Document(
text="混合检索器结合向量检索和关键词检索的优势,既保证语义匹配精度,又提升关键词查询效率。",
metadata={"source": "混合检索器文档"}
)
]
# 初始化Chroma向量存储
chroma_client = chromadb.PersistentClient(path="./chroma_db_query")
chroma_collection = chroma_client.get_or_create_collection("retriever_test")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# 构建向量存储索引
index = VectorStoreIndex.from_documents(
documents,
vector_store=vector_store,
embed_model=OpenAIEmbeddings()
)
# 3. 方式1:使用向量检索器(语义检索)
vector_retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2 # 检索前2个最相关的节点
)
query = "语义检索适合用什么检索器?"
vector_retrieved_nodes = vector_retriever.retrieve(query)
print("向量检索器检索结果:")
for i, node in enumerate(vector_retrieved_nodes):
print(f"节点{i+1}:{node.text},相似度:{node.score:.4f}")
# 4. 方式2:使用关键词检索器(关键词匹配)
keyword_retriever = KeywordTableRetriever(
index=index,
top_k=2 # 检索前2个匹配的节点
)
query_keyword = "关键词检索器"
keyword_retrieved_nodes = keyword_retriever.retrieve(query_keyword)
print("n关键词检索器检索结果:")
for i, node in enumerate(keyword_retrieved_nodes):
print(f"节点{i+1}:{node.text}")
# 5. 方式3:使用混合检索器(结合两种检索方式)
hybrid_retriever = HybridRetriever(
vector_retriever=vector_retriever,
keyword_retriever=keyword_retriever,
alpha=0.7 # alpha=0.7表示向量检索权重70%,关键词检索权重30%
)
query_hybrid = "哪种检索器兼顾语义和关键词匹配?"
hybrid_retrieved_nodes = hybrid_retriever.retrieve(query_hybrid)
print("n混合检索器检索结果:")
for i, node in enumerate(hybrid_retrieved_nodes):
print(f"节点{i+1}:{node.text},综合得分:{node.score:.4f}")代码说明:分别使用向量检索器、关键词检索器和混合检索器进行检索,展示了不同检索器的适用场景。混合检索器通过调整alpha参数控制两种检索方式的权重,可根据实际需求优化检索精度。
2.5.2 查询引擎
查询引擎(Query Engine)是LlamaIndex的"查询入口",封装了检索器和响应合成器的功能,用户只需调用查询引擎的query方法输入问题,即可直接获取LLM生成的精准回答,无需手动处理检索和合成步骤,是最常用的查询工具。
LlamaIndex内置了多种查询引擎,适配不同的查询场景,常见的有:默认查询引擎、列表查询引擎、树状查询引擎、知识图谱查询引擎等,同时支持自定义查询引擎,扩展查询功能。
核心功能:
-
自动调用检索器获取相关节点;
-
调用响应合成器,结合LLM生成回答;
-
支持过滤条件(如按元数据过滤)、分页等功能;
-
可配置不同的检索和合成策略,适配个性化需求。
代码示例(使用不同查询引擎进行查询):
python
from llama_index.core import VectorStoreIndex, Document, SimpleDirectoryReader
from llama_index.embeddings.openai import OpenAIEmbeddings
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
from llama_index.core.query_engine import ListQueryEngine, TreeQueryEngine
import os
from dotenv import load_dotenv
# 1. 加载环境变量,配置OpenAI API密钥
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 准备文档并构建向量存储索引
documents = [
Document(
text="LlamaIndex的默认查询引擎适用于大多数基础问答场景,自动结合检索和合成功能,操作简单。",
metadata={"source": "默认查询引擎文档"}
),
Document(
text="列表查询引擎将检索到的所有节点按顺序拼接,结合LLM生成回答,适合需要完整上下文的场景。",
metadata={"source": "列表查询引擎文档"}
),
Document(
text="树状查询引擎将检索到的节点构建成树状结构,分层合成回答,适合长文档、多节点的复杂查询场景。",
metadata={"source": "树状查询引擎文档"}
)
]
# 初始化Chroma向量存储并构建索引
chroma_client = chromadb.PersistentClient(path="./chroma_db_query_engine")
chroma_collection = chroma_client.get_or_create_collection("query_engine_test")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
index = VectorStoreIndex.from_documents(
documents,
vector_store=vector_store,
embed_model=OpenAIEmbeddings()
)
# 3. 方式1:默认查询引擎(最常用)
default_query_engine = index.as_query_engine()
response_default = default_query_engine.query("默认查询引擎适用于什么场景?")
print("默认查询引擎回答:", response_default)
# 4. 方式2:列表查询引擎
list_query_engine = ListQueryEngine.from_args(
index=index,
similarity_top_k=3 # 检索所有3个节点
)
response_list = list_query_engine.query("列表查询引擎和树状查询引擎的区别是什么?")
print("n列表查询引擎回答:", response_list)
# 5. 方式3:树状查询引擎
tree_query_engine = TreeQueryEngine.from_args(
index=index,
num_children=2 # 每个节点下有2个子节点,构建树状结构
)
response_tree = tree_query_engine.query("树状查询引擎适合什么场景?")
print("n树状查询引擎回答:", response_tree)
# 6. 带过滤条件的查询引擎(按元数据过滤)
filtered_query_engine = index.as_query_engine(
filters=[
{
"key": "source",
"operator": "==",
"value": "默认查询引擎文档" # 只检索source为默认查询引擎文档的节点
}
]
)
response_filtered = filtered_query_engine.query("默认查询引擎的特点是什么?")
print("n带过滤条件的查询引擎回答:", response_filtered)代码说明:展示了默认查询引擎、列表查询引擎、树状查询引擎的使用方法,同时演示了带元数据过滤的查询功能。不同查询引擎适配不同场景,可根据查询需求选择合适的引擎类型。
2.5.3 聊天引擎
聊天引擎(Chat Engine)是专门用于多轮对话场景的查询工具,与查询引擎的区别在于:查询引擎适用于单轮问答(用户问一次,系统答一次),而聊天引擎支持多轮对话,能记忆上下文,结合历史对话内容生成回答,更贴合日常聊天场景。
LlamaIndex内置了多种聊天引擎,常见的有:SimpleChatEngine(简单聊天引擎)、ContextChatEngine(上下文聊天引擎)、CondenseQuestionChatEngine(压缩问题聊天引擎)等,每种聊天引擎有其适用场景。
核心特点:
-
记忆对话上下文,无需用户重复输入历史问题;
-
支持对话历史的持久化和加载,可恢复之前的对话;
-
可配置检索策略,结合索引数据生成回答,避免编造信息;
-
支持自定义对话语气、格式,适配个性化需求。
代码示例(使用聊天引擎进行多轮对话):
python
from llama_index.core import VectorStoreIndex, Document
from llama_index.embeddings.openai import OpenAIEmbeddings
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
from llama_index.core.chat_engine import SimpleChatEngine, ContextChatEngine
from llama_index.llms.openai import OpenAI
import os
from dotenv import load_dotenv
# 1. 加载环境变量,配置OpenAI API密钥
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 准备文档并构建向量存储索引
documents = [
Document(
text="LlamaIndex的聊天引擎支持多轮对话,能记忆上下文,结合索引数据生成精准回答,避免编造信息。",
metadata={"source": "聊天引擎文档"}
),
Document(
text="SimpleChatEngine适用于简单多轮对话场景,无需复杂配置;ContextChatEngine支持结合检索上下文,适合需要索引数据的多轮对话。",
metadata={"source": "聊天引擎类型文档"}
)
]
# 初始化Chroma向量存储并构建索引
chroma_client = chromadb.PersistentClient(path="./chroma_db_chat")
chroma_collection = chroma_client.get_or_create_collection("chat_engine_test")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
index = VectorStoreIndex.from_documents(
documents,
vector_store=vector_store,
embed_model=OpenAIEmbeddings()
)
# 3. 方式1:SimpleChatEngine(简单多轮对话)
simple_chat_engine = SimpleChatEngine.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo"),
index=index
)
print("=== SimpleChatEngine 多轮对话 ===")
response1 = simple_chat_engine.chat("LlamaIndex的聊天引擎支持多轮对话吗?")
print("用户:LlamaIndex的聊天引擎支持多轮对话吗?")
print("助手:", response1)
response2 = simple_chat_engine.chat("有哪些类型的聊天引擎?")
print("用户:有哪些类型的聊天引擎?")
print("助手:", response2)
# 4. 方式2:ContextChatEngine(结合检索上下文的多轮对话)
context_chat_engine = ContextChatEngine.from_defaults(
retriever=index.as_retriever(similarity_top_k=2),
llm=OpenAI(model="gpt-3.5-turbo"),
chat_mode="context" # 结合检索上下文生成回答
)
print("n=== ContextChatEngine 多轮对话 ===")
response3 = context_chat_engine.chat("ContextChatEngine适合什么场景?")
print("用户:ContextChatEngine适合什么场景?")
print("助手:", response3)
response4 = context_chat_engine.chat("它和SimpleChatEngine有什么区别?")
print("用户:它和SimpleChatEngine有什么区别?")
print("助手:", response4)
# 5. 保存对话历史并加载
chat_history = context_chat_engine.chat_history # 获取对话历史
print("n保存的对话历史:", chat_history)
# 加载对话历史(恢复之前的对话)
new_context_chat_engine = ContextChatEngine.from_defaults(
retriever=index.as_retriever(similarity_top_k=2),
llm=OpenAI(model="gpt-3.5-turbo"),
chat_history=chat_history
)
response5 = new_context_chat_engine.chat("刚才说的两种聊天引擎,哪种更简单?")
print("用户:刚才说的两种聊天引擎,哪种更简单?")
print("助手:", response5)代码说明:分别使用SimpleChatEngine和ContextChatEngine进行多轮对话,展示了聊天引擎的上下文记忆功能,同时演示了对话历史的保存和加载。ContextChatEngine结合检索上下文生成回答,更适合需要结合索引数据的多轮对话场景。
2.5.4 响应合成器
响应合成器(Response Synthesizer)是查询流程的"回答生成器",核心作用是将检索器获取的相关节点数据,结合用户的查询,通过LLM生成最终的回答。响应合成器的合成策略直接影响回答的质量和格式,LlamaIndex内置了多种合成策略,适配不同的场景。
常见的合成策略:
-
简单合成(Simple Synthesis):将所有相关节点拼接后,输入LLM生成回答,适合节点数量少、上下文简单的场景;
-
树状合成(Tree Synthesis):将节点构建成树状结构,分层合成回答,适合节点数量多、上下文复杂的场景;
-
摘要合成(Summary Synthesis):对相关节点进行摘要,生成简洁的回答,适合需要简短回答的场景;
-
精炼合成(Refine Synthesis):先基于第一个节点生成初步回答,再结合后续节点逐步精炼,提升回答精度。
代码示例(使用不同合成策略生成回答):
python
from llama_index.core import VectorStoreIndex, Document
from llama_index.embeddings.openai import OpenAIEmbeddings
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
from llama_index.core.response_synthesizers import (
SimpleResponseSynthesizer,
TreeResponseSynthesizer,
SummaryResponseSynthesizer,
RefineResponseSynthesizer
)
from llama_index.core.query_engine import RetrieverQueryEngine
import os
from dotenv import load_dotenv
# 1. 加载环境变量,配置OpenAI API密钥
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 2. 准备文档并构建向量存储索引
documents = [
Document(
text="响应合成器是LlamaIndex查询流程的核心组件,负责将检索到的节点数据结合用户查询,生成最终回答。",
metadata={"source": "响应合成器文档1"}
),
Document(
text="简单合成策略将所有相关节点拼接后输入LLM,适合节点数量少的场景,操作简单、效率高。",
metadata={"source": "响应合成器文档2"}
),
Document(
text="树状合成策略将节点构建成树状结构,分层合成回答,适合节点数量多、上下文复杂的场景,回答更精准。",
metadata={"source": "响应合成器文档3"}
),
Document(
text="摘要合成策略对相关节点进行摘要,生成简洁的回答,适合需要简短、精炼回答的场景;精炼合成策略逐步优化回答,提升精度。",
metadata={"source": "响应合成器文档4"}
)
]
# 初始化Chroma向量存储并构建索引
chroma_client = chromadb.PersistentClient(path="./chroma_db_synthesizer")
chroma_collection = chroma_client.get_or_create_collection("synthesizer_test")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
index = VectorStoreIndex.from_documents(
documents,
vector_store=vector_store,
embed_model=OpenAIEmbeddings()
)
# 3. 准备检索器(获取相关节点)
retriever = index.as_retriever(similarity_top_k=4)
# 4. 方式1:简单合成策略
simple_synthesizer = SimpleResponseSynthesizer()
simple_query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=simple_synthesizer
)
response_simple = simple_query_engine.query("响应合成器有哪些合成策略?")
print("简单合成策略回答:", response_simple)
# 5. 方式2:树状合成策略
tree_synthesizer = TreeResponseSynthesizer(
num_children=2 # 每个节点下有2个子节点,构建树状结构
)
tree_query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=tree_synthesizer
)
response_tree = tree_query_engine.query("树状合成策略适合什么场景?")
print("n树状合成策略回答:", response_tree)
# 6. 方式3:摘要合成策略
summary_synthesizer = SummaryResponseSynthesizer(
response_mode="tree_summarize" # 按树状结构摘要
)
summary_query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=summary_synthesizer
)
response_summary = summary_query_engine.query("请简要说明响应合成器的作用和常见策略。")
print("n摘要合成策略回答:", response_summary)
# 7. 方式4:精炼合成策略
refine_synthesizer = RefineResponseSynthesizer()
refine_query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=refine_synthesizer
)
response_refine = refine_query_engine.query("详细说明不同合成策略的适用场景。")
print("n精炼合成策略回答:", response_refine)代码说明:分别使用四种常见的合成策略生成回答,展示了不同合成策略的特点和适用场景。可根据节点数量、上下文复杂度和回答需求,选择合适的合成策略,提升回答质量。
2.6 总结
本章系统讲解了LlamaIndex的核心基本概念,涵盖提示、加载、索引、存储、查询五大核心模块,每个模块都配套了可直接运行的代码示例和详细注释,帮助读者快速理解和上手。
LlamaIndex的核心价值在于搭建了LLM与私有数据之间的"桥梁",通过完整的工具链,解决了LLM上下文窗口有限、无法处理私有数据、检索精度不足等痛点,让开发者无需从零构建复杂的RAG流程,即可快速搭建企业级知识库、问答系统等LLM应用。
核心模块关联关系:加载模块将多源数据转换为文档和节点,索引模块对节点进行结构化组织,存储模块持久化所有数据,查询模块通过检索和合成生成回答,提示模块则贯穿整个流程,优化LLM的交互效果。
后续章节将基于本章的基本概念,讲解LlamaIndex的实际应用场景、进阶技巧和性能优化方法,帮助读者进一步提升LlamaIndex的使用能力,实现更复杂的LLM应用开发。
python
from llama_index.core.storage.kvstore import SimpleKVStore
import os
# 1. 初始化键值存储(本地持久化,保存到JSON文件)
kv_store = SimpleKVStore.from_persist_dir(persist_dir="./kv_store")
# 2. 存储键值对(模拟存储配置信息)
config_data = {
"embed_model": "openai",
"chunk_size": 100,
"chunk_overlap": 10
}
kv_store.put(key="llamaindex_config", value=config_data)
# 3. 存储会话历史(模拟聊天引擎的会话数据)
chat_history = [
{"role": "user", "content": "什么是LlamaIndex?"},
{"role": "assistant", "content": "LlamaIndex是一款开源的LLM应用框架,用于连接LLM和私有数据,提供完整的数据加载、索引、存储和查询工具链。"}
]
kv_store.put(key="chat_history_1", value=chat_history)
# 4. 读取键值对(获取存储的配置和会话数据)
loaded_config = kv_store.get(key="llamaindex_config")
loaded_chat_history = kv_store.get(key="chat_history_1")
print("加载的配置信息:", loaded_config)
print("加载的会话历史:", loaded_chat_history)
# 5. 删除指定键值对
kv_store.delete(key="chat_history_1")
print("删除会话历史后,是否存在:", kv_store.get(key="chat_history_1")) # 输出None表示已删除
# 6. 持久化键值存储(确保数据保存到本地)
kv_store.persist(persist_dir="./kv_store")
print("键值存储已持久化到本地")
# 7. 加载本地键值存储(后续可直接复用数据)
loaded_kv_store = SimpleKVStore.from_persist_dir(persist_dir="./kv_store")
loaded_config_again = loaded_kv_store.get(key="llamaindex_config")
print("重新加载的配置信息:", loaded_config_again)三、本章练习题及其答案
3.1 选择题
(每题只有一个正确答案,共5题)
-
下列关于LlamaIndex中"提示(Prompt)"的描述,错误的是( )
-
A. 提示是LlamaIndex与LLM交互的核心载体
-
B. LlamaIndex的提示需要用户手动拼接上下文和查询意图
-
C. 提示的质量会直接影响LLM的响应效果
-
D. LlamaIndex内置了丰富的默认提示模板
-
-
LlamaIndex中,用于将多源数据转换为可识别格式的核心模块是( )
-
A. 索引模块
-
B. 加载模块
-
C. 存储模块
-
D. 查询模块
-
-
下列哪种索引类型是LlamaIndex中最常用的,基于向量嵌入技术实现语义检索( )
-
A. 属性图表索引
-
B. 文件管理索引
-
C. 向量存储索引
-
D. 元数据索引
-
-
关于LlamaIndex中的"文档(Document)"和"节点(Node)",下列说法正确的是( )
-
A. 文档是节点拆分后的片段,节点是完整的数据源
-
B. 节点是文档拆分后的片段,文档是完整的数据源
-
C. 文档和节点是完全独立的,没有关联关系
-
D. 索引构建和检索操作基于文档,而非节点
-
-
下列哪种存储组件专门用于存储节点的嵌入向量,支持高效的相似度查询( )
-
A. 文档存储
-
B. 向量存储
-
C. 索引存储
-
D. 键值存储
-
3.1 选择题答案
B(解析:LlamaIndex的提示会自动整合数据上下文、查询意图,无需用户手动拼接)
B(解析:加载模块的核心作用是将多源数据转换为LlamaIndex可识别的文档和节点格式)
C(解析:向量存储索引基于向量嵌入技术,是最常用的索引类型,适合语义检索场景)
B(解析:文档是完整的数据源,节点是文档拆分后的片段,索引和检索操作基于节点)
B(解析:向量存储专门用于存储嵌入向量,提供高效的向量相似度查询功能)
3.2 填空题
(共5题,每空1分)
-
LlamaIndex曾用名是__________,它是一款开源的Python数据框架,核心作用是搭建LLM与__________之间的桥梁。
-
提示(Prompt)的本质是一段__________,用于告诉LLM"该做什么、怎么做"。
-
LlamaIndex中,__________是文档的拆分单元,是索引构建和检索的最小操作单位。
-
向量存储索引的核心原理是利用__________技术,将节点转换为向量,通过计算相似度实现检索。
-
LlamaIndex的存储体系由StorageContext统一管理,核心存储类型包括向量存储、文档存储、__________和键值存储。
3.2 填空题答案
GPT Index;私有数据
结构化的文本指令
节点(Node)
向量嵌入
索引存储
3.3 简答题
(共3题,每题10分)
-
简述LlamaIndex中"提示(Prompt)"的核心特点。
-
简述LlamaIndex加载模块的核心流程,以及该模块包含的主要组件。
-
简述向量存储索引和属性图表索引的适用场景区别。
3.3 简答题答案
- (10分)提示的核心特点有3点:
① 结构化设计:默认提示模板包含系统指令、上下文、用户问题等固定格式,确保LLM清晰理解任务;
② 动态适配:会根据检索到的节点数据、用户查询类型,自动填充提示内容,无需手动修改;
③ 高度可定制:支持修改默认模板、添加自定义指令(如格式、语气要求),适配个性化场景需求。
- (10分) 核心流程:
数据来源 → 读取数据 → 转换为文档对象 → (可选)解析为节点 → 进入摄取管道;
② (10分)主要组件:
文档和节点、目录读取器(如SimpleDirectoryReader)、数据连接器、节点解析器、文本分割器、摄取管道。
- (10分)它们的适用场景如下:
① 向量存储索引 :基于向量嵌入技术,通过相似度计算实现检索,适合语义检索场景,如私有文档问答、摘要生成等,是最常用的索引类型;
② 属性图表索引:基于知识图谱,将节点转换为"实体-关系-属性"结构,适合需要挖掘实体关联的场景,如知识问答、关系推理、实体检索等。
3.4 实操题
(共1题,20分)
要求:使用LlamaIndex编写代码,完成以下操作,代码需带详细注释,确保可运行。
-
创建2个测试文档,文档内容围绕"LlamaIndex提示模块"展开,自定义元数据(如source、create_time);
-
使用SentenceSplitter将文档拆分为节点,设置chunk_size=100,chunk_overlap=10;
-
构建向量存储索引(使用Chroma向量存储,本地持久化);
-
创建查询引擎,查询"LlamaIndex的提示有哪些特点",并输出查询结果。
3.4 实操题答案(可运行代码)
python
# 1. 安装所需依赖(若未安装,执行以下命令)
# pip install llama-index-core llama-index-vector-stores-chroma chromadb llama-index-embeddings-openai python-dotenv
# 2. 导入所需模块
from llama_index.core import Document, VectorStoreIndex
from llama_index.core.node_parser import SentenceSplitter
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
from llama_index.embeddings.openai import OpenAIEmbeddings
import os
from dotenv import load_dotenv
# 3. 加载环境变量,配置OpenAI API密钥(需提前创建.env文件,写入OPENAI_API_KEY=你的密钥)
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
# 4. 步骤1:创建2个测试文档,自定义元数据
documents = [
Document(
text="LlamaIndex的提示是与LLM交互的核心,内置丰富默认模板,覆盖索引、查询等全流程。它能自动整合上下文,无需手动拼接指令,降低LLM调用门槛。",
metadata={
"source": "提示模块测试文档1",
"create_time": "2026-04-06",
"author": "AI爱好者"
}
),
Document(
text="LlamaIndex的提示具有结构化、动态适配和高度可定制的特点。结构化设计确保LLM理解任务,动态适配能自动填充内容,可定制性支持个性化指令修改。",
metadata={
"source": "提示模块测试文档2",
"create_time": "2026-04-06",
"author": "AI爱好者"
}
)
]
# 5. 步骤2:使用SentenceSplitter拆分文档为节点
# 配置拆分参数:每个节点最大100字符,重叠10字符,按中文句号分隔
splitter = SentenceSplitter(
chunk_size=100,
chunk_overlap=10,
separator="。"
)
# 将文档拆分为节点
nodes = splitter.get_nodes_from_documents(documents)
print(f"文档拆分后生成的节点数量:{len(nodes)}")
# 6. 步骤3:构建向量存储索引(Chroma本地持久化)
# 初始化Chroma客户端,持久化到本地chroma_prompt_db目录
chroma_client = chromadb.PersistentClient(path="./chroma_prompt_db")
# 创建或获取集合(用于存储向量数据)
chroma_collection = chroma_client.get_or_create_collection("prompt_test_collection")
# 初始化Chroma向量存储
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# 构建向量存储索引,指定嵌入模型
index = VectorStoreIndex.from_documents(
documents, # 可直接传入文档,内部会自动拆分(也可传入nodes)
vector_store=vector_store,
embed_model=OpenAIEmbeddings(), # 使用OpenAI嵌入模型生成向量
show_progress=True # 显示索引构建进度
)
# 7. 步骤4:创建查询引擎,执行查询
# 生成查询引擎
query_engine = index.as_query_engine()
# 定义查询问题
query = "LlamaIndex的提示有哪些特点?"
# 执行查询并获取结果
response = query_engine.query(query)
# 输出查询结果
print("n查询问题:", query)
print("查询结果:", response)代码说明:该代码完整实现了题目要求的4个操作,注释详细,可直接运行。运行前需安装对应依赖,配置OpenAI
API密钥;Chroma向量存储会持久化到本地,后续可直接加载使用,无需重新构建索引。
四、总结
本文以教案风格,系统讲解了LlamaIndex的核心基本概念,面向多类受众,兼顾理论与实操。重点介绍了提示、加载、索引、存储、查询五大核心模块,明确了各模块的功能、组件及应用场景,配套可运行的代码示例与详细注释,帮助读者快速上手。通过本章练习题,可检验学习效果,巩固核心知识点。LlamaIndex作为LLM与私有数据的桥梁,简化了RAG应用的搭建流程,其开源、可扩展的特性,使其成为各类LLM应用开发的优选工具。掌握本章基础概念,能为后续进阶学习和实际开发奠定坚实基础。
🌟 感谢您耐心阅读到这里!
🚀 技术成长没有捷径,但每一次的阅读、思考和实践,都在默默缩短您与成功的距离。
💡 如果本文对您有所启发,欢迎点赞👍、收藏📌、分享📤给更多需要的伙伴!
🗣️ 期待在评论区看到您的想法、疑问或建议,我会认真回复,让我们共同探讨、一起进步~
🔔 关注我,持续获取更多干货内容!
🤗 我们下篇文章见!