前几天 Claude Code 因为 sourcemap 没关,导致源码被公开。这件事在技术圈引起的讨论密度很高,因为这种真正跑在生产环境里的闭源通用 Agent 产品,它的内部实现本身就是一份高价值的学习材料。
我看了一些解析文章。有讲它设计模式的,有分析它安全边界的,也有拆解 Prompt 架构的。
但有一个细节我反复确认了一下:
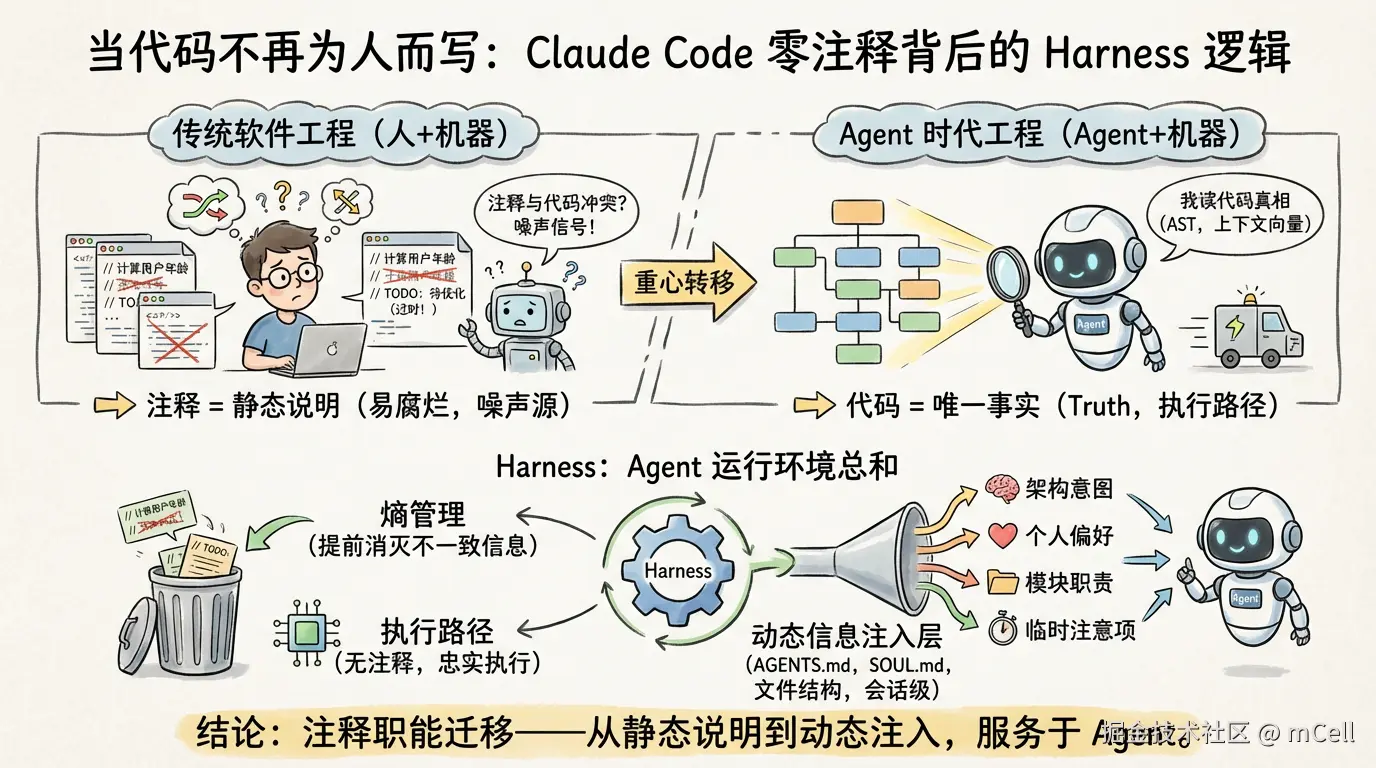
Claude Code 内部要求,不要写任何注释。
第一反应是反直觉。
注释难道不是为了理解代码吗?我从写代码以来接受的教育就是:复杂逻辑要写注释,接口参数要写注释,业务背景要写注释。后来在团队协作里,Code Review 如果发现某个模块的职责和边界没写清楚,是会被打回去的。
注释,一直是代码写给「人」看的那部分。
但问题就出在「人」这个前提上。
现在大家的工作流已经变了。写一个新功能,可能先用自然语言把意图丢给 Claude,让 AI 吐一版初稿,然后通过对话不断调整------「这里换个数据结构」「那个循环改成流式」。整个过程中,我几乎没有主动写过一行注释。
不是我懒了。而是注释的受众已经发生了迁移。
现在的代码,更多的时候是写给 Claude Code 这类 Agent 看的。Agent 在读代码的时候,依赖的是 LSP 解析出来的 AST,是符号索引,或者是上下文向量检索。它不需要你那一行 // 计算用户年龄 的注释------它从 calculateAge(birthDate) 的方法签名和返回类型就能推断出来。
真正的问题是,注释有时候会帮倒忙。
代码逻辑改了三版,但顶部那个 // TODO: 待优化 的注释还躺在那里。Agent 在执行任务时读到这条注释,可能会被误导,认为「这里性能有问题,我应该重构它」,然后引入一堆不必要的改动。而 LSP 和 Bash 在执行时只会忠实地跑代码本身,它永远不会跳出来说「注释里写的和代码不一致」。
过时的注释,对 Agent 来说不是辅助信息,是噪声信号。
如果把这件事放进 Harness 工程的框架里看,逻辑就更顺了。
Harness 是 Agent 运行时的「工程环境总和」。
真正决定 Agent 上限的,不是你有没有这些组件,而是你有没有把这些组件工程化成一个可以长期运转的环境。
Agent 的工作环境里,代码本身是 Truth。Agent 通过工具读取文件、分析 AST、执行命令,最终输出的行动都基于「代码实际写了什么」,而不是「注释里说它应该是什么」。
注释不在执行路径上。
如果一个环境里同时存在「代码逻辑」和「注释描述」两套信息,而这两套信息可能出现不一致,那对于 Harness 来说,这就是一个需要管理的熵源。
Claude Code 团队那条「不写注释」的规矩,本质上是在做熵管理------提前消灭掉一种不可验证、不可执行、且容易腐烂的信息形态。
所以结论其实很明确:
当协作对象从「人 + 机器」变成「Agent + 机器」,注释的定位必须重新评估。
这不是说所有注释都该死。而是说,注释的职能应该从「代码内的静态说明」,转移到 Harness 的动态信息注入层里去。
比如:
- 架构意图 → 放到
AGENTS.md - 个人偏好 → 放到
SOUL.md - 模块职责 → 靠文件结构和命名自解释
- 临时注意项 → 作为会话级上下文动态注入,用完即弃
这些东西不应该以注释的形式永久附着在代码文件里。
因为它们真正的消费者,已经不是那个读代码的人,而是那个在环境里执行任务的 Agent。
(完)